AWS Web3 Blog
Building Personalized Web3 Experiences with ❜embed’s AI Recommendation Platform on AWS
The decentralized web has unlocked significant opportunities for user-owned digital experiences, with Web3 applications built on public blockchains (onchain) processing billions of dollars in daily transaction volume across thousands of protocols. However, despite this rapid growth, most Web3 platforms still rely on rudimentary content discovery mechanisms—chronological feeds, basic search, and manual curation—don’t utilize the rich behavioral data available onchain. While traditional web and mobile applications such as social media platforms and e-commerce stores (‘Web2’ platforms) leverage recommendation systems to drive engagement and user satisfaction, Web3 applications struggle to deliver personalized experiences that improve user retention and platform value due to the cost and technical complexity involved in adapting these systems to the Web3 space.
Web3 platforms must leverage intelligent systems that can interpret complex onchain behaviors, social signals, and content preferences in real-time. When users interact with decentralized applications, mint non-fungible tokens (NFTs), transact, or engage with social protocols like Farcaster, they generate valuable behavioral data that powers personalized experiences. Yet, most platforms fail to capitalize on this opportunity, leaving users to navigate information overload without intelligent guidance or recommendations.
In this post, we will explore how ❜embed built a scalable, intelligent recommendation engine on AWS that transforms how Web3 applications understand and engage their users, examining the technical architecture, AWS services integration, and real-world results achieved by development teams using the platform.
The challenges with transforming onchain data into intelligence in real-time
Building effective recommendation systems for Web3 applications presents unique engineering and infrastructure challenges compared to traditional content platforms. There is a high volume of data from multiple diverse sources to collect and analyze, and new data is created at high velocity. This data volume, diversity and velocity make training, fine-tuning and operating machine learning models for content recommendations in Web3 extremely complex. This complexity requires engineering teams with deep technical knowledge and experience with blockchains, Web3 applications, data engineering and AI/ML to solve. These challenges influenced the design and implementation of solution ❜embed built on AWS.
Challenge 1: Data Volume and Velocity
Onchain data exists across multiple blockchains, layer-2 solutions, and decentralized protocols, each with different data formats, access patterns, and latency characteristics. Real-time data ingestion requires scalable infrastructure to monitor blockchain events, process transaction logs, and normalize data across heterogeneous sources. The complexity multiplies when considering the volume and velocity of onchain activity. Ethereum, a public blockchain, processes over one million transactions daily, while protocols like Farcaster generate hundreds of thousands of social interactions. Each transaction contains multiple data points—sender, receiver, contract interactions, token transfers, and metadata—that must be processed, enriched, and made available for real-time recommendation engines. Traditional database architectures struggle with this combination of high-volume writes and low latency reads required for personalized experiences. The sheer volume of data to work with for onchain activity makes model fine-tuning a scalability challenge.
Challenge 2: Adapting machine learning operations to Web3
The data volume challenge extends beyond infrastructure to machine learning operations at scale. Training effective recommendation models requires processing terabytes of historical onchain data while continuously incorporating new behavioral signals. Unlike traditional social platforms where user actions are relatively simple (likes, shares, follows), Web3 user behavior spans complex multi-step interactions across onchain apps like DeFi protocols, NFT marketplaces, social networks, and governance systems. Model fine-tuning becomes particularly challenging when considering the diverse behavioral patterns unique to Web3. A user might simultaneously be a DeFi power user, NFT collector, and occasional social participant, with each context requiring different recommendation strategies. The temporal nature of onchain data adds another layer of complexity; transaction patterns that indicate interest today might be irrelevant within hours as market conditions change. Scaling machine learning operations to handle this data velocity while maintaining model accuracy requires purpose-built MLOps infrastructure and domain expertise.
Challenge 3: Specialized engineering skills required
Perhaps the most significant barrier to building effective Web3 recommendation systems is the breadth of specialized expertise required. Development teams must master blockchain infrastructure and protocol integration while simultaneously building AI/ML pipelines. They need data engineers who understand both traditional analytics platforms and blockchain-specific tools, machine learning engineers familiar with recommendation systems and graph neural networks, and infrastructure specialists capable of managing real-time data processing at scale. This expertise requirement creates a substantial resource burden for Web3 development teams. Small startups lack the resources to hire across all necessary domains, while larger organizations face months or years of development time to build internal capabilities. The rapidly evolving Web3 ecosystem compounds this challenge—new protocols, standards, and data sources emerge continuously, requiring constant adaptation of data pipelines and models. ❜embed addresses these challenges by providing an AI recommendation engine specifically designed for Web3 applications. Rather than building and maintaining complex recommendation infrastructure, development teams can integrate ❜embed’s APIs to deliver personalized content experiences powered by real-time onchain behavioral data. The platform handles the entire recommendation pipeline—from data ingestion across multiple blockchains to model training and real-time inference—enabling Web3 applications to focus on user experience rather than infrastructure complexity.
Solution
❜embed’s solution architecture (Figure 1) addresses the fundamental challenges of Web3 recommendation systems through a three-layer approach that separates concerns while maintaining tight integration for optimal performance. This architecture leverages AWS services to handle the complexity of real-time data processing, vector similarity search, and model inference at scale.
Figure 1: Architecture Diagram
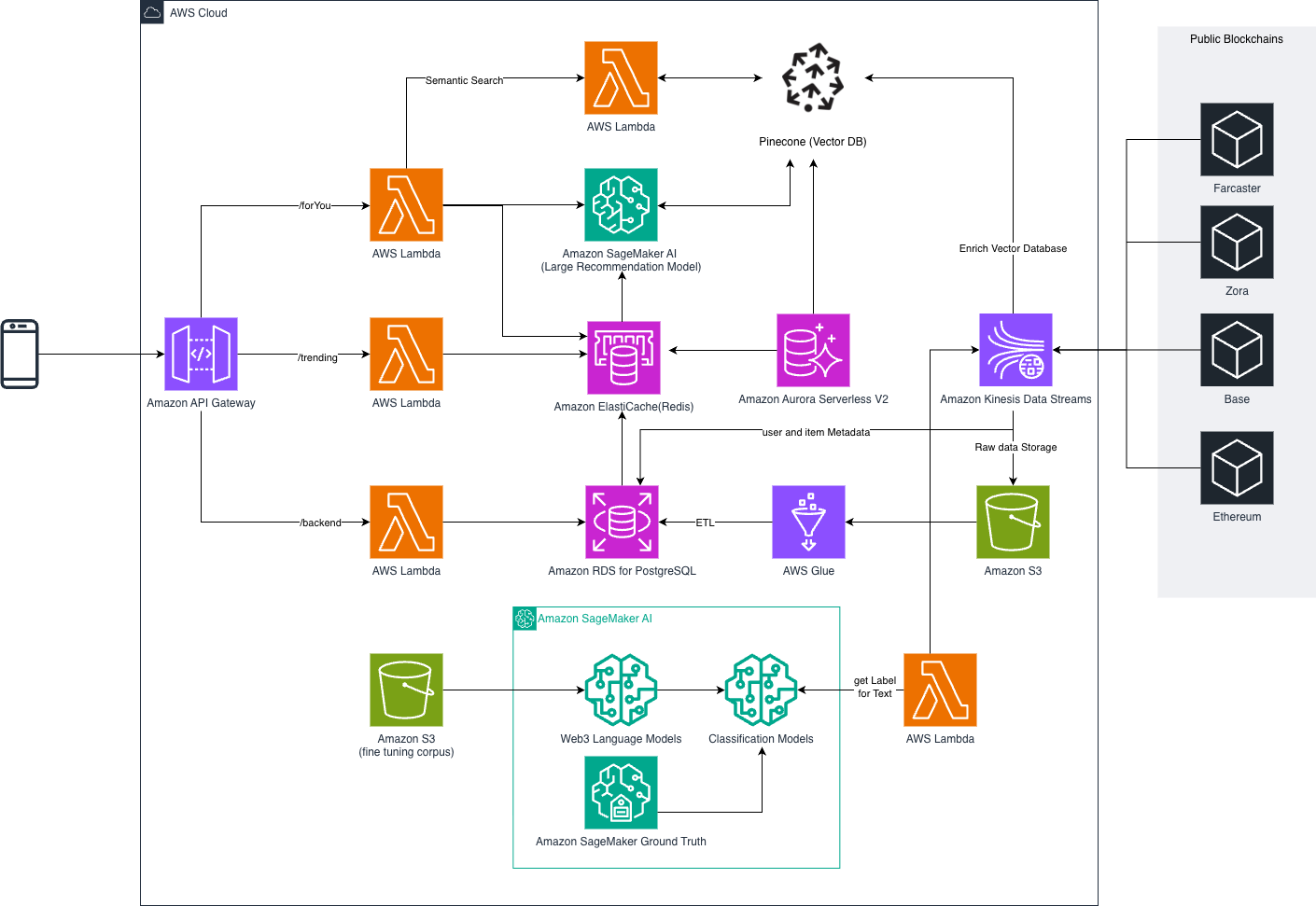
Layer 1: Content Enrichment and ❜ embedding Pipeline
The foundation of ❜embed’s recommendation engine begins with data ingestion and enrichment across multiple Web3 data sources. This layer processes onchain transactions, social interactions from protocols like Farcaster and Zora, as well as NFT metadata, DeFi activity and more to create rich behavioral profiles for users and content.
❜embed’s data pipeline leverages Amazon Kinesis Data Streams to handle high-velocity onchain data ingestion, processing millions of blockchain events daily. The platform monitors multiple blockchain networks simultaneously, using AWS Lambda functions to normalize and enrich raw transaction data with contextual information. For social protocols like Farcaster, ❜embed processes cast content, engagement patterns, and social graph relationships to understand both explicit preferences and implicit behavioral signals.
The content enrichment process transforms raw onchain data into machine learning-ready features through several stages, organized into three key feature categories: user_features, item_features, and interaction_features. Classification models process text content from social posts and feed semantic classifications into item_features. Image and video analysis processes NFT and Token metadata and visual content of posts. This provides a first layer of defense against malicious and unwanted content. Transaction analysis identifies patterns in DeFi usage, token preferences, and protocol interactions to build an array user_features and help with personalization as well as spam detection. This is achieved using advanced graph analysis using proprietary ❜embed Rust library that implements real-time reputation and belief propagation algorithms which are hosted in memory-optimized Amazon Elastic Compute Cloud (EC2) instances that can handle +1B nodes graph in memory.
AWS Glue, Crawler, and Amazon Athena handles ETL processing of raw onchain data for offline model building, with Amazon Relational Database Service (RDS) for PostgreSQL, Amazon DynamoDB,
and Amazon ElastiCache storing user and item metadata that feeds into the vector embedding pipeline. Onchain data is streamed in real-time and converted into high-dimensional vector embeddings for items and users using a custom trained Large Recommendation Model (LRM) which captures relationships beyond simple categorical matching. These embeddings enable the system to identify subtle behavioral patterns—for instance, recognizing that users interested in certain DeFi protocols might also engage with specific types of social content or tokens.
Lastly, the embeddings pipeline focuses on merging interaction_features and the rest of item and users features in real time using Flink to power evaluation of ranking, as well as continuous training of downstream models (See Layer3).
Layer 2: Hybrid Vector-Graph Database for Real-Time Retrieval
❜embed’s second layer implements a hybrid database architecture that combines vector similarity search and relational queries with fast feature retrieval. This approach addresses the unique challenge of Web3 data, where user behaviors span multiple protocols and platforms with interconnections that traditional databases struggle to represent effectively.
The platform utilizes Pinecone as its vector database, accessed via a VPC endpoint for secure connectivity, storing user and item embeddings for similarity queries across millions of behavioral patterns. AWS Lambda functions power semantic search capabilities, enabling ❜embed to quickly identify users with similar onchain behavioral patterns or find content that matches specific user preferences. The vector database maintains real-time updates as new onchain activity generates fresh embeddings, ensuring recommendations reflect current user interests rather than historical patterns.
In addition to the vector search capabilities, ❜embed uses Amazon Aurora Serverless v2 to fetch candidates that satisfy some user requirements like content from creators a user is following or content with specific metadata. To compliment retrieval, Amazon ElastiCache, a Redis OSS-compatible in-memory data store service, acts as a feature store for user and item features, enabling sub-millisecond retrieval of feature categories for real-time recommendations. This in-memory approach ensures that feature lookups don’t become a bottleneck in the recommendation pipeline.
Through its console, ❜embed provides multiple ranking functions with weights that can be customized for different dimensions: trendiness, popularity, user interest, closeness to creators, freshness, and many other dimensions can be tuned by ❜embed customers. The console is also used to put moderation safeguards in place, maintained by customer experience and product management teams. Ultimately, items returned include trending and popular content alongside personalized recommendations that respect the users’ ownership over their onchain history. The hybrid approach enables ❜embed to combine the speed and efficiency of Serverless store: Pinecone’s vector similarity, Amazon Aurora Serverless v2 and Amazon ElastiCache’s ultra-fast feature retrieval, while Lambda-powered semantic search and trending signals refine results to consider both user preferences and broader content momentum across multiple protocols and platforms.
Layer 3: Custom models for Web3
The third layer of ❜embed’s architecture focuses on the machine learning models that power personalized recommendations. Rather than relying on generic recommendation algorithms, ❜embed has developed and fine-tuned models specifically for Web3 behavioral patterns and content types, enriching recommendations based on real-time events stored as embeddings, labelling models, and objective-oriented reranking.
Classification models trained with Amazon SageMaker Ground Truth provide ground truth labeling of text content for feature enrichment. Time-series forecasting models power trending and popular content identification, to surface content gaining momentum before it becomes widely popular. The objective specific models serve as the core recommendation engine, combining embeddings from Pinecone, feature categories retrieved from the Amazon ElastiCache feature store, and real-time onchain data. These models leverage reinforcement learning that incorporates implicit onchain behaviors (that can be sent by customers like impressions) and Web3-specific signals, using the real-time features to predict each user’s specific next onchain action given a specific customer objective. ❜embed runs multiple online contextual bandit models that focuses on specific actions such as swaps, mints, watch that customers can finetune to achieve their own business objectives.
The platform leverages Amazon SageMaker with autoscaling P3 family instances for model training, experimentation, and deployment. Models are fine-tuned on a corpus of 100+ million onchain content pieces and events, enabling them to capture subtle behavioral nuances specific to Web3 users and social content patterns. Reranking models also run on Amazon SageMaker with autoscaling P3 instances, ensuring optimal performance during inference while managing computational costs.
Well-Architected View
❜embed’s architecture follows AWS Well-Architected Framework principles to ensure security, reliability, performance, and cost optimization.
Security: ❜embed implements security through multiple layers. AWS Identity and Access Management (IAM) Roles controls access across all services, while VPC endpoints provide secure connectivity to Pinecone without traversing the public internet. Amazon RDS for PostgreSQL encrypts data at rest, and Amazon ElastiCache clusters use encryption in transit. API Gateway handles authentication and rate limiting for external access, while AWS Secrets Manager securely stores database credentials and API keys used by Lambda functions and SageMaker endpoints.
Reliability: Multi-AZ deployments ensure high availability across Amazon RDS for PostgreSQL and Amazon ElastiCache clusters. Auto Scaling Groups manage EC2 instances for consistent performance, while Amazon SageMaker endpoints provide built-in failover capabilities for ML inference. The architecture separates concerns between real-time serving (Lambda + Amazon ElastiCache) and batch processing (Glue ETL, Flink), ensuring that failures in one system don’t impact others. Load balancers distribute traffic across multiple availability zones.
Performance Efficiency: The hybrid architecture optimizes for different access patterns—Amazon ElastiCache provides sub-millisecond feature retrieval, Pinecone delivers fast vector similarity search via VPC endpoints, and SageMaker P3 instances with autoscaling handle compute-intensive ML workloads. Lambda functions scale automatically for candidate retrieval operations, while CloudWatch monitors performance metrics across all services to enable proactive optimization.
Cost Optimization: Autoscaling SageMaker P3 instances ensure compute resources scale with demand for model training and inference. Serverless Lambda functions eliminate idle costs for candidate retrieval operations. AWS Glue provides managed ETL without infrastructure overhead, while Reserved Instances optimize costs for steady-state workloads like RDS and Amazon ElastiCache. Amazon Simple Storage Service (S3) lifecycle policies manage training data storage costs.
Operational Excellence: The architecture enables monitoring through Amazon CloudWatch across all services. AWS Glue provides managed ETL with built-in error handling and retry mechanisms. SageMaker Model Registry tracks model versions and enables A/B testing of reranking algorithms. Infrastructure as Code (CloudFormation) ensures consistent deployments across environments, while automated scaling reduces operational overhead.
Results
How ❜embed generates value for its customers
❜embed’s implementation delivers measurable improvements across Web3 applications.
- Early adopters report significant engagement increases, with 2-3x uplift in user engagement compared to popular alternatives and enhanced user retention
- Pilot implementations with Embed trained models on expanded multi-chain datasets to personalize prediction market recommendations, show a 5-6x increase in user engagement.
- Content discovery rates show significant improvements, with 50+% of trades now originating from the AI-driven discovery feed, demonstrating the effectiveness of replacing manual curation with intelligent recommendations.
- Developer productivity shows significant gains, with teams reducing time-to-market from months to weeks with the ability to tune the feed using ❜embed’s SDK.
- ❜embed console’s ease of use enables product managers, business owners, as well as engineers to iterate quickly to achieve their objectives.
Conclusion
Building effective Web3 recommendation systems requires addressing unique infrastructure, scalability, and expertise challenges that traditional approaches cannot handle. ❜embed’s three-layer AWS architecture demonstrates how managed services can power AI systems accessible to development teams regardless of size or internal AI expertise.As Web3 applications mature, platforms leveraging rich onchain behavioral data will have significant user acquisition and retention advantages. ❜embed is democratizing access to recommendation capabilities for the Web3 ecosystem via pre-trained models optimized for onchain behaviors, real-time APIs for content discovery and user recommendations, and SDKs for rapid integration. By leveraging AWS’s global infrastructure, ❜embed empowers Web3 applications to deliver consistent, low-latency personalized experiences regardless of their users’ geographic location or the underlying blockchain networks they interact with.
Ready to enhance your Web3 application with high-signal, personalized content? ❜embed is a member of the AWS Partner Network (APN) and has documentation and SDKs to get you started building with their solutions. Learn more with the Coinbase Wallet case study and visit ❜embed’s documentation to start building personalized Web3 experiences today.
About the authors

Yassine Landa
Yassine is the founder and CEO at ❜embed, a web3 native AI and machine-learning platform incubated at a16z crypto startup accelerator in 2023. Previously a Senior Data Scientist at Chainlink Labs and AWS Professional Services team focused on Emerging Technologies.

Anirudh Marc J
Anirudh is a Startups Solutions Architect with Amazon Web Services,. He helps Startups and Web3 projects build and innovate on AWS.