Artificial Intelligence
Chain custom Amazon SageMaker Ground Truth jobs for image processing
Amazon SageMaker Ground Truth supports many different types of labeling jobs, including several image-based labeling workflows like image-level labels, bounding box-specific labels, or pixel-level labeling. For situations not covered by these standard approaches, Ground Truth also supports custom image-based labeling, which allows you to create a labeling workflow with a completely unique UI and associated processing. Beyond that, you can chain different Ground Truth labeling jobs together so that the output of one job acts as the input to another job, to allow even more flexibility in a labeling workflow by breaking the job into multiple stages.
In this post, we show how to chain two custom Ground Truth jobs together to perform advanced image manipulations, including isolating portions of images, and de-skewing images that were photographed from an angle. Additionally, we demonstrate several techniques for augmenting source images, which are helpful for situations where you have a limited number of source images.
Extracting regions of an image
Suppose we’re tasked with creating a machine learning (ML) model that processes an image of a shelving unit and determines whether any of the bins in that shelving unit need restocking. Due to the size of the storage room, a single camera is used to capture images of several shelving units, each from a different angle. The following image is an example of such a shelving unit.

Figure 1: A shelving unit with many bins full, photographed from an angle
For training or inference, we need images of individual bins, rather than the overall shelving unit. The model we’re developing takes an image of a single bin, and return a classification of Empty or Full. This classification feeds into an automated restocking system, allowing us to maintain stock levels at the bin level without the trouble of someone physically checking the levels.
Unfortunately, because the shelf images are taken at an angle, each bin is skewed and has a different size and shape. Because any bin images extracted from the main image are rectangular, the extracted images include undesirable content, as shown in the following image of two adjoining bins.

Figure 2: A closeup of a single bin, which shows two adjoining bins
In this example, we’ve isolated a rectangular region that bounds a given bin, but because the image was taken from an angle, portions of the bins on the left and right are also partially included. Because a rectangular section includes information from other bins, an image like this performs poorly when used for training or for inference.
To solve this, we can select a non-rectangular section of the original image and warp it to create a new image. The following image demonstrates the results of a warp transformation applied to the original image.

Figure 3: Original shelving unit with just the bins isolated, and the image warped to make it orthogonal
This warping accomplishes two tasks. First, we’ve selected just the shelving unit, cropping out the nearby walls, floor, and any other irrelevant areas near the edges of the shelves. Second, the warping of the image results in each bin being more rectangular than the original version.
This warped image doesn’t have any new content—it’s just a distortion of the original image. But by performing this warping, each bin can be selected using a rectangular bounding box, which provides needed consistency, no matter what position a bin is in. Compare the following two bin images: the image on the left is extracted from the original image, and the image on the right is the same bin, extracted from the de-skewed image.

Figure 4: A single bin from the original image (left) compared with the bin from the warped image (right)
The bottom opening of the bin was originally at an angle, and now it’s horizontal. Overall, we’ve reduced the amount of the bin shown, and increased the proportion of the contents of the bin within the image. This improves our ML training process, because each bin image has less superfluous content.
Ground Truth jobs
Each custom Ground Truth labeling job is defined with a web-based user interface and two associated AWS Lambda functions (for more information, see Processing with AWS Lambda). One function runs prior to each image displayed by the UI, and the other runs after the user finishes the labeling job for all the images. Ground Truth offers several pre-made user interfaces (like bounding box-based selection), but you can also create your own custom UI if needed, as we do for this example.
When Ground Truth jobs are chained together, the output of one job is used as the input of another job. For this task, we use two chained jobs to process our images, as illustrated in the following diagram.
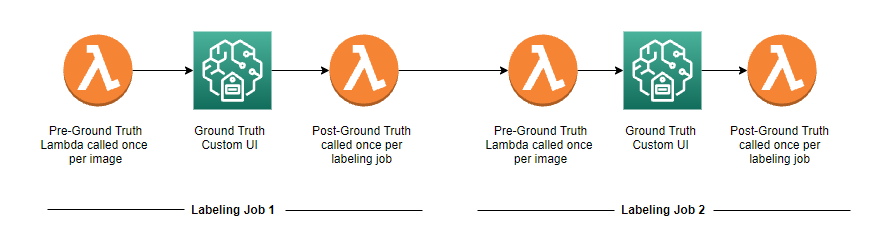
Figure 5: Architecture diagram showing two chained Ground Truth jobs, each with a Pre- and Post- UI Lambda function
Images that need to be labeled are stored in Amazon Simple Storage Solution (Amazon S3). The first Ground Truth job retrieves images from Amazon S3 and displays them one at a time, waiting for the user to specify the four corners of the shelving unit within the image, using a custom UI. When that step is complete, the post-UI Lambda function uses the corner coordinates to warp or de-skew each image, which is then saved to the same S3 bucket that the original image resides in. Note that it’s not necessary to do this during inference—for a situation where the camera is in a fixed location, you can save those corner coordinates for later use during inference.
After the first Ground Truth job has de-skewed the source image, the second job uses simple bounding boxes to label each bin within the de-skewed image. The post-UI Lambda function then extracts the individual bin images, augments them with rotations, flipping, and color and brightness alterations, and writes the resulting data to Amazon S3, where it can be used for model training or other purposes.
You can find example code and deployment instructions in the GitHub repo.
Custom user interface
From a labeler’s perspective, after they log in and select a job, they use the custom UI to select the four corners of a bin.

Figure 6: The custom Ground Truth UI for the first labeling job
For custom Ground Truth user interfaces, a set of custom tags is available, known as Crowd tags. These tags include bounding boxes, lines, points, and other user interface elements that you can use to build a labeling UI. In this case, we use the crowd-polygon tag, which is displayed as a yellow polygon.
After the labeler draws a polygon with four corners on the UI for all source images, they exit the UI by choosing Done. At this point, the post-UI Lambda function is run and each de-skewed image is saved to Amazon S3. When the function is complete, control is passed to the next chained Ground Truth job.
Generally, chained Ground Truth jobs reuse an output manifest file as the input manifest file for the next (chained) labeling job. In this case, we created a new image, so we modify the pre-UI Lambda function so it passes in the correct (de-skewed) file name, rather than the original, skewed image file name.
The second job in the chain uses the bounding box-based labeling functionality that is built in to Ground Truth. The bounding boxes don’t cover the entire contents of each bin, but they do cover the openings of the bins. This provides enough data to create a model to detect whether a bin is full or empty.

Figure 7: De-skewed image with bounding boxes from the second chained Ground Truth labeling job
After the labeler selects all the bins, they exit the UI by choosing Done. At this point, the post-UI Lambda function runs and crops out each bin image, makes variations of it for image augmentation purposes, and saves the variations into a folder structure in Amazon S3 based on classification. The top level of the folder structure is named training_data, with two subfolders: empty and full. Each subfolder contains images of bins that are either empty or full, suitable for use in model training.
Image augmentation
Image augmentation is a technique sometimes used in image-based ML workloads. It’s especially helpful when the number of source images is low, or limited in the number of variants. Typically, image augmentation is performed by taking a source image and creating multiple variants of it, altering factors like brightness and contrast, coloring, and even cropping or rotating images. These variations help the resulting model be more robust and capable of handling images that are dissimilar to the original training images.
In this example, we use image augmentation methods in the post-UI Lambda function of the second Ground Truth job. The labeler has specified the bounding boxes for each bin image in the Ground Truth UI, and that data is used to extract portions of the overall image. Those extracted portions are of the individual bins, and these smaller images are used as input into our image augmentation process.
In our case, we create 14 variants of each bin image, with variations of brightness, contrast, and sharpness, as well horizontal flipping combined with these variations. With this approach, a single source image of a shelving unit with 24 bins generates 14 variants for each bin image, for a total of 336 images that can be used for training a model. The following shows an original bin image (upper left) and each of its variants.

Conclusion
Custom Ground Truth jobs provide a great deal of flexibility, and using them with images allows advanced functionality like cropping and de-skewing images, as well as performing custom image augmentation. The supplied Crowd HTML tags support many different labeling approaches like polygons, lines, text boxes, modal alerts, key point placement, and others. Combined with the power of pre-UI and post-UI Lambda functions, a custom Ground Truth job allows you to construct complex labeling jobs to support a wide variety of use cases, and combining different custom jobs by chaining them together provides even more options.
You can use the GitHub repo associated with this post as a starting point for your own chained image labeling jobs. You can also extend the code to support additional image augmentation methods (like cropping or rotating the source images), or modify it to fit your particular use case.
To learn more about chained Ground Truth jobs, see Chaining Labeling Jobs.
For more information about the Crowd tags you can use in the Ground Truth UI, see Crowd HTML Elements Reference.
About the Author
 Greg Sommerville is a Senior Prototyping Architect on the AWS Envision Engineering Americas Prototyping team, where he helps AWS customers implement innovative solutions to challenging problems with machine learning, IoT and serverless technologies. He lives in Ann Arbor, Michigan and enjoys practicing yoga, catering to his dogs, and playing poker.
Greg Sommerville is a Senior Prototyping Architect on the AWS Envision Engineering Americas Prototyping team, where he helps AWS customers implement innovative solutions to challenging problems with machine learning, IoT and serverless technologies. He lives in Ann Arbor, Michigan and enjoys practicing yoga, catering to his dogs, and playing poker.