AWS for M&E Blog
Reading the defense: How the NFL and AWS quantify coverage responsibility
While many aspects of football have been thoroughly analyzed with modern metrics, our understanding of defensive coverage schemes remains one of the last major untapped areas in football analytics. Tackles, sacks, and passing yards can be easily quantified. However, determining who was responsible for covering whom—and how well they did it—has historically been a manual judgment call. It has relied on coaches’ and scouts’ playback film studies and experience rather than box scores.
For years, NFL fans, analysts, and coaches have had to piece together coverage assignments by hand—watching replays, interpreting pre-snap alignments, and inferring intent from player movement. Even in this data-rich era, the numbers couldn’t precisely reveal which defender was tasked with covering specific receivers, or how those assignments shifted mid-play. While broad classifications of team coverage schemes exist—such as Cover 1, Cover 3 or Quarters—there was no way to break this down to individual responsibilities.
To address this challenge, the NFL Next Gen Stats team partnered with Amazon Web Services (AWS) to build a new AI framework called Coverage Responsibility. It tackles one of the hardest problems in football analytics: automatically determining and updating, frame by frame, each defender’s coverage responsibility on every passing play.
A problem that looks nothing like traditional stats
Coverage responsibility isn’t like counting passing yards or logging a tackle. It’s a complex prediction problem. Defenders must continuously adjust their coverage decisions based on the evolving routes, quarterback movements, and positioning of offensive players and their defensive teammates.
Assignments can change in the blink of an eye. A slot corner might start in player-to-player coverage, but pass off his receiver when a crossing route brings another defender into position. A safety might disguise his role by lining up in a two-deep shell before rotating down to cover a tight end in the flat.
Capturing this complexity meant building models that could do more than only track proximity. The system had to understand context, cooperation, and deception—all from raw player tracking data and imperfect human labels. It was a challenge in representation learning, as well as in prediction.
Borrowing from self-driving cars
The breakthrough came from outside football entirely. AWS engineers recognized that the problem of interpreting coverage was structurally similar to what autonomous vehicles face. You need to track the trajectories of multiple agents over time, each influencing the others, and predicting their roles in a larger system. In self-driving vehicles, those influencing agents are cars, pedestrians, and cyclists; in football, they’re defenders, receivers, and the quarterback.
The team adapted a spatial-temporal transformer architecture—a model designed to jointly reason over spatial relationships and temporal dynamics. Rather than operating through separate layers, the model uses attention heads that can attend across both spatial (player-to-player relationships within a frame) and temporal (evolution of these relationships across frames) dimensions simultaneously. This allows it to capture complex interdependencies. For example, how a cornerback’s positioning influences (and is influenced by) the safety behind him across multiple timesteps, or how a linebacker and nickel corner coordinate their coverage responsibilities as the play develops.
By combining these dimensions, the model could learn to see football the way an experienced defensive coordinator does: not as isolated positions, but as a living, shifting structure.
One backbone, three models
With the backbone in place, the team didn’t build one model—they built three, each addressing a different, but connected, subproblem. Using the same architecture and feature pipeline for all three created consistency and meant improvements in one area often benefited the others.
Model 1: Coverage assignments
The first model assigned a coverage responsibility to every defender on every frame of a play. There were nearly twenty possible responsibilities in the NFL taxonomy (from deep half and deep third to hook-curl and flat).
Because plays are run in both directions, positions were normalized so the offense always moved left to right in the model’s coordinate system. Additional features captured velocities, accelerations, and relative positions between defenders and eligible receivers.
One of the biggest challenges was label noise. In reviewing the data, the team found that human annotators were sometimes wrong and often in subtle, hard-to-detect ways. In some cases, the model’s predictions were more consistent with the video than the provided label. This label noise put an artificial ceiling on measured accuracy, which came in around 88%. However, the team believed the true performance was higher.
The most intriguing capability was the model’s sensitivity to disguise. By comparing pre-snap predictions to post-snap reality, the system could quantify how often and how effectively a team disguised its coverage. This is something coaches talk about constantly, but previously wasn’t captured without intensive manual charting from domain experts.
In production, these zones aren’t hand-drawn—they’re the model’s own predictions rendered over the tracking data. What you see in Figure 1 is what the algorithm thinks, frame by frame.
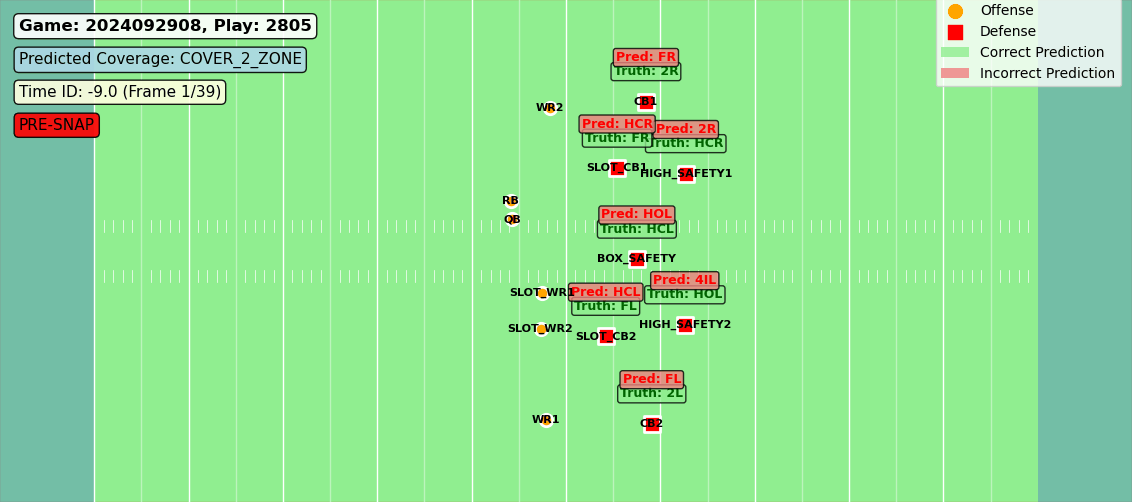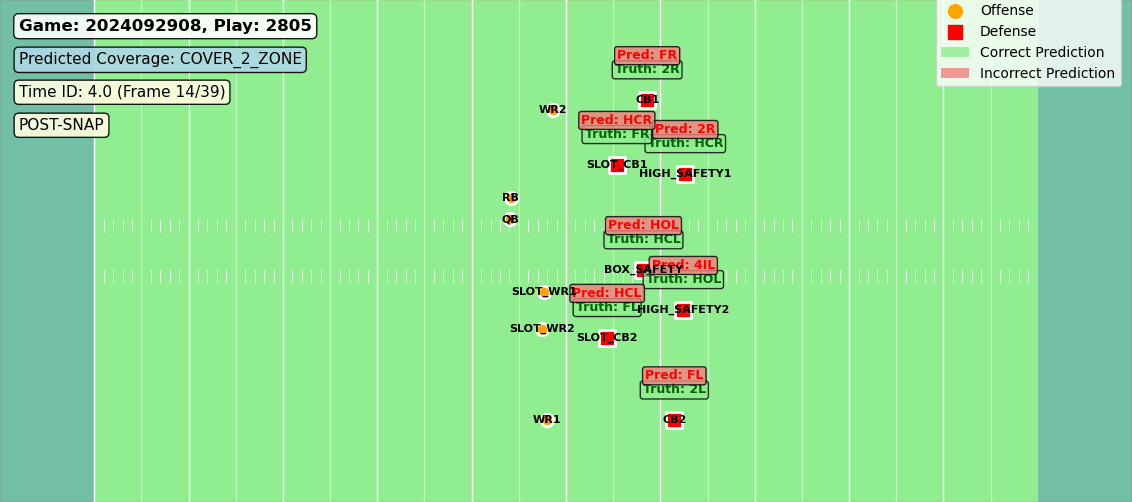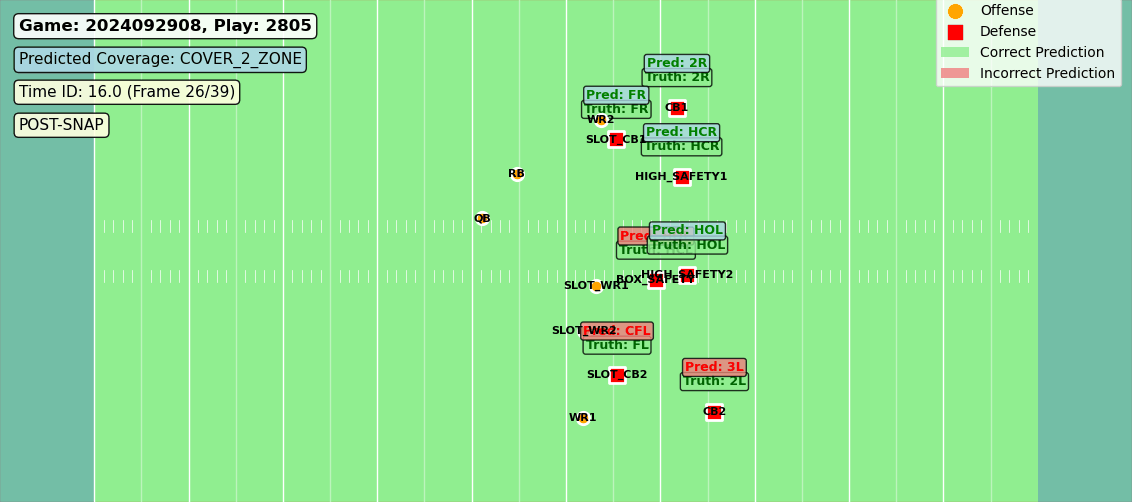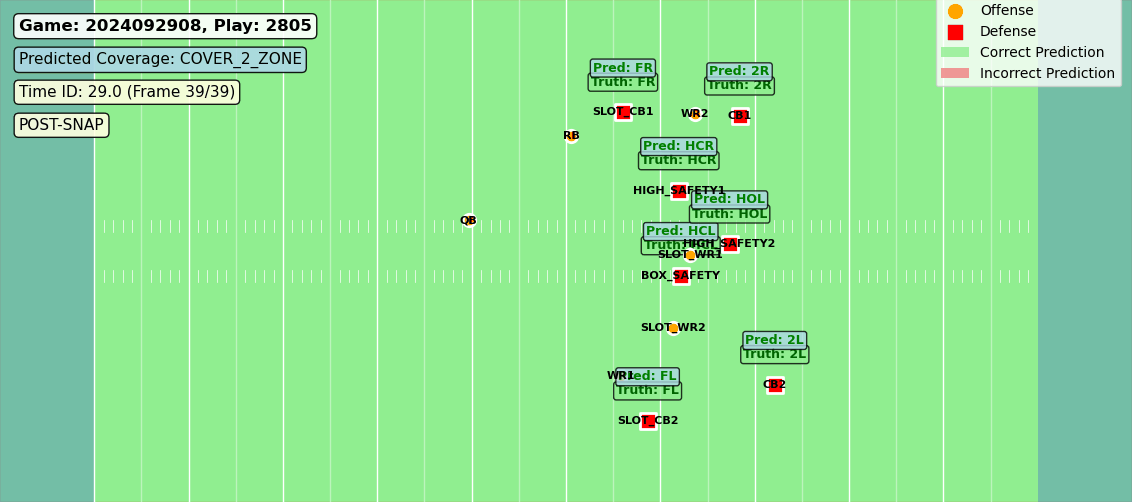
Figure 1: Predictions compared to labels for each offensive players’ coverage assignment.
Model 2: Defender–receiver matchups
The second model tackled the question of matchups: who is covering whom?
Before this, the Next Gen Stats team used a rule-of-thumb approach—use the nearest defender to a receiver at the end of the play. That broke down on plays, such as a high-low in-zone coverage, where the underneath defender was occupied by a shallower route.
The new model, using the same spatial-temporal backbone, generated frame-level matchup predictions, then solved for player-to-player assignments using the Hungarian algorithm. This let the system capture handoffs in player-to-player coverage and the fluid boundaries of zones.
This matchup output became a key building block for other stats. It made double coverage detection quicker by finding two defenders assigned to the same receiver. It also fed directly into the third model, improving its stability.
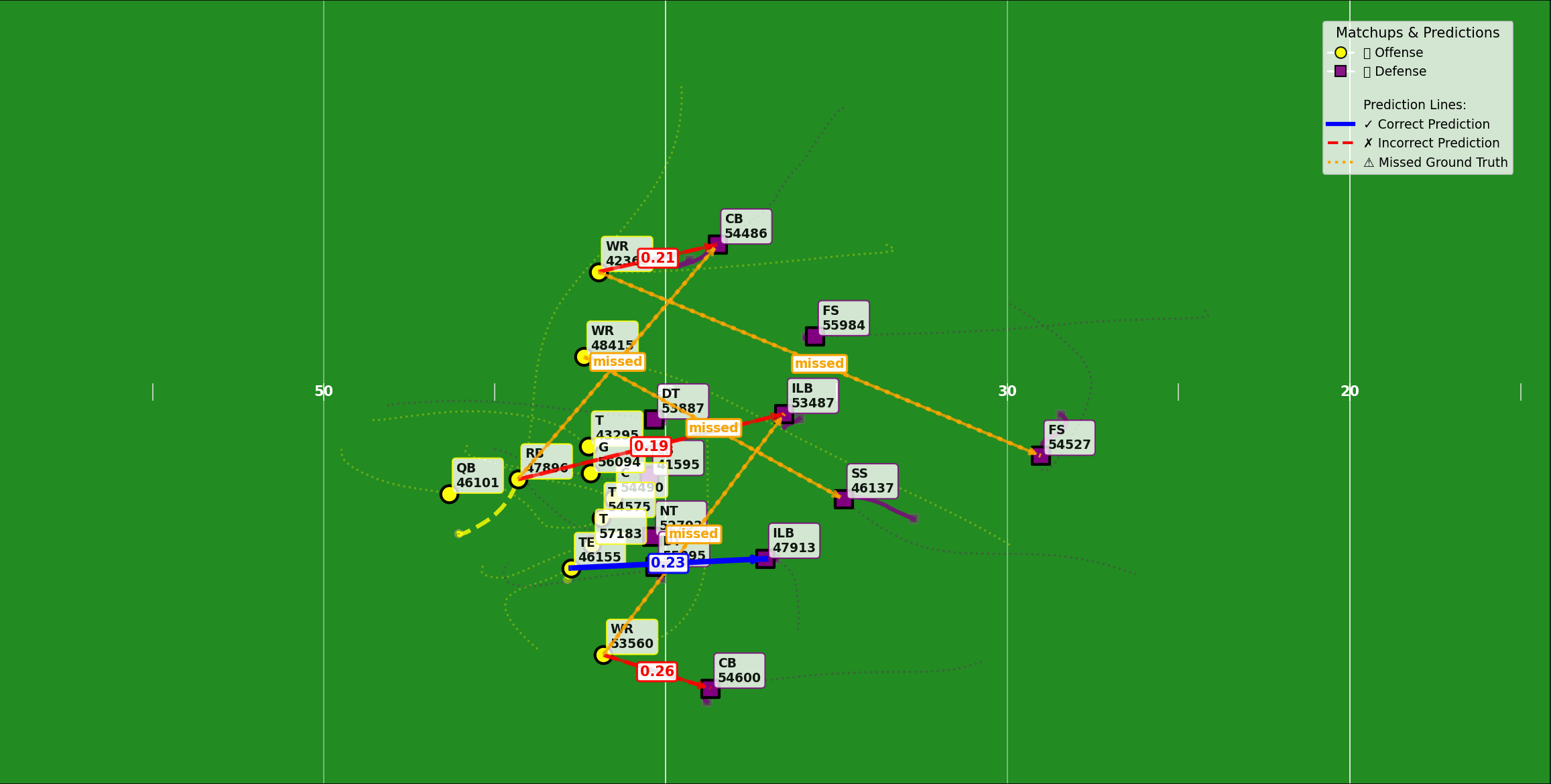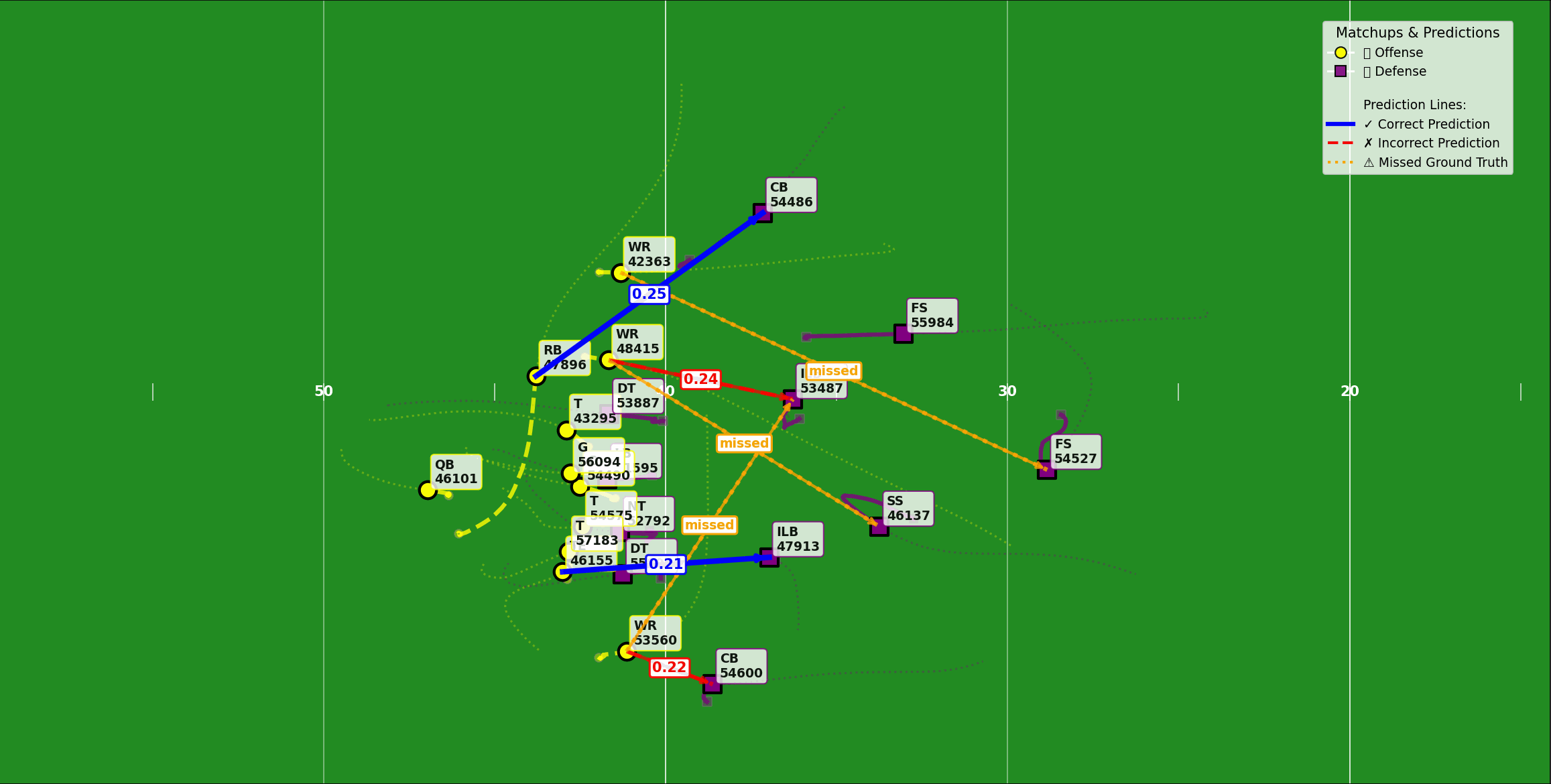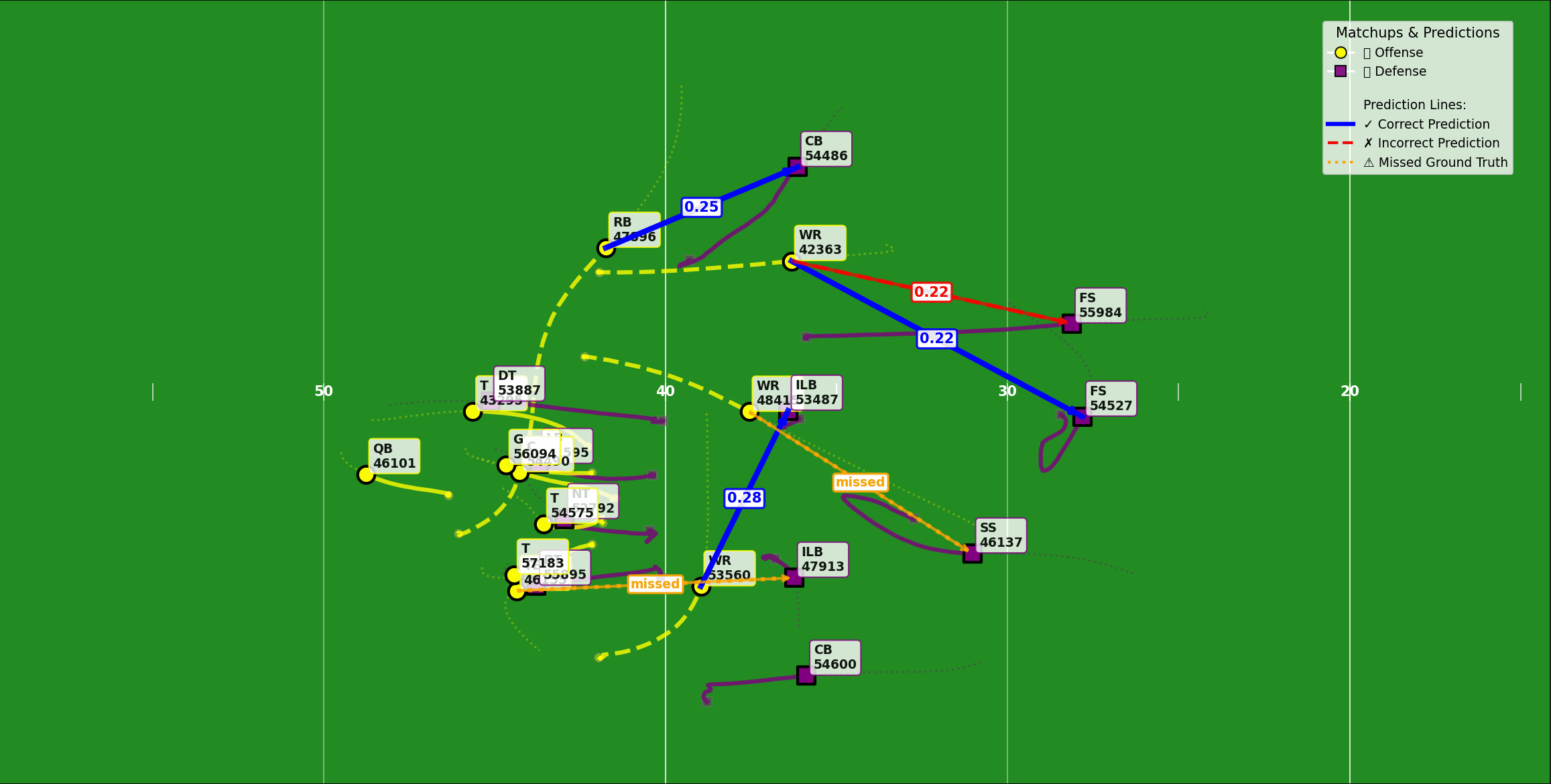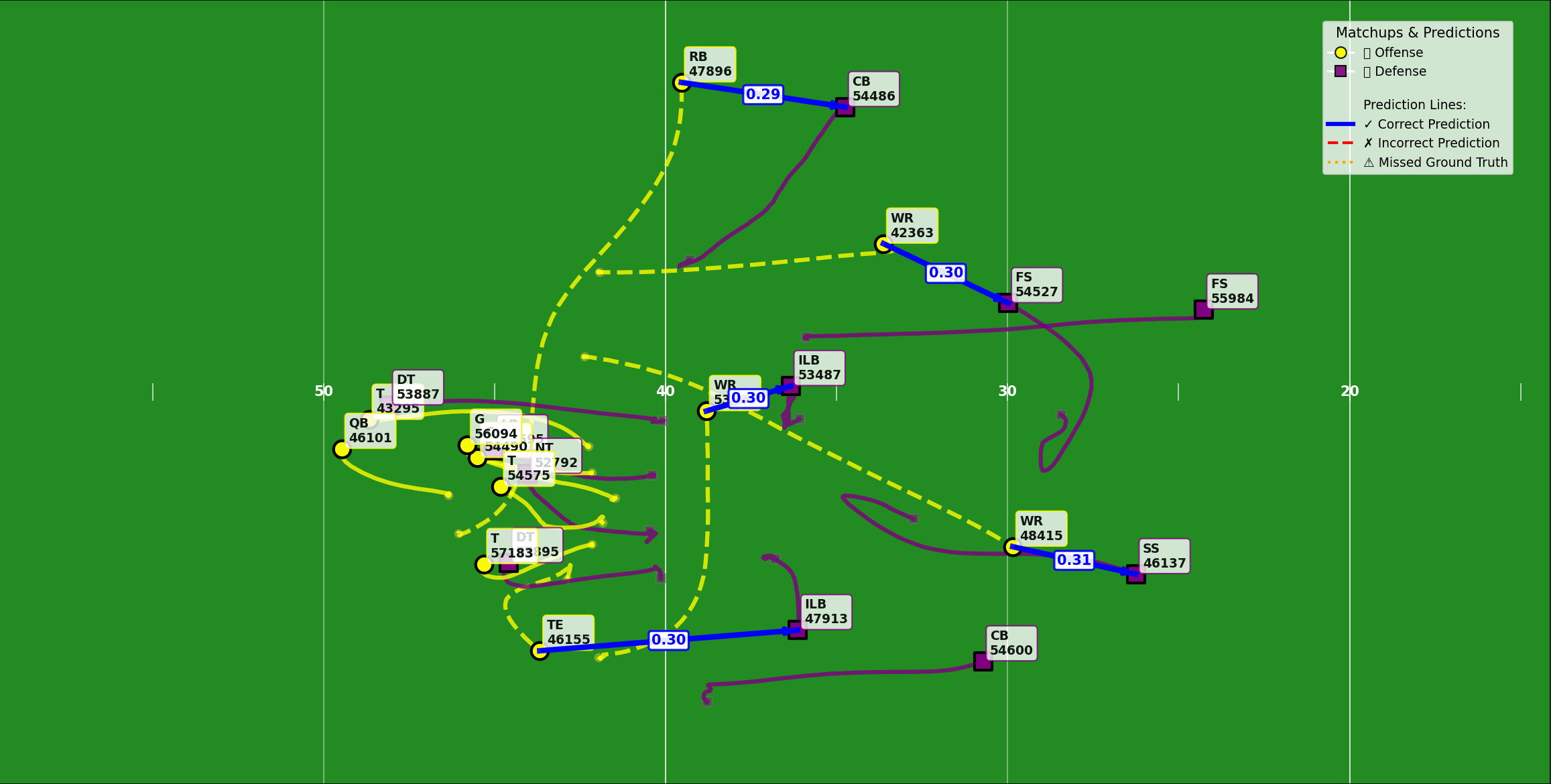
Figure 2: Defender-receiver matchup for each player on the field.
Model 3: Target defender
The final model identified the target defender—the player the quarterback had to beat to complete the pass. In the old rules-based approach, this was just the nearest defender to the targeted receiver at the catch point. According to the NFL, it was incorrect nearly 25% of the time.
While the model’s architecture was similar to the others, it added a crucial feature: a prediction override solution. This solution uses smart game logic to adjust predictions when the model confidence is low. For example, in low model confidence scenarios, it assigns no target defender when the defense is in a preventative alignment (the defense is spread out to stop game-winning scoring) or when receptions occur behind the line of scrimmage.
In other low-confidence cases, it defers to the matchup model’s assignment for the targeted receiver. This post-prediction override created a synergy between the models, boosting accuracy and preventing wild misclassifications.
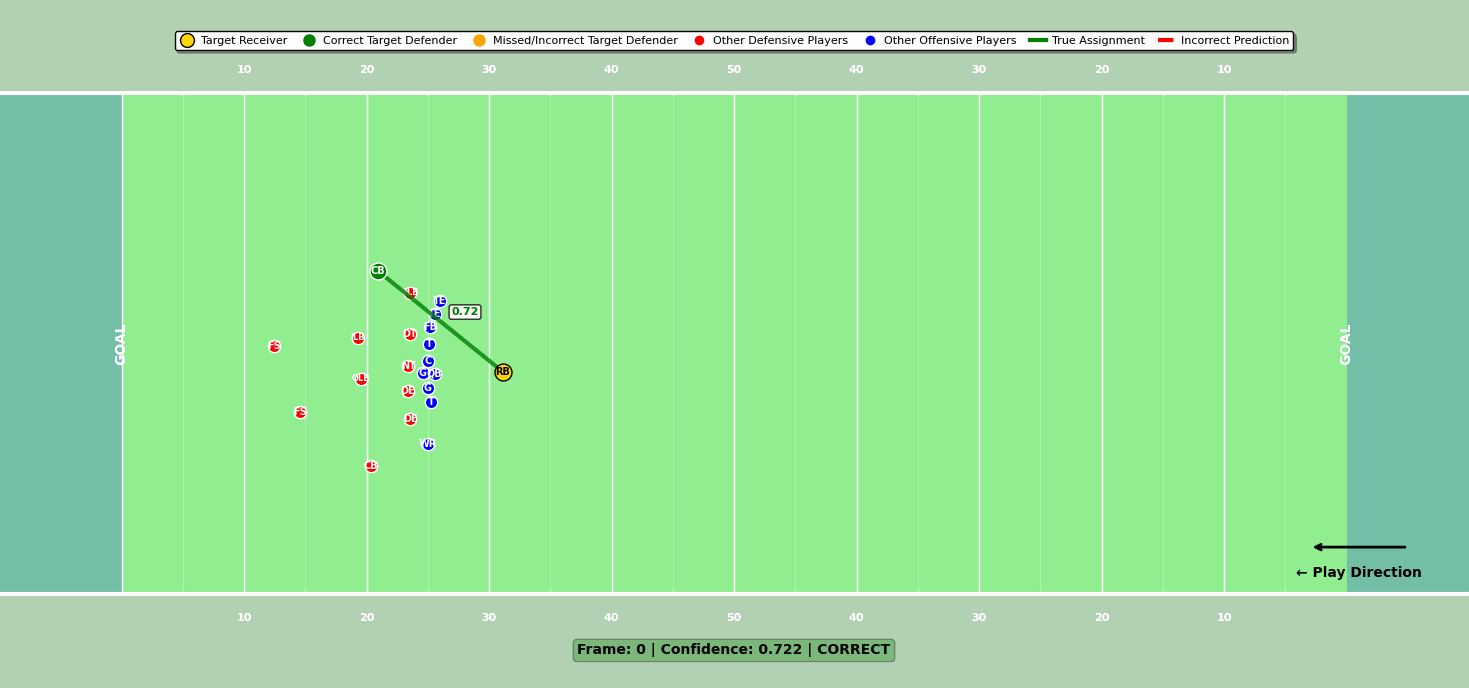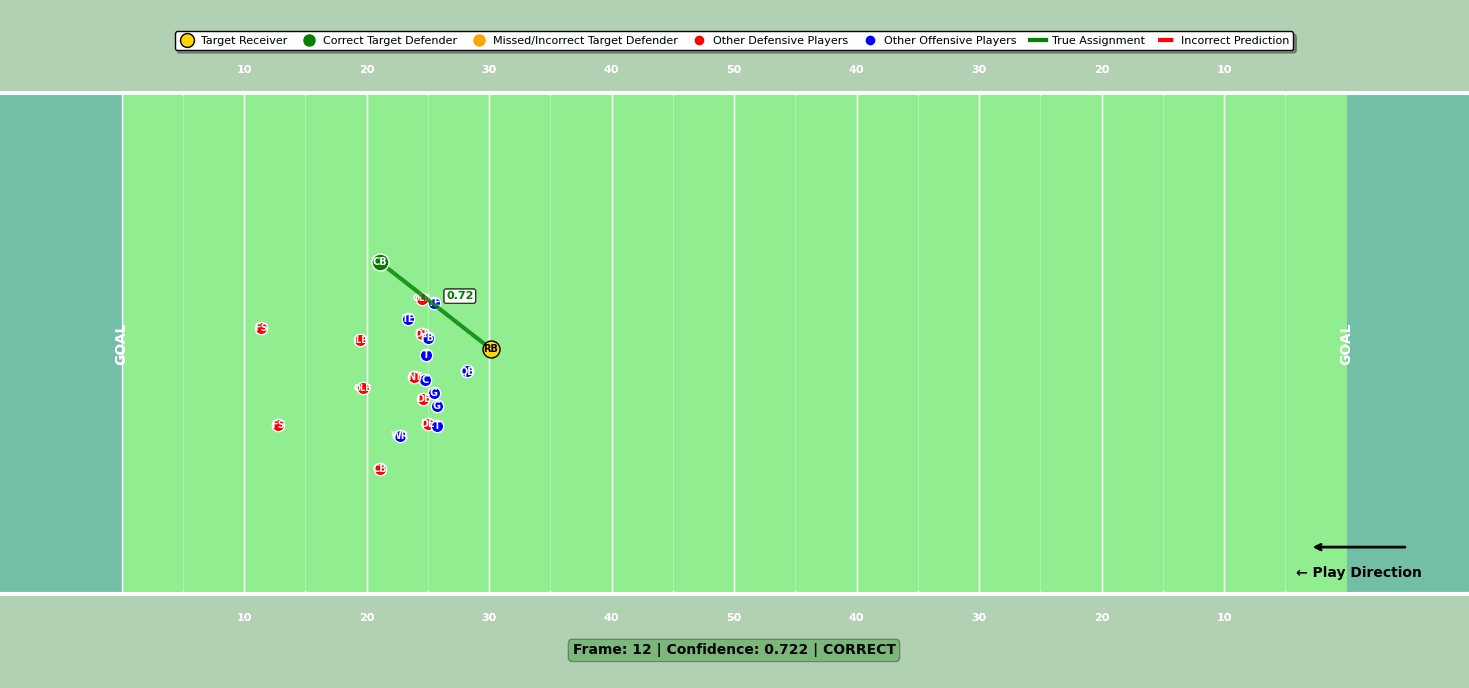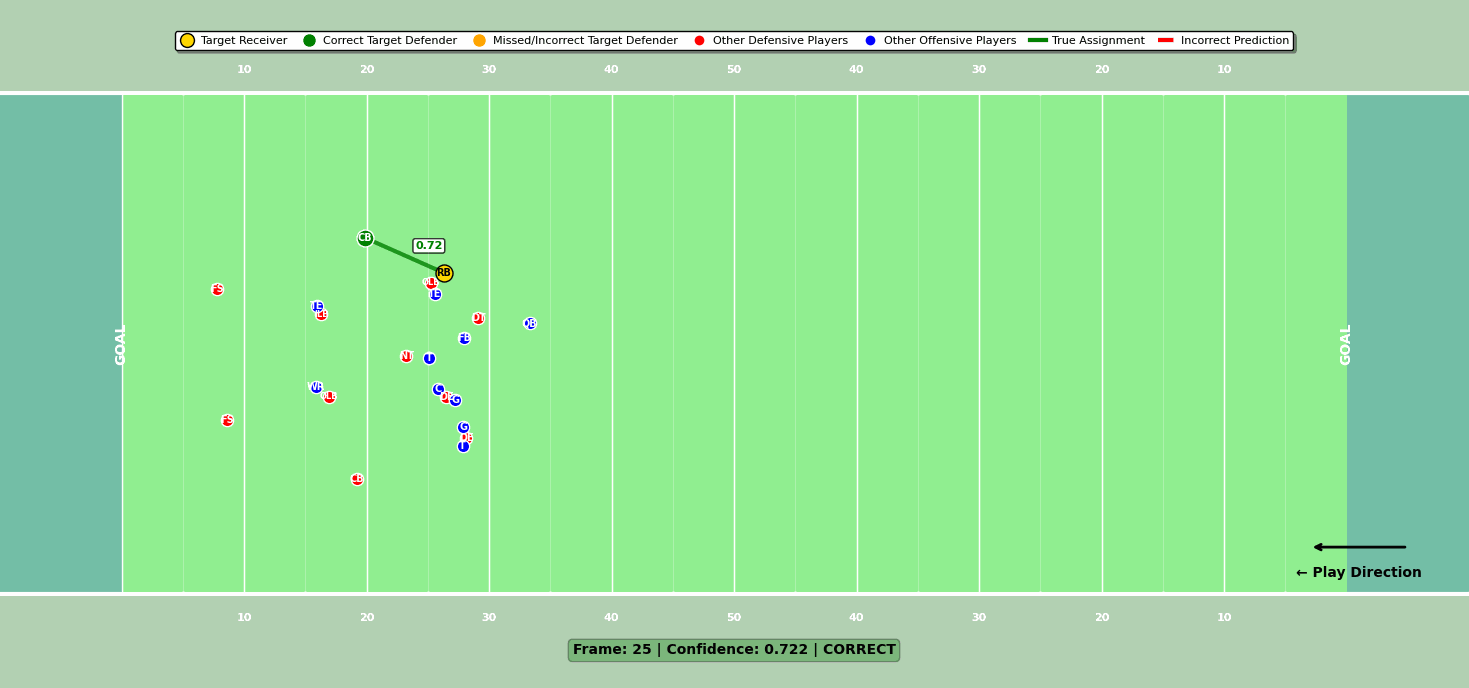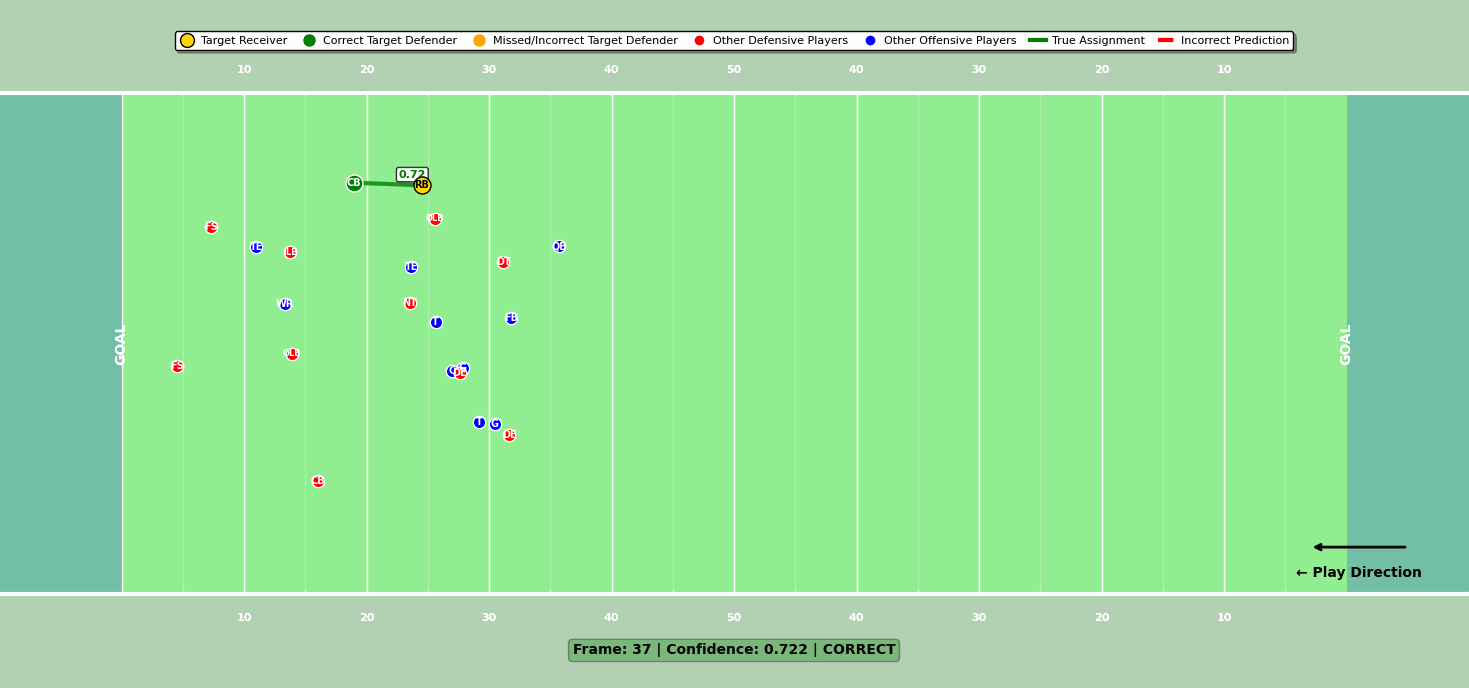
Figure 3: Target defender compared to targeted receiver for a particular play.
Engineering under NFL deadlines
Technically, the three models are impressive. Operationally, building them under NFL timelines was challenging. The project kicked off months after the NFL Combine in late March and had to be integrated into the live analytics pipeline before the next season. Two weeks into the project, key engineers moved to other projects, and new leads had to onboard at full speed.
Amazon SageMaker Studio became the central hub for the work, hosting notebooks, managing distributed GPU training jobs, and tracking experiments. Raw tracking data and processed feature sets lived in Amazon Simple Storage Service (Amazon S3).
Generative AI as a force multiplier
A major accelerator was the generative AI services of AWS. With NFL and AWS leadership approval, the team used Amazon Bedrock code generation to bootstrap model scaffolding, refactor preprocessing pipelines, and quickly generate visualization scripts.
Without AWS services, implementing the spatial-temporal transformer from scratch might have taken 2-3 weeks for each model. With them, the team did it in days. The time saved was able to be spent on the hard problems: handling label noise, tuning attention mechanisms, and improving predictions on rare, but critical, scenarios such as disguised blitzes or broken plays.
From predictions to football insights
When the models were handed off, the Next Gen Stat team wasn’t only getting raw predictions. They were getting a system that could produce an entirely new layer of football analytics. By combining the three model’s outputs, the league could now:
- Rank defenses by their rate of disguise, with hard numbers to back up reputations.
- Quantify double coverage tendencies by team, receiver, and game situation.
- Evaluate the quality of matchups that a receiver faces for a better capture of their degree of difficulty.
Kansas City, for example, emerged as one of the best teams in the league at disguising defensive schemes, validating what coaches had long said about that coaching staff.
Why it matters
For engineers, this project, coverage responsibility, is a case study in adapting advanced architectures to new domains in modular machine learning and generative AI solution design. It was also an experience in building production-grade models under severe time constraints. For football analytics professionals, it’s a leap forward in quantifying something that was once left to the eye test.
On Sundays, the assignments will still shift, the disguises will still work, and even the best quarterbacks will guess wrong. However, now for the first time, the NFL can measure those moments with precision, and with data that can tell the story as clearly as what’s seen on film.
Contact an AWS Representative to know how we can help accelerate your business.