Artificial Intelligence
Mitigate hallucinations through Retrieval Augmented Generation using Pinecone vector database & Llama-2 from Amazon SageMaker JumpStart
Despite the seemingly unstoppable adoption of LLMs across industries, they are one component of a broader technology ecosystem that is powering the new AI wave. Many conversational AI use cases require LLMs like Llama 2, Flan T5, and Bloom to respond to user queries. These models rely on parametric knowledge to answer questions. The model learns this knowledge during training and encodes it into the model parameters. In order to update this knowledge, we must retrain the LLM, which takes a lot of time and money.
Fortunately, we can also use source knowledge to inform our LLMs. Source knowledge is information fed into the LLM through an input prompt. One popular approach to providing source knowledge is Retrieval Augmented Generation (RAG). Using RAG, we retrieve relevant information from an external data source and feed that information into the LLM.
In this blog post, we’ll explore how to deploy LLMs such as Llama-2 using Amazon Sagemaker JumpStart and keep our LLMs up to date with relevant information through Retrieval Augmented Generation (RAG) using the Pinecone vector database in order to prevent AI Hallucination.
Retrieval Augmented Generation (RAG) in Amazon SageMaker
Pinecone will handle the retrieval component of RAG, but you need two more critical components: somewhere to run the LLM inference and somewhere to run the embedding model.
Amazon SageMaker Studio an integrated development environment (IDE) that provides a single web-based visual interface where you can access purpose-built tools to perform all machine learning (ML) development. It provides SageMaker JumpStart which is a model hub where users can locate, preview, and launch a particular model in their own SageMaker account. It provides pretrained, publicly available and proprietary models for a wide range of problem types, including Foundation Models.
Amazon SageMaker Studio provides the ideal environment for developing RAG-enabled LLM pipelines. First, using the AWS console, go to Amazon SageMaker & create a SageMaker Studio domain and open a Jupyter Studio notebook.
Prerequisites
Complete the following prerequisite steps:
- Set up Amazon SageMaker Studio.
- Onboard to an Amazon SageMaker Domain.
- Sign up for a free-tier Pinecone Vector Database.
- Prerequisite libraries: SageMaker Python SDK, Pinecone Client
Solution Walkthrough
Using SageMaker Studio notebook, we first need install prerequisite libraries:
Deploying an LLM
In this post, we discuss two approaches to deploying an LLM. The first is through the HuggingFaceModel object. You can use this when deploying LLMs (and embedding models) directly from the Hugging Face model hub.
For example, you can create a deployable config for the google/flan-t5-xl model as shown in the following screen capture:
When deploying models directly from Hugging Face, initialize the my_model_configuration with the following:
- An
envconfig tells us which model we want to use and for what task. - Our SageMaker execution
rolegives us permissions to deploy our model. - An
image_uriis an image config specifically for deploying LLMs from Hugging Face.
Alternatively, SageMaker has a set of models directly compatible with a simpler JumpStartModel object. Many popular LLMs like Llama 2 are supported by this model, which can be initialized as shown in the following screen capture:
For both versions of my_model, deploy them as shown in the following screen capture:
With our initialized LLM endpoint, you can begin querying. The format of our queries may vary (particularly between conversational and non-conversational LLMs), but the process is generally the same. For the Hugging Face model, do the following:
You can find the solution in the GitHub repository.
The generated answer we’re receiving here doesn’t make much sense — it is a hallucination.
Providing Additional Context to LLM
Llama 2 attempts to answer our question based solely on internal parametric knowledge. Clearly, the model parameters do not store knowledge of which instances we can with managed spot training in SageMaker.
To answer this question correctly, we must use source knowledge. That is, we give additional information to the LLM via the prompt. Let’s add that information directly as additional context for the model.
We now see the correct answer to the question; that was easy! However, a user is unlikely to insert contexts into their prompts, they would already know the answer to their question.
Rather than manually inserting a single context, automatically identify relevant information from a more extensive database of information. For that, you will need Retrieval Augmented Generation.
Retrieval Augmented Generation
With Retrieval Augmented Generation, you can encode a database of information into a vector space where the proximity between vectors represents their relevance/semantic similarity. With this vector space as a knowledge base, you can convert a new user query, encode it into the same vector space, and retrieve the most relevant records previously indexed.
After retrieving these relevant records, select a few of them and include them in the LLM prompt as additional context, providing the LLM with highly relevant source knowledge. This is a two-step process where:
- Indexing populates the vector index with information from a dataset.
- Retrieval happens during a query and is where we retrieve relevant information from the vector index.
Both steps require an embedding model to translate our human-readable plain text into semantic vector space. Use the highly efficient MiniLM sentence transformer from Hugging Face as shown in the following screen capture. This model is not an LLM and therefore is not initialized in the same way as our Llama 2 model.
In the hub_config, specify the model ID as shown in the screen capture above but for the task, use feature-extraction because we are generating vector embeddings not text like our LLM. Following this, initialize the model config with HuggingFaceModel as before, but this time without the LLM image and with some version parameters.
You can deploy the model again with deploy, using the smaller (CPU only) instance of ml.t2.large. The MiniLM model is tiny, so it does not require a lot of memory and doesn’t need a GPU because it can quickly create embeddings even on a CPU. If preferred, you can run the model faster on GPU.
To create embeddings, use the predict method and pass a list of contexts to encode via the inputs key as shown:
Two input contexts are passed, returning two context vector embeddings as shown:
len(out)
2
The embedding dimensionality of the MiniLM model is 384 which means each vector embedding MiniLM outputs should have a dimensionality of 384. However, looking at the length of our embeddings, you will see the following:
len(out[0]), len(out[1])
(8, 8)
Two lists contain eight items each. MiniLM first processes text in a tokenization step. This tokenization transforms our human-readable plain text into a list of model-readable token IDs. In the output features of the model, you can see the token-level embeddings. one of these embeddings shows the expected dimensionality of 384 as shown:
len(out[0][0])
384
Transform these token-level embeddings into document-level embeddings by using the mean values across each vector dimension, as shown in the following illustration.
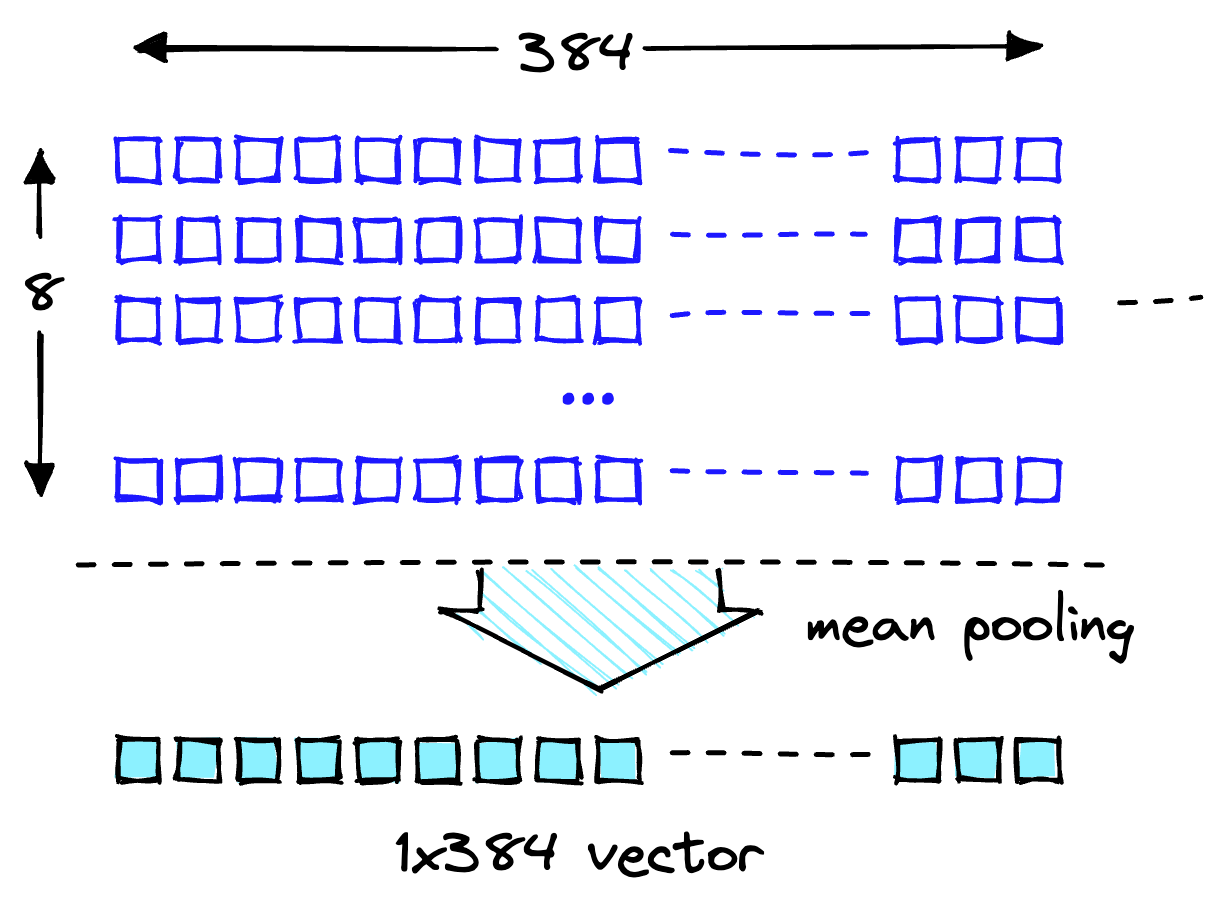
Mean pooling operation to get a single 384-dimensional vector.
With two 384-dimensional vector embeddings, one for each input text. To make our lives easier, wrap the encoding process into a single function as shown in the following screen capture:
Downloading the Dataset
Download the Amazon SageMaker FAQs as the knowledge base to get the data which contains both question and answer columns.
Download the Amazon SageMaker FAQs
When performing the search, look for Answers only, so you can drop the Question column. See notebook for details.
Our dataset and the embedding pipeline are ready. Now all we need is somewhere to store those embeddings.
Indexing
The Pinecone vector database stores vector embeddings and searches them efficiently at scale. To create a database, you will need a free API key from Pinecone.
After you have connected to the Pinecone vector database, create a single vector index (similar to a table in traditional DBs). Name the index retrieval-augmentation-aws and align the index dimension and metric parameters with those required by the embedding model (MiniLM in this case).
To begin inserting data, run the following:
You can begin querying the index with the question from earlier in this post.
Above output shows that we’re returning relevant contexts to help us answer our question. Since we top_k = 1, index.query returned the top result along side the metadata which reads Managed Spot Training can be used with all instances supported in Amazon.
Augmenting the Prompt
Use the retrieved contexts to augment the prompt and decide on a maximum amount of context to feed into the LLM. Use the 1000 characters limit to iteratively add each returned context to the prompt until you exceed the content length.
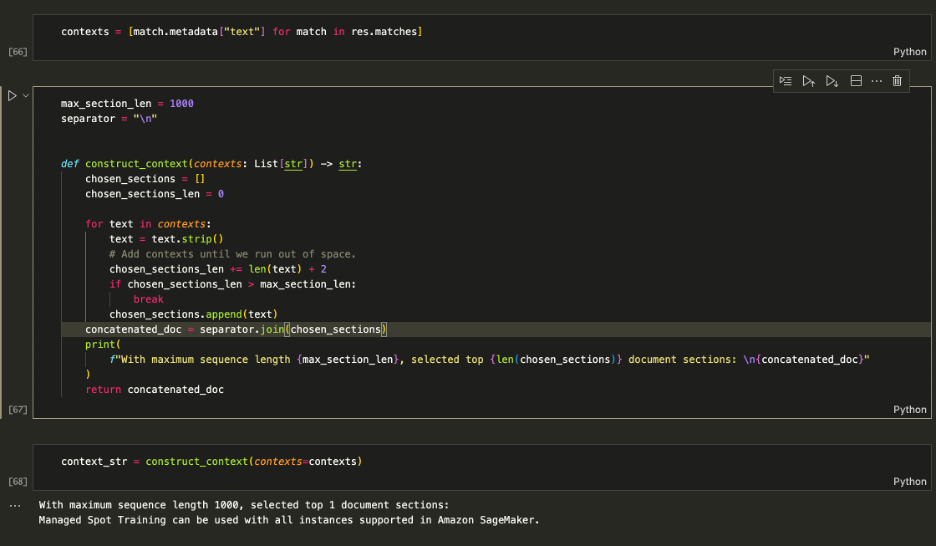
Augmenting the Prompt
Feed the context_str into the LLM prompt as shown in the following screen capture:
[Input]: Which instances can I use with Managed Spot Training in SageMaker? [Output]: Based on the context provided, you can use Managed Spot Training with all instances supported in Amazon SageMaker. Therefore, the answer is: All instances supported in Amazon SageMaker.
The logic works, so wrap it up into a single function to keep things clean.
You can now ask questions like those shown in the following:
Clean up
To stop incurring any unwanted charges, delete the model and endpoint.
Conclusion
In this post, we introduced you to RAG with open-access LLMs on SageMaker. We also showed how to deploy Amazon SageMaker Jumpstart models with Llama 2, Hugging Face LLMs with Flan T5, and embedding models with MiniLM.
We implemented a complete end-to-end RAG pipeline using our open-access models and a Pinecone vector index. Using this, we showed how to minimize hallucinations, and keep LLM knowledge up to date, and ultimately enhance the user experience and trust in our systems.
To run this example on your own, clone this GitHub repository and walkthrough the previous steps using the Question Answering notebook on GitHub.
About the authors
 Vedant Jain is a Sr. AI/ML Specialist, working on strategic Generative AI initiatives. Prior to joining AWS, Vedant has held ML/Data Science Specialty positions at various companies such as Databricks, Hortonworks (now Cloudera) & JP Morgan Chase. Outside of his work, Vedant is passionate about making music, rock climbing, using science to lead a meaningful life & exploring cuisines from around the world.
Vedant Jain is a Sr. AI/ML Specialist, working on strategic Generative AI initiatives. Prior to joining AWS, Vedant has held ML/Data Science Specialty positions at various companies such as Databricks, Hortonworks (now Cloudera) & JP Morgan Chase. Outside of his work, Vedant is passionate about making music, rock climbing, using science to lead a meaningful life & exploring cuisines from around the world.
 James Briggs is a Staff Developer Advocate at Pinecone, specializing in vector search and AI/ML. He guides developers and businesses in developing their own GenAI solutions through online education. Prior to Pinecone James worked on AI for small tech startups to established finance corporations. Outside of work, James has a passion for traveling and embracing new adventures, ranging from surfing and scuba to Muay Thai and BJJ.
James Briggs is a Staff Developer Advocate at Pinecone, specializing in vector search and AI/ML. He guides developers and businesses in developing their own GenAI solutions through online education. Prior to Pinecone James worked on AI for small tech startups to established finance corporations. Outside of work, James has a passion for traveling and embracing new adventures, ranging from surfing and scuba to Muay Thai and BJJ.
 Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.
Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.