Artificial Intelligence
Computer vision using synthetic datasets with Amazon Rekognition Custom Labels and Dassault Systèmes 3DEXCITE
This is a post co-written with Bernard Paques, CTO of Storm Reply, and Karl Herkt, Senior Strategist at Dassault Systèmes 3DExcite.
While computer vision can be crucial to industrial maintenance, manufacturing, logistics, and consumer applications, its adoption is limited by the manual creation of training datasets. The creation of labeled pictures in an industrial context is mainly done manually, which creates limited recognition capabilities, doesn’t scale, and results in labor costs and delays on business value realization. This goes against the business agility provided by rapid iterations in product design, product engineering, and product configuration. This process doesn’t scale for complex products such as cars, airplanes, or modern buildings, because in those scenarios every labeling project is unique (related to unique products). As result, computer vision technology can’t be easily applied to large-scale unique projects without a big effort in data preparation, sometimes limiting use case delivery.
In this post, we present a novel approach where highly specialized computer vision systems are created from design and CAD files. We start with the creation of visually correct digital twins and the generation of synthetic labeled images. Then we push these images to Amazon Rekognition Custom Labels to train a custom object detection model. By using existing intellectual property with software, we’re making computer vision affordable and relevant to a variety of industrial contexts.
The customization of recognition systems helps drive business outcomes
Specialized computer vision systems that are produced from digital twins have specific merits, which can be illustrated in the following use cases:
- Traceability for unique products – Airbus, Boeing, and other aircraft makers assign unique Manufacturer Serial Numbers (MSNs) to every aircraft they produce. This is managed throughout the entire production process, in order to generate airworthiness documentation and get permits to fly. A digital twin (a virtual 3D model representing a physical product) can be derived from the configuration of each MSN, and generates a distributed computer vision system that tracks the progress of this MSN across industrial facilities. Custom recognition automates the transparency given to airlines, and replaces most checkpoints performed manually by airlines. Automated quality assurance on unique products can apply to aircrafts, cars, buildings, and even craft productions.
- Contextualized augmented reality – Professional-grade computer vision systems can scope limited landscapes, but with higher discrimination capabilities. For example, in industrial maintenance, finding a screwdriver in a picture is useless; you need to identify the screwdriver model or even its serial number. In such bounded contexts, custom recognition systems outperform generic recognition systems because they’re more relevant in their findings. Custom recognition systems enable precise feedback loops via dedicated augmented reality delivered in HMI or in mobile devices.
- End-to-end quality control – With system engineering, you can create digital twins of partial constructs, and generate computer vision systems that adapt to the various phases of manufacturing and production processes. Visual controls can be intertwined with manufacturing workstations, enabling end-to-end inspection and early detection of defects. Custom recognition for end-to-end inspection effectively prevents the cascading of defects to assembly lines. Reducing the rejection rate and maximizing the production output is the ultimate goal.
- Flexible quality inspection – Modern quality inspection has to adapt to design variations and flexible manufacturing. Variations in design come from feedback loops on product usage and product maintenance. Flexible manufacturing is a key capability for a make-to-order strategy, and aligns with the lean manufacturing principle of cost-optimization. By integrating design variations and configuration options in digital twins, custom recognition enables the dynamic adaptation of computer vision systems to the production plans and design variations.
Enhance computer vision with Dassault Systèmes 3DEXCITE powered by Amazon Rekognition
Within Dassault Systèmes, a company with deep expertise in digital twins that is also the second largest European software editor, the 3DEXCITE team is exploring a different path. As explained by Karl Herkt, “What if a neural model trained from synthetic images could recognize a physical product?” 3DEXCITE has solved this problem by combining their technology with the AWS infrastructure, proving the feasibility of this peculiar approach. It’s also known as cross-domain object detection, where the detection model learns from labeled images from the source domain (synthetic images) and makes predictions to the unlabeled target domain (physical components).
Dassault Systèmes 3DEXCITE and the AWS Prototyping team have joined forces to build a demonstrator system that recognizes parts of an industrial gearbox. This prototype was built in 3 weeks, and the trained model achieved a 98% F1 score. The recognition model has been trained entirely from a software pipeline, which doesn’t feature any pictures of a real part. From design and CAD files of an industrial gearbox, 3DEXCITE has created visually correct digital twins. They also generated thousands of synthetic labeled images from the digital twins. Then they used Rekognition Custom Labels to train a highly specialized neural model from these images and provided a related recognition API. They built a website to enable recognition from any webcam of one physical part of the gearbox.
Amazon Rekognition is an AI service that uses deep learning technology to allow you to extract meaningful metadata from images and videos—including identifying objects, people, text, scenes, activities, and potentially inappropriate content—with no machine learning (ML) expertise required. Amazon Rekognition also provides highly accurate facial analysis and facial search capabilities that you can use to detect, analyze, and compare faces for a wide variety of user verification, people counting, and safety use cases. Lastly, with Rekognition Custom Labels, you can use your own data to build object detection and image classification models.
The combination of Dassault Systèmes technology for the generation of synthetic labeled images with Rekognition Custom Labels for computer vision provides a scalable workflow for recognition systems. Ease of use is a significant positive factor here because adding Rekognition Custom Labels to the overall software pipeline isn’t difficult—it’s as simple as integrating an API into a workflow. No need to be an ML scientist; simply send captured frames to AWS and receive a result that you can enter into a database or display in a web browser.
This further underscores the dramatic improvement over manual creation of training datasets. You can achieve better results faster and with greater accuracy, without the need for costly, unnecessary work hours. With so many potential use cases, the combination of Dassault Systèmes and Rekognition Custom Labels has the potential to provide today’s businesses with significant and immediate ROI.
Solution overview
The first step in this solution is to render the images that create the training dataset. This is done by the 3DEXCITE platform. We can generate the labeling data programmatically by using scripts. Amazon SageMaker Ground Truth provides an annotation tool to easily label images and videos for classification and object detection tasks. To train a model in Amazon Rekognition, the labeling file needs to comply with Ground Truth format. These labels are in JSON, including information such as image size, bounding box coordinates, and class IDs.
Then upload the synthetic images and the manifest to Amazon Simple Storage Service (Amazon S3), where Rekognition Custom Labels can import them as components of the training dataset.
To let Rekognition Custom Labels test the models versus a set of real component images, we provide a set of pictures of the real engine parts taken with a camera and upload them to Amazon S3 to use as the testing dataset.
Finally, Rekognition Custom Labels trains the best object detection model using the synthetic training dataset and testing dataset composed of pictures of real objects, and creates the endpoint with the model we can use to run object recognition in our application.
The following diagram illustrates our solution workflow:
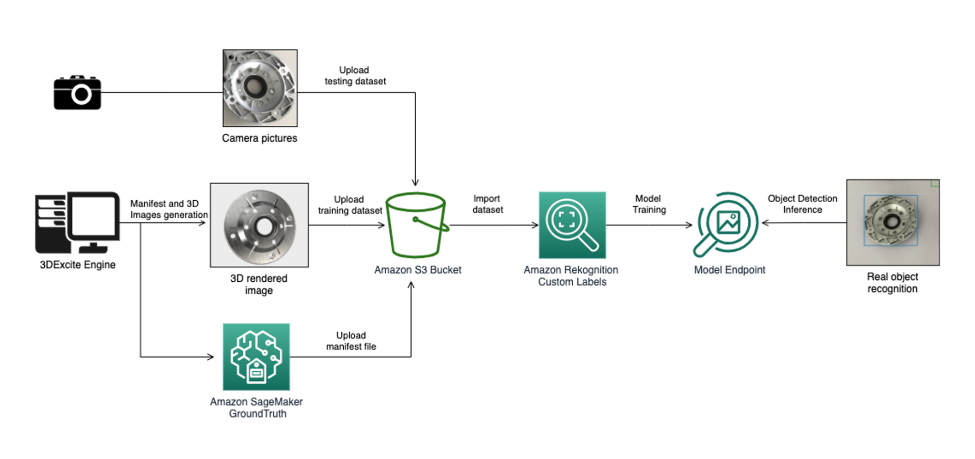
Create synthetic images
The synthetic images are generated from the 3Dexperience platform, which is a product of Dassault Systèmes. This platform allows you to create and render photorealistic images based on the object’s CAD (computer-aided design) file. We can generate thousands of variants in a few hours by changing image transformation configurations on the platform.
In this prototype, we selected the following five visually distinct gearbox parts for object detection. They include a gear housing, gear ratio, bearing cover, flange, and worm gear.

We used the following data augmentation methods to increase the image diversity, and make the synthetic data more photorealistic. It helps reduce the model generalization error.
- Zoom in/out – This method randomly zooms in or out the object in images.
- Rotation – This method rotates the object in images, and it looks like a virtual camera takes random pictures of the object from 360-degree angles.
- Improve the look and feel of the material – We identified that for some gear parts the look of the material is less realistic in the initial rendering. We added a metallic effect to improve the synthetic images.
- Use different lighting settings – In this prototype, we simulated two lighting conditions:
- Warehouse – A realistic light distribution. Shadows and reflections are possible.
- Studio – A homogeneous light is put all around the object. This is not realistic but there is no shadows or reflections.
- Use a realistic position of how the object is viewed in real time – In real life, some objects, such as a flange and bearing cover, are generally placed on a surface, and the model is detecting the objects based on the top and bottom facets. Therefore, we removed the training images that show the thin edge of the parts, also called the edge position, and increased the images of objects in a flat position.
- Add multiple objects in one image – In real-life scenarios, multiple gear parts could all appear in one view, so we prepared images that contain multiple gear parts.
On the 3Dexperience platform, we can apply different backgrounds to the images, which can help increase the image diversity further. Due to time limitation, we didn’t implement this in this prototype.

Import the synthetic training dataset
In ML, labeled data means the training data is annotated to show the target, which is the answer you want your ML model to predict. The labeled data that can be consumed by Rekognition Custom Labels should be complied with Ground Truth manifest file requirements. A manifest file is made of one or more JSON lines; each line contains the information for a single image. For synthetic training data, the labeling information can be generated programmatically based on the CAD file and image transformation configurations we mentioned earlier, which saves significant manual effort of labeling work. For more information about the requirements for labeling file formats, refer to Create a manifest file and Object localization in manifest files. The following is an example of image labeling:
After the manifest file is prepared, we upload it to a S3 bucket, and then create a training dataset in Rekognition Custom Labels by selecting the option Import images labeled by Amazon SageMaker Ground Truth.
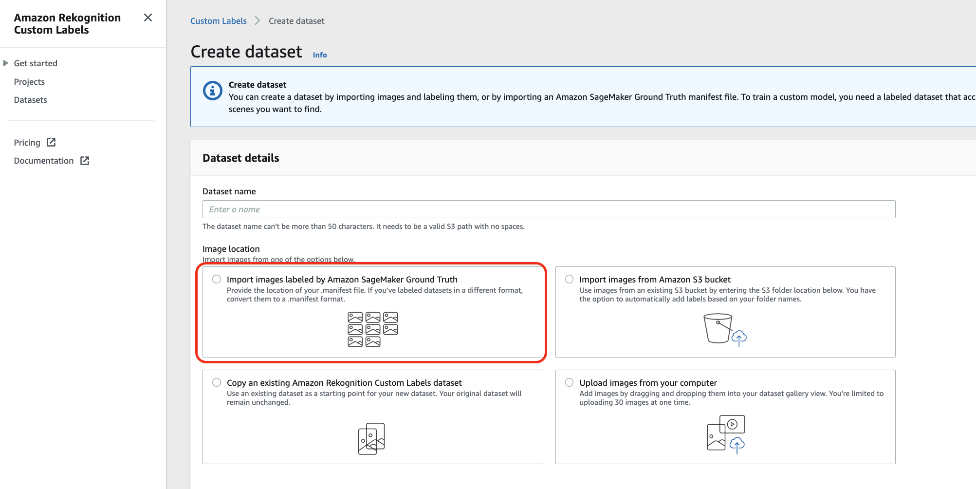
After the manifest file is imported, we can view the labeling information visually on the Amazon Rekognition console. This helps us confirm that the manifest file is generated and imported. More specifically, the bounding boxes should align with the objects in images, and the objects’ class IDs should be assigned correctly.
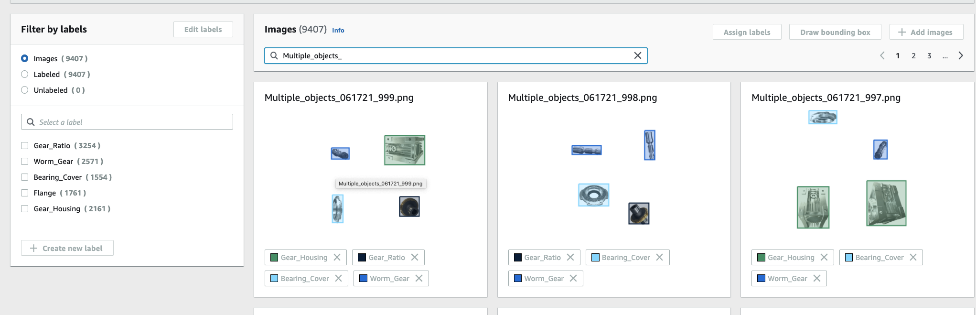
Create the testing dataset
The test images are captured in real life with a phone or camera from different angles and lighting conditions, because we want to validate the model accuracy, which we trained using synthetic data, against the real-life scenarios. You can upload these test images to a S3 bucket, and then import them as datasets in Rekognition Custom Labels. Or you can upload them directly to datasets from your local machine.
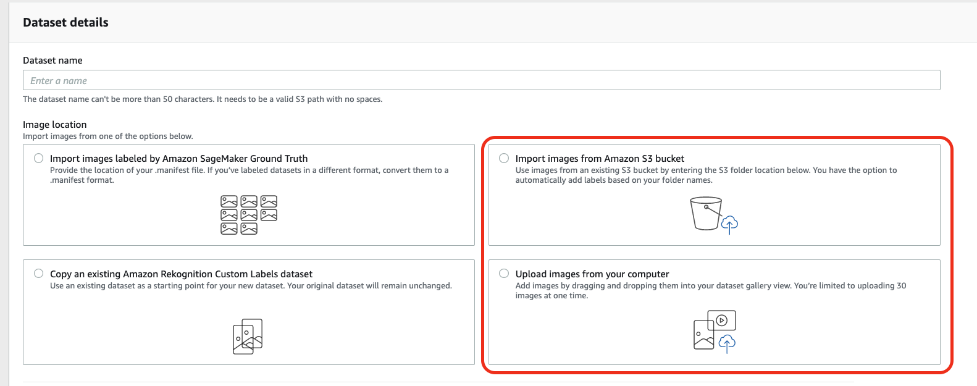
Rekognition Custom Labels provides built-in image annotation capability, which has a similar experience as Ground Truth. You can start the labeling work when test data is imported. For an object detection use case, the bounding boxes should be created tightly around the objects of interest, which helps the model learn precisely the regions and pixels that belong to the target objects. In addition, you should label every instance of the target objects in all images, even those that are partially out of view or occluded by other objects, otherwise the model predicts more false negatives.

Create the cross-domain object detection model
Rekognition Custom Labels is a fully managed service; you just need to provide the train and test datasets. It trains a set of models and chooses the best-performing one based on the data provided. In this prototype, we prepare the synthetic training datasets iteratively by experimenting with different combinations of the image augmentation methods that we mentioned earlier. One model is created for each training dataset in Rekognition Custom Labels, which allows us to compare and find the optimal training dataset for this use case specifically. Each model has the minimum number of training images, contains good image diversity, and provides the best model accuracy. After 15 iterations, we achieved an F1 score of 98% model accuracy using around 10,000 synthetic training images, which is 2,000 images per object on average.
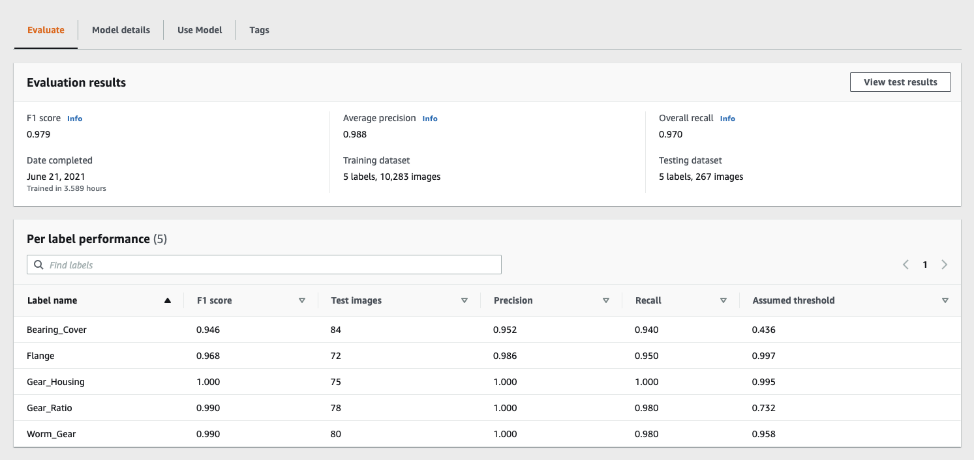
Results of model inference
The following image shows the Amazon Rekognition model being used in a real-time inference application. All components are detected correctly with high confidence.
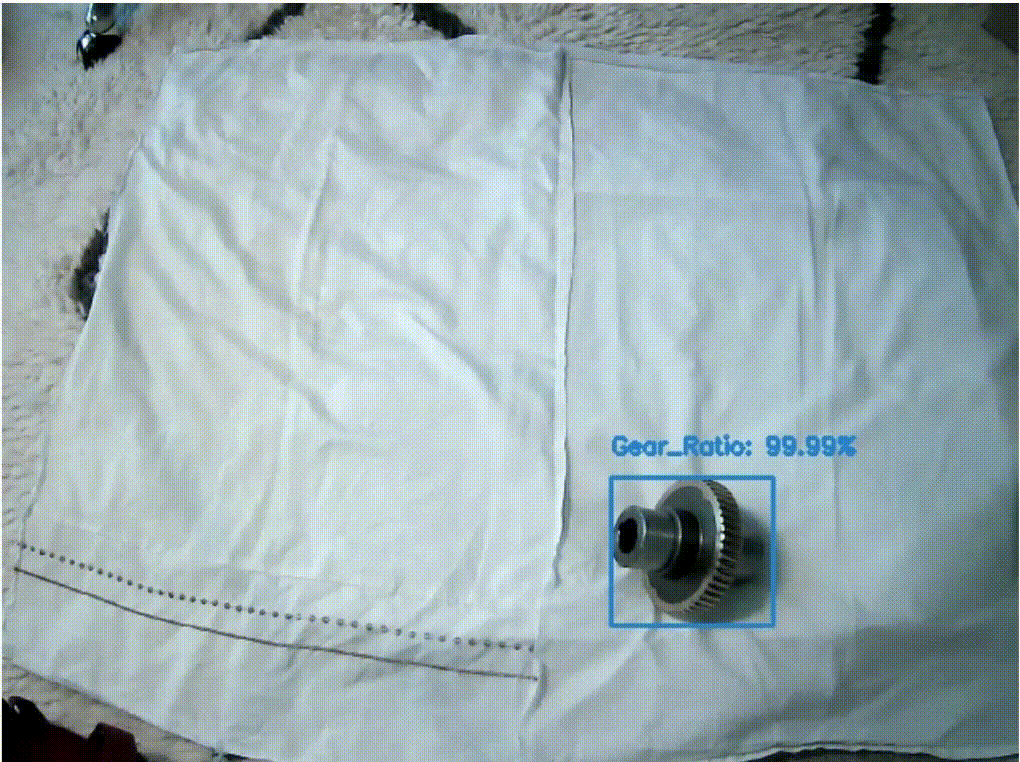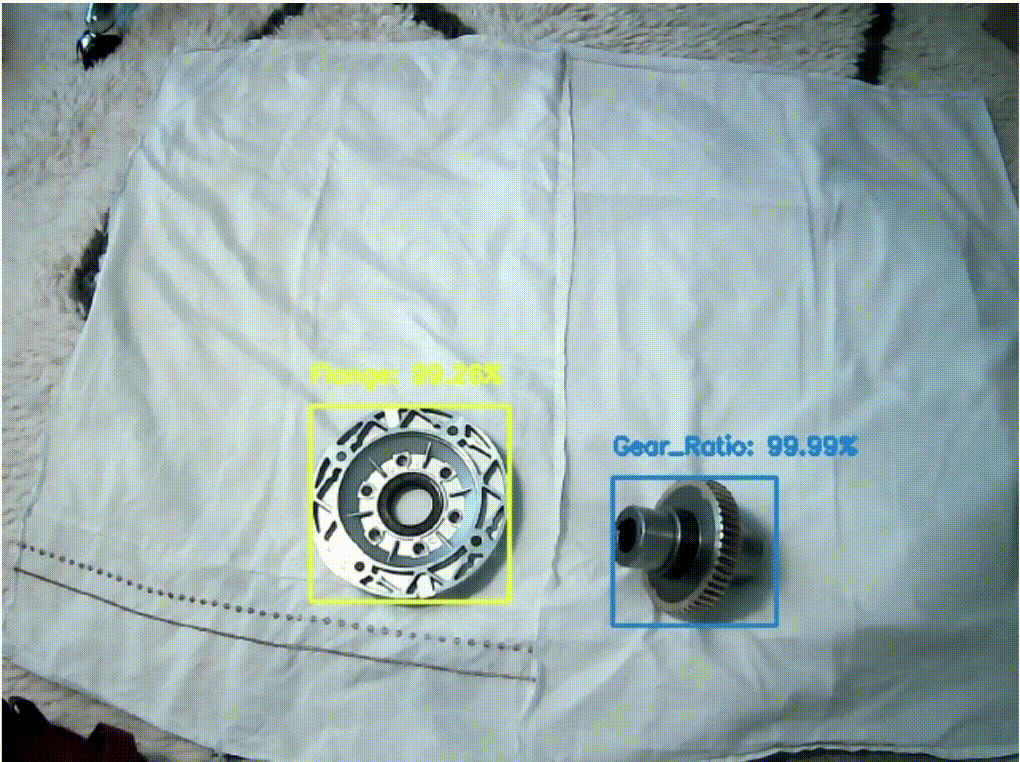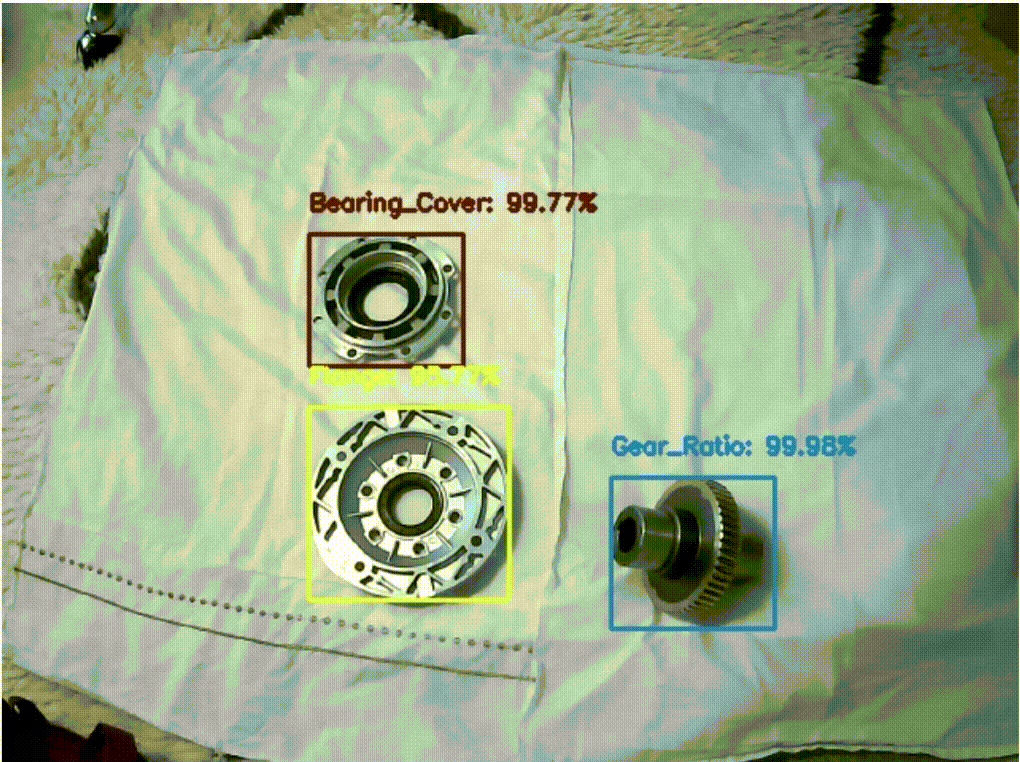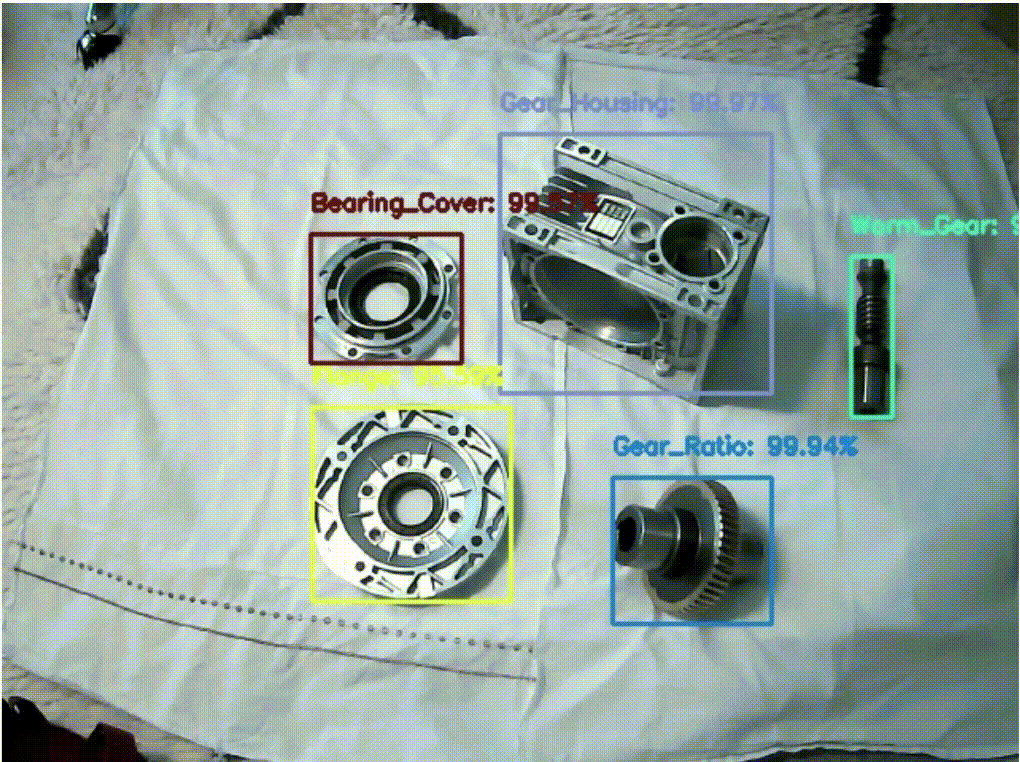
Conclusion
In this post, we demonstrated how to train a computer vision model on purely synthetic images, and how the model can still reliably recognize real-world objects. This saves significant manual effort collecting and labeling the training data. With this exploration, Dassault Systèmes is expanding the business value of the 3D product models created by designers and engineers, because you can now use CAD, CAE, and PLM data in recognition systems for images in the physical world.
For more information about Rekognition Custom Labels key features and use cases, see Amazon Rekognition Custom Labels. If your images aren’t labeled natively with Ground Truth, which was the case for this project, see Creating a manifest file to convert your labeling data to the format that Rekognition Custom Labels can consume.
About the Authors
 Woody Borraccino is currently a Senior Machine Learning Specialist Solution Architect at AWS. Based in Milan, Italy, Woody worked on software development before joining AWS back in 2015, where he growth is passion for Computer Vision and Spatial Computing (AR/VR/XR) technologies. His passion is now focused on the metaverse innovation. Follow him on Linkedin.
Woody Borraccino is currently a Senior Machine Learning Specialist Solution Architect at AWS. Based in Milan, Italy, Woody worked on software development before joining AWS back in 2015, where he growth is passion for Computer Vision and Spatial Computing (AR/VR/XR) technologies. His passion is now focused on the metaverse innovation. Follow him on Linkedin.
 Ying Hou, PhD, is a Machine Learning Prototyping Architect at AWS. Her main areas of interests are Deep Learning, Computer Vision, NLP and time series data prediction. In her spare time, she enjoys reading novels and hiking in national parks in the UK.
Ying Hou, PhD, is a Machine Learning Prototyping Architect at AWS. Her main areas of interests are Deep Learning, Computer Vision, NLP and time series data prediction. In her spare time, she enjoys reading novels and hiking in national parks in the UK.
 Bernard Paques is currently CTO of Storm Reply focused on industrial solutions deployed on AWS. Based in Paris, France, Bernard worked previously as a Principal Solution Architect and as a Principal Consultant at AWS. His contributions to enterprise modernization cover AWS for Industrial, AWS CDK, and these now stem into Green IT and voice-based systems. Follow him on Twitter.
Bernard Paques is currently CTO of Storm Reply focused on industrial solutions deployed on AWS. Based in Paris, France, Bernard worked previously as a Principal Solution Architect and as a Principal Consultant at AWS. His contributions to enterprise modernization cover AWS for Industrial, AWS CDK, and these now stem into Green IT and voice-based systems. Follow him on Twitter.
 Karl Herkt is currently Senior Strategist at Dassault Systèmes 3DExcite. Based in Munich, Germany, he creates innovative implementations of computer vision that deliver tangible results. Follow him on LinkedIn.
Karl Herkt is currently Senior Strategist at Dassault Systèmes 3DExcite. Based in Munich, Germany, he creates innovative implementations of computer vision that deliver tangible results. Follow him on LinkedIn.