Artificial Intelligence
Create and manage Amazon EMR Clusters from SageMaker Studio to run interactive Spark and ML workloads – Part 2
In Part 1 of this series, we offered step-by-step guidance for creating, connecting, stopping, and debugging Amazon EMR clusters from Amazon SageMaker Studio in a single-account setup.
In this post, we dive deep into how you can use the same functionality in certain enterprise-ready, multi-account setups. As described in the AWS Well-Architected Framework, separating workloads across accounts enables your organization to set common guardrails while isolating environments. This can be particularly useful for certain security requirements, as well as simplify cost between projects and teams.
Solution overview
In this post, we go through the process to achieve the following architectural setup. We present the same simple interface as we saw in Part 1 for our data workers, abstracting away multi-account details from their day-to-day workflow when not needed.

We first describe how to set up your cross-account networks in order to connect to Amazon EMR from Studio. To start, we need to make sure that some prerequisites are set correctly. For our example, a DevOps admin needs to configure an Amazon SageMaker domain with an elastic network interface to a private VPC and specify the security group ID to attach.
Set up the network
After we set up the Studio domain, we need to configure our network settings to allow communication between accounts.
VPC peering
We start with VPC peering between the accounts in order to facilitate traffic back and forth.
- From our Studio account, on the Amazon Virtual Private Cloud (Amazon VPC) console, choose Peering connections.
- Choose Create peering connection.
- Create your request to peer the Studio VPC within the Amazon EMR account’s VPC.
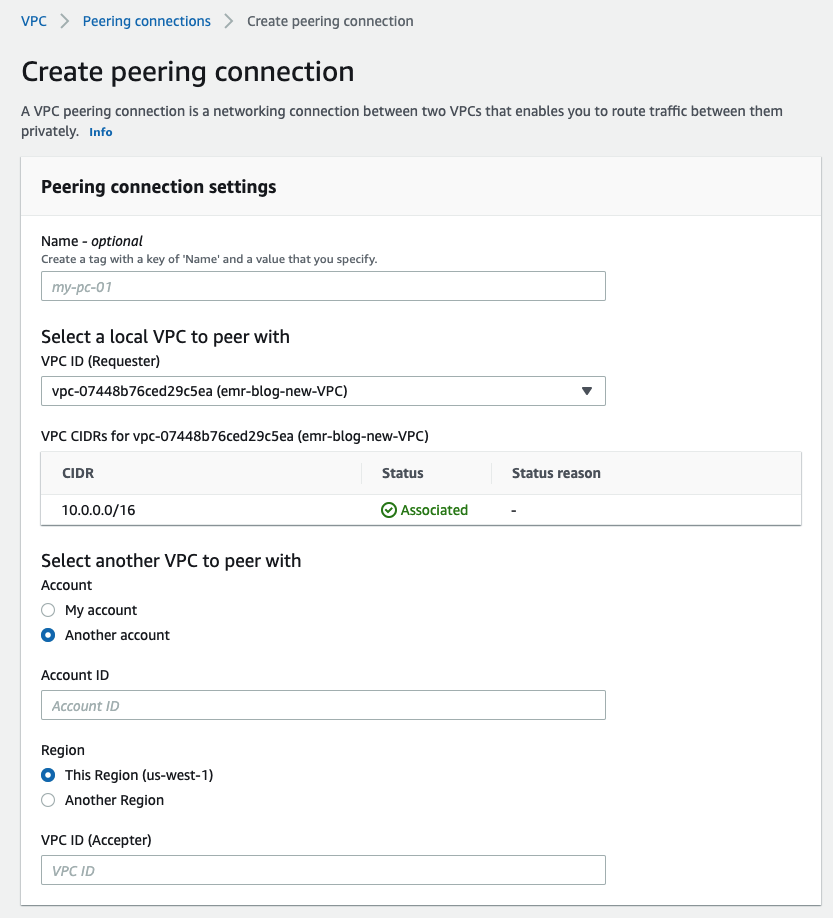
After you make the peering request, the admin can accept this request from the second account.

When peering private subnets, you should enable private IP DNS resolution at the VPC peering connection level.
Route tables
After you establish the peering connection, you must enable the flow of traffic by manually adding routes to the private subnet route tables in both accounts. We do this to enable creation and connection of EMR clusters from the Studio account to the remote account’s private subnet.
These routes point to the IP address range of the peered VPC’s private subnets and are set by going to the Route Tables tab found on the subnet page. Here the admin on each account can edit the routes.
The following route table of a Studio subnet shows traffic outbound from the Studio account for 2.0.1.0/24 through a peering connection.

The following route table of an Amazon EMR subnet shows traffic outbound from the Amazon EMR account to Studio for 10.0.20.0/24 through a peering connection.

Security groups
Lastly, the security group that is attached to your Studio domain must allow outbound traffic, and the security group of the Amazon EMR primary node must allow inbound TCP traffic from the Studio instance security group.
The following screenshot shows the inbound rules configuration in your SageMaker account.
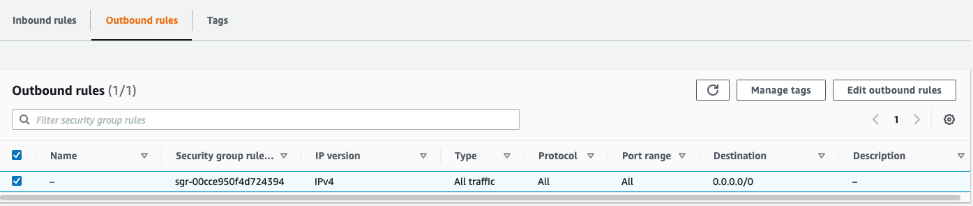
The following screenshot shows the inbound rules configuration in your Amazon EMR account.

Set up permissions
We need to create an AWS Identity and Access Management (IAM) role in the secondary Amazon EMR account that has the same Amazon EMR visibility permission as we saw in Part 1.
The following code shows the specific permissions for the IAM role. It’s the same as in Part 1, but includes the policy AllowRoleAssumptionForCrossAccountDiscovery:
This assumable role also needs a trust relationship with the Studio account (be sure to modify the account ID):
User journey
The following diagram illustrates the user journey for a unified notebook experience after you connect your various accounts. Just as in the previous post, the DevOps persona creates an AWS Service Catalog product and portfolio within the Studio account, from which data workers can provision templated EMR clusters.

Again, it’s worth noting that you can modify the full set of properties for Amazon EMR when creating AWS CloudFormation templates that can be deployed though Studio. This means that you can enable Spot, auto scaling, and other popular configurations through your Service Catalog product.
You can parameterize the preset CloudFormation template, which creates the EMR cluster, so that end-users can modify different aspects of the cluster to match their workloads. For example, the data scientist or data engineer may want to specify the number of core nodes on the cluster, and the creator of the template can specify AllowedValues to set guardrails.
Discover EMR clusters across accounts
To enable cluster discovery across accounts, we need to provide the previously created remote IAM role ARN to the Studio execution role. The Studio execution role assumes that remote role to discover and connect to EMR clusters in the remote account. The ARN of this assumable cross-account role is loaded by the Studio Jupyter server at launch and determines which role to use for cross-account cluster discoverability. To set and modify these user-specific ARNs, admins can create a Lifecycle Configuration (LCC), associated with the Jupyter server not the kernel gateway app, which writes the role ARN onto the Amazon Elastic File System (Amazon EFS) home directory for each user. You can apply this LCC to the entire set of users or it can be specific to individuals so they have granular access to which clusters can be viewed through assumed roles.
When the Jupyter server starts, lifecycle configurations run prior to reading of ARN roles that are written in the config file. This enables administrators to overwrite and fully control which cross-account ARNs are used at runtime. After the LCC runs and the files are written, the server reads the file /home/sagemaker-user/.cross-account-configuration-DO_NOT_DELETE/emr-discovery-iam-role-arns-DO_NOT_DELETE.json and stores that cross-account ARN. The following is an example LCC bash script:
At this point, a user can log in to their account and although they can modify this file, there’s no impact to the admin’s ARN designation. This is because the value is already stored by this point and the file is overwritten upon the server being restarted, because the LCC runs every time the Jupyter server app is started.
This configuration process can be completely abstracted away from data workers who discover and connect to clusters within the Studio. The only noticeable difference for cross-account clusters is that on the browsing tab, there is a column for account ID for which the cluster is housed in.

Use EMR clusters across accounts
After you establish cross-account visibility, the process for creating and stopping clusters remains the same as in Part 1. Refer to our GitHub repository for example cross-account CloudFormation stacks.
After you deploy the Service Catalog product, the process for end-users to spin up a cluster remains the same. Simply go to the Clusters page and choose Create cluster.
After cluster creation, we connect to our cluster using the Clusters graphical interface in Studio Notebooks. This creates an auto-populated magic cell that appears largely the same as with a single account, but with an appended parameter for the assumable cross-account role.
![]()
After the connection is made, we can proceed with the demo as before. You can clone our GitHub example repo and run through the notebook example just as in Part 1.
Conclusion
In this second and final part of our series, we showed how Studio users can create, connect, debug, and stop EMR clusters in cross-account setups. After you set up the networking and permissions, the end-user experience is just as we saw in Part 1. We encourage you to utilize this new functionality of Studio in your multi-account workloads today!
About the Authors
 Sumedha Swamy is a Principal Product Manager at Amazon Web Services. He leads SageMaker Studio team to build it into the IDE of choice for interactive data science and data engineering workflows. He has spent the past 15 years building customer-obsessed consumer and enterprise products using Machine Learning. In his free time he likes photographing the amazing geology of the American Southwest.
Sumedha Swamy is a Principal Product Manager at Amazon Web Services. He leads SageMaker Studio team to build it into the IDE of choice for interactive data science and data engineering workflows. He has spent the past 15 years building customer-obsessed consumer and enterprise products using Machine Learning. In his free time he likes photographing the amazing geology of the American Southwest.
 Prateek Mehrotra is a Senior SDE working for SageMaker Studio at Amazon Web Services. He is focused on building interactive ML solutions which simplify usability by abstracting away complexity. In his spare time, Prateek enjoys spending time with his family and likes to explore the world with them.
Prateek Mehrotra is a Senior SDE working for SageMaker Studio at Amazon Web Services. He is focused on building interactive ML solutions which simplify usability by abstracting away complexity. In his spare time, Prateek enjoys spending time with his family and likes to explore the world with them.
 Sriharsha M S is an AI/ML specialist solutions architect in the Strategic Specialist team at Amazon Web Services. He works with strategic AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement AI/ML applications at scale. His expertise spans application architecture, big data, analytics, and machine learning.
Sriharsha M S is an AI/ML specialist solutions architect in the Strategic Specialist team at Amazon Web Services. He works with strategic AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement AI/ML applications at scale. His expertise spans application architecture, big data, analytics, and machine learning.
 Sean Morgan is a Senior ML Solutions Architect at AWS. He has experience in the semiconductor and academic research fields, and uses his experience to help customers reach their goals on AWS. In his free time Sean is an activate open source contributor/maintainer and is the special interest group lead for TensorFlow Addons.
Sean Morgan is a Senior ML Solutions Architect at AWS. He has experience in the semiconductor and academic research fields, and uses his experience to help customers reach their goals on AWS. In his free time Sean is an activate open source contributor/maintainer and is the special interest group lead for TensorFlow Addons.
 Ruchir Tewari is a Senior Solutions Architect specializing in security and is a member of the ML TFC. For several years he has helped customers build secure architectures for a variety of hybrid, big data and AI/ML applications. He enjoys spending time with family, music and hikes in nature.
Ruchir Tewari is a Senior Solutions Architect specializing in security and is a member of the ML TFC. For several years he has helped customers build secure architectures for a variety of hybrid, big data and AI/ML applications. He enjoys spending time with family, music and hikes in nature.
 Luna Wang is a UX designer at AWS who has a background in computer science and interaction design. She is passionate about building customer-obsessed products and solving complex technical and business problems by using design methods. She is now working with a cross-functional team to build a set of new capabilities for interactive ML in SageMaker Studio.
Luna Wang is a UX designer at AWS who has a background in computer science and interaction design. She is passionate about building customer-obsessed products and solving complex technical and business problems by using design methods. She is now working with a cross-functional team to build a set of new capabilities for interactive ML in SageMaker Studio.