Artificial Intelligence
Category: Foundation models

Train CodeFu-7B with veRL and Ray on Amazon SageMaker Training jobs
In this post, we demonstrate how to train CodeFu-7B, a specialized 7-billion parameter model for competitive programming, using Group Relative Policy Optimization (GRPO) with veRL, a flexible and efficient training library for large language models (LLMs) that enables straightforward extension of diverse RL algorithms and seamless integration with existing LLM infrastructure, within a distributed Ray cluster managed by SageMaker training jobs. We walk through the complete implementation, covering data preparation, distributed training setup, and comprehensive observability, showcasing how this unified approach delivers both computational scale and developer experience for sophisticated RL training workloads.

Scale LLM fine-tuning with Hugging Face and Amazon SageMaker AI
In this post, we show how this integrated approach transforms enterprise LLM fine-tuning from a complex, resource-intensive challenge into a streamlined, scalable solution for achieving better model performance in domain-specific applications.

Evaluating generative AI models with Amazon Nova LLM-as-a-Judge on Amazon SageMaker AI
Evaluating the performance of large language models (LLMs) goes beyond statistical metrics like perplexity or bilingual evaluation understudy (BLEU) scores. For most real-world generative AI scenarios, it’s crucial to understand whether a model is producing better outputs than a baseline or an earlier iteration. This is especially important for applications such as summarization, content generation, […]
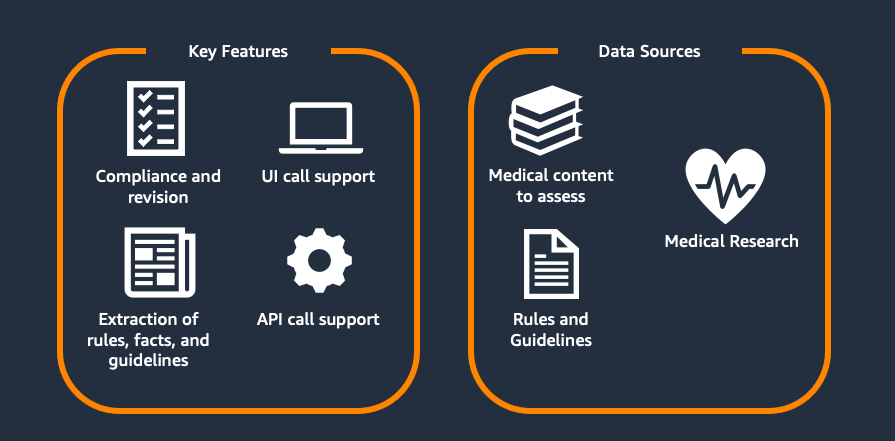
Scaling medical content review at Flo Health using Amazon Bedrock (Part 1)
This two-part series explores Flo Health’s journey with generative AI for medical content verification. Part 1 examines our proof of concept (PoC), including the initial solution, capabilities, and early results. Part 2 covers focusing on scaling challenges and real-world implementation. Each article stands alone while collectively showing how AI transforms medical content management at scale.

Accelerate Enterprise AI Development using Weights & Biases and Amazon Bedrock AgentCore
In this post, we demonstrate how to use Foundation Models (FMs) from Amazon Bedrock and the newly launched Amazon Bedrock AgentCore alongside W&B Weave to help build, evaluate, and monitor enterprise AI solutions. We cover the complete development lifecycle from tracking individual FM calls to monitoring complex agent workflows in production.

Build a multimodal generative AI assistant for root cause diagnosis in predictive maintenance using Amazon Bedrock
In this post, we demonstrate how to implement a predictive maintenance solution using Foundation Models (FMs) on Amazon Bedrock, with a case study of Amazon’s manufacturing equipment within their fulfillment centers. The solution is highly adaptable and can be customized for other industries, including oil and gas, logistics, manufacturing, and healthcare.

Scale visual production using Stability AI Image Services in Amazon Bedrock
This post was written with Alex Gnibus of Stability AI. Stability AI Image Services are now available in Amazon Bedrock, offering ready-to-use media editing capabilities delivered through the Amazon Bedrock API. These image editing tools expand on the capabilities of Stability AI’s Stable Diffusion 3.5 models (SD3.5) and Stable Image Core and Ultra models, which […]

Prompting for precision with Stability AI Image Services in Amazon Bedrock
Amazon Bedrock now offers Stability AI Image Services: 9 tools that improve how businesses create and modify images. The technology extends Stable Diffusion and Stable Image models to give you precise control over image creation and editing. Clear prompts are critical—they provide art direction to the AI system. Strong prompts control specific elements like tone, […]
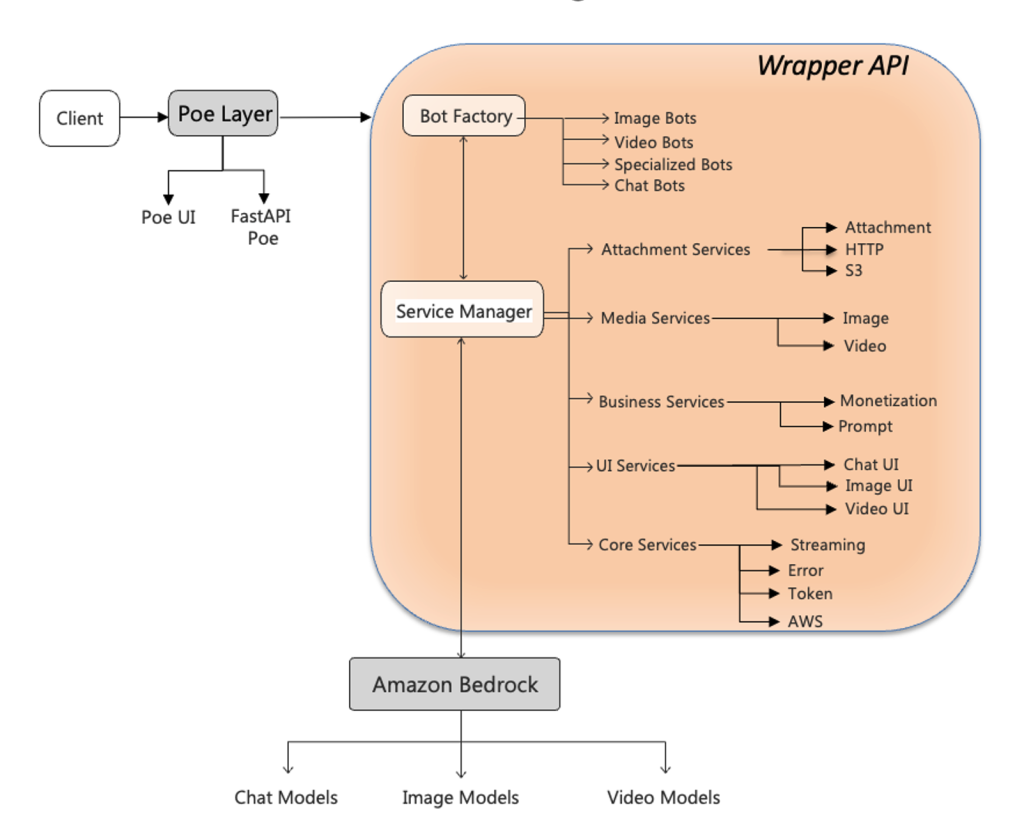
Unified multimodal access layer for Quora’s Poe using Amazon Bedrock
In this post, we explore how the AWS Generative AI Innovation Center and Quora collaborated to build a unified wrapper API framework that dramatically accelerates the deployment of Amazon Bedrock FMs on Quora’s Poe system. We detail the technical architecture that bridges Poe’s event-driven ServerSentEvents protocol with Amazon Bedrock REST-based APIs, demonstrate how a template-based configuration system reduced deployment time from days to 15 minutes, and share implementation patterns for protocol translation, error handling, and multi-modal capabilities.

TII Falcon-H1 models now available on Amazon Bedrock Marketplace and Amazon SageMaker JumpStart
We are excited to announce the availability of the Technology Innovation Institute (TII)’s Falcon-H1 models on Amazon Bedrock Marketplace and Amazon SageMaker JumpStart. With this launch, developers and data scientists can now use six instruction-tuned Falcon-H1 models (0.5B, 1.5B, 1.5B-Deep, 3B, 7B, and 34B) on AWS, and have access to a comprehensive suite of hybrid architecture models that combine traditional attention mechanisms with State Space Models (SSMs) to deliver exceptional performance with unprecedented efficiency.