Artificial Intelligence
Identify mangrove forests using satellite image features using Amazon SageMaker Studio and Amazon SageMaker Autopilot – Part 2
Mangrove forests are an important part of a healthy ecosystem, and human activities are one of the major reasons for their gradual disappearance from coastlines around the world. Using a machine learning (ML) model to identify mangrove regions from a satellite image gives researchers an effective way to monitor the size of the forests over time. In Part 1 of this series, we showed how to gather satellite data in an automated fashion and analyze it in Amazon SageMaker Studio with interactive visualization. In this post, we show how to use Amazon SageMaker Autopilot to automate the process of building a custom mangrove classifier.
Train a model with Autopilot
Autopilot provides a balanced way of building several models and selecting the best one. While creating multiple combinations of different data preprocessing techniques and ML models with minimal effort, Autopilot provides complete control over these component steps to the data scientist, if desired.
You can use Autopilot using one of the AWS SDKs (details available in the API reference guide for Autopilot) or through Studio. We use Autopilot in our Studio solution following the steps outlined in this section:
- On the Studio Launcher page, choose the plus sign for New Autopilot experiment.

- For Connect your data, select Find S3 bucket, and enter the bucket name where you kept the training and test datasets.
- For Dataset file name, enter the name of the training data file you created in the Prepare the training data section in Part 1.
- For Output data location (S3 bucket), enter the same bucket name you used in step 2.
- For Dataset directory name, enter a folder name under the bucket where you want Autopilot to store artifacts.
- For Is your S3 input a manifest file?, choose Off.
- For Target, choose label.
- For Auto deploy, choose Off.

- Under the Advanced settings, for Machine learning problem type, choose Binary Classification.
- For Objective metric, choose AUC.
- For Choose how to run your experiment, choose No, run a pilot to create a notebook with candidate definitions.
- Choose Create Experiment.

For more information about creating an experiment, refer to Create an Amazon SageMaker Autopilot experiment.It may take about 15 minutes to run this step. - When complete, choose Open candidate generation notebook, which opens a new notebook in read-only mode.

- Choose Import notebook to make the notebook editable.

- For Image, choose Data Science.
- For Kernel, choose Python 3.
- Choose Select.

This auto-generated notebook has detailed explanations and provides complete control over the actual model building task to follow. A customized version of the notebook, where a classifier is trained using Landsat satellite bands from 2013, is available in the code repository under notebooks/mangrove-2013.ipynb.
The model building framework consists of two parts: feature transformation as part of the data processing step, and hyperparameter optimization (HPO) as part of the model selection step. All the necessary artifacts for these tasks were created during the Autopilot experiment and saved in Amazon Simple Storage Service (Amazon S3). The first notebook cell downloads those artifacts from Amazon S3 to the local Amazon SageMaker file system for inspection and any necessary modification. There are two folders: generated_module and sagemaker_automl, where all the Python modules and scripts necessary to run the notebook are stored. The various feature transformation steps like imputation, scaling, and PCA are saved as generated_modules/candidate_data_processors/dpp*.py.
Autopilot creates three different models based on the XGBoost, linear learner, and multi-layer perceptron (MLP) algorithms. A candidate pipeline consists of one of the feature transformations options, known as data_transformer, and an algorithm. A pipeline is a Python dictionary and can be defined as follows:
In this example, the pipeline transforms the training data according to the script in generated_modules/candidate_data_processors/dpp5.py and builds an XGBoost model. This is where Autopilot provides complete control to the data scientist, who can pick the automatically generated feature transformation and model selection steps or build their own combination.
You can now add the pipeline to a pool for Autopilot to run the experiment as follows:
This is an important step where you can decide to keep only a subset of candidates suggested by Autopilot, based on subject matter expertise, to reduce the total runtime. For now, keep all Autopilot suggestions, which you can list as follows:
| Candidate Name | Algorithm | Feature Transformer |
| dpp0-xgboost | xgboost | dpp0.py |
| dpp1-xgboost | xgboost | dpp1.py |
| dpp2-linear-learner | linear-learner | dpp2.py |
| dpp3-xgboost | xgboost | dpp3.py |
| dpp4-xgboost | xgboost | dpp4.py |
| dpp5-xgboost | xgboost | dpp5.py |
| dpp6-mlp | mlp | dpp6.py |
The full Autopilot experiment is done in two parts. First, you need to run the data transformation jobs:
This step should complete in about 30 minutes for all the candidates, if you make no further modifications to the dpp*.py files.
The next step is to build the best set of models by tuning the hyperparameters for the respective algorithms. The hyperparameters are usually divided into two parts: static and tunable. The static hyperparameters remain unchanged throughout the experiment for all candidates that share the same algorithm. These hyperparameters are passed to the experiment as a dictionary. If you choose to pick the best XGBoost model by maximizing AUC from three rounds of a five-fold cross-validation scheme, the dictionary looks like the following code:
For the tunable hyperparameters, you need to pass another dictionary with ranges and scaling type:
The complete set of hyperparameters is available in the mangrove-2013.ipynb notebook.
To create an experiment where all seven candidates can be tested in parallel, create a multi-algorithm HPO tuner:
The objective metrics are defined independently for each algorithm:
Trying all possible values of hyperparameters for all the experiments is wasteful; you can adopt a Bayesian strategy to create an HPO tuner:
In the default setting, Autopilot picks 250 jobs in the tuner to pick the best model. For this use case, it’s sufficient to set max_jobs=50 to save time and resources, without any significant penalty in terms of picking the best set of hyperparameters. Finally, submit the HPO job as follows:
The process takes about 80 minutes on ml.m5.4xlarge instances. You can monitor progress on the SageMaker console by choosing Hyperparameter tuning jobs under Training in the navigation pane.

You can visualize a host of useful information, including the performance of each candidate, by choosing the name of the job in progress.

Finally, compare the model performance of the best candidates as follows:
| candidate | AUC | run_time (s) |
| dpp6-mlp | 0.96008 | 2711.0 |
| dpp4-xgboost | 0.95236 | 385.0 |
| dpp3-xgboost | 0.95095 | 202.0 |
| dpp4-xgboost | 0.95069 | 458.0 |
| dpp3-xgboost | 0.95015 | 361.0 |
The top performing model based on MLP, while marginally better than the XGBoost models with various choices of data processing steps, also takes a lot longer to train. You can find important details about the MLP model training, including the combination of hyperparameters used, as follows:
| TrainingJobName | mangrove-2-notebook–211021-2016-012-500271c8 |
| TrainingJobStatus | Completed |
| FinalObjectiveValue | 0.96008 |
| TrainingStartTime | 2021-10-21 20:22:55+00:00 |
| TrainingEndTime | 2021-10-21 21:08:06+00:00 |
| TrainingElapsedTimeSeconds | 2711 |
| TrainingJobDefinitionName | dpp6-mlp |
| dropout_prob | 0.415778 |
| embedding_size_factor | 0.849226 |
| layers | 256 |
| learning_rate | 0.00013862 |
| mini_batch_size | 317 |
| network_type | feedforward |
| weight_decay | 1.29323e-12 |
Create an inference pipeline
To generate inference on new data, you have to construct an inference pipeline on SageMaker to host the best model that can be called later to generate inference. The SageMaker pipeline model requires three containers as its components: data transformation, algorithm, and inverse label transformation (if numerical predictions need to be mapped on to non-numerical labels). For brevity, only part of the required code is shown in the following snippet; the complete code is available in the mangrove-2013.ipynb notebook:
After the model containers are built, you can construct and deploy the pipeline as follows:
The endpoint deployment takes about 10 minutes to complete.
Get inference on the test dataset using an endpoint
After the endpoint is deployed, you can invoke it with a payload of features B1–B7 to classify each pixel in an image as either mangrove (1) or other (0):
Complete details on postprocessing the model predictions for evaluation and plotting are available in notebooks/model_performance.ipynb.
Get inference on the test dataset using a batch transform
Now that you have created the best-performing model with Autopilot, we can use the model for inference. To get inference on large datasets, it’s more efficient to use a batch transform. Let’s generate predictions on the entire dataset (training and test) and append the results to the features, so that we can perform further analysis to, for instance, check the predicted vs. actuals and the distribution of features amongst predicted classes.
First, we create a manifest file in Amazon S3 that points to the locations of the training and test data from the previous data processing steps:
Now we can create a batch transform job. Because our input train and test dataset have label as the last column, we need to drop it during inference. To do that, we pass InputFilter in the DataProcessing argument. The code "$[:-2]" indicates to drop the last column. The predicted output is then joined with the source data for further analysis.
In the following code, we construct the arguments for the batch transform job and then pass to the create_transform_job function:
You can monitor the status of the job on the SageMaker console.

Visualize model performance
You can now visualize the performance of the best model on the test dataset, consisting of regions from India, Myanmar, Cuba, and Vietnam, as a confusion matrix. The model has a high recall value for pixels representing mangroves, but only about 75% precision. The precision of non-mangrove or other pixels stand at 99% with an 85% recall. You can tune the probability cutoff of the model predictions to adjust the respective values depending on the particular use case.


It’s worth noting that the results are a significant improvement over the built-in smileCart model.
Visualize model predictions
Finally, it’s useful to observe the model performance on specific regions on the map. In the following image, the mangrove area in the India-Bangladesh border is depicted in red. Points sampled from the Landsat image patch belonging to the test dataset are superimposed on the region, where each point is a pixel that the model determines to be representing mangroves. The blue points are classified correctly by the model, whereas the black points represent mistakes by the model.

The following image shows only the points that the model predicted to not represent mangroves, with the same color scheme as the preceding example. The gray outline is the part of the Landsat patch that doesn’t include any mangroves. As is evident from the image, the model doesn’t make any mistake classifying points on water, but faces a challenge when distinguishing pixels representing mangroves from those representing regular foliage.

The following image shows model performance on the Myanmar mangrove region.
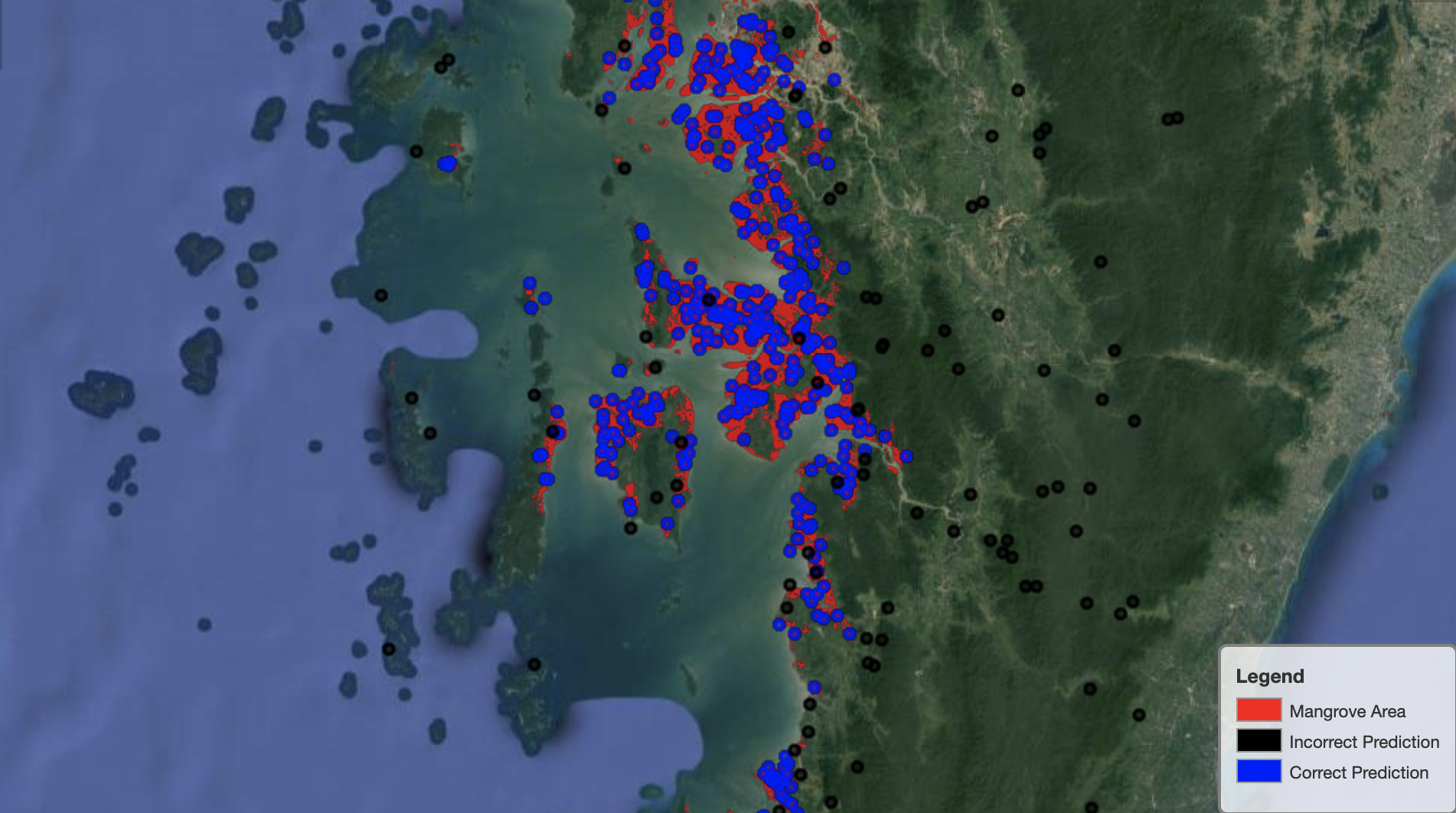
In the following image, the model does a better job identifying mangrove pixels.

Clean up
The SageMaker inference endpoint continues to incur cost if left running. Delete the endpoint as follows when you’re done:
Conclusion
This series of posts provided an end-to-end framework for data scientists for solving GIS problems. Part 1 showed the ETL process and a convenient way to visually interact with the data. Part 2 showed how to use Autopilot to automate building a custom mangrove classifier.
You can use this framework to explore new satellite datasets containing a richer set of bands useful for mangrove classification and explore feature engineering by incorporating domain knowledge.
About the Authors
 Andrei Ivanovic is an incoming Master’s of Computer Science student at the University of Toronto and a recent graduate of the Engineering Science program at the University of Toronto, majoring in Machine Intelligence with a Robotics/Mechatronics minor. He is interested in computer vision, deep learning, and robotics. He did the work presented in this post during his summer internship at Amazon.
Andrei Ivanovic is an incoming Master’s of Computer Science student at the University of Toronto and a recent graduate of the Engineering Science program at the University of Toronto, majoring in Machine Intelligence with a Robotics/Mechatronics minor. He is interested in computer vision, deep learning, and robotics. He did the work presented in this post during his summer internship at Amazon.
 David Dong is a Data Scientist at Amazon Web Services.
David Dong is a Data Scientist at Amazon Web Services.
 Arkajyoti Misra is a Data Scientist at Amazon LastMile Transportation. He is passionate about applying Computer Vision techniques to solve problems that helps the earth. He loves to work with non-profit organizations and is a founding member of ekipi.org.
Arkajyoti Misra is a Data Scientist at Amazon LastMile Transportation. He is passionate about applying Computer Vision techniques to solve problems that helps the earth. He loves to work with non-profit organizations and is a founding member of ekipi.org.