Artificial Intelligence
AWS AI League: Atos fine-tunes approach to AI education
This post is co-written with Mark Ross from Atos.
Organizations pursuing AI transformation can face a familiar challenge: how to upskill their workforce at scale in a way that changes how teams build, deploy, and use AI. Traditional AI training approaches—online courses, certification programs, and classroom-based instruction—are necessary, but often insufficient. While they build foundational knowledge, many organizations struggle with low engagement, limited hands-on practice, and a gap between theoretical understanding and real-world application. As a result, teams may earn certifications without gaining the confidence or experience required to apply AI meaningfully to business problems.
Through Atos’ partnership with AWS, we’ve long recognized that hands-on learning is the missing ingredient in effective AI enablement. When combined with structured e-learning and certification pathways, experiential learning helps translate knowledge into impact. Today, Atos employees hold over 5,800 AWS Certifications and 11 Golden Jackets, reflecting our strong foundation in cloud and AI skills. But with a commitment to achieving a 100% AI-fluent workforce by 2026, we knew we needed a learning model that could scale engagement, accelerate practical skills, and motivate engineers to apply AI in realistic scenarios.
To address this, Atos partnered with AWS to deliver a hands-on, gamified learning experience through the AWS AI League—designed to move beyond passive learning and immerse participants in real AI challenges. In this post, we’ll explore how Atos used the AWS AI League to help accelerate AI education across 400+ participants, highlight the tangible benefits of gamified, experiential learning, and share actionable insights you can apply to your own AI enablement programs.
AI enablement through the AWS AI League
While e-learning courses and certifications are an essential foundation, many organizations struggle to translate that knowledge into hands-on experience, sustained engagement, and real business impact—particularly at scale.
The AWS AI League was designed to address this gap. Rather than focusing solely on conceptual learning, the program combines hands-on experimentation with structured competition, so builders can work directly with generative AI tools used in real-world environments. For Atos, this approach offered a way to accelerate applied AI skills across the organization while maintaining engagement, collaboration, and measurable outcomes.
The AWS AI League helps builders level up their AI skills by abstracting away deep infrastructure complexity while preserving the core mechanics of model customization and evaluation. Participants work with Amazon SageMaker and Amazon SageMaker JumpStart to fine-tune large language models (LLMs), gaining practical experience with techniques that are increasingly central to enterprise AI adoption.
Why fine-tuning matters for business use cases
Fine-tuning a large language model is a form of transfer learning—a machine learning technique where a pre-trained model is adapted using a smaller, domain-specific dataset rather than being trained from scratch. For business teams, this approach offers a pragmatic path to customization: it helps reduce training time and computational cost while allowing models to reflect specialized knowledge, terminology, and decision logic.

In practice, organizations that use fine-tuning can adapt general-purpose models to specific domains where accuracy, reasoning, and explainability are critical. For Atos, this meant tailoring models to the insurance underwriting domain, where understanding risk profiles, policy conditions, exclusions, and premium calculations requires more than generic language fluency. The AWS AI League demonstrates that, with the right structure and tooling, teams across roles—including solutions architects, developers, consultants, and business analysts—can fine-tune and deploy models without requiring deep machine learning specialization. This makes fine-tuning a practical capability for partner organizations focused on delivering customer-ready AI solutions.
How the AWS AI League works
The AWS AI League follows a three-stage structure designed to build hands-on, production-oriented AI skills while maintaining momentum and engagement.The program begins with an immersive workshop that introduces the fundamentals of fine-tuning using SageMaker JumpStart. SageMaker JumpStart provides access to pre-trained foundation models through a guided interface, allowing participants to focus on model behavior and outcomes rather than infrastructure setup.Participants then move into an intensive model development phase. During this stage, teams iterate across multiple fine-tuning strategies, experimenting with dataset composition, augmentation techniques, and hyperparameter settings. Model submissions are evaluated on a dynamic leaderboard powered by an AI-based evaluation system, which benchmarks performance across a consistent set of criteria. This structure encourages rapid experimentation and makes progress visible, allowing teams to compare their customized models against larger baseline models.The program culminates in a live, interactive finale. Top-performing teams demonstrate their models through real-time challenges, with outputs evaluated using a multi-dimensional scoring system. Technical judges assess depth and correctness, an AI benchmark measures objective performance, and audience voting introduces a practical, user-oriented perspective. Together, these dimensions reinforce the League’s goal: turning hands-on learning into models that perform well in real-world scenarios.
Atos’s use case – Intelligent Insurance Underwriter
With this foundation in place, Atos selected a use case that closely reflects real customer needs: the Intelligent Insurance Underwriter. Developed through an AWS AI League event, the goal was to fine-tune a large language model capable of analyzing complex insurance scenarios and providing expert-level underwriting guidance. The model was designed to assess risk, recommend appropriate policy conditions or deductibles, suggest premium adjustments, and clearly explain the reasoning behind each decision — all while aligning with professional industry standards.This use case was chosen not as a theoretical exercise, but as a realistic example of how generative AI can support underwriting professionals by improving consistency and efficiency across insurance product lines. Built on cost-effective, fine-tuned open source models and powered by Amazon SageMaker, SageMaker Unified Studio, and Amazon S3, the solution incorporates a knowledge base alongside reasoning and recommendation modules trained on proprietary underwriting data. The result is an affordable, customized assistant that enhances team productivity, sharpens risk assessment accuracy, and integrates seamlessly with the authentic industry expertise underwriters already rely on.
Fine-tuning with Amazon SageMaker Studio and Amazon SageMaker JumpStart
AWS AI League participants do their model fine-tuning within Amazon SageMaker Studio—a fully integrated, web-based development environment for machine learning. SageMaker Studio provides a low-code/no-code (LCNC) interface to build, fine-tune, deploy, and monitor generative AI models end-to-end. By following this approach, Atos participants could focus on experimentation and innovation rather than infrastructure management, helping accelerate time-to-value. AI League now also offers customization of Amazon Nova models through serverless SageMaker model customization and agentic challenges built on top of Amazon Bedrock AgentCore.
Users follow a streamlined series of steps within Amazon SageMaker Studio:
- Select a model – SageMaker JumpStart offers a catalog of pre-trained, publicly available foundation models for tasks such as text generation, summarization, and image creation. Participants can seamlessly browse and select models from leading providers, which are pre-integrated for customization. For this competition, participants were required to fine-tune the Meta Llama 3.2 3B Instruct model, which is achieved in a no-code way utilizing Amazon SageMaker Jumpstart.
- Provide a training dataset – Datasets stored in Amazon Simple Storage Service (Amazon S3) are connected directly to SageMaker, leveraging its virtually unlimited storage capacity for fine-tuning tasks.
- Perform fine-tuning – Users can configure hyperparameters such as learning rate, epochs, and batch size before launching the fine-tuning job. SageMaker then manages the training process, including provisioning compute resources and logging progress.
- Deploy the model – Once training is complete, participants can deploy their models directly from SageMaker Studio for inference or import them into Amazon Bedrock, which provides a fully managed environment for scalable production deployment.
- Evaluate and iterate – During the AWS AI League, evaluation was performed using LLM-as-a-Judge, an internal judging system that automatically scored models on quality, accuracy, and responsiveness.
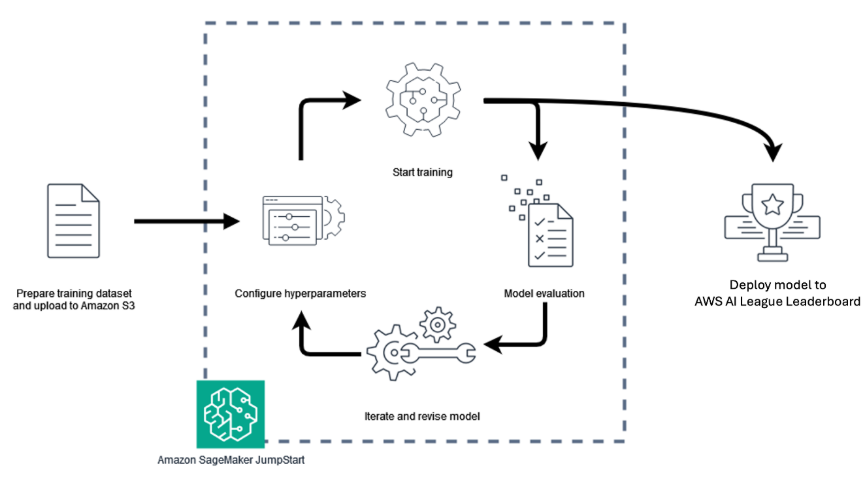
This simplified workflow, depicted above, shows the AWS AI League model development lifecycle and how it helps reduce the complexity of developing and operationalizing specialized AI models, while preserving performance, transparency, and cost-efficiency. For Atos, this hands-on process provides a practical, production-ready foundation for extending generative AI capabilities into customer-facing solutions. Participants were required to generate insurance use case datasets in JSON Lines (JSONL) format. Each record consisted of two fields:
- Instruction – the prompt or question for the Intelligent Insurance Underwriter to consider.
- Response – an example of the ideal answer the fine-tuned model should produce.
These datasets formed the foundation for the model fine-tuned phase.
To simplify dataset creation, participants were given access to an AWS provided PartyRock application which offered an simple-to-use interface for generating and exporting data. Once complete, the datasets were uploaded to Amazon Simple Storage Service (Amazon S3), where they served as the input for model fine-tuning.
During fine-tuning, participants could adjust a range of hyperparameters to influence the fine-tuning including, but not limited, to the following:
- Epochs – The number of times the fine-tuning process will pass over the dataset .
- Learning rate – The weighting applied to the updates the model makes each time it passes over the data.
After fine-tuning, participants deployed their customized language models in Amazon SageMaker and used the endpoints to perform inference. This allowed them to observe how the fine-tuned models responded to sample insurance queries and assessed the quality of their outputs
Results varied across participants. Some fine-tuned models delivered strong, contextually relevant answers, while others displayed signs of overfitting — a condition where a model learns the training data too precisely, leading to repetitive or irrelevant responses when exposed to new inputs. Overtrained models, for instance, tend to echo phrases from the dataset rather than generalizing to unseen scenarios. Armed with these insights, participants evaluated their models’ performance and determined which versions to submit to the AWS AI League leaderboard and which to refine or discard. This iterative process emphasized experimentation, data quality, and parameter tuning as key success factors in achieving high-performing generative AI models.
Gamification ignites participation.
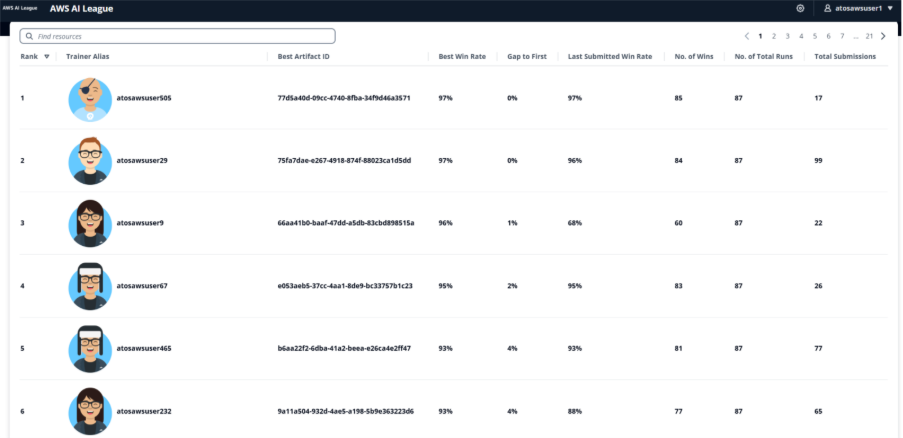
Hands-on labs and workshops are a great way to provide people with an opportunity to learn by doing but providing a gamified approach where you’re competing with other people takes it to another level. Atos saw this with the AWS AI League. Following an initial kick-off workshop, Atos participants created and submitted initial models, before turning their approach to maximizing their scores on the leaderboard by iteratively creating or improving their datasets and tuning their hyperparameters over a two-week virtual league. By the completion of the virtual round, Atos had their best level of engagement for a gamified competition, with 409 participants on the leaderboard, with over 4,100 fine-tuned models having been created.

Despite the gamified nature of the competition, communication channels and office hours were full of people balancing sharing information with each other whilst avoiding giving everything away. It was a great balance which made sure those that wanted to take part and improve were supported enough, whilst also having to figure some things out for themselves. The friendly competition was incredibly fierce at the same time, and to make the top five a participant’s fine-tuned model was required to achieve at least a 93%-win rate against the answers provided by a much larger model, showing the power of fine-tuning for domain specific knowledge. The virtual stage of the competition was fully automated with a Llama 3.2 90B LLM as a judge providing the scoring. Upon completion of the virtual round, the top five participants were taken forward to a live gameshow finale, competing for a spot in the AWS finals during AWS re:Invent Las Vegas in December.
To rank the top five, the live finale introduced additional scoring methods, as well as providing the finalists with an opportunity to influence their model’s response. Finale scoring was split between 40% for LLM-as-a-Judge, 40% between our five human expert judges from Atos, and 20% for audience voting. Five rounds of questions provided an ample chance to check out the model’s performance, and during each question the finalists were able to influence model output with some system prompting, and hyperparameter tuning for inference (temperature and top p to control the randomness and creativity of the answer). Finalists only had 90 seconds to tune their inference and submit their final answers, so it was a tense and close competition.
Tips to fine-tune your way to success
The fine-tuning competition comes down to two key elements – the participants’ ability to generate a good dataset for the subject of the competition, and an ability to find the optimal hyperparameters to use for fine-tuning with the dataset.
Whilst AWS provided a PartyRock application to generate a dataset, some of the Atos participants took inspiration from the provided application and remixed their own. The idea of this application was to a) generate more data and b) generate diverse and unique data, both improvements over the AWS provided application. Some participants chose to use alternative generative AI tools they had access to, to generate their own responses, but this required them to create system prompts that the PartyRock application took care of to verify data was provided in the right format, for example.
Larger datasets didn’t necessarily lead to better results, so there was also a requirement to review the datasets that had been generated and work out how to improve them. Successful participants also used generative AI for this, with general recommendations on how to improve (e.g. for the Atos use case areas of insurance that may have been missing from the dataset), as well as more specific recommendations and actions being taken on the dataset, for example removing items in the dataset that were too similar. This resulted in a new PartyRock application being created and shared amongst participants to provide improvement tips.
Participants had control over several critical hyperparameters that significantly influenced fine-tuning outcomes. Epochs determine how many times the training process passes over the entire dataset—too few epochs result in underfitting where the model hasn’t learned enough, while too many can cause overfitting where the model memorizes training data rather than generalizing. Learning rate controls the magnitude of updates the model makes during each training step; a high learning rate enables faster training but risks overshooting optimal values, while a low learning rate provides more precise adjustments but requires longer training time.
Additional parameters included batch size, which affects training stability and memory usage, and Low-Rank Adaptation (LoRA) parameters such as lora_r and lora_alpha, which control the efficiency of the fine-tuning process. Successful participants approached hyperparameter tuning systematically, either changing single values at a time to isolate their effects or adjusting related parameters together while carefully logging results to identify patterns
Understanding model performance and overfitting
This discrepancy highlights an important aspect of model behavior. During fine-tuning, the model gradually becomes better at answering questions derived from the training and evaluation datasets, which are subsets of the same underlying data. However, the leaderboard evaluated each model using 87 unseen questions — examples that were not included in the training data.
During fine-tuning, participants could also monitor metrics such as evaluation loss (eval-loss) and perplexity (ppl), which help indicate how well a model fits the training data. Lower eval-loss and perplexity generally suggest the model is learning the dataset effectively, while large gaps between training and evaluation metrics can signal overfitting and reduced ability to generalize. Evaluation loss is the loss value calculated on the validation or evaluation dataset during training. It measures how well the model predicts the correct next tokens for examples it has not directly trained on in that step. Perplexity is a commonly used metric for language models that represents how “surprised” the model is by the evaluation data. Lower perplexity indicates the model is better able to predict the correct next tokens, suggesting it has learned the underlying patterns in the dataset more effectively.
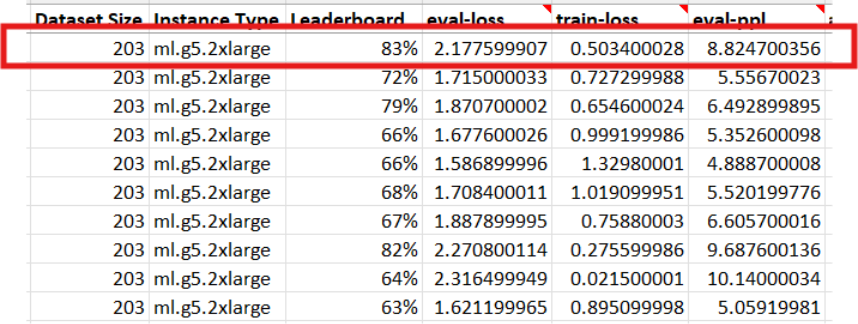
As a result, some models became overfitted, meaning they performed extremely well on the data they had seen but struggled to generalize to new questions. This pattern could be observed by deploying the model to an inference endpoint and interacting with it directly: overfitted models often produced irrelevant or repetitive responses, a clear sign that they had memorized patterns from the training set rather than learning to reason more broadly.
Upskilling ambitions achieved
Through the AWS AI League Atos’ ambition was to put generative AI tech into participants’ hands and allow them to feel more confident talking about and using it after the event, whilst having some fun and team building along the way. Participants learned how a smaller 3 billion parameter model (Llama 3.2 3B Instruct) could outperform a much larger 90 billion parameter model through fine-tuning with relevant domain knowledge, in this instance becoming a true digital insurance underwriter assistant able to answer complex cases with appropriate feedback on risk areas and appropriate levels of deductibles etc. As generative AI and agentic AI develop, we see more use cases for specific knowledge within AI agents. Fine tuning a model to provide this specific knowledge can result in a much smaller model which can provide faster inference at a lower cost than larger models, something that will be crucial as we enter the age of agentic AI. As you move toward agentic AI architectures where multiple specialized AI agents collaborate to solve complex problems, having cost-effective, domain-specific models becomes crucial. Fine-tuned models can serve as specialized agents within larger agentic systems, each handling specific domains while maintaining fast response times and manageable costs.
Conclusion
As you continue to explore generative AI implementations, the ability to efficiently build, customize, and deploy specialized models becomes increasingly critical. The AWS AI League provides a structured pathway for partners like Atos to deepen their AI capabilities—whether enhancing existing offerings or creating entirely new, AI-driven services that address real-world customer needs. The AWS AI League program demonstrates how gamified learning can accelerate partners’ AI innovation while driving measurable business outcomes. The AWS AI League delivered measurable outcomes for Atos beyond participant engagement. The program showed that fine-tuned 3B parameter models could achieve win rates exceeding 93% against much larger 90B parameter models for domain-specific tasks, demonstrating the cost-efficiency of specialized model development. From a resource perspective, the fine-tuned models required less computational infrastructure—running on ml.g5.4xlarge instances compared to the ml.g5.48xlarge instances needed for larger base models—translating to cost savings for inference at scale. The compressed learning timeline was particularly valuable, with participants being able to develop practical AI skills in just two weeks that would typically require months of traditional training. The 409 active participants and 4,100+ fine-tuned models created during the event represented an acceleration in Atos’s journey toward their 2026 goal of 100% AI fluency across their workforce. Post-event surveys indicated that 85% of participants felt more confident discussing and implementing generative AI solutions with customers, directly supporting Atos’s business objectives
If you’re interested in building AI capabilities through hands-on, gamified learning, you can learn more about hosting their own AWS AI League event at the official site.
To learn more about implementing AI solutions:
- Explore how you can get started to build, train, and deploy ML models at scale with SageMaker
- Use serverless model customization from SageMaker AI
- Connect with AWS Partners like Atos who are building innovative AI solutions
You can also visit the AWS Artificial Intelligence blog for more stories about partners and customers implementing generative AI solutions across various industries.