Artificial Intelligence
Model Server for Apache MXNet v1.0 released
AWS recently released Model Server for Apache MXNet (MMS) v1.0, featuring a new API for managing the state of the service, which includes the ability to dynamically load models during runtime, to lower latency, and to have higher throughput. In this post, we will explore the new features and showcase the performance gains of the MMS v1.0.
What is Model Server for Apache MXNet (MMS)?
MMS is an open-source model serving framework, designed to simplify the task of serving deep learning models for inference at scale. The following is an architectural diagram of the MMS scalable deployment.

Here are some key features of MMS v1.0:
- Designed to serve MXNet, Gluon, and ONNX neural network models.
- Gives you the ability to customize every step in the inference execution pipeline using custom code packaged into the model archive.
- Comes with a preconfigured stack of services that is light and scalable, including REST API endpoints.
- Exposes a management API that allows model loading, unloading, and scaling at runtime.
- Provides prebuilt and optimized container images for serving inference at scale.
- Includes real-time operational metrics to monitor health, performance, and load of the system and APIs.
Quick start with MMS
MMS 1.0 requires Java 8 or higher. Here’s how to install it on the supported platforms:
MMS is currently not supported on Windows.
To install MMS v1.0 package:
MMS v1.0 doesn’t depend on any specific deep learning engine, but in this blog post we will focus doing inference using the MXNet engine.
To verify the installation:
This should produce the output:
The previous step will fail if no Java runtime is found, or if MMS is not properly installed by pip.
To stop the server, run:
Now that we have verified the MMS installation, let’s go infer some cat breeds.
Running inference
To allow you to get started quickly, we’ll show how you can start MMS, load a pre-trained model for inference, and scale the model at runtime.
We’ll start by running a model server serving SqueezeNet, a light-weight image classification model:
Let’s download a cat image and send it to MMS to get an inference result that identifies the cat breed.

To send requests to the prediction API we use port 8080.
As you can see, the model has identified the little Egyptian cat rightly, and MMS has delivered the result. Now the SqueezeNet worker is up, running, and able to predict.
Model Management API
MMS v1.0 features a new management API enabling registration, loading, and unloading of models at runtime. This is especially useful in production environments where deep learning (DL)/machine learning (ML) models are often consumed from external model-building pipelines. The MMS model management API provides a convenient REST interface to ensure that inference is served without downtime that otherwise would be necessary to populate new models into the running model server. This API consists of resources to register the new model, load it into running MMS instance (scale the model up) and unload it from the MMS instance when it’s no longer needed (scale the model down). All of these resources are available at runtime and don’t cause MMS downtime because they don’t perform bounce of MMS instance.
For security reasons, there is a separate port to access the management API that can only be accessed from the local host. By default, port 8081 is for the management API and port 8080 is for the prediction API. Let’s register and load the Network in Network (NIN) image classification model at runtime.
This makes MMS aware of a model and where to load it from. Then it starts a single worker process, in a synchronous fashion. In order to spawn more workers for a registered model:
We now have two workers for the NIN model. The min_workers parameter defines the minimum number of workers that should be up for the model. If this is set to 0 existing workers will be killed. In general, if it is set to ‘N’ (where N >= 0), ‘N – current_workers’ indicates that more additional workers will be spawned (or deleted if result is a negative number). The synchronous parameter ensures the request-response cycle is synchronous. For details on parameters see the MMS REST API specification.
Now MMS is ready to take inference requests for the NIN model as well. We’ll download an image of a tabby cat.

The NIN identified the tabby cat with 85% probability.
For more details on available APIs for management and prediction see the API documentation.
In the following section we’ll cover performance gains with MMS v1.0.
Performance improvements
MMS 1.0 introduces improved scalability and performance, the output of a newly designed architecture. To measure performance we use a CPU machine (EC2 c5.4xlarge instance, mxnet-mkl 1.3.0 package installed), to run inference on CPU. We use a GPU machine (EC2 p3.16xlarge, mxnet-cu90mkl 1.3.0 package installed) to run inference on GPU.
In addition to considering time spent in inference, you should also be aware of the overhead that is incurred from request handling. This overhead affects latency as the number of concurrent requests increases. Two addends comprise inference latency. There is the latency of running a forward pass on the model, and there is the latency of infra steps. The latency of infra steps consists of preparing data and handling results for/of forward pass, collecting metrics, passing data between frontend and backend, and switching between contexts while dealing with a greater number of concurrent users. To measure the latency of infra steps we run a test on a CPU machine using a specially devised no operation (no-op) model. This model doesn’t include running a forward pass, which means that the inference latency that is captured includes only the cost of the infra steps. This test demonstrated that MMS v1.0 has 4x better latency overhead with 100 concurrent requests and 7x better latency overhead with 200 concurrent requests. Latency on bigger models like Resnet-18 (where the actual inference on the engine is the hotspot) showed improvement as well. The inference latency with single concurrent request has improved 1.15x running resnet-18 on a GPU machine with a 128×128 image. With an increase to 100 concurrent requests GPU tests show up to 2.2x improvement in MMS v1.0 performance.
For throughput there is a 1.11x gain on a CPU machine, while running on GPU machine results in a 1.35x gain.
Another important performance metric is success rate, as the number of concurrent requests increases. As load increases and pushes towards hardware limits, the service starts to error on requests. The following graph shows that MMS v1.0 makes improvements in the request success rate:
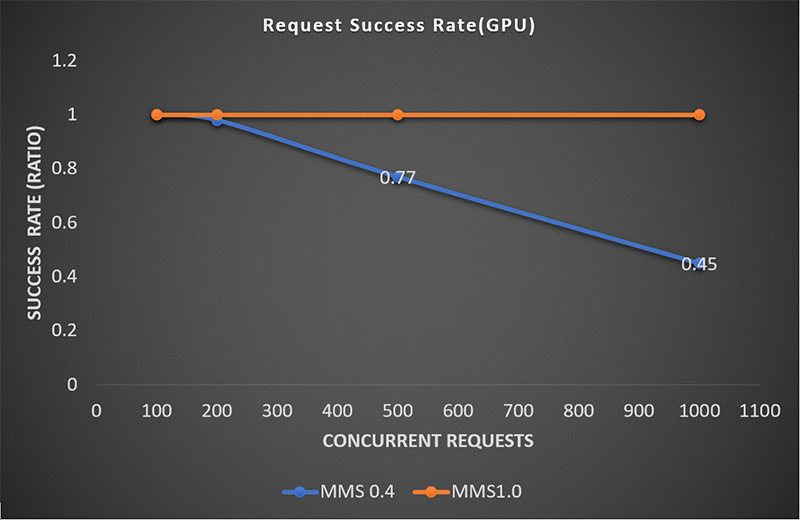
On a GPU machine, the load is shared with CPU. Here MMS v0.4 holds up until 200 concurrent requests, but starts showing errors as it moves towards more concurrent requests. On a CPU machine, the success rate of MMS v0.4 drops on fewer concurrent requests.
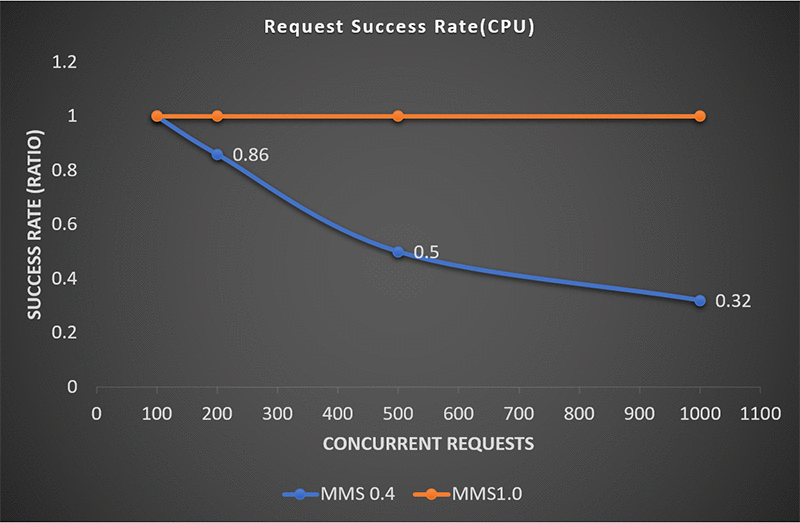
The tests for success rates of requests show that the load handling capacity on a single node has significantly improved.
Learn more and contribute
This is a preview of improvements and updates introduced in MMS v1.0. To learn more about MMS v1.0, start with our examples and documentation in the repository’s model zoo and documentation folder.
We welcome community participation including questions, requests, and contributions, as we continue to improve MMS. If you are using MMS already, we welcome your feedback via the repository’s GitHub issues. Head over to awslabs/mxnet-model-server to get started!
About the Authors
 Denis Davydenko is an Engineering Manager with AWS Deep Learning. He focuses on building Deep Learning tools that enable developers and scientists to build intelligent applications. In his spare time he enjoys spending time with his family, playing poker and video games.
Denis Davydenko is an Engineering Manager with AWS Deep Learning. He focuses on building Deep Learning tools that enable developers and scientists to build intelligent applications. In his spare time he enjoys spending time with his family, playing poker and video games.
 Frank Liu is a Software Engineer for AWS Deep Learning. He focuses on building innovative deep learning tools for software engineers and scientists. In his spare time, he enjoys hiking with friends and family.
Frank Liu is a Software Engineer for AWS Deep Learning. He focuses on building innovative deep learning tools for software engineers and scientists. In his spare time, he enjoys hiking with friends and family.
 Vamshidhar Dantu is a Software Developer with AWS Deep Learning. He focuses on building scalable and easily deployable deep learning systems. In his spare time, he enjoy spending time with family and playing badminton.
Vamshidhar Dantu is a Software Developer with AWS Deep Learning. He focuses on building scalable and easily deployable deep learning systems. In his spare time, he enjoy spending time with family and playing badminton.
 Rakesh Vasudevan is a Software Development Engineer with AWS Deep Learning. He is passionate about building scalable deep learning systems. In spare time, he enjoys gaming, cricket and hanging out with friends and family.
Rakesh Vasudevan is a Software Development Engineer with AWS Deep Learning. He is passionate about building scalable deep learning systems. In spare time, he enjoys gaming, cricket and hanging out with friends and family.