Artificial Intelligence
Category: Customer Solutions
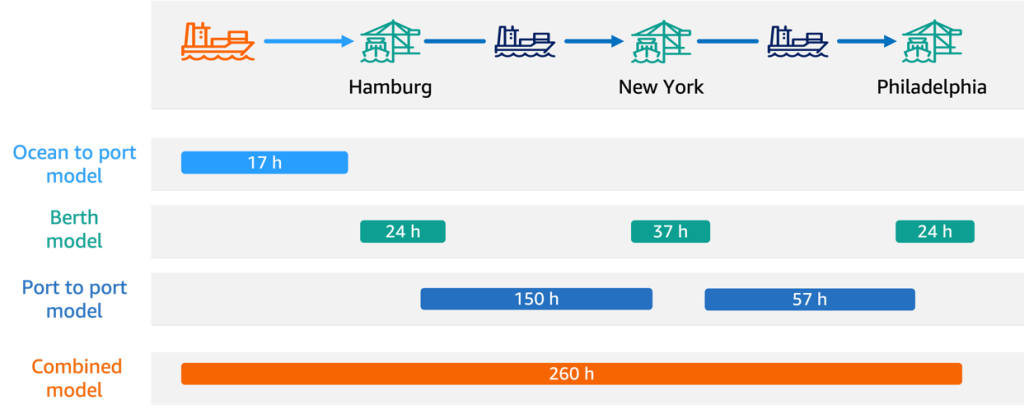
How Hapag-Lloyd improved schedule reliability with ML-powered vessel schedule predictions using Amazon SageMaker
In this post, we share how Hapag-Lloyd developed and implemented a machine learning (ML)-powered assistant predicting vessel arrival and departure times that revolutionizes their schedule planning. By using Amazon SageMaker AI and implementing robust MLOps practices, Hapag-Lloyd has enhanced its schedule reliability—a key performance indicator in the industry and quality promise to their customers.
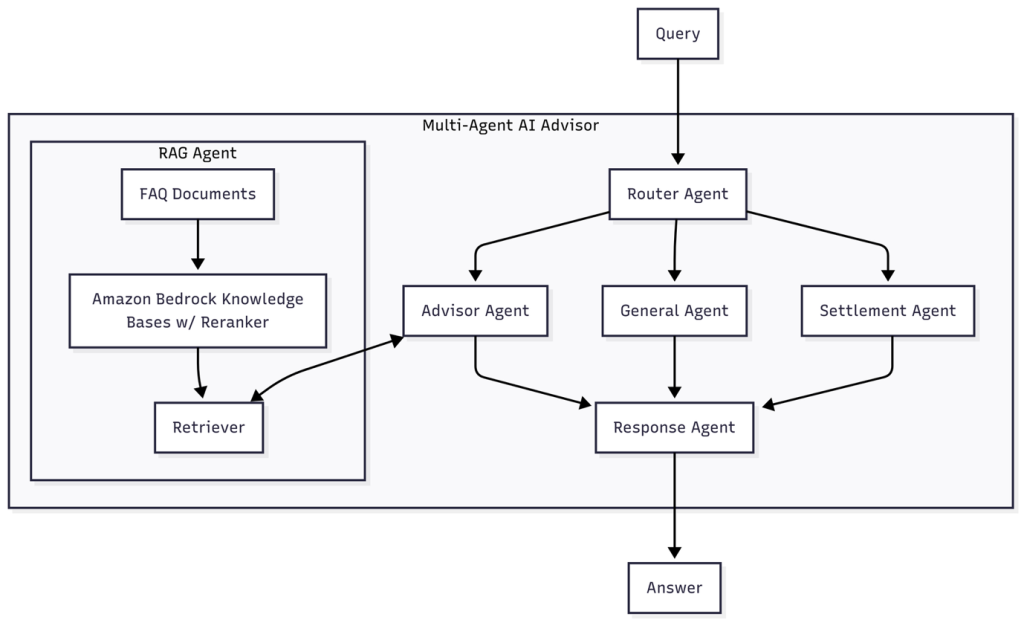
How PropHero built an intelligent property investment advisor with continuous evaluation using Amazon Bedrock
In this post, we explore how we built a multi-agent conversational AI system using Amazon Bedrock that delivers knowledge-grounded property investment advice. We explore the agent architecture, model selection strategy, and comprehensive continuous evaluation system that facilitates quality conversations while facilitating rapid iteration and improvement.

Build Agentic Workflows with OpenAI GPT OSS on Amazon SageMaker AI and Amazon Bedrock AgentCore
In this post, we show how to deploy gpt-oss-20b model to SageMaker managed endpoints and demonstrate a practical stock analyzer agent assistant example with LangGraph, a powerful graph-based framework that handles state management, coordinated workflows, and persistent memory systems.
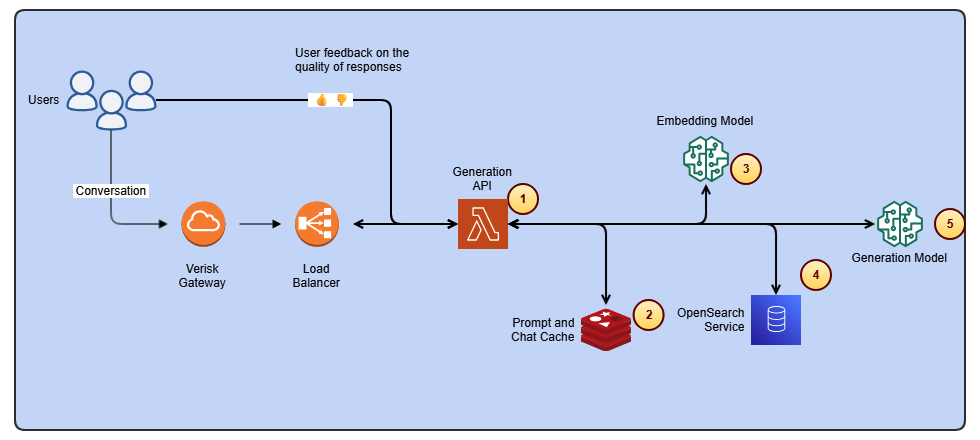
Streamline access to ISO-rating content changes with Verisk rating insights and Amazon Bedrock
In this post, we dive into how Verisk Rating Insights, powered by Amazon Bedrock, large language models (LLM), and Retrieval Augmented Generation (RAG), is transforming the way customers interact with and access ISO ERC changes.
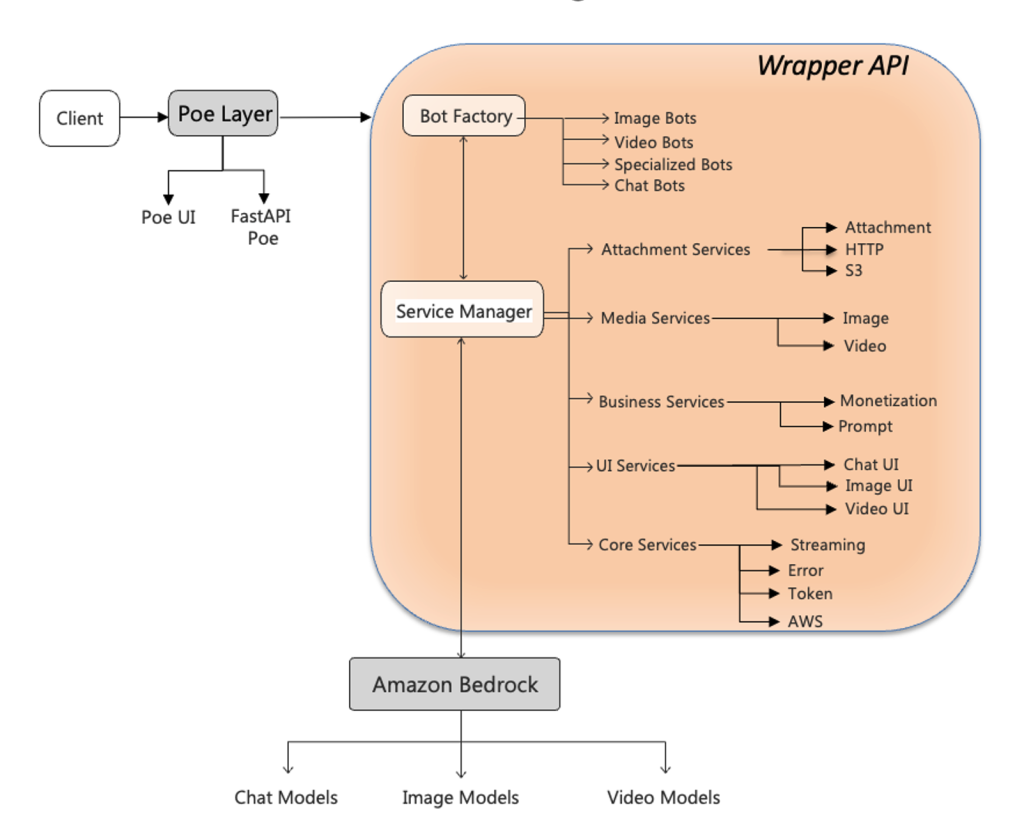
Unified multimodal access layer for Quora’s Poe using Amazon Bedrock
In this post, we explore how the AWS Generative AI Innovation Center and Quora collaborated to build a unified wrapper API framework that dramatically accelerates the deployment of Amazon Bedrock FMs on Quora’s Poe system. We detail the technical architecture that bridges Poe’s event-driven ServerSentEvents protocol with Amazon Bedrock REST-based APIs, demonstrate how a template-based configuration system reduced deployment time from days to 15 minutes, and share implementation patterns for protocol translation, error handling, and multi-modal capabilities.
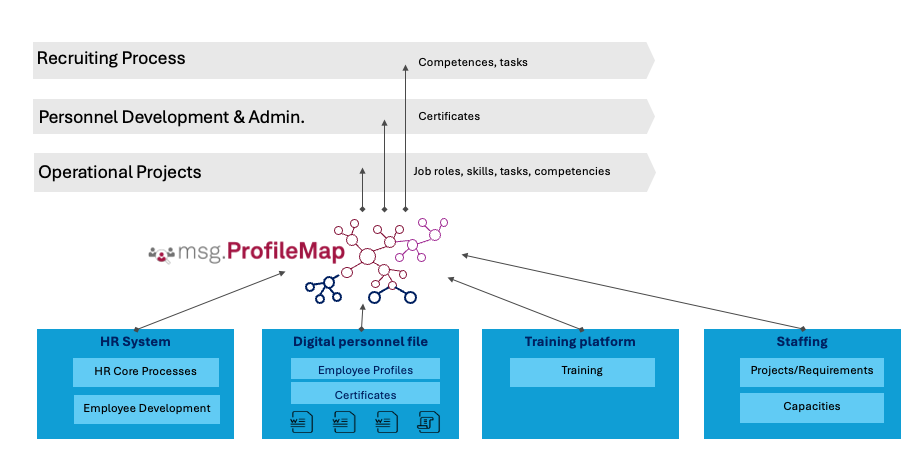
How msg enhanced HR workforce transformation with Amazon Bedrock and msg.ProfileMap
In this post, we share how msg automated data harmonization for msg.ProfileMap, using Amazon Bedrock to power its large language model (LLM)-driven data enrichment workflows, resulting in higher accuracy in HR concept matching, reduced manual workload, and improved alignment with compliance requirements under the EU AI Act and GDPR.
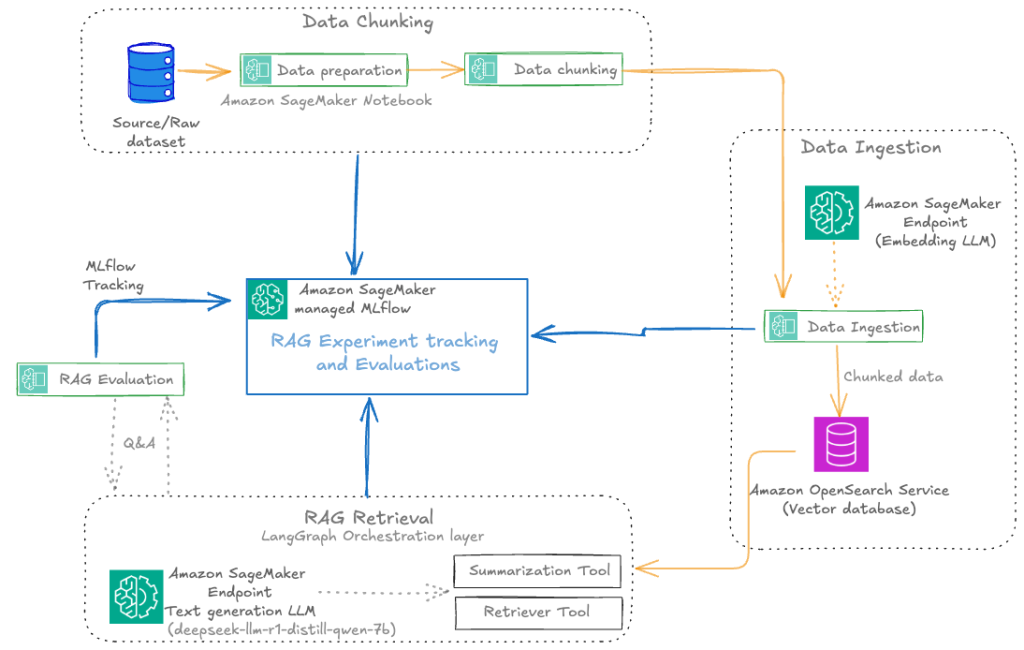
Automate advanced agentic RAG pipeline with Amazon SageMaker AI
In this post, we walk through how to streamline your RAG development lifecycle from experimentation to automation, helping you operationalize your RAG solution for production deployments with Amazon SageMaker AI, helping your team experiment efficiently, collaborate effectively, and drive continuous improvement.
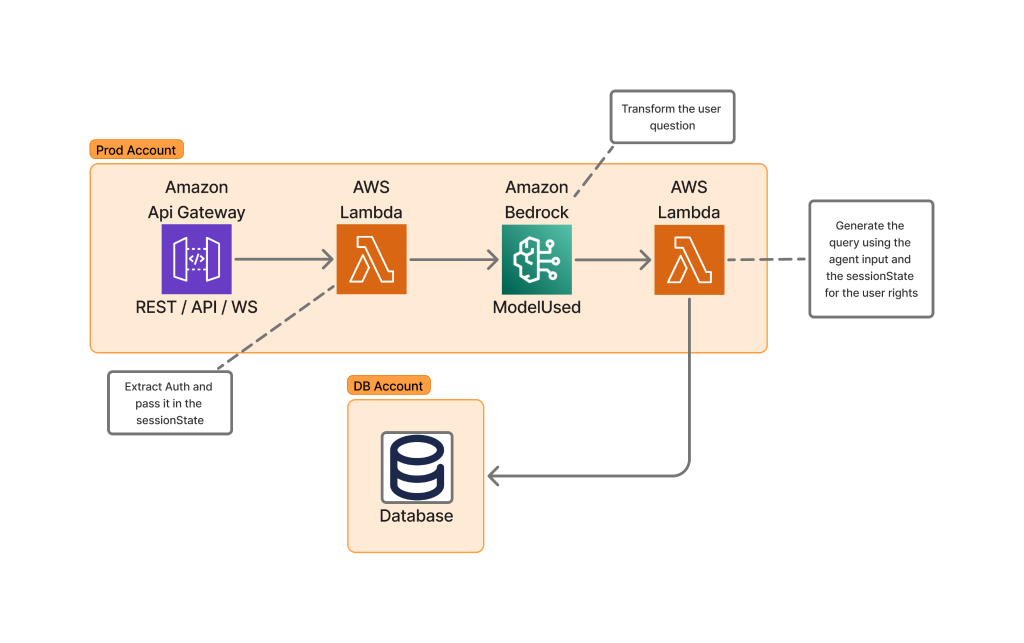
How Skello uses Amazon Bedrock to query data in a multi-tenant environment while keeping logical boundaries
Skello is a leading human resources (HR) software as a service (SaaS) solution focusing on employee scheduling and workforce management. Catering to diverse sectors such as hospitality, retail, healthcare, construction, and industry, Skello offers features including schedule creation, time tracking, and payroll preparation. We dive deep into the challenges of implementing large language models (LLMs) for data querying, particularly in the context of a French company operating under the General Data Protection Regulation (GDPR).
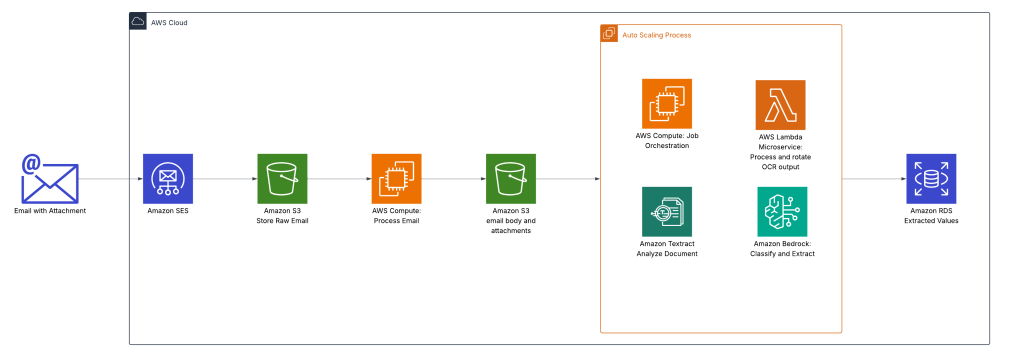
Oldcastle accelerates document processing with Amazon Bedrock
This post explores how Oldcastle partnered with AWS to transform their document processing workflow using Amazon Bedrock with Amazon Textract. We discuss how Oldcastle overcame the limitations of their previous OCR solution to automate the processing of hundreds of thousands of POD documents each month, dramatically improving accuracy while reducing manual effort.
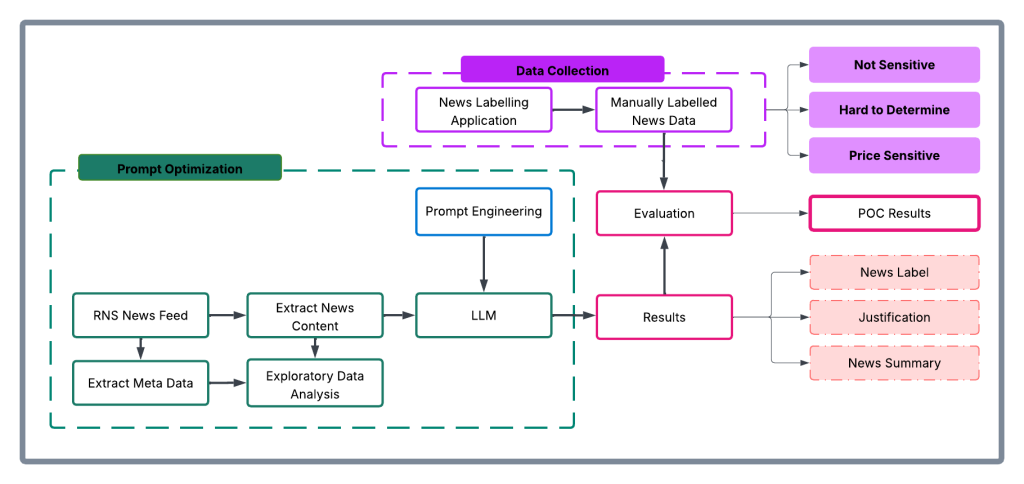
How London Stock Exchange Group is detecting market abuse with their AI-powered Surveillance Guide on Amazon Bedrock
In this post, we explore how London Stock Exchange Group (LSEG) used Amazon Bedrock and Anthropic’s Claude foundation models to build an automated system that aims to significantly improve the efficiency and accuracy of market surveillance operations.