Artificial Intelligence
How Wix empowers customer care with AI capabilities using Amazon Transcribe
With over 200 million users worldwide, Wix is a leading cloud-based development platform for building fully personalized, high-quality websites. Wix makes it easy for anyone to create a beautiful and professional web presence. When Wix started, it was easy to understand user sentiment and identify product improvement opportunities because the user base was small. Such information could include the quality of support operations, product issues, and feature requests.
Thousands of Wix customer care experts support tens of thousands of calls a day in various languages from countries around the world. Wix previously used user surveys to measure user sentiment regarding the company brand, products, services, or interactions with customer care agents. At best, we managed to receive feedback on 12% of our calls. In addition, this process was manual and limited in coverage. We were losing sight of important information crucial to customer success. This is where machine learning (ML) can solve many of these challenges.
ML capabilities such as automatic speech recognition enables you to process 100% of your customer conversations and improve your ability to understand and serve your customers. With accurate call transcripts, you can unlock further insights such as sentiment, trending issues, and agent effectiveness at resolving calls. Sentiment analysis is the use of natural language processing (NLP), a subfield of ML that determines whether data is positive, negative, or neutral. This helps agents and supervisors better understand and anticipate customer needs while enabling them to make informed decisions using actionable insights.
Wix wanted to expand visibility of customer conversation sentiment to 100% with the help of ML. In this post, we explain how Wix used Amazon Transcribe, a speech to text service, accurately redacted personally identifiable information (PII) from phone calls and other customer interactions from other channels, to develop a sentiment analysis system that can effectively determine how users feel throughout an interaction with customer care agents.
How we integrated Amazon Transcribe
Building a sentiment analysis service requires three main components:
- A data store for audio calls and transcribed data. For our solution, we used Amazon Simple Storage Service (Amazon S3).
- An automatic speech recognition ML model (Amazon Transcribe) for converting audio into text transcriptions.
- A sentiment analysis ML model for predicting sentiment.

For transcription (speech to text), we evaluated three leading vendors. The predominant parameters were accuracy, ease of use, and features for the call center use case (such as PII redaction). We found Amazon Transcribe to be the leading solution. The following are some of the differentiating capabilities:
- Custom vocabulary, is a list of specific words that you want Amazon Transcribe to recognize in your audio input. These are generally domain-specific words, phrases, or proper nouns that Amazon Transcribe isn’t recognizing. Custom vocabularies worked well to capture Wix’s specific terminology and phrases, such as the company name. The following is an example of the vocabulary we used:
| Phrase | Sounds Like |
| Wix | weeks |
| Wix | picks |
| Wix.com | weeks-dot-com |
| Wix.com | wix-that-come |
| Wix Professionals | Wix-affection-als |
After you upload your custom vocabulary list, you can use it for a transcription job.

- Channel identification in which Amazon Transcribe takes an audio file or stream that has multiple channels, transcribes each channel, and distinguishes between two different speakers (such as the agent and caller) automatically.
- Automatic redaction of PII data from output and a blocklist of words and phrases.
- Custom language models allow you to submit training data (a corpus of text data) to train custom language models that target domain-specific use cases and improve transcription accuracy. For example, you can provide Amazon Transcribe with industry-specific terms or acronyms that it might not otherwise recognize.
Custom language models are more powerful than custom vocabularies, because they can utilize a larger corpus of data, allow for tuning data, and understand individual terms as well as context. Because of the additional data and training involved, custom language models can produce significant accuracy improvements. To supercharge your accuracy, you can combine custom vocabularies with custom language models.
With these customization features, boosted the accuracy of Amazon Transcribe to specifically understand how users interact with Wix products and services. We first used a custom language model to produce transcriptions, then used custom vocabulary to replace words (as seen in the preceding examples). Then we trained with additional labeled data such as manually labeled transcriptions from real calls and knowledge base articles related to various vertical domains such as stores and payments.
Word error rate (WER) is the most common way to measure accuracy. WER counts how many words need to be changed to reach 100% accuracy. After we completed our model training with the customization features mentioned, we managed to increase the transcription accuracy (in US English) to 92% (8% WER).
92% is great, but we’re not done yet; we will continue to improve our transcription accuracy.
For sentiment analysis, we decided to develop a proprietary sentiment model that was tailored to identify sentiment regarding specific Wix features and data, and enabled custom integrations across various internal services.
Architecture overview
The following diagram illustrates our solution architecture and workflow.
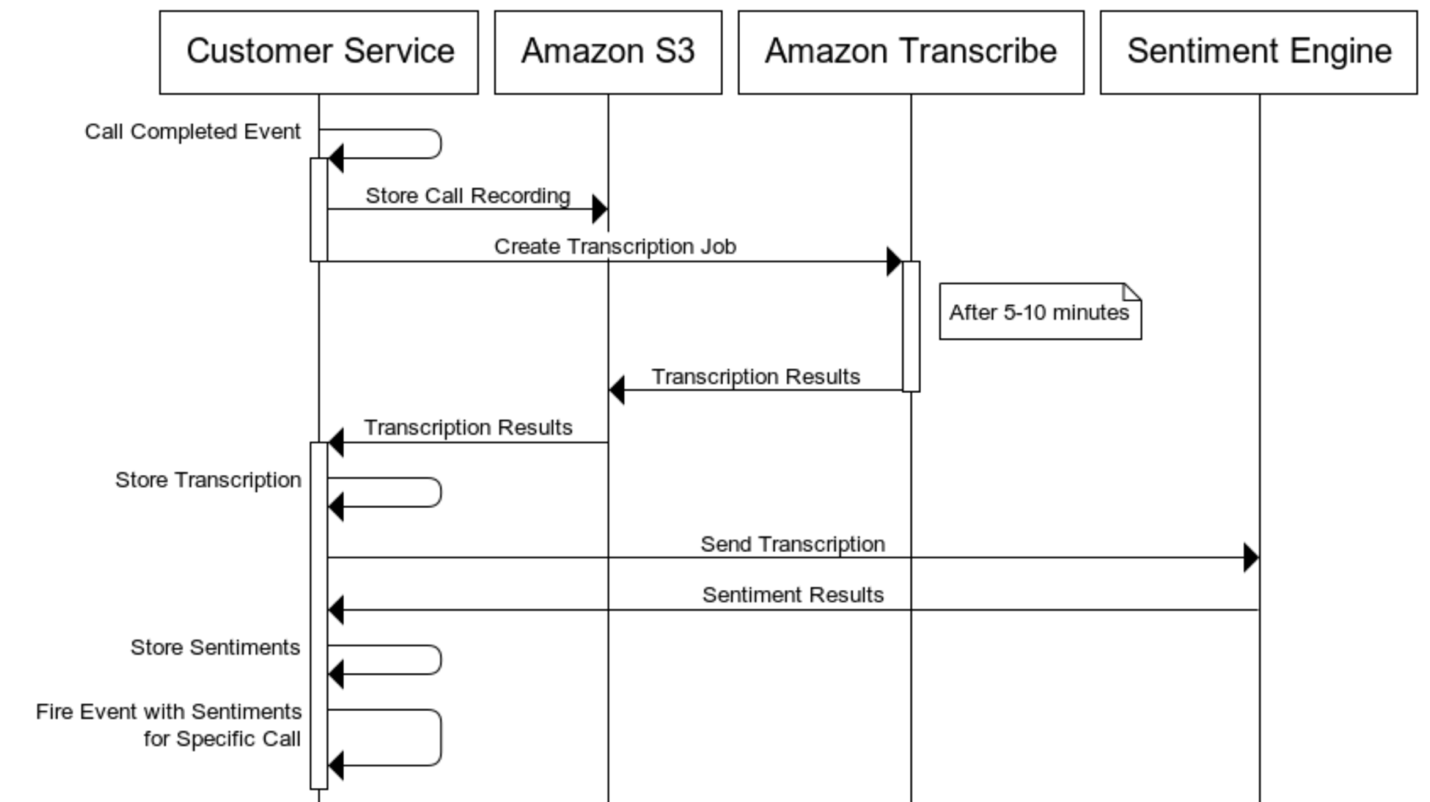
We start the process by listening for events (via a webhook) of calls that are completed. For every incoming new call, we download the call in audio format (.mp3) and save it to Amazon S3 with call metadata such as user ID and job ID.
When the audio download is complete, we start an asynchronous Amazon Transcribe transcription job. We receive a response (JSON) that consists of a list where each transcribed word is defined as a row containing additional metadata. We can then aggregate sentences based on stopwords or gaps in given timestamps between words.
Amazon Transcribe can have a response time of 1–10 minutes for a call lasting 30–120 minutes. To tackle this issue, we built a service that manages the asynchronous jobs and maintains consistency and synchronization of predefined steps. For example, we define the order of what steps need to be completed in the job before others can.
After the transcription is complete and returned from Amazon Transcribe, we save it to Amazon S3 for future use, and pass it on to our sentiment analysis model for processing. The response for sentiment ranges on a scale of 0–1 (0 being positive and 1 being negative). Finally, we save and log the results for future use.
Conclusion and next steps
Going forward, we want not only to better predict the sentiment of calls and chats, but to also understand and predict the root cause. This approach of combining predictive analytics with proactive care requires innovation and is yet to be tackled at scale.
With sentiment analysis, we can detect and trigger proactive care based on negative sentiment. We can also utilize the findings to improve visibility for our product managers on how our users feel about certain products and features, including negative trends related to specific releases.
Sentiment analysis is just one example of the many use cases that we can achieve with Amazon Transcribe.
In the future, we plan to use Amazon Transcribe to understand not just how users feel, but what topics they’re talking about. This can help us reach an even greater depth of what is needed to increase user success. For example, we can determine which products and features need urgent care, how to improve our customer care interactions across channels, and how to predict and prevent escalations from even happening.
We encourage you to try Amazon Transcribe and review the Developer Guide for more details.
About the Authors
 Assaf Elovic is Head of R&D at Wix, leading all customer care engineering efforts in the fields of virtual assistants, predictive analysis, and proactive care. Prior to this role, Assaf was an entrepreneur specializing in conversational user interfaces and NLP. Assaf holds a B.Sc. in Computer Science and B.A. in Economics from IDC Hertzylia.
Assaf Elovic is Head of R&D at Wix, leading all customer care engineering efforts in the fields of virtual assistants, predictive analysis, and proactive care. Prior to this role, Assaf was an entrepreneur specializing in conversational user interfaces and NLP. Assaf holds a B.Sc. in Computer Science and B.A. in Economics from IDC Hertzylia.
 Mykhailo Ulianchenko is an Engineering Manager at Customer Care, Wix. His teams are responsible for delivering data-driven products that help Wix to provide the best customer care service. Prior to the managerial position, Mykhailo was working as a software engineer in server, mobile and front-end areas. He is a big fan of extreme sports and Brazilian jiu-jitsu.
Mykhailo Ulianchenko is an Engineering Manager at Customer Care, Wix. His teams are responsible for delivering data-driven products that help Wix to provide the best customer care service. Prior to the managerial position, Mykhailo was working as a software engineer in server, mobile and front-end areas. He is a big fan of extreme sports and Brazilian jiu-jitsu.
 Vitalii Kloz is a Software Engineer at Wix.com, working on building flexible and resilient applications to automate data pipelines at Wix and, particularly, to enhance users’ experience with Wix Customer Care by providing data-driven insights using Machine Learning. Vitalii holds B.Sc in Computer Science from Kyiv University and is currently studying for M.Sc.
Vitalii Kloz is a Software Engineer at Wix.com, working on building flexible and resilient applications to automate data pipelines at Wix and, particularly, to enhance users’ experience with Wix Customer Care by providing data-driven insights using Machine Learning. Vitalii holds B.Sc in Computer Science from Kyiv University and is currently studying for M.Sc.
 Yaniv Vaknin is a Machine Learning Specialist at Amazon Web Services. Prior to AWS, Yaniv held leadership positions with AI startups and Enterprise including co-founder and CEO of Dipsee.ai. Yaniv works with AWS customers to harness the power of Machine Learning to solve real world tasks and derive value. In his spare time, Yaniv enjoys playing soccer with his boys.
Yaniv Vaknin is a Machine Learning Specialist at Amazon Web Services. Prior to AWS, Yaniv held leadership positions with AI startups and Enterprise including co-founder and CEO of Dipsee.ai. Yaniv works with AWS customers to harness the power of Machine Learning to solve real world tasks and derive value. In his spare time, Yaniv enjoys playing soccer with his boys.
 Gili Nachum is a senior AI/ML Specialist Solutions Architect in the AWS EMEA ML team. Gili is passionate about ML and in specific the cost and performance challenges of training deep learning models. Previously Gili was a SW architect working on Big Data, and Search.
Gili Nachum is a senior AI/ML Specialist Solutions Architect in the AWS EMEA ML team. Gili is passionate about ML and in specific the cost and performance challenges of training deep learning models. Previously Gili was a SW architect working on Big Data, and Search.