AWS Public Sector Blog
Accelerating federal document processing using Document AI from DMI

If your agency is managing millions of unstructured documents, from eligibility records to case files, this post introduces how DMI Document AI, built on Amazon Bedrock, can help you automate document processing, reduce backlogs, and redirect your team toward higher-value mission work.
Common digitalization challenges across federal agencies and beyond
Your agency might be navigating a massive influx of unstructured, high sensitivity documents every day. These could include regulatory records, eligibility evidence, applications, and supporting documentation such as birth and educational certificates, citizen forms, adjudication packets, and case files.
Many agencies are dealing with backlogs of millions of cases, alongside annual intake volumes that often exceed tens of millions of forms. This creates an urgent need to automate data extraction and validation to speed up approvals, compliance, and mission-critical workflows.
Agencies are noticing encouraging early outcomes from intelligent document processing (IDP) pilots and partial automation. By integrating workflow automation with optical character recognition (OCR) or intelligent character recognition (ICR), some have achieved impressive milestones, such as 50% faster cycle times, based on DMI field experience. However, these pilots also reveal the challenges of scaling enterprise production across various document types, noisy documents, and unstandardized formats.
Many agencies have strategic mandates to digitize hundreds of millions of pages to meet federal digitization mandates.
The challenges are essentially of scale and complexity:
- Billions of paper documents
- Scanned legacy forms with inconsistent layouts
- Aged or degraded paper records, such as legacy handwriting notes, signatures, and historical service records
These document collections require capabilities well beyond traditional OCR. Agencies increasingly need advanced generative AI–driven IDP solutions such as Document AI to:
- Interpret handwritten and inconsistent text
- Classify documents automatically (document understanding)
- Extract key entities such as names, dates, addresses, occupations, and identifiers
- Normalize and validate extracted data against business rules
- Make extracted artifacts searchable, discoverable, and usable for downstream mission operations
Agencies are seeking secure, scalable, and high-accuracy modern IDP solutions that can modernize intake-heavy workflows while maintaining stringent standards for privacy, auditability, and data integrity. To meet these rigorous demands, Document AI uses Federal Risk and Authorization Management Program (FedRAMP) accredited Amazon Web Services (AWS) services, providing a foundation of robust encryption, data residency, and comprehensive audit logging. By building on these pre-authorized components, agencies can support secure, responsible adoption and significantly fast-track FedRAMP certification for their document solutions while maintaining data protection within their AWS environment.
Introducing DMI Document AI solution powered by Amazon Bedrock
DMI Document AI is a robust solution for IDP. Organizations can use it to digitize, comprehend, and operationalize documents. The solution delivers precise document capture and data extraction, paired with AI-driven document type classification, analytics, workflow automation, and automated document generation. In essence, it converts static documents into searchable, actionable business intelligence. It includes three integrated modules: DocuChew, DocuRun, and DocuGen:
- DocuChew – Moving beyond traditional rule-based OCR, uses generative AI–enabled approach to document classification and metadata extraction, using advanced generative AI and multimodal large language models (LLMs) to replace rigid, rule-based workflows. The solution currently supports English-language processing for common document formats, including Word, PDF, images, and Excel. Although traditional OCR systems often struggle with context, handwriting, and layout changes, DocuChew maintains a high extraction accuracy of over 90 percent, based on DMI’s benchmarking using several hundred page data. This provides agencies with a more flexible and sustainable foundation for managing new and evolving document types without the reactive cycle of manual workarounds required by legacy systems.
- DocuRun – Uses Amazon Bedrock Data Automation to transform how organizations handle unstructured multimodal content using pre-built smart document templates known as blueprints. These blueprints apply natural language context to intelligently identify, normalize, and extract data, decoupling extraction logic from underlying code for rapid scaling. To support data integrity, DocuRun incorporates robust validation and error handling through human-in-the-loop workflows. By using Amazon Augmented AI (A2I), the system allows for manual reviews and corrections, providing high accuracy and compliance.
- DocuGen – Is an advanced Retrieval Augmented Generation (RAG) system (patent pending) specifically designed for long document generation (LDG). Traditional RAG pipelines often act as black boxes that collate all available source data, which can lead to wasted LLM processing tokens and outputs that ignore user priorities. DMI’s DocuGen solves this by:
- Prioritizing relevance – Uses a weighted mechanism to make the generated content, such as policies and standard operating procedures (SOPs), align with the specific importance of sources in the document.
- Massive efficiency gains – The module can autonomously produce a more than 200-page word document in approximately 45 minutes, a task that typically takes days to complete. This solution securely stores generated documents in Amazon Simple Storage Service (Amazon S3) for further processing.
The following graphic illustrates these three modules.

Figure 1: Document AI modules
Solution architecture and capabilities
To deliver a secure, scalable, and fully customizable solution, DMI Document AI integrates with core AWS services, using Amazon Bedrock for leading LLMs including Amazon Nova family of models, Amazon Bedrock Knowledge Bases for durable vectorization and embeddings, and Amazon Bedrock Data Automation for intelligent document extraction and smart templates. The solution further supports mission integrity through AWS tenant security isolation, Amazon Bedrock Guardrails, and personally identifiable information (PII) protection for security, while using A2I for human-in-the-loop workflows and AWS CloudFormation for rapid, standardized deployment using infrastructure as code (IaC).
The following diagram illustrates the solution architecture.
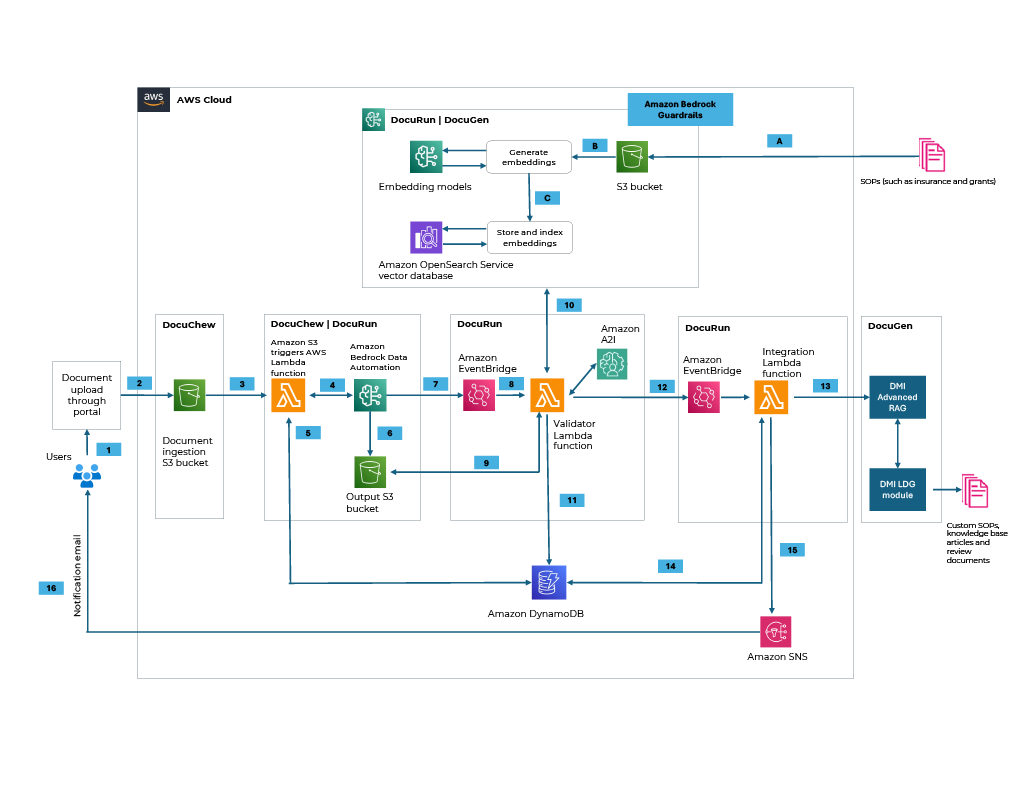
Figure 2: Document AI architecture
The solution is deployed through IaC using AWS CloudFormation templates, enabling quicker deployments. Document AI is deployed within customer’s AWS account, allowing customers to maintain control over their data and avoid vendor lock-in or black-box architectures.
Key solution capabilities
The DMI Document AI solution is a modular, AWS based solution designed to modernize the entire document lifecycle through three core modules: DocuChew (ingestion and extraction), DocuRun (classification and workflow), and DocuGen (advanced document generation). The solution’s end-to-end workflow follows a multistep process that transforms raw data into actionable intelligence and business asset. Here are the steps:
1. OCR-free ingestion – Documents are ingested through automated data pipelines using generative AI, avoiding the limitations of rigid, rule-based OCR.
2. Multimodal analysis – The system handles multipage processing for complex, unstructured data, including PDFs, images, and handwritten records.
3. Intelligent classification – DocuChew uses multimodal LLMs to automatically identify document types and extract metadata.
4. Smart template application – DocuRun uses Amazon Bedrock Data Automation to apply blueprints that use natural language context to identify content structures.
5. Contextual extraction – Data is extracted and normalized from various file types, including tables and images, without custom-coded logic.
6. Entity recognition – Key entities such as names, dates, and identifiers are extracted and validated against business rules.
7. Durable vectorization – Extracted artifacts are vectorized using Amazon Bedrock Knowledge Bases backed by OpenSearch Serverless, creating a long-term memory for LLM-aware processing.
8. Search and discovery – Documents are transformed into searchable artifacts for downstream mission operations.
9. User priority definition – For new long document generation, users begin by assigning weights to identify the relative importance of each data source.
10. Weight validation – The system performs a check to validate user-defined priority weights sum up to 100 percent.
11. Strategic source selection – Based on weights, the system selects content from diverse sources such as agency security docs, past audits, and SOPs.
12. Package aggregation – Relevant content is combined into a single working package.
13. Constraint management – The system automatically confirms the package stays within allowed size and token limits.
14. Autonomous generation – The package is sent to high-performance models to generate targeted, multipage documents.
15. Human-in-the-loop review – The output is reviewed by business users through A2I to support accuracy and compliance.
16. Iterative refinement – User feedback is fed back into the system to refine future results, creating a repeatable loop for continuous improvement.
Security and integrity
DMI Document AI solution is engineered with a defense-in-depth architecture, so that every stage of the multistep process adheres to stringent government mandates for privacy, auditability, and data integrity.
For infrastructure and data sovereignty, the solution is deployed through IaC using AWS CloudFormation templates, allowing for rapid, standardized deployment directly within the agency’s own AWS account. This supports data sovereignty and Amazon Virtual Private Cloud (Amazon VPC) isolation, preventing data from leaving the agency’s secure perimeter or being used to train third-party models. Solution can be augmented with AWS PrivateLink, VPC Endpoints for inter service communication to further security posture.
To maintain a zero trust posture, the solution uses AWS Identity and Access Management (IAM) controls for access and encryption and API security to enforce the principle of least privilege. Data is protected by industry-standard encryption both at rest and in transit, so that sensitive materials such as regulatory records and personnel files remain secure throughout the ingestion and extraction lifecycle.
The system uses Amazon Bedrock Guardrails specifically configured for high-sensitivity federal use cases. Examples of these include:
- PII protection – Automatically detects and masks PII such as Social Security numbers found in eligibility evidence and case files.
- Prompt injection defense – Neutralizes malicious attempts to bypass model constraints or exploit vulnerabilities, referred to as jailbreaking, in AI systems, keeping the system focused only on its mission-critical extraction or generation tasks.
- Content filtering – Prevents the generation of harmful or off-topic content during the creation of documents.
- Governance and compliance – Provides comprehensive audit logging, tracking interactions for full transparency. Because the solution uses FedRAMP-accredited AWS services, agencies can inherit established security controls, significantly fast-tracking the path to final Authority to Operate (ATO) for their implementations. Please refer to Security Reference Architecture for AI for details on securing AI solutions.
An AI-enabled approach for digitization
Traditional unstructured data extraction pipelines are often rule based and limited in their support for recognizing new document types and dynamic adjustment.
Although traditional template-based OCR has been the standard for decades, it’s insufficient for the scale and complexity of current federal datasets. DMI Document AI provides a flexible, OCR-free approach that addresses these limitations.
The following table compares the abilities of traditional OCR and DMI Document AI across a range of features.
| Feature | Traditional OCR | DMI Document AI |
| Handwriting support | Struggles with handwritten content and degraded images. | Designed to interpret handwritten content, signatures, and aged paper records, such as archives, with high precision. |
| Context understanding | Often loses context when layouts change or when dealing with complex structures such as table headers and chart captions. | Uses generative AI and multimodal LLMs to apply natural language context, allowing it to intelligently classify documents and extract data based on meaning rather than rigid coordinates. |
| Deployment time | Takes weeks or more to configure for new document types. | Uses IaC through CloudFormation templates. The entire solution can be configured and deployed in days, providing rapid, measurable value. |
| Maintenance | Forces teams into a reactive cycle of tweaking extraction rules each time form layout changes. | Decouples extraction logic from underlying code using smart templates (blueprints), which allow for seamless updates through straightforward configuration, significantly reducing operational burden. |
DMI’s proprietary advanced RAG: An innovative approach for LDG
Enterprise RAG has been used to create on-demand, high-quality documents for agencies. However, the current RAG pipelines often function as generic systems that include all data elements. This approach leads to blanket ingestion, including non-business essential attributes, resulting in inefficient usage of LLM resources and ignoring priorities preferred by business users.
As an advanced RAG-based solution, DocuGen can create long documents. For example, DocuGen has autonomously generated 200-page documents in only 45 minutes in a representative testing environment. This drastically cuts down time and reduces manual labor and errors.
DocuGen helps the AI workflow produce better content that is contextually relevant by incorporating a proprietary, user-steered prioritization model. Users start by assigning percentage weights (called user-defined weights) to reflect what matters most to them. The system confirms that the percentages add up to 100%. It then uses these weights to decide how to prioritize information from each document source, such as agency security documentation, past audit reports, and existing SOPs.
It selects an optimal portion of content from each source, combines them into a single working package, and helps the package stay within the allowed LLM context window size limits. The system then sends the package along with the prompt to the AI model to generate the targeted content.
Finally, the output is reviewed by the user, using A2I, and the feedback is used to refine future results. This creates a repeatable loop that improves accuracy, relevance, and alignment with business objectives.
Designed for broad application
Agencies are at various stages of technical maturity when it comes to handling unstructured data, and they explore various AI-powered IDP solutions. Some have experimented with proofs of concept (POCs) and generic LLMs such as ChatGPT, while others have limited AI skills and resources. Document AI offers a way to automate tasks more efficiently and manage workloads effectively. It supports modular deployment, allowing each module (DocuChew, DocuRun, and DocuGen) to be deployed independently. Here are the key benefits:
- Deployment – The plug-and-play design integrates seamlessly with existing enterprise systems.
- Customization – Each component can be tailored to meet the specific needs of the agencies.
- Integration – Components can be deployed and integrated within existing environments independently.
Document AI use case examples
Organizations across large federal, defense, civilian, and health sectors can streamline their document operations and expand their capabilities, as demonstrated in DMI’s work with a U.S. Department of Defense organization and multiple other federal customers.
For example, DMI supported a U.S. Department of Defense organization in modernizing its records management system, enabling scalable processing and secure storage of millions of personnel records. This effort enhanced document handling, accessibility, and organization, reducing total cost of ownership significantly while improving the speed and accuracy of working with high-volume document sets.
Some of the most common uses cases:
- Automate digital document intake, processing, and extraction of content such as invoices and case files, reducing data engineering time for business users.
- Use AI to automatically index incoming personnel documents, enabling the reassignment of personnel.
- Generate new documents from existing knowledge bases (such as internal policies and manuals)
- Automate structured and unstructured processing and progress review of grants, reducing review timelines for grant approvers.
Conclusion
DMI, an AWS Advanced Tier Services Partner, helps government agencies cut through document processing burdens by eliminating manual, repetitive tasks and embracing secure, responsible AI. Powered by Amazon Bedrock and Amazon Bedrock Data Automation—and tailored for mission operations—it accelerates the shift to a modern, outcome-focused organization.
With Document AI, agencies can handle different document types, streamline document compliance, and automate document workflows with human-in-the-loop review without the need to overhaul their systems.
DMI brings together an integrated set of mission-driven transformation services and solutions to help US defense, intelligence, and federal civilian agencies evolve through the next wave of digital transformation and beyond. Combining the best of both public and private sector expertise, DMI provides managed services, application development, digital strategy and consulting, cloud transformation, cybersecurity, and AI services to deliver human-centric outcomes at scale while maintaining the highest standards for reliability, performance, and security.
To learn more about DMI’s Document AI capabilities and how agencies are applying this approach in production environments, visit the DMI AWS Partner Profile or contact our team at engage@dminc.com. You can also connect with DMI to explore use cases aligned to your agency’s document processing and modernization priorities.