Artificial Intelligence
Build reliable Agentic AI solution with Amazon Bedrock: Learn from Pushpay’s journey on GenAI evaluation
This post was co-written with Saurabh Gupta and Todd Colby from Pushpay.
Pushpay is a market-leading digital giving and engagement platform designed to help churches and faith-based organizations drive community engagement, manage donations, and strengthen generosity fundraising processes efficiently. Pushpay’s church management system provides church administrators and ministry leaders with insight-driven reporting, donor development dashboards, and automation of financial workflows.
Using the power of generative AI, Pushpay developed an innovative agentic AI search feature built for the unique needs of ministries. The approach uses natural language processing so ministry staff can ask questions in plain English and generate real-time, actionable insights from their community data. The AI search feature addresses a critical challenge faced by ministry leaders: the need for quick access to community insights without requiring technical expertise. For example, ministry leaders can enter “show me people who are members in a group, but haven’t given this year” or “show me people who are not engaged in my church,” and use the results to take meaningful action to better support individuals in their community. Most community leaders are time-constrained and lack technical backgrounds; they can use this solution to obtain meaningful data about their congregations in seconds using natural language queries.
By empowering ministry staff with faster access to community insights, the AI search feature supports Pushpay’s mission to encourage generosity and connection between churches and their community members. Early adoption users report that this solution has shortened their time to insights from minutes to seconds. To achieve this result, the Pushpay team built the feature using agentic AI capabilities on Amazon Web Services (AWS) while implementing robust quality assurance measures and establishing a rapid iterative feedback loop for continuous improvements.
In this post, we walk you through Pushpay’s journey in building this solution and explore how Pushpay used Amazon Bedrock to create a custom generative AI evaluation framework for continuous quality assurance and establishing rapid iteration feedback loops on AWS.
Solution overview: AI powered search architecture
The solution consists of several key components that work together to deliver an enhanced search experience. The following figure shows the solution architecture diagram and the overall workflow.
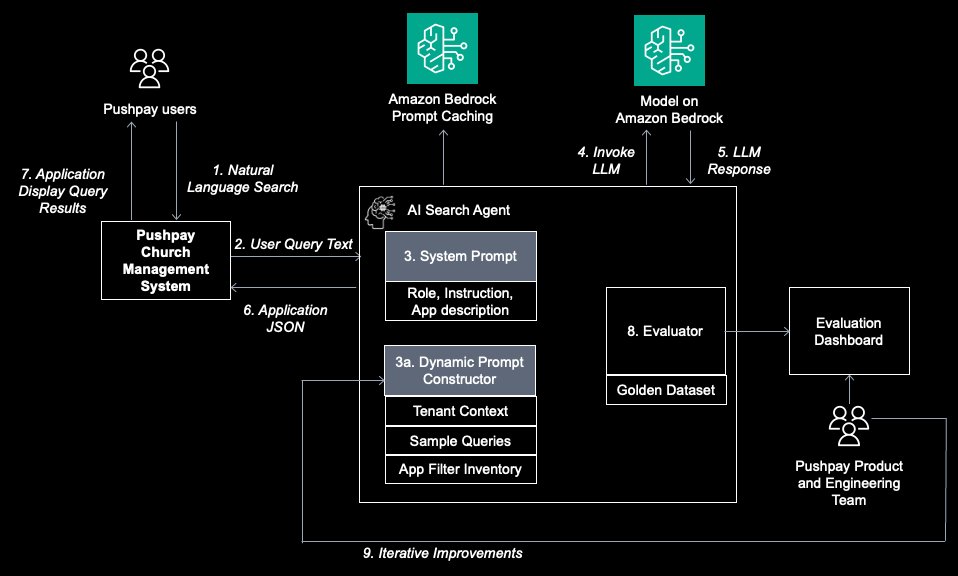
Figure 1: AI Search Solution Architecture
- User interface layer: The solution begins with Pushpay users submitting natural language queries through the existing Pushpay application interface. By using natural language queries, church ministry staff can obtain data insights using AI capabilities without learning new tools or interfaces.
- AI search agent: At the heart of the system lies the AI search agent, which consists of two key components:
- System prompt: Contains the large language model (LLM) role definitions, instructions, and application descriptions that guide the agent’s behavior.
- Dynamic prompt constructor (DPC): automatically constructs additional customized system prompts based on the user specific information, such as church context, sample queries, and application filter inventory. They also use semantic search to select only relevant filters among hundreds of available application filters. The DPC improves response accuracy and user experience.
- Amazon Bedrock advanced feature: The solution uses the following Amazon Bedrock managed services:
- Prompt caching: Reduces latency and costs by caching frequently used system prompt.
- LLM processing: Uses Claude Sonnet 4.5 to process prompts and generate JSON output required by the application to display the desired query results as insights to users.
- Evaluation system: The evaluation system implements a closed-loop improvement solution where user interactions are instrumented, captured and evaluated offline. The evaluation results feed into a dashboard for product and engineering teams to analyze and drive iterative improvements to the AI search agent. During this process, the data science team collects a golden dataset and continuously curates this dataset based on the actual user queries coupled with validated responses.
The challenges of initial solution without evaluation
To create the AI search feature, Pushpay developed the first iteration of the AI search agent. The solution implements a single agent configured with a carefully tuned system prompt that includes the system role, instructions, and how the user interface works with detailed explanation of each filter tool and their sub-settings. The system prompt is cached using Amazon Bedrock prompt caching to reduce token cost and latency. The agent uses the system prompt to invoke an Amazon Bedrock LLM which generates the JSON document that Pushpay’s application uses to apply filters and present query results to users.
However, this first iteration quickly revealed some limitations. While it demonstrated a 60-70% success rate with basic business queries, the team reached an accuracy plateau. The evaluation of the agent was a manual and tedious process Tuning the system prompt beyond this accuracy threshold proved challenging given the diverse spectrum of user queries and the application’s coverage of over 100 distinct configurable filters. These presented critical blockers for the team’s path to production.
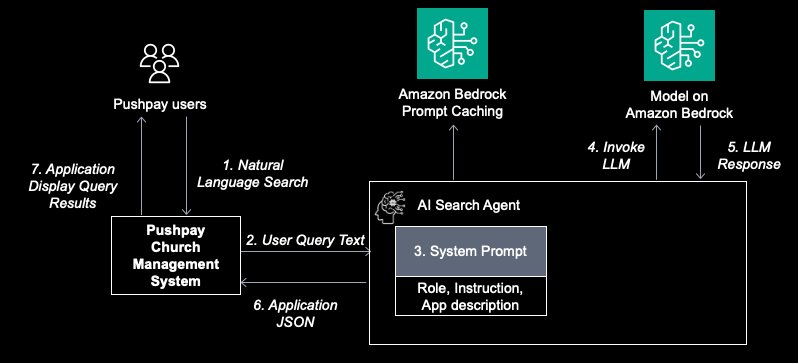
Figure 2: AI Search First Solution
Improving the solution by adding a custom generative AI evaluation framework
To address the challenges of measuring and improving agent accuracy, the team implemented a generative AI evaluation framework integrated into the existing architecture, shown in the following figure. This framework consists of four key components that work together to provide comprehensive performance insights and enable data-driven improvements.
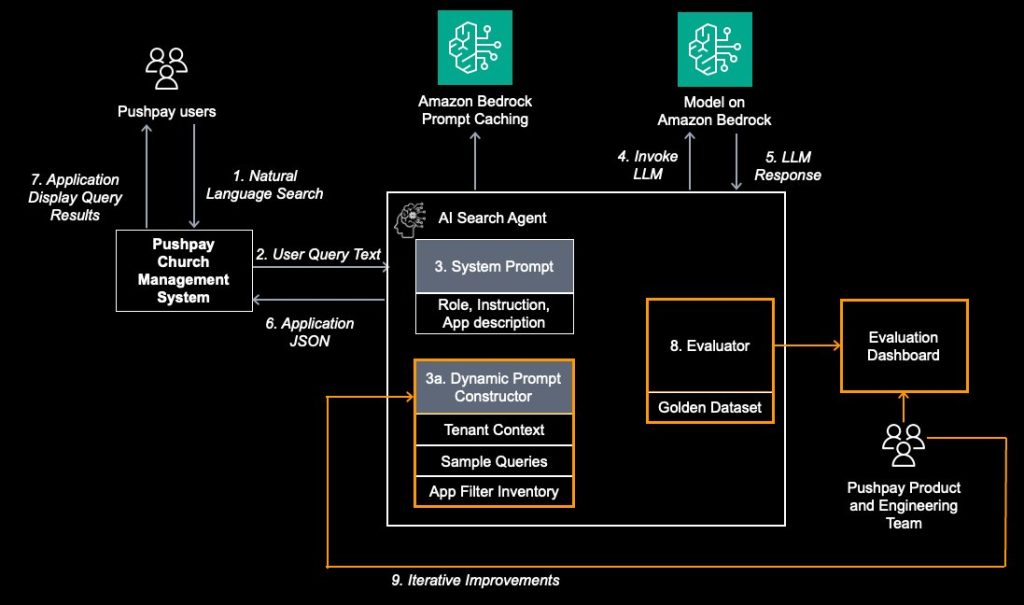
Figure 3: Introducing the GenAI Evaluation Framework
- The golden dataset: A curated golden dataset containing over 300 representative queries, each paired with its corresponding expected output, forms the foundation of automated evaluation. The product and data science teams carefully developed and validated this dataset to achieve comprehensive coverage of real-world use cases and edge cases. Additionally, there is a continuous curation process of adding representative actual user queries with validated results.
- The evaluator: The evaluator component processes user input queries and compares the agent-generated output against the golden dataset using the LLM as a judge pattern This approach generates core accuracy metrics while capturing detailed logs and performance data, such as latency, for further analysis and debugging.
- Domain category: Domain categories are developed using a combination of generative AI domain summarization and human-defined regular expressions to effectively categorize user queries. The evaluator determines the domain category for each query, enabling nuanced, category-based evaluation as an additional dimension of evaluation metrics.
- Generative AI evaluation dashboard: The dashboard serves as the mission control for Pushpay’s product and engineering teams, displaying domain category-level metrics to assess performance and latency and guide decisions. It shifts the team from single aggregate scores to nuanced, domain-based performance insights.
The accuracy dashboard: Pinpointing weaknesses by domain
Because user queries are categorized into domain categories, the dashboard incorporates statistical confidence visualization using a 95% Wilson score interval to display accuracy metrics and query volumes at each domain level. By using categories, the team can pinpoint the AI agent’s weaknesses by domain. In the following example , the “activity” domain shows significantly lower accuracy than other categories.
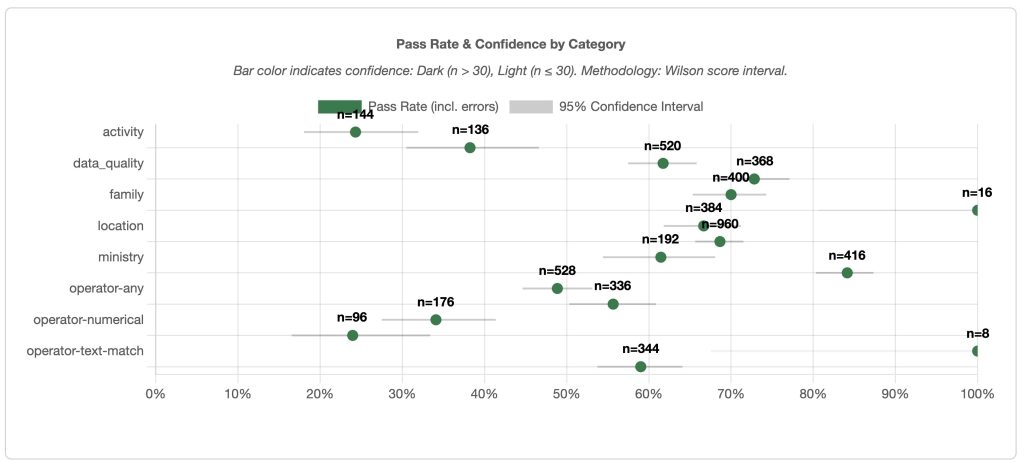
Figure 4: Pinpointing Agent Weaknesses by Domain
Additionally, a performance dashboard, shown in the following figure, visualizes latency indicators at the domain category level, including latency distributions from p50 to p90 percentiles. In the following example, the activity domain exhibits notably higher latency than others.
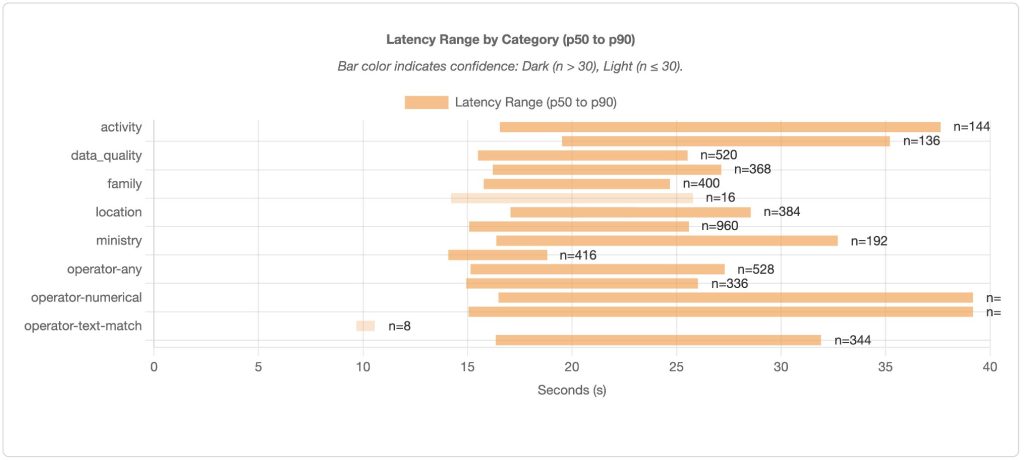
Figure 5: Identifying Latency Bottlenecks by Domain
Strategic rollout through domain-Level insights
Domain-based metrics revealed varying performance levels across semantic domains, providing crucial insights into agent effectiveness. Pushpay used this granular visibility to make strategic feature rollout decisions. By temporarily suppressing underperforming categories—such as activity queries—while undergoing optimization, the system achieved 95% overall accuracy. By using this approach, users experienced only the highest-performing features while the team refined others to production standards.
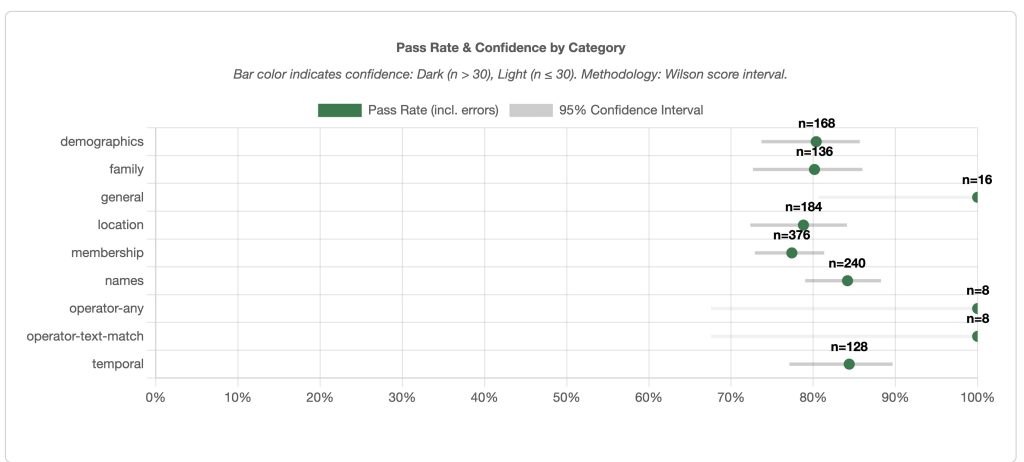
Figure 6: Achieving 95% Accuracy with Domain-Level Feature Rollout
Strategic prioritization: Focusing on high-impact domains
To prioritize improvements systematically, Pushpay employed a 2×2 matrix framework plotting topics against two dimensions (shown in the following figure): Business priority (vertical axis) and current performance or feasibility (horizontal axis). This visualization placed topics with both high business value and strong existing performance in the top-right quadrant. The team then focused on these areas because they required less heavy lifting to achieve further accuracy improvement from already-good levels to an exceptional 95% accuracy for the business focused topics.
The implementation followed an iterative cycle: after each round of enhancements, they re-analyze the results to identify the next set of high-potential topics. This systematic, cyclical approach enabled continuous optimization while maintaining focus on business-critical areas.
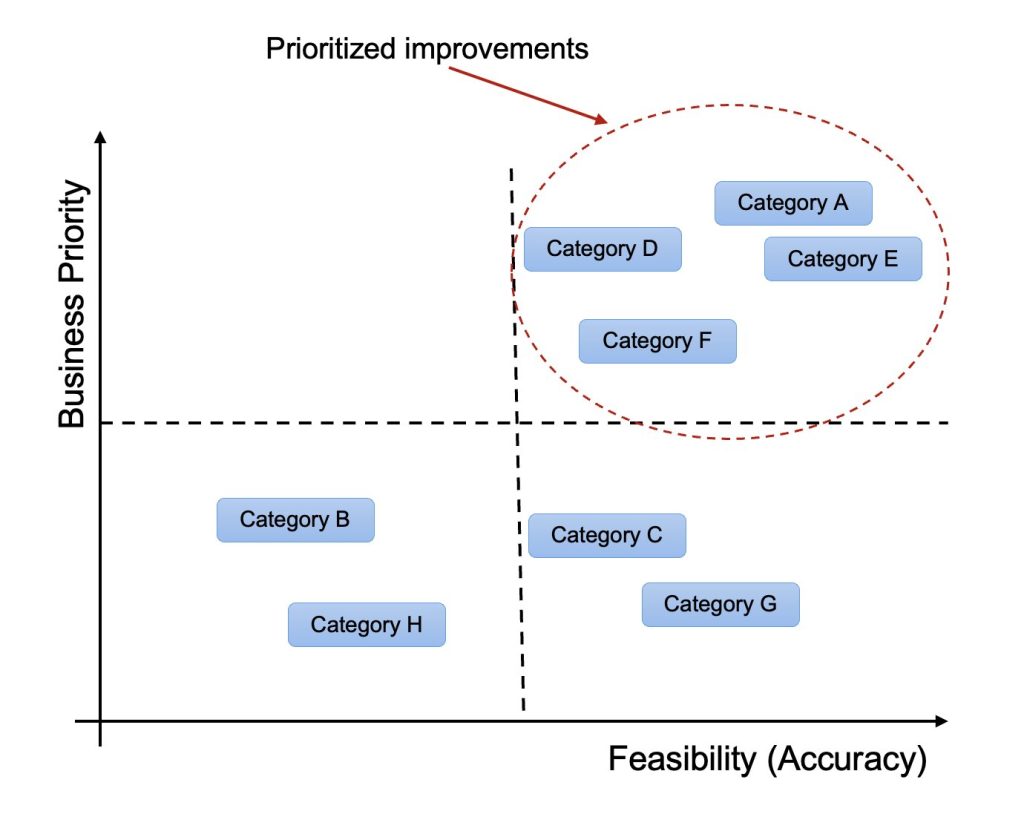
Figure 7: Strategic Prioritization Framework for Domain Category Optimization
Dynamic prompt construction
The insights gained from the evaluation framework led to an architectural enhancement: the introduction of a dynamic prompt constructor. This component enabled rapid iterative improvements by allowing fine-grained control over which domain categories the agent could address. The structured field inventory – previously embedded in the system prompt – was transformed into a dynamic element, using semantic search to construct contextually relevant prompts for each user query. This approach tailors the prompt filter inventory based on three key contextual dimensions: query content, user persona, and tenant-specific requirements. The result is a more precise and efficient system that generates highly relevant responses while maintaining the flexibility needed for continuous optimization.
Business impact
The generative AI evaluation framework became the cornerstone of Pushpay’s AI feature development, delivering measurable value across three dimensions:
- User experience: The AI search feature reduced time-to-insight from approximately 120 seconds (experienced users manually navigating complex UX) to under 4 seconds – a 15-fold acceleration that directly helps enhance ministry leaders’ productivity and decision-making speed. This feature democratized data insights, so that users of different technical levels can access meaningful intelligence without requiring specialized expertise.
- Development velocity: The scientific evaluation approach transformed optimization cycles. Rather than debating prompt modifications, the team now validates changes and measures domain-specific impacts within minutes, replacing prolonged deliberations with data-driven iteration.
- Production readiness: Improvements from 60–70% accuracy to more than 95% accuracy using high-performance domains provided the quantitative confidence required for customer-facing deployment, while the framework’s architecture enables continuous refinement across other domain categories.
Key takeaways for your AI agent journey
The following are key takeaways from Pushpay’s experience that you can use in your own AI agent journey.
1/ Build with production in mind from day one
Building agentic AI systems is straightforward, but scaling them to production is challenging. Developers should adopt a scaling mindset during the proof-of-concept phase, not after. Implementing robust tracing and evaluation frameworks early, provides a clear pathway from experimentation to production. By using this method, teams can identify and address accuracy issues systematically before they become blockers.
2/ Take advantage of the advanced features of Amazon Bedrock
Amazon Bedrock prompt caching significantly reduces token costs and latency by caching frequently used system prompts. For agents with large, stable system prompts, this feature is essential for production-grade performance.
3/ Think beyond aggregate metrics
Aggregate accuracy scores can sometimes mask critical performance variations. By evaluating agent performance at the domain category level, Pushpay uncovered weaknesses beyond what a single accuracy metric can capture. This granular approach enables targeted optimization and informed rollout decisions, making sure users only experience high-performing features while others are refined.
4/ Data security and responsible AI
When developing agentic AI systems, consider information protection and LLM security considerations from the outset, following the AWS Shared Responsibility Model, because security requirements fundamentally impact the architectural design. Pushpay’s customers are churches and faith-based organizations who are stewards of sensitive information—including pastoral care conversations, financial giving patterns, family struggles, prayer requests and more. In this implementation example, Pushpay set a clear approach to incorporating AI ethically within its product ecosystem, maintaining strict security standards to ensure church data and personally identifiable information (PII) remains within its secure partnership ecosystem. Data is shared only with secure and appropriate data protections applied and is never used to train external models. To learn more about Pushpay’s standards for incorporating AI within their products, visit the Pushpay Knowledge Center for a more in-depth review of company standards.
Conclusion: Your Path to Production-Ready AI Agents
Pushpay’s journey from a 60–70% accuracy prototype to a 95% accurate production-ready AI agent demonstrates that building reliable agentic AI systems requires more than just sophisticated prompts—it demands a scientific, data-driven approach to evaluation and optimization. The key breakthrough wasn’t in the AI technology itself, but in implementing a comprehensive evaluation framework built on strong observability foundation that provided granular visibility into agent performance across different domains. This systematic approach enabled rapid iteration, strategic rollout decisions, and continuous improvement.
Ready to build your own production-ready AI agent?
- Explore Amazon Bedrock: Begin building your agent with Amazon Bedrock
- Implement LLM-as-a-judge: Create your own evaluation system using the patterns described in this LLM-as-a-judge on Amazon Bedrock Model Evaluation
- Build your golden dataset: Start curating representative queries and expected outputs for your specific use case
About the authors
 Roger Wang is a Senior Solution Architect at AWS. He is a seasoned architect with over 20 years of experience in the software industry. He helps New Zealand and global software and SaaS companies use cutting-edge technology at AWS to solve complex business challenges. Roger is passionate about bridging the gap between business drivers and technological capabilities and thrives on facilitating conversations that drive impactful results.
Roger Wang is a Senior Solution Architect at AWS. He is a seasoned architect with over 20 years of experience in the software industry. He helps New Zealand and global software and SaaS companies use cutting-edge technology at AWS to solve complex business challenges. Roger is passionate about bridging the gap between business drivers and technological capabilities and thrives on facilitating conversations that drive impactful results.
 Melanie Li, PhD, is a Senior Generative AI Specialist Solutions Architect at AWS based in Sydney, Australia, where her focus is on working with customers to build solutions leveraging state-of-the-art AI and machine learning tools. She has been actively involved in multiple Generative AI initiatives across APJ, harnessing the power of Large Language Models (LLMs). Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries.
Melanie Li, PhD, is a Senior Generative AI Specialist Solutions Architect at AWS based in Sydney, Australia, where her focus is on working with customers to build solutions leveraging state-of-the-art AI and machine learning tools. She has been actively involved in multiple Generative AI initiatives across APJ, harnessing the power of Large Language Models (LLMs). Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries.
 Frank Huang, PhD, is a Senior Analytics Specialist Solutions Architect at AWS based in Auckland, New Zealand. He focuses on helping customers deliver advanced analytics and AI/ML solutions. Throughout his career, Frank has worked across a variety of industries such as financial services, Web3, hospitality, media and entertainment, and telecommunications. Frank is eager to use his deep expertise in cloud architecture, AIOps, and end-to-end solution delivery to help customers achieve tangible business outcomes with the power of data and AI.
Frank Huang, PhD, is a Senior Analytics Specialist Solutions Architect at AWS based in Auckland, New Zealand. He focuses on helping customers deliver advanced analytics and AI/ML solutions. Throughout his career, Frank has worked across a variety of industries such as financial services, Web3, hospitality, media and entertainment, and telecommunications. Frank is eager to use his deep expertise in cloud architecture, AIOps, and end-to-end solution delivery to help customers achieve tangible business outcomes with the power of data and AI.
 Saurabh Gupta is a data science and AI professional at Pushpay based in Auckland, New Zealand, where he focuses on implementing practical AI solutions and statistical modeling. He has extensive experience in machine learning, data science, and Python for data science applications, with specialized experience training in database agents and AI implementation. Prior to his current role, he gained experience in telecom, retail and financial services, developing expertise in marketing analytics and customer retention programs. He has a Master’s in Statistics from University of Auckland and a Master’s in Business Administration from the Indian Institute of Management, Calcutta.
Saurabh Gupta is a data science and AI professional at Pushpay based in Auckland, New Zealand, where he focuses on implementing practical AI solutions and statistical modeling. He has extensive experience in machine learning, data science, and Python for data science applications, with specialized experience training in database agents and AI implementation. Prior to his current role, he gained experience in telecom, retail and financial services, developing expertise in marketing analytics and customer retention programs. He has a Master’s in Statistics from University of Auckland and a Master’s in Business Administration from the Indian Institute of Management, Calcutta.
 Todd Colby is a Senior Software Engineer at Pushpay based in Seattle. His expertise is focused on evolving complex legacy applications with AI, and translating user needs into structured, high-accuracy solutions. He leverages AI to increase delivery velocity and produce cutting edge metrics and business decision tools.
Todd Colby is a Senior Software Engineer at Pushpay based in Seattle. His expertise is focused on evolving complex legacy applications with AI, and translating user needs into structured, high-accuracy solutions. He leverages AI to increase delivery velocity and produce cutting edge metrics and business decision tools.