Artificial Intelligence
Exafunction supports AWS Inferentia to unlock best price performance for machine learning inference
Across all industries, machine learning (ML) models are getting deeper, workflows are getting more complex, and workloads are operating at larger scales. Significant effort and resources are put into making these models more accurate since this investment directly results in better products and experiences. On the other hand, making these models run efficiently in production is a non-trivial undertaking that’s often overlooked, despite being key to achieving performance and budget goals. In this post we cover how Exafunction and AWS Inferentia work together to unlock easy and cost-efficient deployment for ML models in production.
Exafunction is a start-up focused on enabling companies to perform ML at scale as efficiently as possible. One of their products is ExaDeploy, an easy-to-use SaaS solution to serve ML workloads at scale. ExaDeploy efficiently orchestrates your ML workloads across mixed resources (CPU and hardware accelerators) to maximize resource utilization. It also takes care of auto scaling, compute colocation, network issues, fault tolerance, and more, to ensure efficient and reliable deployment. AWS Inferentia-based Amazon EC2 Inf1 instances are purpose built to deliver the lowest cost-per-inference in the cloud. ExaDeploy now supports Inf1 instances, which allows users to get both the hardware-based savings of accelerators and the software-based savings of optimized resource virtualization and orchestration at scale.
Solution overview
How ExaDeploy solves for deployment efficiency
To ensure efficient utilization of compute resources, you need to consider proper resource allocation, auto scaling, compute co-location, network cost and latency management, fault tolerance, versioning and reproducibility, and more. At scale, any inefficiencies materially affect costs and latency, and many large companies have addressed these inefficiencies by building internal teams and expertise. However, it’s not practical for most companies to assume this financial and organizational overhead of building generalizable software that isn’t the company’s desired core competency.
ExaDeploy is designed to solve these deployment efficiency pain points, including those seen in some of the most complex workloads such as those in Autonomous Vehicle and natural language processing (NLP) applications. On some large batch ML workloads, ExaDeploy has reduced costs by over 85% without sacrificing on latency or accuracy, with integration time as low as one engineer-day. ExaDeploy has been proven to auto scale and manage thousands of simultaneous hardware accelerator resource instances without any system degradation.
Key features of ExaDeploy include:
- Runs in your cloud: None of your models, inputs, or outputs ever leave your private network. Continue to use your cloud provider discounts.
- Shared accelerator resources: ExaDeploy optimizes the accelerators used by enabling multiple models or workloads to share accelerator resources. It can also identify if multiple workloads are deploying the same model, and then share the model across those workloads, thereby optimizing the accelerator used. Its automatic rebalancing and node draining capabilities maximize utilization and minimize costs.
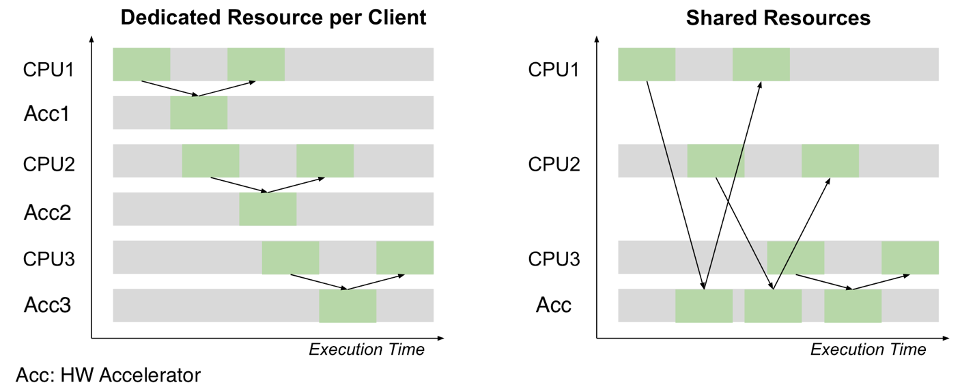
- Scalable serverless deployment model: ExaDeploy auto scales based on accelerator resource saturation. Dynamically scale down to 0 or up to thousands of resources.
- Support for a variety of computation types: You can offload deep learning models from all major ML frameworks as well as arbitrary C++ code, CUDA kernels, custom ops, and Python functions.
- Dynamic model registration and versioning: New models or model versions can be registered and run without having to rebuild or redeploy the system.
- Point-to-point execution: Clients connect directly to remote accelerator resources, which enables low latency and high throughput. They can even store the state remotely.
- Asynchronous execution: ExaDeploy supports asynchronous execution of models, which allows clients to parallelize local computation with remote accelerator resource work.
- Fault-tolerant remote pipelines: ExaDeploy allows clients to dynamically compose remote computations (models, preprocessing, etc.) into pipelines with fault tolerance guarantee. The ExaDeploy system handles pod or node failures with automatic recovery and replay, so that the developers never have to think about ensuring fault tolerance.
- Out-of-the-box monitoring: ExaDeploy provides Prometheus metrics and Grafana dashboards to visualize accelerator resource usage and other system metrics.
ExaDeploy supports AWS Inferentia
AWS Inferentia-based Amazon EC2 Inf1 instances are designed for deep learning specific inference workloads. These instances provide up to 2.3x throughput and up to 70% cost saving compared to the current generation of GPU inference instances.
ExaDeploy now supports AWS Inferentia, and together they unlock the increased performance and cost-savings achieved through purpose-built hardware-acceleration and optimized resource orchestration at scale. Let’s look at the combined benefits of ExaDeploy and AWS Inferentia by considering a very common modern ML workload: batched, mixed-compute workloads.
Hypothetical workload characteristics:
- 15 ms of CPU-only pre-process/post-process
- Model inference (15 ms on GPU, 5 ms on AWS Inferentia)
- 10 clients, each make request every 20 ms
- Approximate relative cost of CPU:Inferentia:GPU is 1:2:4 (Based on Amazon EC2 On-Demand pricing for c5.xlarge, inf1.xlarge, and g4dn.xlarge)
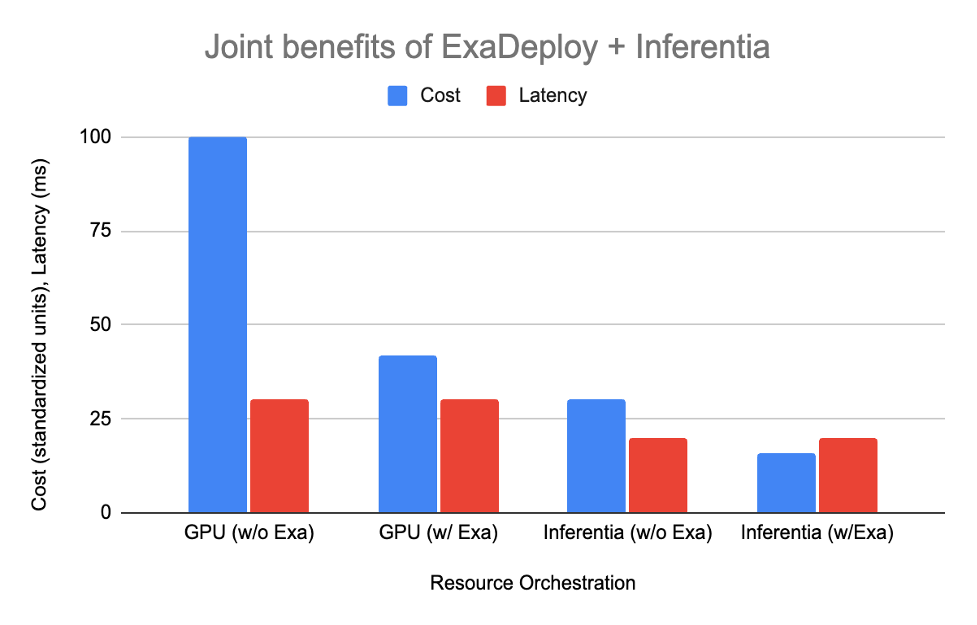
The table below shows how each of the options shape up:
| Setup | Resources needed | Cost | Latency |
| GPU without ExaDeploy | 2 CPU, 2 GPU per client (total 20 CPU, 20 GPU) | 100 | 30 ms |
| GPU with ExaDeploy | 8 GPUs shared across 10 clients, 1 CPU per client | 42 | 30 ms |
| AWS Inferentia without ExaDeploy | 1 CPU, 1 AWS Inferentia per client (total 10 CPU, 10 Inferentia) | 30 | 20 ms |
| AWS Inferentia with ExaDeploy | 3 AWS Inferentia shared across 10 clients, 1 CPU per client | 16 | 20 ms |
ExaDeploy on AWS Inferentia example
In this section, we go over the steps to configure ExaDeploy through an example with inf1 nodes on a BERT PyTorch model. We saw an average throughput of 1140 samples/sec for the bert-base model, which demonstrates that little to no overhead was introduced by ExaDeploy for this single model, single workload scenario.
Step 1: Set up an Amazon Elastic Kubernetes Service (Amazon EKS) cluster
An Amazon EKS cluster can be brought up with our Terraform AWS module. For our example, we used an inf1.xlarge for AWS Inferentia.
Step 2: Set up ExaDepoy
The second step is to set up ExaDeploy. In general, the deployment of ExaDeploy on inf1 instances is straightforward. Setup mostly follows the same procedure as it does on graphics processing unit (GPU) instances. The primary difference is to change the model tag from GPU to AWS Inferentia and recompile the model. For example, moving from g4dn to inf1 instances using ExaDeploy’s application programming interfaces (APIs) required only approximately 10 lines of code to be changed.
- One simple method is to use Exafunction’s Terraform AWS Kubernetes module or Helm chart. These deploy the core ExaDeploy components to run in the Amazon EKS cluster.
- Compile model into a serialized format (e.g., TorchScript, TF saved models, ONNX, etc).. For AWS Inferentia, we followed this tutorial.
- Register the compiled model in ExaDeploy’s module repository.
- Prepare the data for the model (i.e., not
ExaDeploy-specific).
- Run the model remotely from the client.
ExaDeploy and AWS Inferentia: Better together
AWS Inferentia is pushing the boundaries of throughput for model inference and delivering lowest cost-per-inference in the cloud. That being said, companies need the proper orchestration to enjoy the price-performance benefits of Inf1 at scale. ML serving is a complex problem that, if addressed in-house, requires expertise that’s removed from company goals and often delays product timelines. ExaDeploy, which is Exafunction’s ML deployment software solution, has emerged as the industry leader. It serves even the most complex ML workloads, while providing smooth integration experiences and support from a world-class team. Together, ExaDeploy and AWS Inferentia unlock increased performance and cost-savings for inference workloads at scale.
Conclusion
In this post, we showed you how Exafunction supports AWS Inferentia for performance ML. For more information on building applications with Exafunction, visit Exafunction. For best practices on building deep learning workloads on Inf1, visit Amazon EC2 Inf1 instances.
About the Authors
Nicholas Jiang, Software Engineer, Exafunction
Jonathan Ma, Software Engineer, Exafunction
Prem Nair, Software Engineer, Exafunction
Anshul Ramachandran, Software Engineer, Exafunction
Shruti Koparkar, Sr. Product Marketing Manager, AWS
Max Liu, Principal Specialist, AWS
Jianying Lang, Principal Solution Architect, AWS
Kamran Khan, Sr Technical Product Manager, AWS