AWS for M&E Blog
Identifying opportunities to place overlay advertisements in video content
Overlay advertisements (also called banner advertisements) are often used during a broadcast to promote related or upcoming shows, or for general third-party advertisements. They are typically displayed in the lower third of the screen (overlapping the broadcast video), and disappear after a few seconds. Although these can be effective tools for building awareness about new shows or products, they can cause complications because you don’t want the banner to cover up important on-screen information like subtitles, captions, or other text.
Manually finding viable times for overlay advertisements is time-consuming, but this article outlines an automated method that uses Amazon Rekognition, a machine learning service that works with images and videos. Using the outlined approach, a video can be automatically examined to find viable time slots for inserting overlay ads.
Overlay advertisement considerations
When thinking about where and when to place an overlay ad, there are a number of factors to consider.
First, there’s the digital on-screen logo graphic known as a bug. Bugs sit in a lower corner of the screen, and serve to identify the broadcaster, increase brand recognition, and assert ownership of the program being aired. Overlay advertisements should ideally avoid overlapping the bug, if one is present.
The second factor is the amount of time needed to display the ad. If there’s an open space at the bottom of the screen where an overlay ad could be placed, it is not usable if the availability only lasts for a few seconds when you want the ad to display for a longer period than that. In other words, having an open region to display the ad is important, but that region also needs to be available for a certain number of seconds in a row.
Finally, and arguably the most important factor, is whether an overlay ad obscures meaningful information like a caption, subtitle, or content that is viable to the show. This can be a challenging question to answer, since what “meaningful information” means varies from show to show. If the broadcast contains printed information on the screen, it’s usually not desirable to obscure that printed information, but there are a couple of important exceptions.
Suppose that the size of the text is too small to read clearly. This could be because the text is in the background (like a sign shown above a storefront in the background of a scene) or because the text is incidental (like printed text on a person’s shirt). In both of these cases, the text probably isn’t relevant to the program and can be safely covered.
The following is an example of a screen showing a wall with various advertising signs (with the region of interest highlighted with an orange dashed line). Note that none of the advertisements on the wall would normally be considered meaningful to the viewer, even though they contain text:

Likewise, suppose the screen shows text that is at a sharp angle (for example, greater than 45 degrees). The angled text may be part of the scenery or background of the scene, rather than something meant to be read by the viewer. In fact, one could make the assumption that strongly angled text is not meant to be significant, since viewers might have trouble making out what the words say. How much text angle is acceptable varies from case to case.
Using Amazon Rekognition to analyze images and videos
Amazon Rekognition is a service that uses artificial intelligence to analyze either still pictures or videos. You can easily use Amazon Rekognition to identify objects or people in a scene, look for inappropriate content, or search for and recognize individual faces in an image or frame of video – all without requiring any knowledge of machine learning. In this case, we use Amazon Rekognition to look for text. Here’s an example of Amazon Rekognition detecting text in an image:

Notice the light blue boxes around the runners’ jersey numbers. Those are called bounding boxes (since they show the boundaries of the text that was detected) and a number of them were detected in this single image.
To be clear, Amazon Rekognition didn’t add the blue bounding boxes to the image. Instead, Amazon Rekognition detected the text in the original image, and then the results were used to draw the blue overlays on the image for illustrative purposes. Amazon Rekognition doesn’t change your original images or videos – it just analyzes them and returns information about what was found.
Amazon Rekognition can be used to search for text in an image or in a video. When used to detect text in a video, Amazon Rekognition examines individual frames at about one frame per second of video. Additionally, you can specify which part of each frame to look in (called a region of interest), or you can look at the entire frame. Those two elements will play an important part in an automated solution to find overlay opportunities – more about them shortly.
The data returned by Amazon Rekognition is a list of all of the text items found in an image or a frame of video. That data includes information such as the text itself, how confident Amazon Rekognition was in its identification of the text, and information about when and where the text was detected (as a bounding box). By using this information, we can find opportunities for placing overlay ads in videos.
Finding available overlay opportunities
At this point, we understand the details of the problem, and we know what Amazon Rekognition can do. Next, let’s create an architecture to use Amazon Rekognition to do the overlay opportunity detection. The code for this project can be found in this GitHub repository, so be sure to download it if you want to follow along.
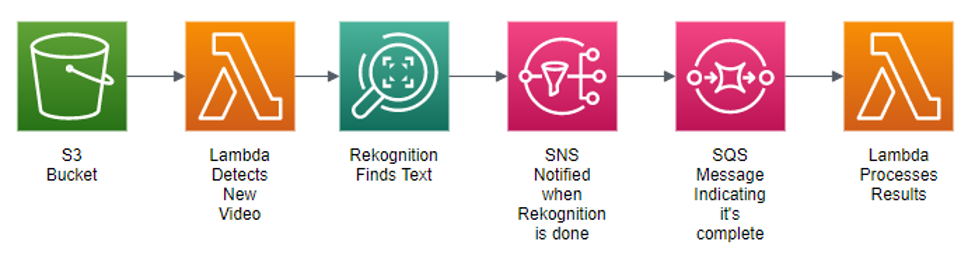
The architecture starts with an Amazon Simple Storage Service (Amazon S3) bucket, where we place videos for processing. When a new video file is placed in the bucket, we want code to run to analyze the video file and look for overlay opportunities. That code is run via two AWS Lambda functions, a serverless approach to deploying code. That means you don’t have to set up and maintain a server – instead, the code is executed only when needed, and you only pay for the computing power that’s used during the execution of the Lambda function.
Our first Lambda function has a single job to submit the new video file to Amazon Rekognition. It’s at this point that we specify a bounding box for the region of interest we want Amazon Rekognition to look for text in. That bounding box is specific to the broadcast to avoid overlapping the logo bug (if any), and so you can position the bounding box exactly as you want. Once the request to Amazon Rekognition is made, the first Lambda job is complete, and it shuts down.

Searching through a video to look for text takes time, even with Amazon Rekognition examining roughly one frame per second of video. For example, it may take thirty minutes to process a one hour video. Because of this, the Lambda function requests the text detection and then shuts down, at which point Amazon Rekognition runs for a while, and then uses Amazon Simple Notification Service (Amazon SNS) as a mechanism to signal when the text detection process is complete.
Amazon SNS is an AWS service that allows different parts of an application to communicate with each other using notifications. In this case, Amazon Rekognition posts a notification to an SNS topic when video processing is complete.
That notification causes a message to be placed on an Amazon Simple Queue Service (Amazon SQS) queue, which acts as a trigger for another Lambda. Then the second Lambda function takes the results from Amazon Rekognition, analyzes them, and outputs data that indicates where overlay opportunities exist.
Like Amazon SNS, Amazon SQS is a service that allows different parts of an application to communicate with each other using queues. Queues can be thought of as holding a set of messages, and different parts of your application can write messages to, or read messages from a queue. Using a queue allows the application to scale easily, since you can have many different instances of the same Lambda function read messages from a single queue, allowing certain types of processing to be done in parallel. Also, a message remains on a queue until it is successfully processed, which adds an element of resiliency to this solution.
The following is a diagram that illustrates the process:
Now let’s talk about the Lambda that takes the results from Amazon Rekognition and finds overlay opportunities. As previously discussed, Amazon Rekognition looks at roughly one frame per second when searching for text. That means if a piece of text like a title screen or caption appears onscreen between timestamp 22:01 to 22:15 (meaning it is shown for 15 seconds) Amazon Rekognition returns data that indicates 15 consecutive text detections, each found with the same text and bounding box, but with different timestamps.
There are a couple of important things to know about how Amazon Rekognition checks for text in video. First, text detection isn’t accurate at the frame level. Instead, Amazon Rekognition returns timestamps (rather than timecodes) for detected text, and the text detection happens roughly once per second. Because of that one second interval, we should assume that the first time a piece of text is found, it may have been onscreen for up to one second before the time reported. Similarly, the last time a piece of text is detected, we should assume it could be onscreen for up to one second after that detection. We can refer to this as “padding”, since it occurs on both ends of a set of contiguous text detection results. We should incorporate this padding as we look for opportunities for overlay ads, and you may want to adjust the size of the padding to ensure that an overlay advertisement doesn’t get displayed immediately after a subtitle, for example.
We can use this resulting data from Amazon Rekognition to measure how long a piece of text appears on the screen, and then we can calculate when there is no text displayed. That’s what we want, ultimately – a number of seconds in the region at the bottom of the screen where there is no text. That’s where we can insert an overlay ad without any overlap of text on the screen.
Ultimately, the work of the second Lambda function is to look at all of the detected text and find gaps of a sufficient length where there is no text in the selected area of interest at the bottom of the screen. The following is a diagram that illustrates this idea:
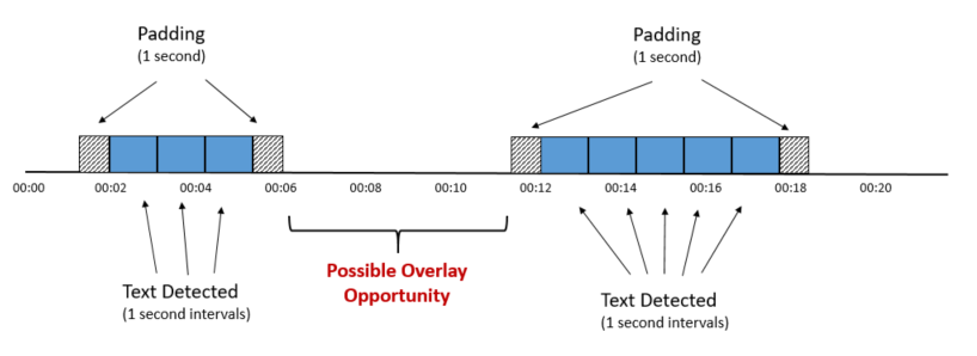
As you can see, two blocks of text have been found, the first from 00:02 to 00:05, and the second from 00:12 to 00:17. Adding one second of padding to the ends of each reveals a potential five second opportunity for an overlay ad from 00:06 to 00:11.
This is the general approach that the second Lambda function takes – merging consecutive one-second text detections into contiguous blocks of time, adding padding on both ends, and then looking for open spots between those blocks.
The output from this second Lambda can be saved in many different forms, depending on your need. For example, if you need the data stored in a database for easy retrieval in the future, the results can be written into a relational database like one of the ones supported by Amazon Relational Database Service (Amazon RDS), or they can be stored into Amazon DynamoDB for a key/value retrieval approach. The code associated with this article writes the results into a text file saved in an S3 bucket, although that can be customized based on your needs.
Conclusion
By leveraging the text detection abilities of Amazon Rekognition you can automatically find opportunities for overlay ad insertion, saving you time and effort. Because text detection is a complex problem with many possible edge cases, it’s always a good idea to have a human review the results, but this approach can serve as a good starting point.
Amazon Rekognition provides a number of useful functions, and it may be beneficial to incorporate it into your media processing pipeline. Aside from detecting opportunities for overlay ad placements, you can search for objects (like a bug), specific people, and more. Please see the documentation for Amazon Rekognition for more information.
The use case described here is based on work performed in collaboration with SFL Scientific, a data science consulting firm and AWS Machine Learning Competency Partner. Working on behalf of a multinational media organization, SFL Scientific partnered with the AWS Envision Engineering team to develop and optimize an Amazon Rekognition and Lambda deployment to perform the detection at above 99% accuracy.