亚马逊AWS官方博客
可实现高性能模型训练的 Amazon EC2 Trn1 实例现已推出
在过去的几年中,深度学习(DL)模型的规模和复杂性在不断增大,导致训练时间从几天延长到数周。训练像 GPT-3 这样大小的大型语言模型可能需要几个月的时间,训练成本随之呈指数级增长。为了缩短模型训练时间并使机器学习(ML)从业者能够快速迭代,AWS 一直在芯片、服务器和数据中心连接等方面进行创新。
在 AWS re:Invent 2021 上,我们宣布推出由 AWS Trainium 芯片提供支持的 Amazon EC2 Trn1 实例预览版。AWS Trainium 针对高性能深度学习训练进行了优化,是 AWS 继 AWS Inferentia 之后构建的第二代机器学习芯片。
今天,我非常高兴地宣布,Amazon EC2 Trn1 实例现已全面推出! 这些实例非常适合在自然语言处理、图像识别等多种应用之间对复杂的 DL 模型进行大规模分布式训练。
与 Amazon EC2 P4d 实例相比,Trn1 实例将为 BF16、TF32 和 FP32 数据类型提供的 TeraFlops 分别提高至 1.4 倍、2.5 倍和 5 倍,并将节点间网络带宽增大到 4 倍,最多可节省 50% 的训练成本。Trn1 实例可以部署在 EC2 UltraClusters 中,这些集群可用作强大的超级计算机,以快速训练复杂的深度学习模型。稍后,我会在这篇博客文章中分享有关 EC2 UltraClusters 的更多详细信息。
全新 Trn1 实例亮点
Trn1 实例目前有两种大小可供选择,并由多达 16 个 AWS Trainium 芯片和 128 个 vCPU 提供支持。它们提供了高性能的网络和存储,以支持高效的数据和模型并行性,这是分布式训练的常用策略。
Trn1 实例可提供高达 512 GB 的高带宽内存和高达 3.4 PetaFlops 的 TF32/FP16/BF16 计算能力,芯片之间采用超高速 NeuronLink 互连。在多个 Trainium 芯片之间扩展工作负载时,NeuronLink 可以帮助避免通信瓶颈。
Trn1 实例也是首批支持高达 800 Gbps 的 Elastic Fabric Adapter(EFA)网络带宽以实现高吞吐量网络通信的 EC2 实例。与上一代相比,第二代 EFA 可提供更低的延迟和最多 2 倍的网络带宽。Trn1 实例还配有多达 8 TB 的本地 NVMe SSD 存储,可实现对大型数据集的超快速访问。
下表详细列出了 Trn1 实例的大小和规格。
| 实例名称
|
vCPU | AWS Trainium 芯片 | 加速器内存 | NeuronLink | 实例内存 | 实例网络 | 本地实例存储 |
| trn1.2xlarge | 8 | 1 | 32 GB | 不适用 | 32 GB | 最高 12.5 Gbps | 1 x 500 GB NVMe |
| trn1.32xlarge | 128 | 16 | 512 GB | 支持 | 512 GB | 800 Gbps | 4 x 2 TB NVMe |
Trn1 EC2 UltraClusters
对于大规模模型训练,Trn1 实例与 Amazon FSx for Lustre 高性能存储集成,并部署在 EC2 UltraClusters 中。EC2 UltraClusters 是超大规模集群,与无阻塞的千万亿位网络互连。这样,您就可以按需访问超级计算机,从而将大型复杂模型的模型训练时间从数月缩短到几周甚至几天。
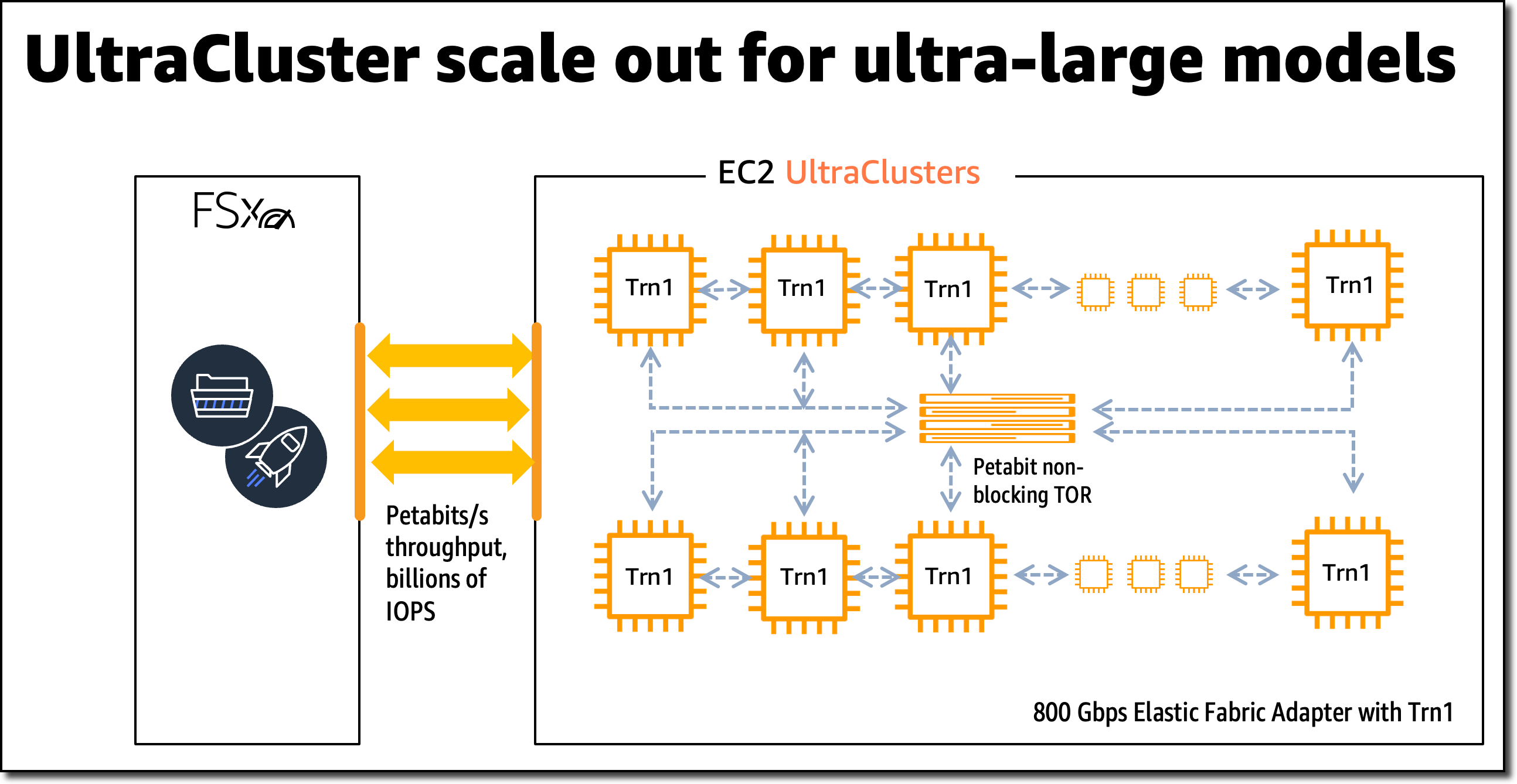
AWS Trainium 创新
AWS Trainium 芯片包括专为深度学习算法构建的特定标量、矢量和张量引擎。与其他架构相比,这样可确保更高的芯片利用率,因此提高了性能。
以下是其他硬件创新的简短摘要:
- 数据类型:AWS Trainium 支持多种数据类型,包括 FP32、TF32、BF16、FP16 和 UINT8,因此您可以为工作负载选择最合适的数据类型。它还支持一种全新、可配置的 FP8(cFP8)数据类型,这与大型模型尤其相关,因为它可以降低模型的内存占用和 I/O 要求。
- 针对硬件进行了优化的随机四舍五入:当启用从 FP32 到 BF16 数据类型的自动转换时,随机四舍五入可实现接近于 FP32 级别的精度和更快的 BF16 级性能。随机四舍五入是另一种四舍五入浮点数的方法,与常用的“四舍五入到最近的偶数”舍入相比,它更适合机器学习工作负载。通过将环境变量
NEURON_RT_STOCHASTIC_ROUNDING_EN=1设置为使用随机四舍五入,您可以将模型训练速度提高多达 30%。 - 自定义运算符、动态张量形状:AWS Trainium 还支持使用以 C++ 和动态张量形状编写的自定义运算符。对于输入张量大小未知的模型(例如文本处理模型),动态张量形状至关重要。
AWS Trainium 与 AWS Inferentia 共享相同的 AWS Neuron SDK,这样,已经在使用 AWS Inferentia 的任何人都可以轻松开始使用 AWS Trainium。
对于模型训练,Neuron SDK 由编译器、框架扩展、运行时库和开发人员工具组成。Neuron 插件与 PyTorch 和 TensorFlow 等常用机器学习框架原生集成。
除预先(AOT)编译以外,AWS Neuron SDK 还支持即时(JIT)编译以加快模型编译速度,并支持用于分步执行的急切调试模式。
要在 AWS Trainium 上编译和运行模型,只需更改训练脚本中的几行代码。您无需调整模型,也不必考虑数据类型转换。
开始使用 Trn1 实例
在这个示例中,我使用可用的 PyTorch Neuron 软件包在一个 EC2 Trn1 实例上训练 PyTorch 模型。PyTorch Neuron 基于 PyTorch XLA 软件包,可以将 PyTorch 操作转换为 AWS Trainium 指令。
每个 AWS Trainium 芯片都包含两个 NeuronCore 加速器,它们是主要的神经网络计算单元。只需对训练代码进行一些更改,即可在 AWS Trainium NeuronCore 上训练您的 PyTorch 模型。
通过 SSH 进入 Trn1 实例,并激活包含 PyTorch Neuron 软件包的 Python 虚拟环境。如果您在使用 Neuron 提供的 AMI,可以通过运行如下命令来激活预安装的环境:
source aws_neuron_venv_pytorch_p36/bin/activate在运行训练脚本之前,您需要进行一些修改。在 Trn1 实例上,应将默认的 XLA 设备映射到 NeuronCore。
我们首先将 PyTorch XLA 导入内容添加到您的训练脚本中:
import torch, torch_xla
import torch_xla.core.xla_model as xm然后将您的模型和张量放到 XLA 设备上:
model.to(xm.xla_device())
tensor.to(xm.xla_device())将模型移到 XLA 设备(NeuronCore)之后,将记录对模型执行的后续操作,以便在稍后执行。这是 XLA 的延迟执行,与 PyTorch 的急切执行有所不同。在训练循环内,您必须使用 xm.mark_step() 标记要在 XLA 设备上优化和运行的图表。没有这个标记,XLA 就无法确定图表在哪里终止。
...
for data, target in train_loader:
output = model(data)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
xm.mark_step()
...您现在可以使用 torchrun <my_training_script>.py 运行您的训练脚本。
运行训练脚本时,您可以使用 torchrun –nproc_per_node 配置用来训练的 NeuronCore 数量。
例如,要对一个 trn1.32xlarge 实例中的所有 32 个 NeuronCore 执行多工作线程数据并行模型训练,请运行 torchrun --nproc_per_node=32 <my_training_script>.py。
数据并行是一种分布式训练策略,它使您能够在多个工作线程之间复制脚本,每个工作线程分别处理训练数据集的一部分。随后,工作线程互相共享各自的结果。
有关受支持的机器学习框架、模型类型以及如何为 trn1.32xlarge 实例之间的大规模分布式训练准备模型训练脚本的更多详细信息,请查看 AWS Neuron SDK 文档。
分析工具
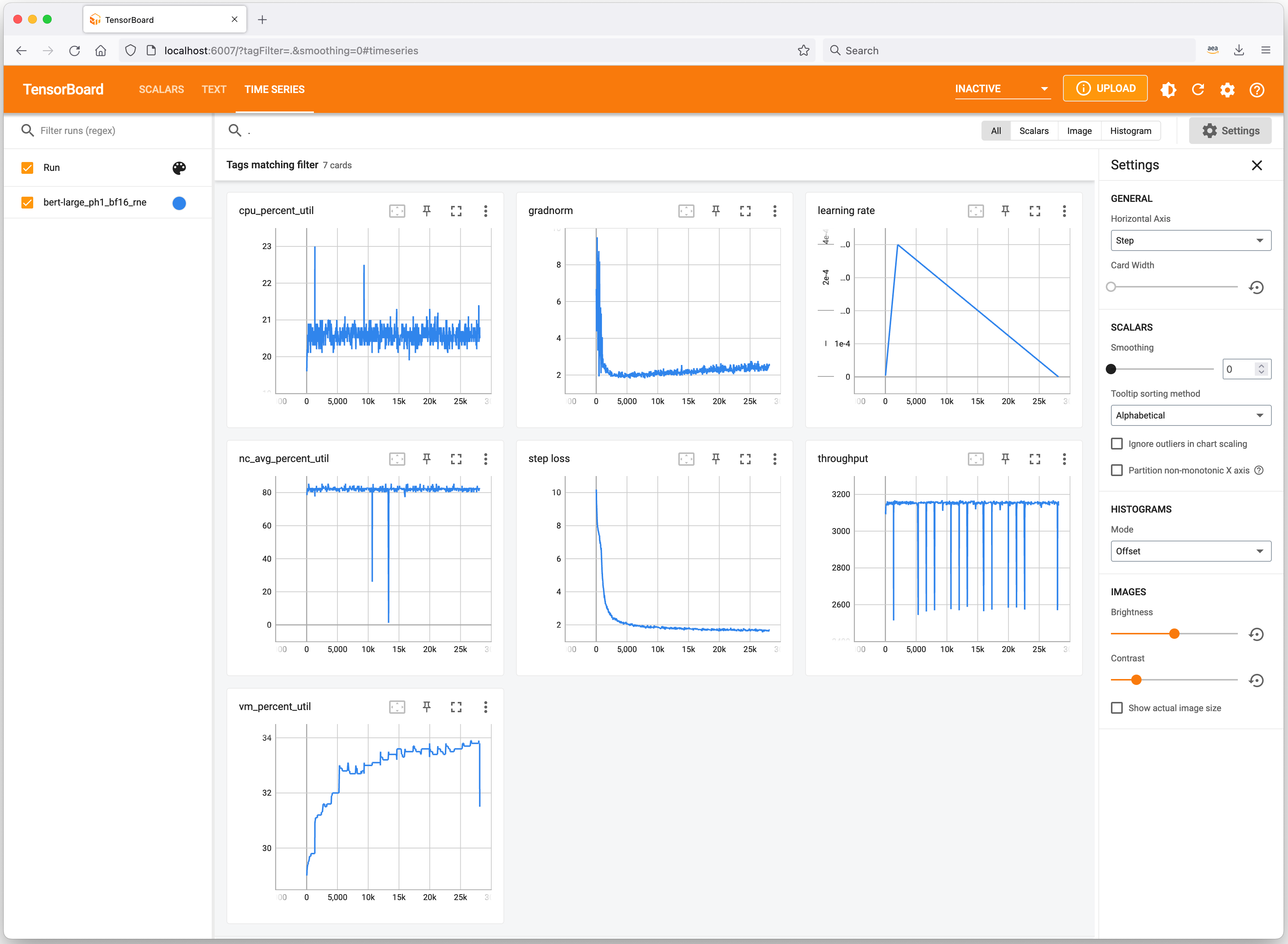
我们来快速了解一些有用的工具,这些工具可以跟踪您的机器学习实验并分析 Trn1 实例的资源消耗情况。Neuron 与 TensorBoard 集成,以跟踪和显示您的模型训练指标。
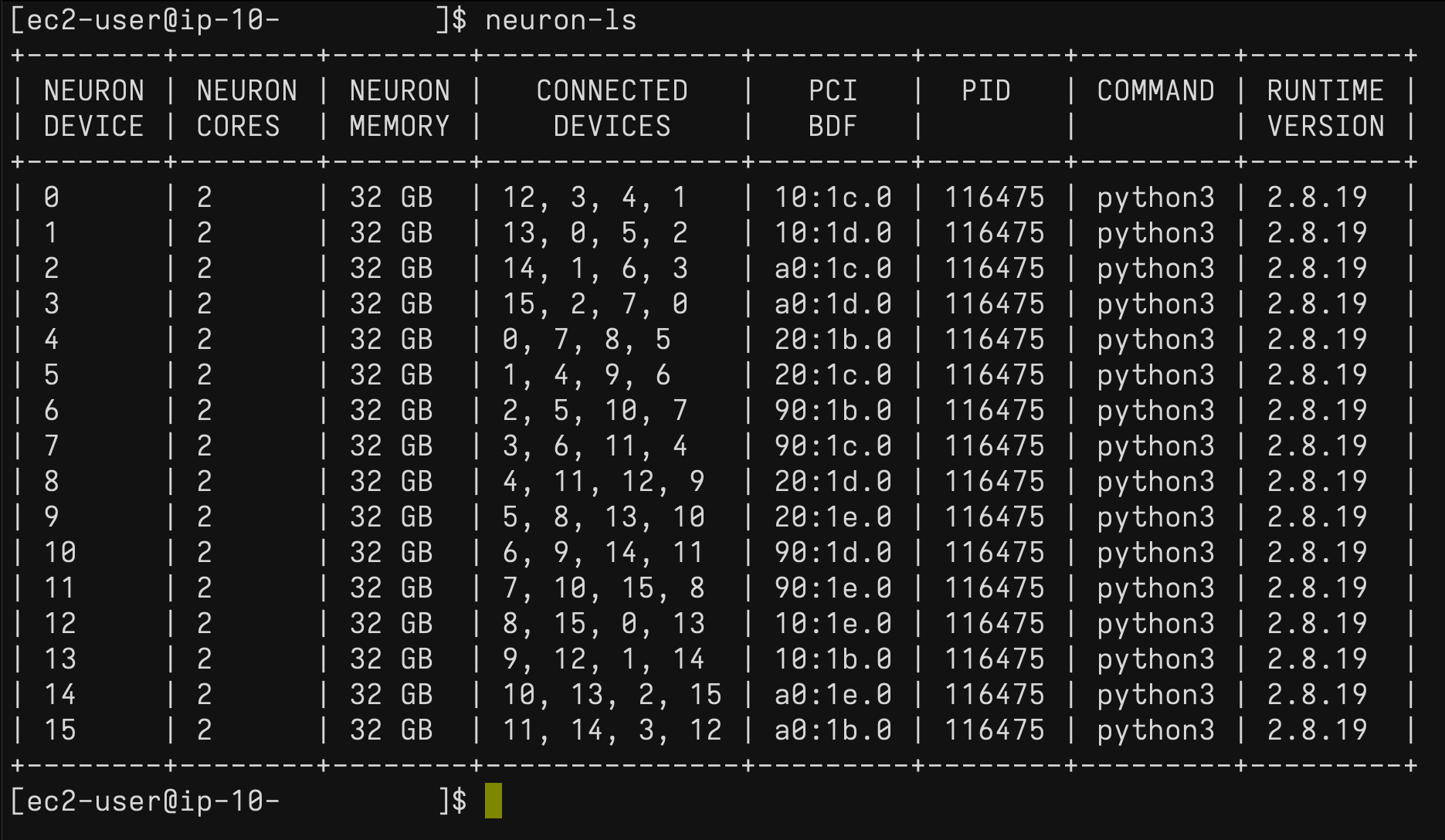
在 Trn1 实例上,您可以使用 neuron-ls 命令来说明系统中存在的 Neuron 设备数量、相关 NeuronCore 计数、内存、连接/拓扑、PCI 设备信息,以及目前拥有 NeuronCore 所有权的 Python 进程:
同样,您可以使用 neuron-top 命令查看 Neuron 环境的概要视图。此视图显示了每个 NeuronCore 的利用率、当前加载到一个或多个 NeuronCore 上的任何模型、使用 Neuron 运行时的任何进程的进程 ID 以及与 vCPU 和内存使用情况相关的基本系统统计信息。

现已推出
现在,您可以在 AWS 美国东部(弗吉尼亚州北部)和美国西部(俄勒冈州)区域以按需、预留和竞价型实例形式或作为 Savings Plan 的一部分来启动 Trn1 实例。和 Amazon EC2 一样,您只需为实际使用的资源付费。有关更多信息,请参阅 Amazon EC2 定价。
可以使用 AWS Deep Learning AMI 来部署 Trn1 实例,并通过 Amazon SageMaker、Amazon Elastic Kubernetes Service(Amazon EKS)、Amazon Elastic Container Service(Amazon ECS)和 AWS ParallelCluster 等托管式服务来获得容器镜像。
要了解更多信息,请访问我们的 Amazon EC2 Trn1 实例页面并发送反馈至 EC2 的 AWS re:Post,或使用您的常用 AWS Support 联系方式。
– Antje