Artificial Intelligence
Powering enterprise search with the Cohere Embed 4 multimodal embeddings model in Amazon Bedrock
The Cohere Embed 4 multimodal embeddings model is now available as a fully managed, serverless option in Amazon Bedrock. Users can choose between cross-Region inference (CRIS) or Global cross-Region inference to manage unplanned traffic bursts by utilizing compute resources across different AWS Regions. Real-time information requests and time zone concentrations are example events that can cause inference demand to exceed anticipated traffic.
The new Embed 4 model on Amazon Bedrock is purpose-built for analyzing business documents. The model delivers leading multilingual capabilities and shows notable improvements over Embed 3 across the key benchmarks, making it ideal for use cases such as enterprise search.
In this post, we dive into the benefits and unique capabilities of Embed 4 for enterprise search use cases. We’ll show you how to quickly get started using Embed 4 on Amazon Bedrock, taking advantage of integrations with Strands Agents, S3 Vectors, and Amazon Bedrock AgentCore to build powerful agentic retrieval-augmented generation (RAG) workflows.
Embed 4 advances multimodal embedding capabilities by natively supporting complex business documents that combine text, images, and interleaved text and images into a unified vector representation. Embed 4 handles up to 128,000 tokens, minimizing the need for tedious document splitting and preprocessing pipelines. Embed 4 also offers configurable compressed embeddings that reduce vector storage costs by up to 83% (Introducing Embed 4: Multimodal search for business). Together with multilingual understanding across over 100 languages, enterprises in regulated industries such as finance, healthcare, and manufacturing can efficiently process unstructured documents, accelerating insight extraction for optimized RAG systems. Read about Embed 4 in this launch blog from July 2025 to explore how to deploy on Amazon SageMaker JumpStart.
Embed 4 can be integrated into your applications using the InvokeModel API, and here’s an example of how to use the AWS SDK for Python (Boto3) with Embed 4:
For the text only input:
For the mixed modalities input:
For more details, you can check Amazon Bedrock User Guide for Cohere Embed 4.
Enterprise search use case
In this section, we focus on using Embed 4 for an enterprise search use case in the finance industry. Embed 4 unlocks a range of capabilities for enterprises seeking to:
- Streamline information discovery
- Enhance generative AI workflows
- Optimize storage efficiency
Using foundation models in Amazon Bedrock is a fully serverless environment which removes infrastructure management and simplifies integration with other Amazon Bedrock capabilities. See more details for other possible use cases with Embed 4.
Solution overview
With the serverless experience available in Amazon Bedrock, you can get started quickly without spending too much effort on infrastructure management. In the following sections, we show how to get started with Cohere Embed 4. Embed 4 is already designed with storage efficiency in mind.
We choose Amazon S3 vectors for storage because it is a cost-optimized, AI-ready storage with native support for storing and querying vectors at scale. S3 vectors can store billions of vector embeddings with sub-second query latency, reducing total costs by up to 90% compared to traditional vector databases. We leverage the extensible Strands Agent SDK to simplify agent development and take advantage of model choice flexibility. We also use Bedrock AgentCore because it provides a fully managed, serverless runtime specifically built to handle dynamic, long-running agentic workloads with industry-leading session isolation, security, and real-time monitoring.
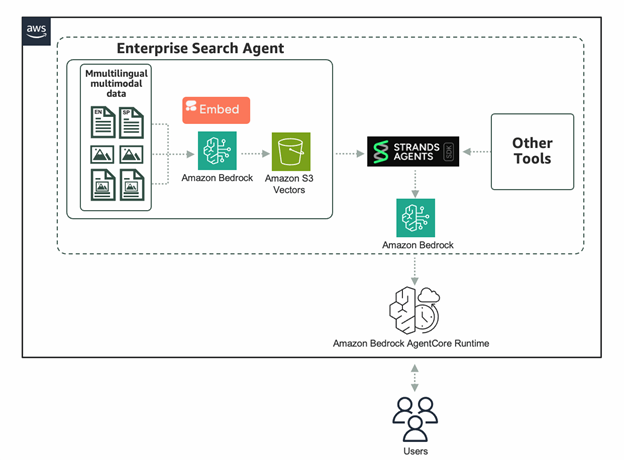
Prerequisites
To get started with Embed 4, verify you have the following prerequisites in place:
- IAM permissions: Configure your IAM role with necessary Amazon Bedrock permissions, or generate API keys through the console or SDK for testing. For more information, see Amazon Bedrock API keys.
- Strands SDK installation: Install the required SDK for your development environment. For more information, see the Strands quickstart guide.
- S3 Vectors configuration: Create an S3 vector bucket and vector index for storing and querying vector data. For more information, see the getting started with S3 Vectors tutorial.
Initialize Strands agents
The Strands Agents SDK offers an open source, modular framework that streamlines the development, integration, and orchestration of AI agents. With the flexible architecture developers can build reusable agent components and create custom tools with ease. The system supports multiple models, giving users freedom to select optimal solutions for their specific use cases. Models can be hosted on Amazon Bedrock, Amazon SageMaker, or elsewhere.
For example, Cohere Command A is a generative model with 111B parameters and a 256K context length. The model excels at tool use which can extend baseline functionality while avoiding unnecessary tool calls. The model is also suitable for multilingual tasks and RAG tasks such as manipulating numerical information in financial settings. When paired with Embed 4, which is purpose-built for highly regulated sectors like financial services, this combination delivers substantial competitive benefits through its adaptability.
We begin by defining a tool that a Strands agent can use. The tool searches for documents stored in S3 using semantic similarity. It first converts the user’s query into vectors with Cohere Embed 4. It then returns the most relevant documents by querying the embeddings stored in the S3 vector bucket. The code below shows only the inference portion. Embeddings created from the financial documents were stored in a S3 vector bucket before querying.
We then define a financial research agent that can use the tool to search financial documents. As your use case becomes more complex, more agents can be added for specialized tasks.
Simply using the tool returns the following results. Multilingual financial documents are ranked by semantic similarity to the query about comparing earnings growth rates. An agent can use this information to generate useful insights.
The example above relies on the QueryVectors API operation for S3 Vectors, which can work well for small documents. This approach can be improved to handle large and complex enterprise documents using sophisticated chunking and reranking techniques. Sentence boundaries can be used to create document chunks to preserve semantic coherence. The document chunks are then used to generate embeddings. The following API call passes the same query to the Strands agent:
The Strands agent uses the search tool we defined to generate an answer for the query about comparing earnings growth rates. The final answer considers the results returned from the search tool:
A custom tool like the S3 Vector search function used in this example is just one of many possibilities. With Strands it is straightforward to develop and orchestrate autonomous agents while Bedrock AgentCore serves as the managed deployment system to host and scale these Strands agents in production.
Deploy to Amazon Bedrock AgentCore
Once an agent is built and tested, it is ready to be deployed. AgentCore Runtime is a secure and serverless runtime purpose-built for deploying and scaling dynamic AI agents. Use the starter toolkit to automatically create the IAM execution role, container image, and Amazon Elastic Container Registry repository to host an agent in AgentCore Runtime. You can define multiple tools available to your agent. In this example, we use the Strands Agent powered by Embed 4:
Clean up
To avoid incurring unnecessary costs when you’re done, empty and delete the S3 Vector buckets created, applications that can make requests to the Amazon Bedrock APIs, the launched AgentCore Runtimes and associated ECR repositories.
For more information, see this documentation to delete a vector index and this documentation to delete a vector bucket, and see this step for removing resources created by the Bedrock AgentCore starter toolkit.
Conclusion
Embed 4 on Amazon Bedrock is beneficial for enterprises aiming to unlock the value of their unstructured, multimodal data. With support for up to 128,000 tokens, compressed embeddings for cost efficiency, and multilingual capabilities across 100+ languages, Embed 4 provides the scalability and precision required for enterprise search at scale.
Embed 4 has advanced capabilities that are optimized with domain specific understanding of data from regulated industries such as finance, healthcare, and manufacturing. When combined with S3 Vectors for cost-optimized storage, Strands Agents for agent orchestration, and Bedrock AgentCore for deployment, organizations can build secure, high-performing agentic workflows without the overhead of managing infrastructure. Check the full Region list for future updates.
To learn more, check out the Cohere in Amazon Bedrock product page and the Amazon Bedrock pricing page. If you’re interested in diving deeper check out the code sample and the Cohere on AWS GitHub repository.
About the authors
 James Yi is a Senior AI/ML Partner Solutions Architect at AWS. He spearheads AWS’s strategic partnerships in Emerging Technologies, guiding engineering teams to design and develop cutting-edge joint solutions in generative AI. He enables field and technical teams to seamlessly deploy, operate, secure, and integrate partner solutions on AWS. James collaborates closely with business leaders to define and execute joint Go-To-Market strategies, driving cloud-based business growth. Outside of work, he enjoys playing soccer, traveling, and spending time with his family.
James Yi is a Senior AI/ML Partner Solutions Architect at AWS. He spearheads AWS’s strategic partnerships in Emerging Technologies, guiding engineering teams to design and develop cutting-edge joint solutions in generative AI. He enables field and technical teams to seamlessly deploy, operate, secure, and integrate partner solutions on AWS. James collaborates closely with business leaders to define and execute joint Go-To-Market strategies, driving cloud-based business growth. Outside of work, he enjoys playing soccer, traveling, and spending time with his family.
 Nirmal Kumar is Sr. Product Manager for the Amazon SageMaker service. Committed to broadening access to AI/ML, he steers the development of no-code and low-code ML solutions. Outside work, he enjoys travelling and reading non-fiction.
Nirmal Kumar is Sr. Product Manager for the Amazon SageMaker service. Committed to broadening access to AI/ML, he steers the development of no-code and low-code ML solutions. Outside work, he enjoys travelling and reading non-fiction.
 Hugo Tse is a Solutions Architect at AWS, with a focus on Generative AI and Storage solutions. He is dedicated to empowering customers to overcome challenges and unlock new business opportunities using technology. He holds a Bachelor of Arts in Economics from the University of Chicago and a Master of Science in Information Technology from Arizona State University.
Hugo Tse is a Solutions Architect at AWS, with a focus on Generative AI and Storage solutions. He is dedicated to empowering customers to overcome challenges and unlock new business opportunities using technology. He holds a Bachelor of Arts in Economics from the University of Chicago and a Master of Science in Information Technology from Arizona State University.
 Mehran Najafi, PhD, serves as AWS Principal Solutions Architect and leads the Generative AI Solution Architects team for AWS Canada. His expertise lies in ensuring the scalability, optimization, and production deployment of multi-tenant generative AI solutions for enterprise customers.
Mehran Najafi, PhD, serves as AWS Principal Solutions Architect and leads the Generative AI Solution Architects team for AWS Canada. His expertise lies in ensuring the scalability, optimization, and production deployment of multi-tenant generative AI solutions for enterprise customers.
 Sagar Murthy is an agentic AI GTM leader at AWS who enjoys collaborating with frontier foundation model partners, agentic frameworks, startups, and enterprise customers to evangelize AI and data innovations, open source solutions, and enable impactful partnerships and launches, while building scalable GTM motions. Sagar brings a blend of technical solution and business acumen, holding a BE in Electronics Engineering from the University of Mumbai, MS in Computer Science from Rochester Institute of Technology, and an MBA from UCLA Anderson School of Management.
Sagar Murthy is an agentic AI GTM leader at AWS who enjoys collaborating with frontier foundation model partners, agentic frameworks, startups, and enterprise customers to evangelize AI and data innovations, open source solutions, and enable impactful partnerships and launches, while building scalable GTM motions. Sagar brings a blend of technical solution and business acumen, holding a BE in Electronics Engineering from the University of Mumbai, MS in Computer Science from Rochester Institute of Technology, and an MBA from UCLA Anderson School of Management.
 Payal Singh is a Solutions Architect at Cohere with over 15 years of cross-domain expertise in DevOps, Cloud, Security, SDN, Data Center Architecture, and Virtualization. She drives partnerships at Cohere and helps customers with complex GenAI solution integrations.
Payal Singh is a Solutions Architect at Cohere with over 15 years of cross-domain expertise in DevOps, Cloud, Security, SDN, Data Center Architecture, and Virtualization. She drives partnerships at Cohere and helps customers with complex GenAI solution integrations.