AWS Partner Network (APN) Blog
Analyzing Performance and Cost of Large-Scale Data Processing with AWS Lambda
By Chris Madden, Senior Cloud Architect at Candid Partners
By Aaron Bawcom, Chief Architect at Candid Partners
 |
 |
There are many tools available for doing large-scale data analysis, and picking the right one for a given job is critical.
In this post, I will provide an in-depth analysis of the architecture and performance characteristics of a completely serverless data processing platform.
While the approach we demonstrate here isn’t applicable for every data analytics use case, it does have two key characteristics that make it a useful part of any IT organization’s tool belt.
First of all, this approach has a very low total cost of ownership (TCO). Unlike traditional server clusters, this serverless data processing architecture costs nothing when it isn’t being used.
For ad hoc jobs against large datasets, it can be extremely costly to maintain enough capacity to run those jobs in a timely manner. By using services like AWS Lambda, we can quickly access massive pools of compute capacity without having to pay for it when it’s sitting idle.
Second, because Lambda allows us to run arbitrary code easily, this approach provides the flexibility to handle non-standard data formats easily. Services like Amazon Athena are great for similar types of data processing, but these tools require your data to be stored in predefined standard formats.
At Candid Partners, an AWS Partner Network (APN) Advanced Consulting Partner, we find that many of our customers have large volumes of data stored in various formats that aren’t compatible with off-the-shelf tools.
For instance, the Web ARChive file format (WARC) used in this example isn’t supported by Amazon Athena or most other common data processing libraries, but it was easy to write a Lambda function that could handle this niche file format.
Candid Partners holds AWS Competencies in both DevOps and Migration, as well as AWS Service Delivery designations for AWS Lambda and other services. We have worked with several large enterprises to build solutions that improve agility while minimizing TCO using the AWS serverless platform.
Greping the Web
To demonstrate our approach, we built a basic search service over the Common Crawl dataset that provides an archive of web pages on the internet. In our example, we looked for all instances of American phone numbers, but you could easily use this to do a grep-like search for any regular expression across all of the pages in the Common Craw archive.
The Common Crawl data are organized into approximately 64,000 large objects using the WARC format. A WARC file is a concatenation of zipped HTTP responses. To process one of these files, you need to first split it into individual records and then unzip each of the records in order to access the raw, uncompressed data.
The dataset also provides an index of all the WARC files for a particular crawl. This index is a simple list of Amazon Simple Storage Service (Amazon S3) URLs pointing to all of the WARC files.
The overall architecture for our Lambda-based data processing solution is simple. The URLs of files to be processed are added to Amazon Simple Queue Service (SQS). Each message on that queue is sent to a separate instance of a Lambda function that processes all of the records in that file.
The results and metrics associated with scanning a given file are then placed on a downstream queue, and eventually recorded using custom Amazon CloudWatch metrics.

Figure 1 – Serverless data processing architecture overview.
Polling the Work Queue
AWS Lambda provides a native event source for triggering functions from an SQS queue. This event source works great for most use cases, but there’s a lag in how quickly the integration will consume function concurrency.
Because the work queue goes from a depth of zero to many thousands of messages almost immediately, and because we want to maximize the number of concurrently executing Lambda functions, we decided to implement our own optimized polling mechanism that we refer to as the fleet launcher.
When it starts, the fleet launcher immediately starts 3,000 instances of the worker Lambda function (the initial concurrency burst limit in us-east-1). Every minute thereafter, it continues to add an additional 500 Lambdas to the processing fleet in order to utilize as much concurrency as possible without being throttled.
The worker function starts by checking the work queue to see if there is work available. If not, it simply terminates. Otherwise, it will process the Amazon S3 object referenced in the message.
Once the object is successfully processed, it puts various metrics about the execution on the downstream metrics queue and deletes the message from the work queue.
Finally, the worker function recursively invokes itself, and the process repeats. Since processing messages off the metrics queue doesn’t require a huge spike in concurrency, we use the standard Lambda-SQS integration to trigger a function that updates CloudWatch based on the data captured there.
It’s important to note that by default the regional Lambda concurrency limit for a new account is 1,000.
In order to test the scale we could achieve with this solution, we worked with AWS to raise the concurrency limit on our account in the US East Region (N. Virginia) where we ran the test. For cases where you’re processing less than a few TB of data, this is probably not necessary.
Results and Observations
Our final test run used more than 12,000 concurrent Lambdas to scan over 64,300 individual Amazon S3 objects. In total, the system processed 259 TB of uncompressed data in just under 20 minutes.
The total cost of this run was $162 or about $0.63 per raw terabyte of data processed ($2.7 per compressed terabyte). We scanned a total of 3.1 billion archived HTTP responses and discovered 1.4 billion phone numbers.
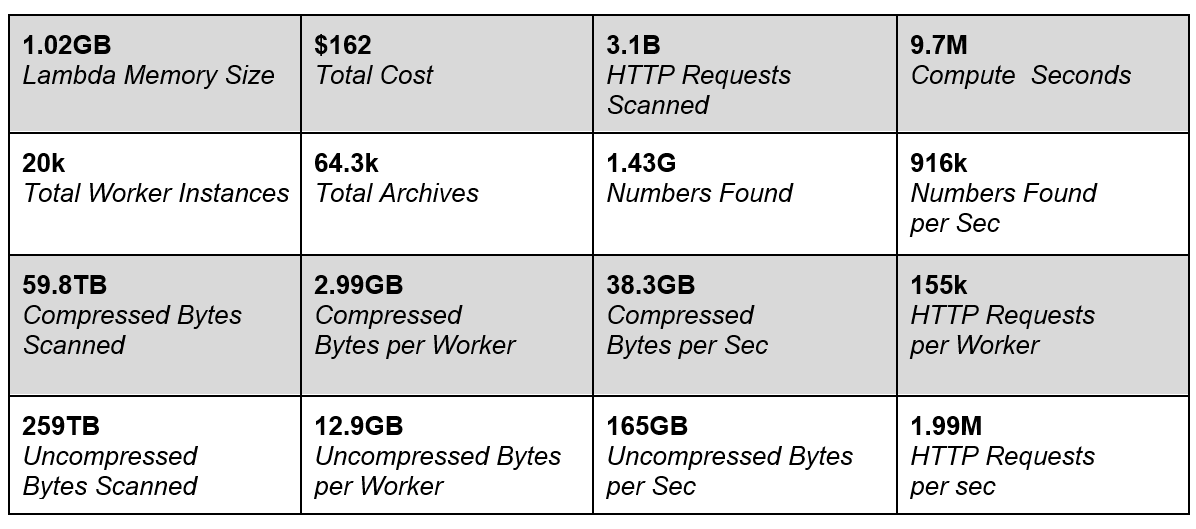 Figure 2 – Dashboard of Candid Partners experiment.
Figure 2 – Dashboard of Candid Partners experiment.
Using this approach, we achieved significant scale using an architecture that provides excellent cost characteristics for ad hoc workloads.
Being able to go from zero to processing nearly two million records per second and back to zero over the course of just minutes is unheard of using traditional server-based architectures. It’s also incredibly powerful across many use cases.
While building grep for archived web pages is probably not a problem many businesses are dying to solve, we see many real-world applications for this approach.
Instead of the Common Crawl archive, a researcher could analyze genomic data in search of the patterns that hold the next breakthrough in the fight against cancer. Or a risk manager could process millions of claims to identify the most at-risk borrowers within minutes.
Imagine running real-time analytics on a flash sale, or if there are millions of Internet of Things (IoT) devices flooding you with data once a day.
Conclusion
If your organization collects and analyzes data, this data analysis pattern could be far simpler than your current methods of performing data analysis.
Your customer experience could improve, your costs of doing business could decrease, and your internal teams could work faster and cheaper than ever before.
If you’re interested in seeing what we did check out Lambda at Scale, or visit the Serverless Repo.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.
|
Candid Partners – APN Partner Spotlight
Candid Partners is an AWS Competency Partner. They combine enterprise-class scale and process with born-in-the-cloud domain expertise to help translate complex business needs into specific technology solutions.
Contact Candid Partners | Practice Overview
*Already worked with Candid Partners? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.