Artificial Intelligence
Building a scalable and adaptable video processing pipeline with Amazon Rekognition Video
This is a guest post by Joe Monti, Sr. Software Engineer at VidMob. Vidmob is, in their own words, “the world’s leading video creation platform, with innovative technology solutions that enable a network of highly trained creators to develop marketing communications that are insight-driven, personalized, and scalable. VidMob creators are trained to produce the full spectrum of video content across every social/digital channel, format, and language.”
Videos pose a unique challenge to automated content recognition, particularly for use in a complex, large-scale, real-time application. Not only are deep learning algorithms difficult to implement and use, but processing large video files and large output files can require a lot of computing power. Amazon Rekognition, combined with the wealth of tools and services available on AWS, makes so many of those hard parts so much easier. It lets you focus on building cool and useful applications.
This post walks through the key components of a highly scalable and adaptable processing pipeline for performing content recognition against video files.
Architecture Overview
The following architecture brings together many AWS services to process videos through content recognition and to build usable datasets.
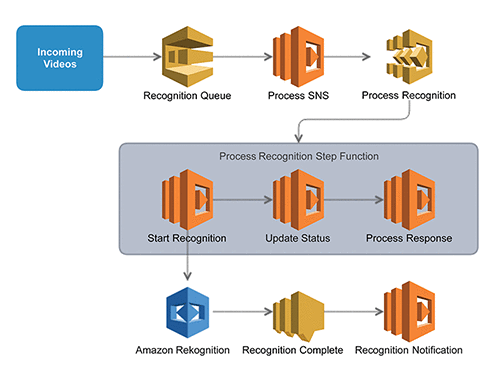
The process starts as the system ingests new videos and a message is sent to an Amazon SQS queue for pending media recognition. This queue acts as a buffer to manage the throughput to the Amazon Rekognition API. The next step is triggered by an Amazon CloudWatch event configured on a fixed-rate schedule to process the SQS queue and start the Process Rekognition step function. This step function then coordinates several AWS Lambda functions to manage the subsequent Amazon Rekognition requests and data processing.
A Step Function for Processing Requests through Amazon Rekognition
You can think of step functions as a system that coordinates the execution of code and provides the control-flow logic to decide what to do next. Step functions can therefore enable you to quickly develop, test, deploy, and improve the functionality of your video processing pipeline. For this example, step functions, created in AWS Step Functions, enable video processing through multiple content Amazon Rekognition API operations. The following image shows a simple step function that starts, waits for, and processes Amazon Rekognition requests.

This step function has the following states:
- Start Recognition – A Lambda function that starts and tracks the Amazon Rekognition job. Because the Amazon Rekognition API operations for videos are asynchronous, you must start an Amazon Rekognition job and wait for it to finish.
- Await Recognition – A wait state that sleeps for a certain amount of time to let the Amazon Rekognition processes completes.
- Update Recognition Status – A Lambda function that monitors for the notification that the asynchronous Amazon Rekognition tasks are completed. Then it signals to the step function when it can continue.
- Check Recognition Complete – A choice state that looks at the previous steps and decides whether to retry the wait, whether the Amazon Rekognition request failed, or whether to continue.
- Process Recognition Response – A Lambda function that processes the response data from all requested jobs for a video into datasets suitable for your application.
Using Lambda Functions in the Step Functions
The Lambda functions for video recognition processing rely on three main AWS services:
- Amazon Rekognition – This is used to start, retrieve status, and retrieve results from individual Rekognition jobs.
- Amazon S3 – Video files and raw Amazon Rekognition output is stored in Amazon S3.
- Amazon RDS – Amazon Rekognition requests and associated data are stored in a MySQL RDS instance.
The following are a few examples of the code required to support the Lambda functions used by the step functions. All Lambda examples are written in Python.
Starting Amazon Rekognition
The following code can start an Amazon Rekognition request to the DetectLabels operation.
Receiving the Amazon SNS Notification
The Amazon Rekognition API sends an Amazon SNS topic to the provided notification channel. Hooking this SNS topic to a Lambda function allows you to respond to the job being completed and continue the processing. The following code shows how you can receive the Amazon SNS notification to retrieve the Amazon Rekognition results, store them in Amazon S3, and update the database with the results.
Video Processing and Data Structure
Processing and correlating data across the timeline of a video can be a challenge. With a video, you often want to make relationships between the labels over time. To achieve this, you can translate the frame-based data coming from the Amazon Rekognition API to a more label-based dataset.
Here’s an example of the data returned by the DetectLabels operation.
The label “Baseball” appears in time stamps 0, 200, and 400 and therefore is present in the entire video (Amazon Rekognition typically detects frames about every 200 ms.). You can condense the tags appearing in consecutive frames to produce the following dataset.
Here’s an example Python function that performs this translation.
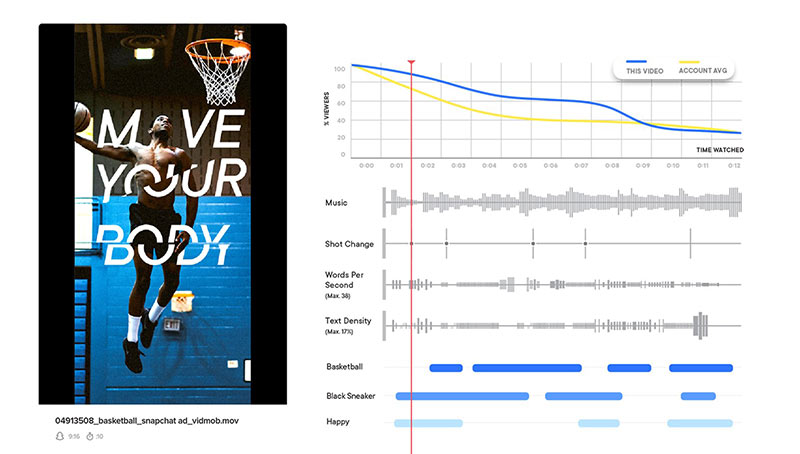
You can then store the condensed labels in a database for an application to use. As an example, here’s how VidMob uses this and other data to build a powerful visualization for showing content recognition data.
Conclusion
There are many more details that go into building a complete system. However, this post should give you a general idea of how to use the tools in the AWS toolbox to build a highly scalable and highly adaptable video processing pipeline.