Artificial Intelligence
Identify mangrove forests using satellite image features using Amazon SageMaker Studio and Amazon SageMaker Autopilot – Part 1
The increasing ubiquity of satellite data over the last two decades is helping scientists observe and monitor the health of our constantly changing planet. By tracking specific regions of the Earth’s surface, scientists can observe how regions like forests, water bodies, or glaciers change over time. One such region of interest for geologists is mangrove forests. These forests are essential to the overall health of the planet and are one of the many areas across the world that are impacted by human activities. In this post, we show how to get access to satellite imagery data containing mangrove forests and how to visually interact with the data in Amazon SageMaker Studio. In Part 2 of this series, we show how to train a machine learning (ML) model using Amazon SageMaker Autopilot to identify those forests from a satellite image.
Overview of solution
A large number of satellites orbit the Earth, scanning its surface on a regular basis. Typical examples of such satellites are Landsat, Sentinel, CBERS, and MODIS, to name a few. You can access both recent and historical data captured by these satellites at no cost from multiple providers like USGS EarthExplorer, Land Viewer, or Copernicus Open Access Hub. Although they provide an excellent service to the scientific community by making their data freely available, it takes a significant amount of effort to gain familiarity with the interfaces of the respective providers. Additionally, such data from satellites is made available in different formats and may not comply with the standard Geographical Information Systems (GIS) data formatting. All of these challenges make it extremely difficult for newcomers to GIS to prepare a suitable dataset for ML model training.
Platforms like Google Earth Engine (GEE) and Earth on AWS make a wide variety of satellite imagery data available in a single portal that eases searching for the right dataset and standardizes the ETL (extract, transform, and load) component of the ML workflow in a convenient, beginner-friendly manner. GEE additionally provides a coding platform where you can programmatically explore the dataset and build a model in JavaScript. The Python API for GEE lacks the maturity of its JavaScript counterpart; however, that gap is sufficiently bridged by the open-sourced project geemap.
In this series of posts, we present a complete end-to-end example of building an ML model in the GIS space to detect mangrove forests from satellite images. Our goal is to provide a template solution that ML engineers and data scientists can use to explore and interact with the satellite imagery, make the data available in the right format for building a classifier, and have the option to validate model predictions visually. Specifically, we walk through the following:
- How to download satellite imagery data to a Studio environment
- How to interact with satellite data and perform exploratory data analysis in a Studio notebook
- How to automate training an ML model in Autopilot
Build the environment
The solution presented in this post is built in a Studio environment. To configure the environment, complete the following steps:
- Add a new SageMaker domain user and launch the Studio app. (For instructions, refer to Get Started.)
- Open a new Studio notebook by choosing the plus sign under Notebook and compute resources (make sure to choose the Data Science SageMaker image).

- Clone the mangrove-landcover-classification Git repository, which contains all the code used for this post. (For instructions, refer to Clone a Git Repository in SageMaker Studio).
- Open the notebook
notebooks/explore_mangrove_data.ipynb. - Run the first notebook cell to pip install all the required dependencies listed in the requirements.txt file in the root folder.
- Open a new Launcher tab and open a system terminal found in the Utilities and files section.

- Install the Earth Engine API:
- Authenticate Earth Engine:
- Follow the Earth Engine link in the output and sign up as a developer so that you can access GIS data from a notebook.

Mangrove dataset
The Global Mangrove Forest Distribution (GMFD) is one of the most cited datasets used by researchers in the area. The dataset, which contains labeled mangrove regions at a 30-meter resolution from around the world, is curated from more than 1,000 Landsat images obtained from the USGS EROS Center. One of the disadvantages of using the dataset is that it was compiled in 2000. In the absence of a newer dataset that is as comprehensive as the GMFD, we decided to use it because it serves the purpose of demonstrating an ML workload in the GIS space.
Given the visual nature of GIS data, it’s critical for ML practitioners to be able to interact with satellite images in an interactive manner with full map functionalities. Although GEE provides this functionality through a browser interface, it’s only available in JavaScript. Fortunately, the open-sourced project geemap aids data scientists by providing those functionalities in Python.
Go back to the explore_mangrove_data.ipynb notebook you opened earlier and follow the remaining cells to understand how to use simple interactive maps in the notebook.
- Start by importing Earth Engine and initializing it:
- Now import the satellite image collection from the database:
- Extract the collection, which contains just one set:
- To visualize the data on a map, you first need to instantiate a map through geemap:
- Next, define some parameters that make it easy to visualize the data on a world map:
- Now add the data as a layer on the map instantiated earlier with the visualization parameters:
You can add as many layers as you want to the map and then interactively turn them on or off for a cleaner view when necessary. Because mangrove forests aren’t everywhere on the earth, it makes sense to center the map to a coastal region with known mangrove forests and then render the map on the notebook as follows:
The latitude and longitude chosen here, 25 degrees north and 81 degrees west, respectively, correspond to the gulf coast of Florida, US. The map is rendered at a zoom level of 9, where a higher number provides a more closeup view.
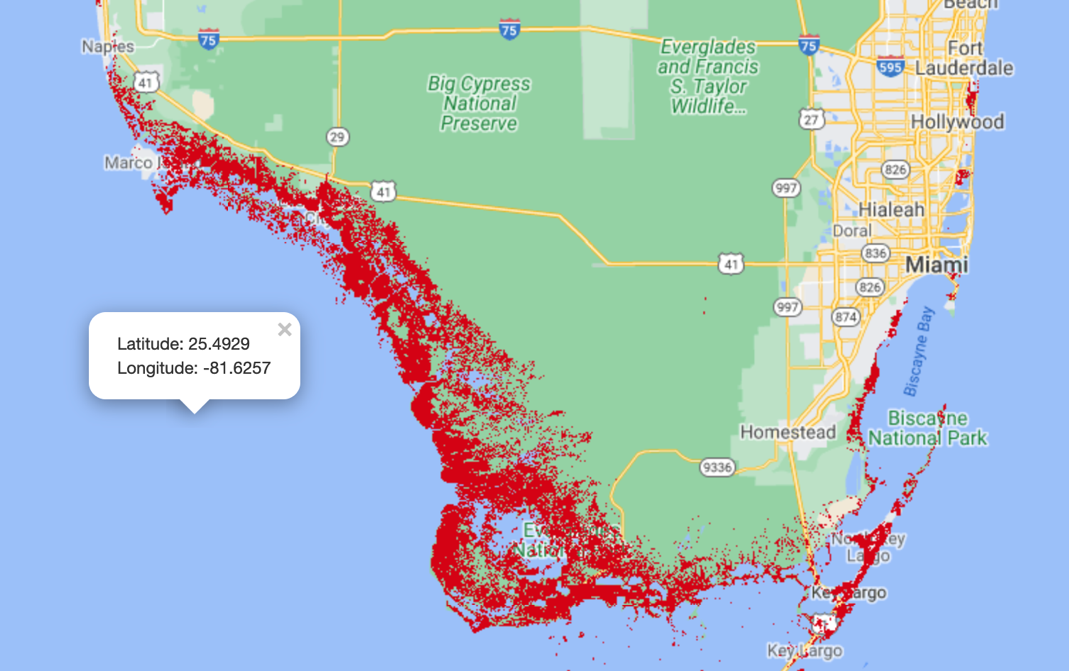
You can obtain some useful information about the dataset by accessing the associated metadata as follows:
You get the following output:
Most of the fields in the metadata are self-explanatory, except for the band names. The next section discusses this field in more detail.
Landsat dataset
The following image is a satellite image of an area at the border of French Guiana and Suriname, where mangrove forests are common. The left image shows a raw satellite image of the region; the image on the right depicts the GMFD data superimposed on it. Pixels representing mangroves are shown in red. It’s quite evident from the side-by-side comparison that there is no straightforward visual cue in either structure or color in the underlying satellite image that distinguishes mangroves from the surrounding region. In the absence of any such distinguishing pattern in the images, it poses a considerable challenge even for state-of-the-art deep learning-based classifiers to identify mangroves accurately. Fortunately, satellite images are captured at a range of wavelengths on the electromagnetic spectrum, part of which falls outside the visible range. Additionally, they also contain important measurements like surface reflectance. Therefore, researchers in the field have traditionally relied upon these measurements to build ML classifiers.

Unfortunately, apart from marking whether or not an individual pixel represents mangroves, the GMFD dataset doesn’t provide any additional information. However, other datasets can provide a host of features for every pixel that can be utilized to train a classifier. In this post, you use the USGS Landsat 8 dataset for that purpose. The Landsat 8 satellite was launched in 2013 and orbits the Earth every 99 minutes at an altitude of 705 km, capturing images covering a 185 km x 180 km patch on the Earth’s surface. It captures nine spectral bands, or portions of the electromagnetic spectrum sensed by a satellite, ranging from ultra blue to shortwave infrared. Therefore, the images available in the Landsat dataset are a collection of image patches containing multiple bands, with each patch time stamped by the date of collection.
To get a sample image from the Landsat dataset, you need to define a point of interest:
Then you filter the image collection by the point of interest, a date range, and optionally by the bands of interest. Because the images collected by the satellites are often obscured by cloud cover, it’s absolutely necessary to extract images with the minimum amount of cloud cover. Fortunately, the Landsat dataset already comes with a cloud detector. This streamlines the process of accessing all available images over several months, sorting them by amount of cloud cover, and picking the one with minimum cloud cover. For example, you can perform the entire process of extracting a Landsat image patch from the northern coast of the continent of South America in a few lines of code:
When specifying a region using a point of interest, that region doesn’t necessarily have to be centered on that point. The extracted image patch simply contains the point somewhere within it.
Finally, you can plot the image patch over a map by specifying proper plotting parameters based on a few of the chosen bands:
The following is a sample image patch collected by Landsat 8 showing in false color the Suriname-French Guiana border region. The mangrove regions are too tiny to be visible at the scale of the image.
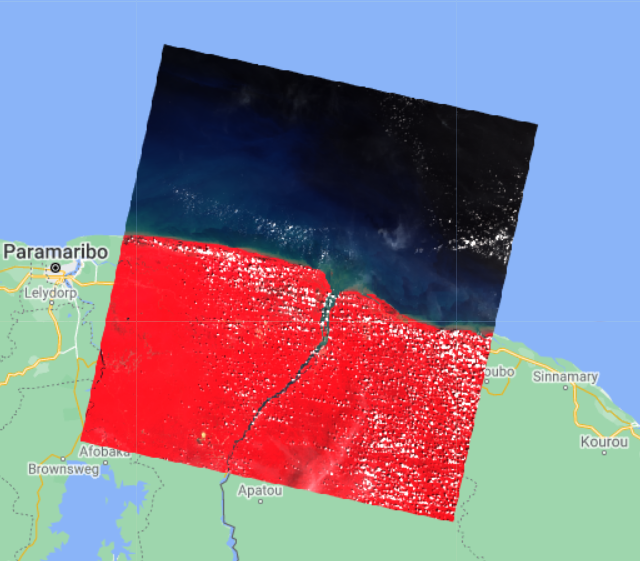
As usual, there is a host of useful metadata available for the extracted image:
The preceding image isn’t free from clouds, which is confirmed by the metadata suggesting a 5.76% cloud cover. Compared to a single binary band available from the GMFD image, the Landsat image contains the bands B1–B7.
ETL process
To summarize, you need to work with two distinct datasets to train a mangrove classifier. The GMFD dataset provides only the coordinates of pixels belonging to the minority class (mangrove). The Landsat dataset, on the other hand, provides band information for every pixel in a collection of patches, each patch covering roughly a 180 km2 area on the Earth’s surface. You now need to combine these two datasets to create the training dataset containing pixels belonging to both the minority and majority classes.
It’s wasteful to have a training dataset covering the entire surface of the Earth, because the mangrove regions cover a tiny fraction of the surface area. Because these regions are generally isolated from one another, an effective strategy is to create a set of points, each representing a specific mangrove forest on the earth’s surface, and collect the Landsat patches around those points. Subsequently, pixels can be sampled from each Landsat patch and a class—either mangrove or non-mangrove—can be assigned to it depending on whether the pixel appears in the GMFD dataset. The full labeled dataset can then be constructed by aggregating points sampled from this collection of patches.
The following table shows a sample of the regions and the corresponding coordinates to filter the Landsat patches.
| . | region | longitude | latitude |
| 0 | Mozambique1 | 36.2093 | -18.7423 |
| 1 | Mozambique2 | 34.7455 | -20.6128 |
| 2 | Nigeria1 | 5.6116 | 5.3431 |
| 3 | Nigeria2 | 5.9983 | 4.5678 |
| 4 | Guinea-Bissau | -15.9903 | 12.1660 |
Due to the larger expanse of mangrove forests in Mozambique and Nigeria, two points each are required to capture the respective regions in the preceding table. The full curated list of points is available on GitHub.
To sample points representing both classes, you have to create a binary mask for each class first. The minority class mask for a Landsat patch is simply the intersection of pixels in the patch and the GMFD dataset. The mask for the majority class for the patch is simply the inverse of the minority class mask. See the following code:
Use these two masks for the patch and create a set of labeled pixels by randomly sampling pixels from the respective masks:
numPixels is the number of samples drawn from the entire patch, and the sampled point is retained in the collection only if it falls in the target mask area. Because the mangrove region is typically a small fraction of the Landsat image patch, you need to use a larger value of numPixels for the mangrove mask compared to that for the non-mangrove mask. You can always look at the size of the two classes as follows to adjust the corresponding numPixels values:
In this example, the mangrove region is a tiny fraction of the Landsat patch because only 900 points were sampled from 100,000 attempts. Therefore, you should probably increase the value for numPixels for the minority class to restore balance between the two classes.
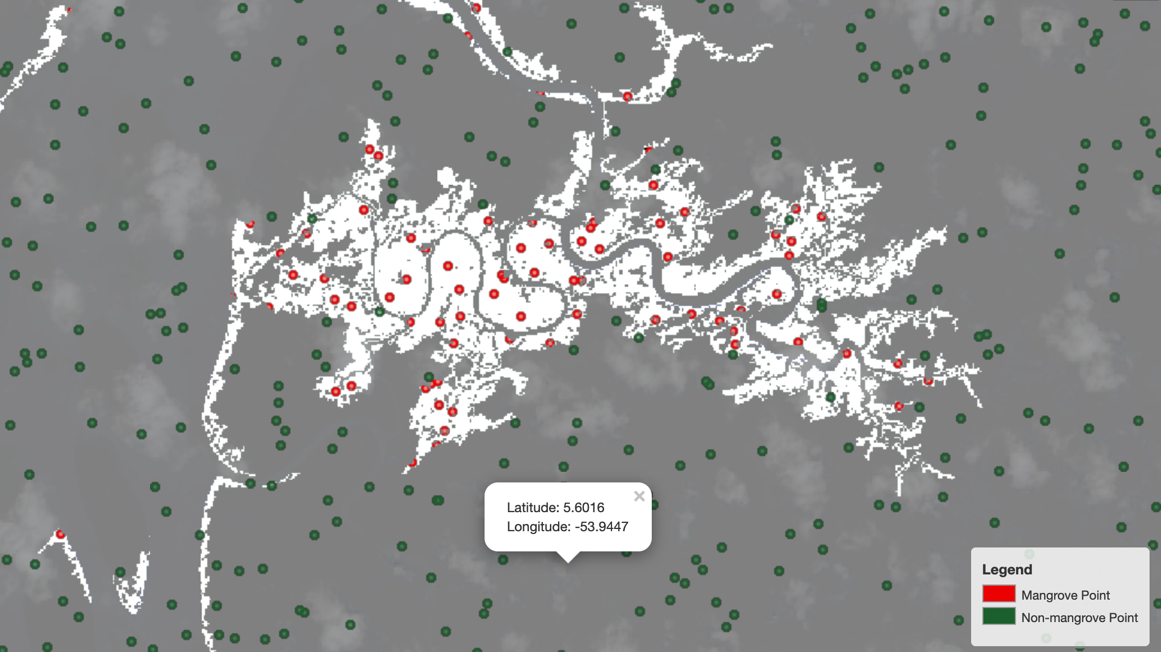
It’s a good idea to visually verify that the sampled points from the two respective sets indeed fall in the intended region in the map:
Sure enough, as the following image shows, the red points representing mangrove pixels fall in the white regions and the green points representing a lack of mangroves fall in the gray region. The maps.ipynb notebook walks through the process of generation and visual inspection of sampled points on a map.
Now you need to convert the sampled points into a DataFrame for ML model training, which can be accomplished by the ee_to_geopandas module of geemap:
The pixel coordinates at this stage are still represented as a Shapely geometry point. In the next step, you have to convert those into latitudes and longitudes. Additionally, you need to add labels to the DataFrame, which for the mangrove_gdf should all be 1, representing the minority class. See the following code:
Similarly, create another DataFrame, non_mangrove_gdf, using sampled points from the non-mangrove part of the Landsat image patch and assigning label=0 to all those points. A training dataset for the region is created by appending mangrove_gdf and non_mangrove_gdf.
Exploring the bands
Before diving into building a model to classify pixels in an image representing mangroves or not, it’s worth looking into the band values associated with those pixels. There are seven bands in the dataset, and the kernel density plots in the following figure show the distribution of those bands extracted from the 2015 Landsat data for the Indian mangrove region. The distribution of each band is broken down into two groups: pixels representing mangroves, and pixels representing other surface features like water or cultivated land.
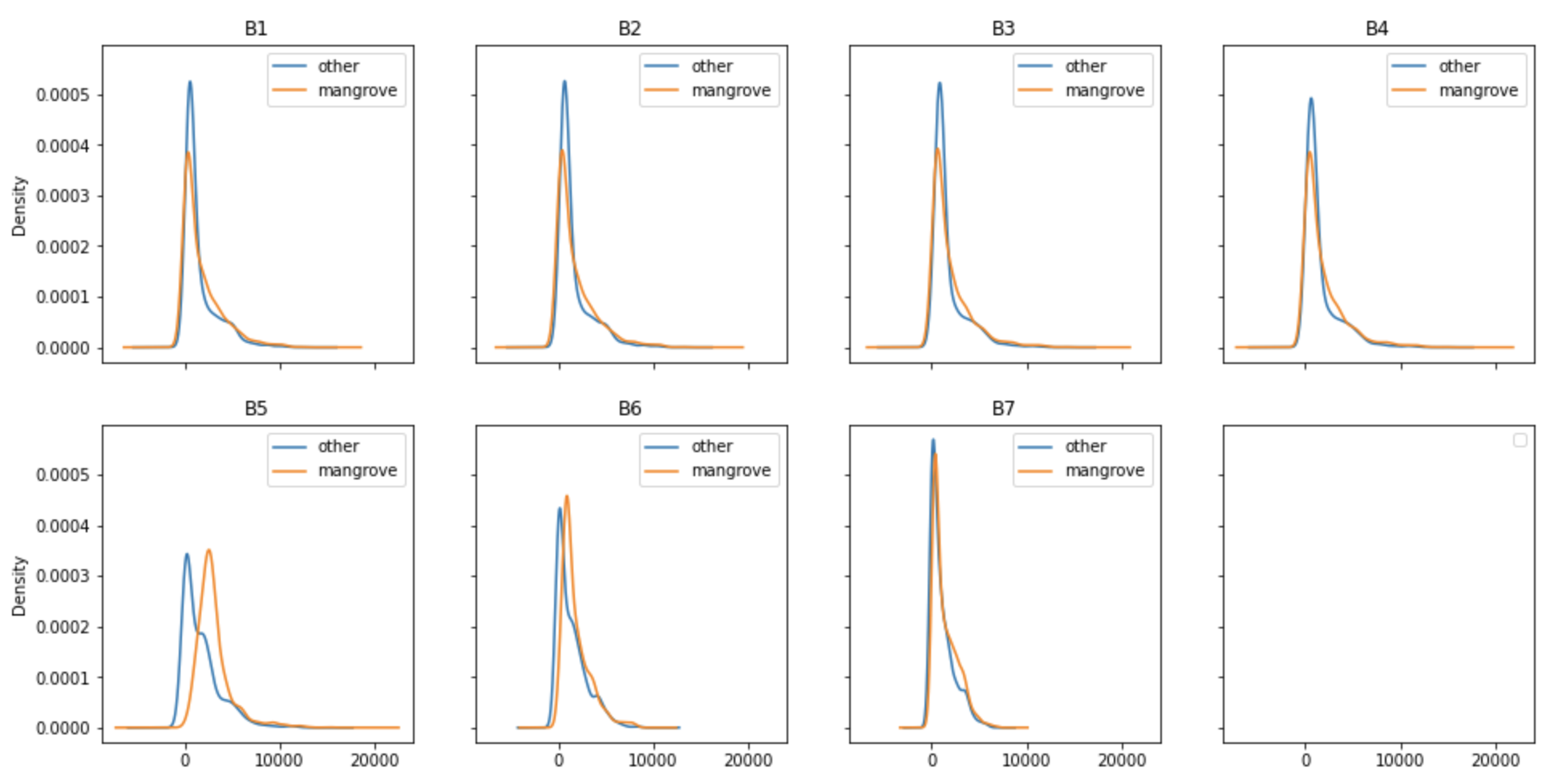
One important aspect of building a classifier is to understand how these distributions vary over different regions of the Earth. The following figure shows the kernel density plots for bands captured in the same year from the Miami area of the US in 2015. The apparent similarity of the density profiles indicate that it may be possible to build a universal mangrove classifier that can be generalized to predict new areas excluded from the training set.
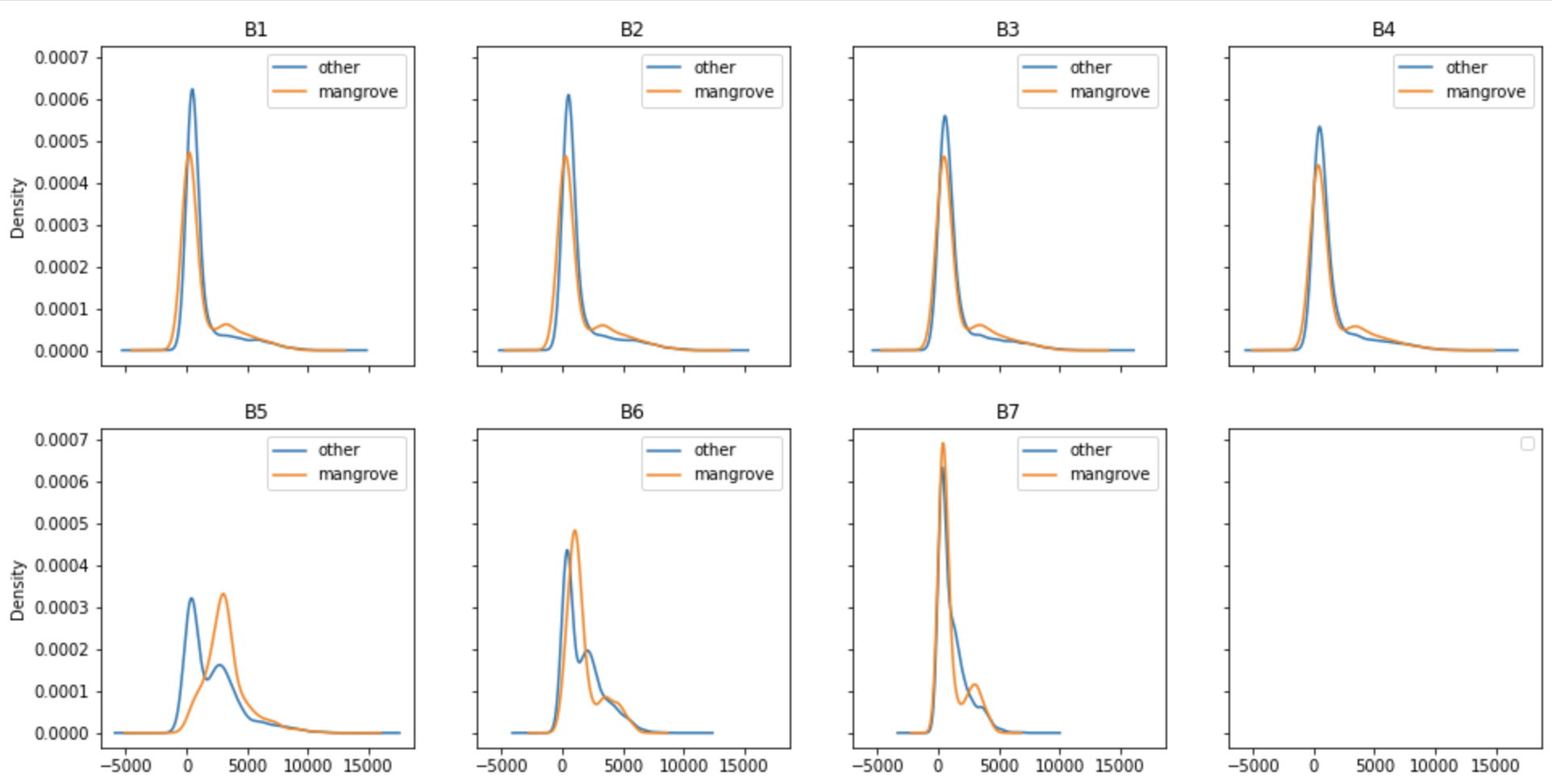
The plots shown in both figures are generated from band values that represent minimum cloud coverage, as determined by the built-in Earth Engine algorithm. Although this is a very reasonable approach, because different regions on the Earth have varying amounts of cloud coverage on the specific date of data collection, there exist alternative ways to capture the band values. For example, it’s also useful to calculate the median from a simple composite and use it for model training, but those details are beyond the scope of this post.
Prepare the training data
There are two main strategies to split the labeled dataset into training and test sets. In the first approach, datasets corresponding to the different regions can be combined into a single DataFrame and then split into training and test sets while preserving the fraction of the minority class. The alternative approach is to train a model on a subset of the regions and treat the remaining regions as part of the test set. One of the critical questions we want to address here is how good a model trained in a certain region generalizes over other regions previously unseen. This is important because mangroves from different parts of the world can have some local characteristics, and one way to judge the quality of a model is to investigate how reliable it is in predicting mangrove forests from the satellite image of a new region. Therefore, although splitting the dataset using the first strategy would likely improve the model performance, we follow the second approach.
As indicated earlier, the mangrove dataset was broken down into geographical regions and four of those, Vietnam2, Myanmar3, Cuba2, and India, were set aside to create the test dataset. The remaining 21 regions made up the training set. The dataset for each region was created by setting numPixels=10000 for mangrove and numPixels=1000 for the non-mangrove regions in the sampling process. The larger value of numPixels for mangroves ensures a more balanced dataset, because mangroves usually cover a small fraction of the satellite image patches. The resulting training data ended up having a 75/25 split between the majority and minority classes, whereas the split was 69/31 for the test dataset. The regional datasets as well as the training and test datasets were stored in an Amazon Simple Storage Service (Amazon S3) bucket. The complete code for generating the training and test sets is available in the prep_mangrove_dataset.ipynb notebook.
Train a model with smileCart
One of the few built-in models GEE provides is a classification and regression tree-based algorithm (smileCart) for quick classification. These built-in models allow you to quickly train a classifier and perform inference, at the cost of detailed model tuning and customization. Even with this downside, using smileCart still provides a beginner-friendly introduction to land cover classification, and therefore can serve as a baseline.
To train the built-in classifier, you need to provide two pieces of information: the satellite bands to use as features and the column representing the label. Additionally, you have to convert the training and test datasets from Pandas DataFrames to GEE feature collections. Then you instantiate the built-in classifier and train the model. The following is a high-level version of the code; you can find more details in the smilecart.ipynb notebook:
Both train_set_pts and test_set_pts are FeatureCollections, a common GEE data structure, containing the train dataset and test dataset, respectively. The model prediction generates the following confusion matrix on the test dataset.
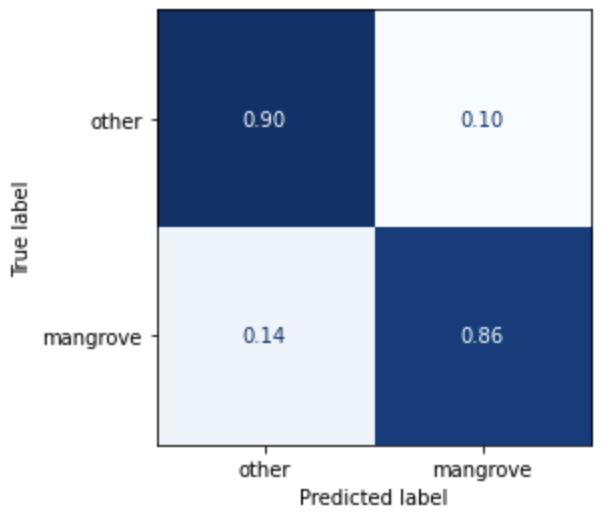
The model doesn’t predict mangroves very well, but this is a good starting point, and the result will act as a baseline for the custom models you build in part two of this series.
Conclusion
This concludes the first part of a two-part post, in which we show the ETL process for building a mangrove classifier based on features extracted from satellite images. We showed how to automate the process of gathering satellite images and visualize it in Studio for detailed exploration. In Part 2 of the post, we show how to use AutoML to build a custom model in Autopilot that performs better than the built-in smileCart model.
About the Authors
 Andrei Ivanovic is an incoming Master’s of Computer Science student at the University of Toronto and a recent graduate of the Engineering Science program at the University of Toronto, majoring in Machine Intelligence with a Robotics/Mechatronics minor. He is interested in computer vision, deep learning, and robotics. He did the work presented in this post during his summer internship at Amazon.
Andrei Ivanovic is an incoming Master’s of Computer Science student at the University of Toronto and a recent graduate of the Engineering Science program at the University of Toronto, majoring in Machine Intelligence with a Robotics/Mechatronics minor. He is interested in computer vision, deep learning, and robotics. He did the work presented in this post during his summer internship at Amazon.
 David Dong is a Data Scientist at Amazon Web Services.
David Dong is a Data Scientist at Amazon Web Services.
 Arkajyoti Misra is a Data Scientist at Amazon LastMile Transportation. He is passionate about applying Computer Vision techniques to solve problems that helps the earth. He loves to work with non-profit organizations and is a founding member of ekipi.org.
Arkajyoti Misra is a Data Scientist at Amazon LastMile Transportation. He is passionate about applying Computer Vision techniques to solve problems that helps the earth. He loves to work with non-profit organizations and is a founding member of ekipi.org.