Artificial Intelligence
Reinventing retail with no-code machine learning: Sales forecasting using Amazon SageMaker Canvas
Retail businesses are data-driven—they analyze data to get insights about consumer behavior, understand shopping trends, make product recommendations, optimize websites, plan for inventory, and forecast sales.
A common approach for sales forecasting is to use historical sales data to predict future demand. Forecasting future demand is critical for planning and impacts inventory, logistics, and even marketing campaigns. Sales forecasting is generated at many levels such as product, sales channel (store, website, partner), warehouse, city, or country.
Sales managers and planners have domain expertise and knowledge of sales history, but lack data science and programming skills to create machine learning (ML) models to generate accurate sales forecasts. They need an intuitive, easy-to-use tool to create ML models without writing code.
To help achieve the agility and effectiveness that business analysts seek, we’ve introduced Amazon SageMaker Canvas, a no-code ML solution that helps companies accelerate delivery of ML solutions down to hours or days. SageMaker Canvas enables analysts to easily use available data in data lakes, data warehouses, and operational data stores; build ML models; and use them to make predictions interactively and for batch scoring on bulk datasets—all without writing a single line of code.
In this post, we show how to use SageMaker Canvas to generate sales forecasts at the retail store level.
Solution overview
SageMaker Canvas can import data from the local disk file, Amazon Simple Storage Service (Amazon S3), Amazon Redshift, and Snowflake (as of this writing).
In this post, we use Amazon Redshift cluster-based data with SageMaker Canvas to build ML models to generate sales forecasts. Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. Retail industry customers use Amazon Redshift to store and analyze large-scale, enterprise-level structured and semi-structured business data. It helps them accelerate data-driven business decisions in a performant and scalable way.
Generally, data engineers are responsible for ingesting and curating sales data in Amazon Redshift. Many retailers have a data lake where this has been done, but we show the steps here for clarity, and to illustrate how the data engineer can help the business analyst (such as the sales manager) by curating data for their use. This allows the data engineers to enable self-service data for use by business analysts.
In this post, we use a sample dataset that consists of two tables: storesales and storepromotions. You can prepare this sample dataset using your own sales data.
The storesales table keeps historical time series sales data for the stores. The table details are as follows:
| Column Name | Data Type |
| store | INT |
| saledate | TIMESTAMP |
| totalsales | DECIMAL |
The storepromotions table contains historical data from the stores regarding promotions and school holidays, on a daily time frame. The table details are as follows:
| Column Name | Data Type |
| store | INT |
| saledate | TIMESTAMP |
| promo | INT (0 /1) |
| schoolholiday | INT (0/1) |
We combine data from these two tables to train an ML model that can generate forecasts for the store sales.
SageMaker Canvas is a visual, point-and-click service that makes it easy to build ML models and generate accurate predictions. There are four steps involved in building the forecasting model:
- Select data from the data source (Amazon Redshift in this case).
- Configure and build (train) your model.
- View model insights such as accuracy and column impact on the prediction.
- Generate predictions (sales forecasts in this case).

Before we can start using SageMaker Canvas, we need to prepare our data and configure an AWS Identity and Access Management (IAM) role for SageMaker Canvas.
Create tables and load sample data
To use the sample dataset, complete the following steps:
- Upload
storesalesandstorepromotionssample data filesstore_sales.csvandstore_promotions.csvto an Amazon S3 bucket. Make sure the bucket is in the same region where you run Amazon Redshift cluster. - Create an Amazon Redshift cluster (if not running).
- Access the Amazon Redshift query editor.
- Create the tables and run the COPY command to load data. Use the appropriate IAM role for the Amazon Redshift cluster in the following code:
By default, the sample data is loaded in the storesales and storepromotions tables in the public schema of the dev database. But you can choose to use a different database and schema.
Create an IAM role for SageMaker Canvas
SageMaker Canvas uses an IAM role to access other AWS services. To configure your role, complete the following steps:
- Create your role. For instructions, refer to Give your users permissions to perform time series forecasting.
- Replace the code in the Trusted entities field on the Trust relationships tab.

The following code is the new trust policy for the IAM role:
- Provide the IAM role permission to Amazon Redshift. For instructions, refer to Give users permissions to import Amazon Redshift data.
The following screenshot shows your permission policies.

The IAM role should be assigned as the execution role for SageMaker Canvas in the Amazon SageMaker domain configuration.
- On the SageMaker console, assign the IAM role created as the execution role when configuring your SageMaker domain.

The data in the Amazon Redshift cluster database and SageMaker Canvas configuration both are ready. You can now use SageMaker Canvas to build the forecasting model.
Launch SageMaker Canvas
After the data engineers prepare the data in Amazon Redshift data warehouse, the sales managers can use SageMaker Canvas to generate forecasts.
To launch SageMaker Canvas, the AWS account administrator first performs the following steps:
- Create a SageMaker domain.
- Create user profiles for the SageMaker domain.
For instructions, refer to Getting started with using Amazon SageMaker Canvas or contact your AWS account administrator for the guidance.
Launch the SageMaker Canvas app from the SageMaker console. Make sure to launch SageMaker Canvas in the same AWS Region where the Amazon Redshift cluster is.

When SageMaker Canvas is launched, you can start with the first step of selecting data from the data source.
Import data in SageMaker Canvas
To import your data, complete the following steps:
- In the SageMaker Canvas application, on the Datasets menu, choose Import.
- On the Import page, choose the Add connection menu and choose Redshift.

The data engineer or cloud administrator can provide Amazon Redshift connection information to the sales manager. We show an example of the connection information in this post. - For Type, choose IAM.
- For Cluster identifier, enter your Amazon Redshift cluster ID.
- For Database name, enter
dev. - For Database user, enter
awsuser. - For Unload IAM role, enter the IAM role you created earlier for the Amazon Redshift cluster.
- For Connection name, enter
redshiftconnection. - Choose Add connection.
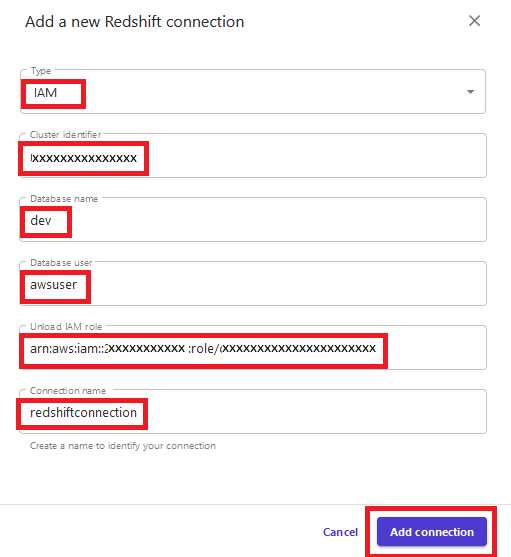
The connection between SageMaker Canvas and the Amazon Redshift cluster is established. You can see theredshiftconnectionicon on the top of the page. - Drag and drop
storesalesandstorepromotionstables under the public schema to the right panel.
It automatically creates an inner join between the tables on their matching column namesstoreandsaledate.

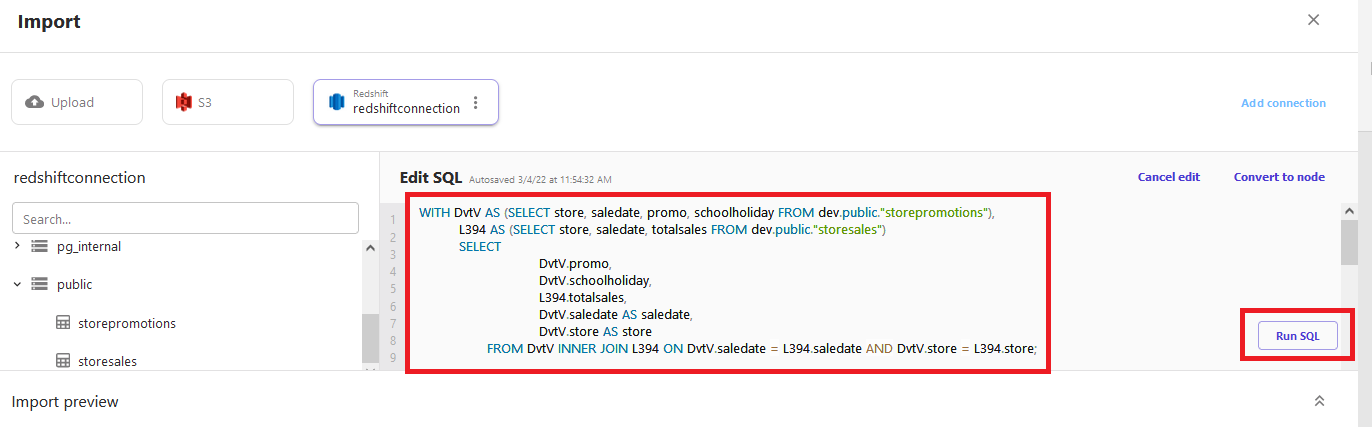
You can update joins and decide which fields to select from each table to create your desired dataset. You can configure the joins and field selection in two ways: using the SageMaker Canvas user interface to drag and drop joining of tables, or update the SQL script in SageMaker Canvas if the sales manager knows SQL. We include an example of editing SQL for completeness, and for the many business analysts who have been trained in SQL. The end goal is to prepare a SQL statement that provides the desired dataset that can be imported to Canvas. - Choose Edit in SQL to see SQL script used for the join.
- Modify the SQL statement with the following code:
- Choose Run SQL to run the query.
When the query is complete, you can see a preview of the output. This is the final data that you want to import in SageMaker Canvas for the ML model and forecasting purposes. - Choose Import data to import the data into SageMaker Canvas.
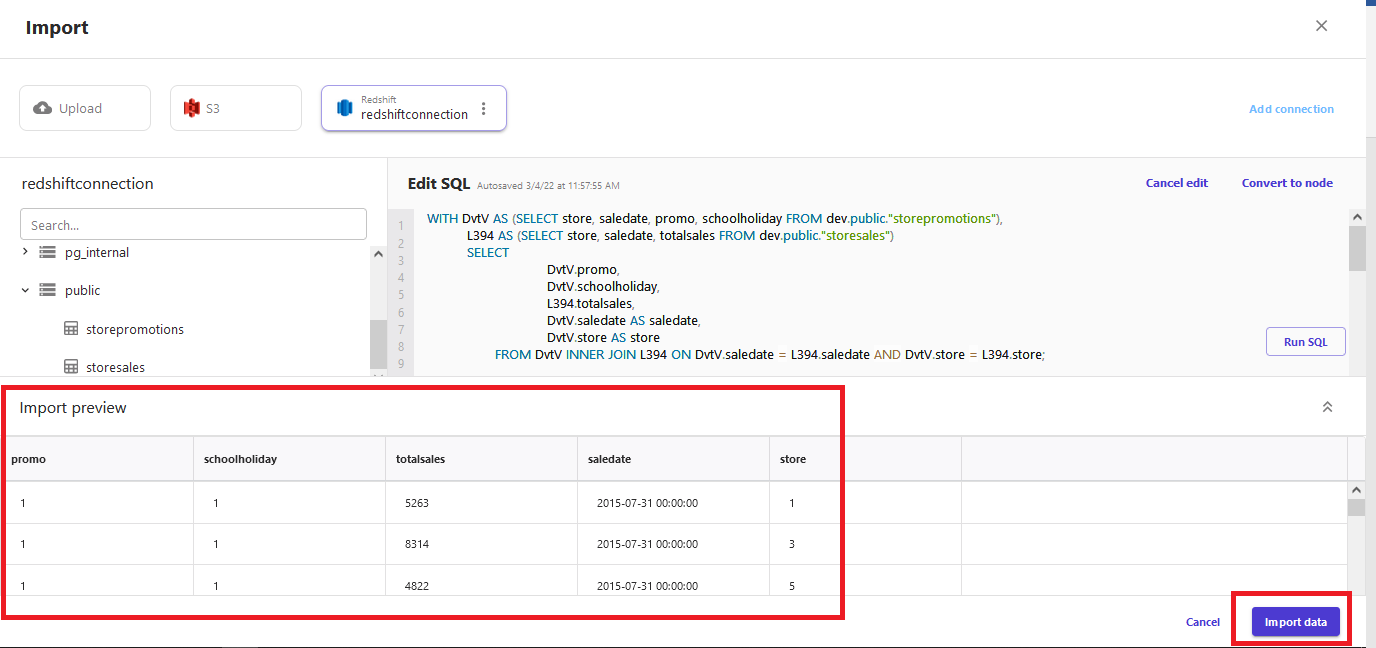
When importing the data, provide a suitable name for the dataset, such as store_daily_sales_dataset.

The dataset is ready in SageMaker Canvas. Now you can start training a model to forecast total sales across stores.
Configure and train the model
To configure model training in SageMaker Canvas, complete the following steps:
- Choose the Models menu option and choose New Model.
- For the new model, give a suitable name such as
store_sales_forecast_model. - Select the dataset
store_daily_sales_dataset. - Choose Select dataset.

On the Build tab, you can see data and column-level statistics as well as the configuration area for the model training.
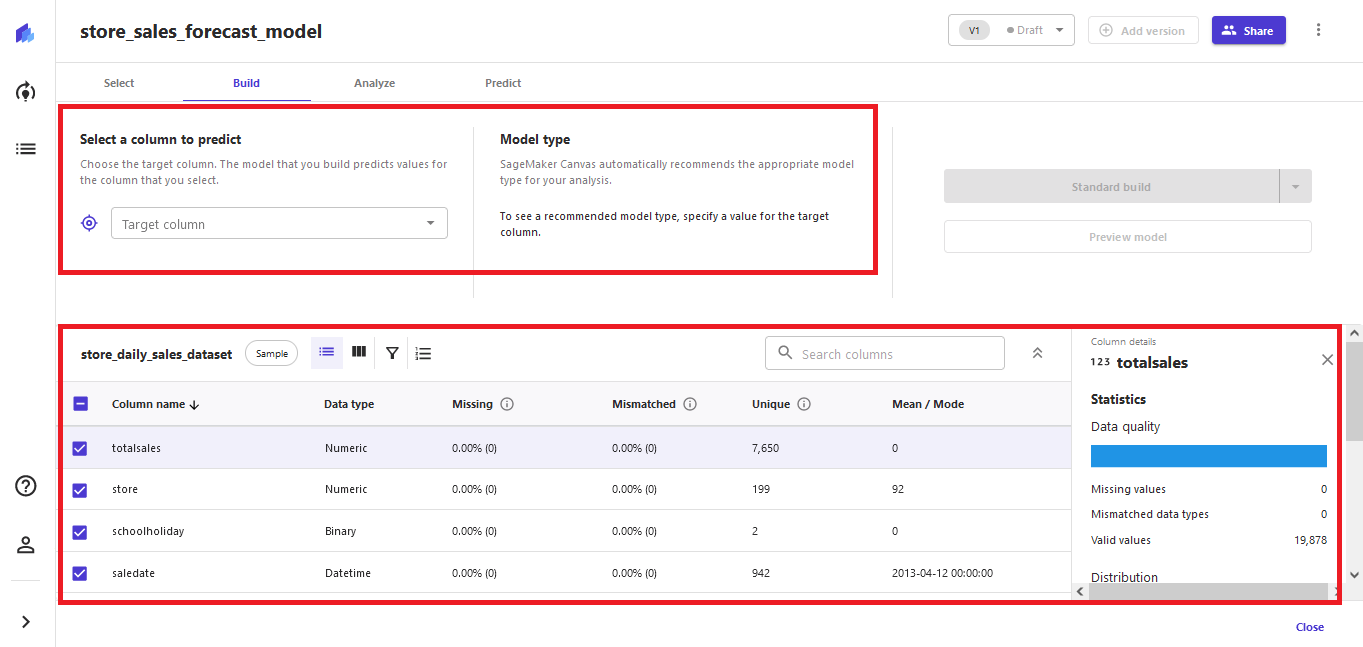
- Select
totalsalesfor the target column.
SageMaker Canvas automatically selects Time series forecasting as the model type. - Choose Configure to start configuration of the model training.

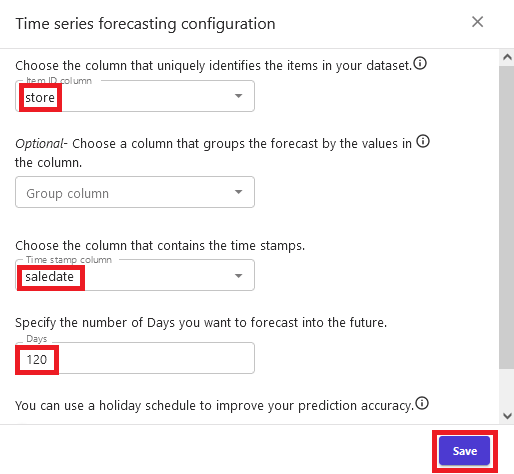
- In the Time series forecasting configuration section, choose store as the unique identity column because we want to generate forecasts for the store.
- Choose saledate for the time stamps column because it represents historical time series.
- Enter
120as the number of days because we want to forecast sales for a 3-month horizon. - Choose Save.
- When the model training configuration is complete, choose Standard build to start the model training.
The Quick build and Preview model options aren’t available for the time series forecasting model type at the time of this writing. After you choose the standard build, the Analyze tab shows the estimated time for the model training.

Model training can take 1–4 hours to complete depending on the data size. For the sample data used in this post, the model training was around 3 hours. When the model is ready, you can use it for generating forecasts.
Analyze results and generate forecasts
When the model training is complete, SageMaker Canvas shows the prediction accuracy of the model on the Analyze tab. For this example, it shows prediction accuracy as 79.13%. We can also see the impact of the columns on the prediction; in this example, promo and schoolholiday don’t influence the prediction. Column impact information is useful in fine-tuning the dataset and optimizing the model training.

The forecasts are generated on the Predict tab. You can generate forecasts for all the items (all stores) or for the selected single item (single store). It also shows the date range for which the forecasts can be generated.

As an example, we choose to view a single item and enter 2 as the store to generate sales forecasts for store 2 for the date range 2015-07-31 00:00:00 through 2015-11-28 00:00:00.

The generated forecasts show the average forecast as well as the upper and lower bound of the forecasts. The forecasts boundary helps make aggressive or balanced approaches for the forecast handling.
You can also download the generated forecasts as a CSV file or image. The generated forecasts CSV file is generally used to work offline with the forecast data.

The forecasts are generated based on time series data for a period of time. When the new baseline of data becomes available for the forecasts, you can upload a new baseline dataset and change the dataset in SageMaker Canvas to retrain the forecast model using new data.

You can retrain the model multiple times as new source data is available.
Clean up
To avoid incurring future session charges, log out of SageMaker Canvas.

Conclusion
Generating sales forecasts using SageMaker Canvas is configuration driven and an easy-to-use process. We showed you how data engineers can help curate data for business analysts to use, and how business analysts can gain insights from their data. The business analyst can now connect to data sources such local disk, Amazon S3, Amazon Redshift, or Snowflake to import data and join data across multiple tables to train a ML forecasting model, which is then used to generate sales forecasts. As the historical sales data updates, you can retrain the forecast model to maintain forecast accuracy.
Sales managers and operations planners can use SageMaker Canvas without expertise in data science and programming. This expedites decision-making time, enhances productivity, and helps build operational plans.
To get started and learn more about SageMaker Canvas, refer to the following resources:
- Amazon SageMaker Canvas documentation
- Announcing Amazon SageMaker Canvas – a Visual, No Code Machine Learning Capability for Business Analysts
About the Authors
 Brajendra Singh is solution architect in Amazon Web Services working with enterprise customers. He has strong developer background and is a keen enthusiast for data and machine learning solutions.
Brajendra Singh is solution architect in Amazon Web Services working with enterprise customers. He has strong developer background and is a keen enthusiast for data and machine learning solutions.
 Davide Gallitelli is a Specialist Solutions Architect for AI/ML in the EMEA region. He is based in Brussels and works closely with customers throughout Benelux. He has been a developer since he was very young, starting to code at the age of 7. He started learning AI/ML at university, and has fallen in love with it since then.
Davide Gallitelli is a Specialist Solutions Architect for AI/ML in the EMEA region. He is based in Brussels and works closely with customers throughout Benelux. He has been a developer since he was very young, starting to code at the age of 7. He started learning AI/ML at university, and has fallen in love with it since then.