亚马逊AWS官方博客
Amazon EMR Serverless 现全面推出 — 无需管理服务器即可运行大数据应用程序
|

|
 借助 EMR Serverless,您可以运行任何规模的分析工作负载,自动扩展可在几秒钟内调整资源大小,以满足不断变化的数据量和处理要求。EMR Serverless 可自动向上和向下扩展资源,为您的应用程序提供恰到好处的容量,而您只需按实际使用量付费。在预览版期间,客户向我们反馈,表示 EMR Serverless 很具性价比,因为他们不必为应对需求高峰而过度配置资源,避免了额外成本的产生。他们不必操心调整实例大小或应用操作系统更新,可以专注于更快地将产品推向市场。Amazon EMR 提供各种部署选项来运行应用程序以满足各种需求,例如 Amazon Elastic Compute Cloud (Amazon EC2) 上的 EMR 集群、 Amazon Elastic Kubernetes Service (Amazon EKS) 集群、 AWS Outposts 或 EMR Serverless。
借助 EMR Serverless,您可以运行任何规模的分析工作负载,自动扩展可在几秒钟内调整资源大小,以满足不断变化的数据量和处理要求。EMR Serverless 可自动向上和向下扩展资源,为您的应用程序提供恰到好处的容量,而您只需按实际使用量付费。在预览版期间,客户向我们反馈,表示 EMR Serverless 很具性价比,因为他们不必为应对需求高峰而过度配置资源,避免了额外成本的产生。他们不必操心调整实例大小或应用操作系统更新,可以专注于更快地将产品推向市场。Amazon EMR 提供各种部署选项来运行应用程序以满足各种需求,例如 Amazon Elastic Compute Cloud (Amazon EC2) 上的 EMR 集群、 Amazon Elastic Kubernetes Service (Amazon EKS) 集群、 AWS Outposts 或 EMR Serverless。
- Amazon EC2 集群上的 EMR 适用于对应用程序运行要求最大的控制和灵活性的客户。借助 EMR 集群,客户可以选择 EC2 实例类型来增强某些应用程序的性能,自定义 Amazon 机器映像 (AMI),选择 EC2 实例配置,自定义和扩展开源框架,以及在集群实例上安装其他自定义软件。
- Amazon EKS 上的 EMR 适用于希望在 EKS 上实现标准化以跨应用程序管理集群或在同一集群上使用不同版本的开源框架的客户。
- AWS Outposts 上的 EMR 适用于希望在 Outpost 内距离其数据中心更近的位置运行 EMR 的客户。
- EMR Serverless 适用于希望避免管理和操作集群,仅使用开源框架运行应用程序的客户。
当您使用 EMR 版本构建应用程序(例如使用 EMR 6.4 版本进行 Spark 作业)时,可以选择在 EMR 集群、EKS 上的 EMR 或 EMR Serverless 上运行该应用程序,无需重新编写应用程序。这使您能够为给定的框架版本构建应用程序,并保留灵活性,以便根据未来运营需求更改部署模式。
Amazon EMR Serverless 入门
要开始使用 EMR Serverless,您可以使用 Amazon EMR Studio,这是一项免费的 EMR 功能,可提供端到端的开发和调试体验。借助 EMR Studio,您可以创建 EMR Serverless 应用程序(Spark 或 Hive),为您的应用程序选择开源软件的版本,提交作业,检查正在运行的作业的状态,以及调用 Spark UI 或 Tez UI 以进行作业诊断。
在 EMR Serverless 控制台中选择入门按钮后,您可以使用预配置的 EMR Serverless 应用程序创建和设置 EMR Studio。
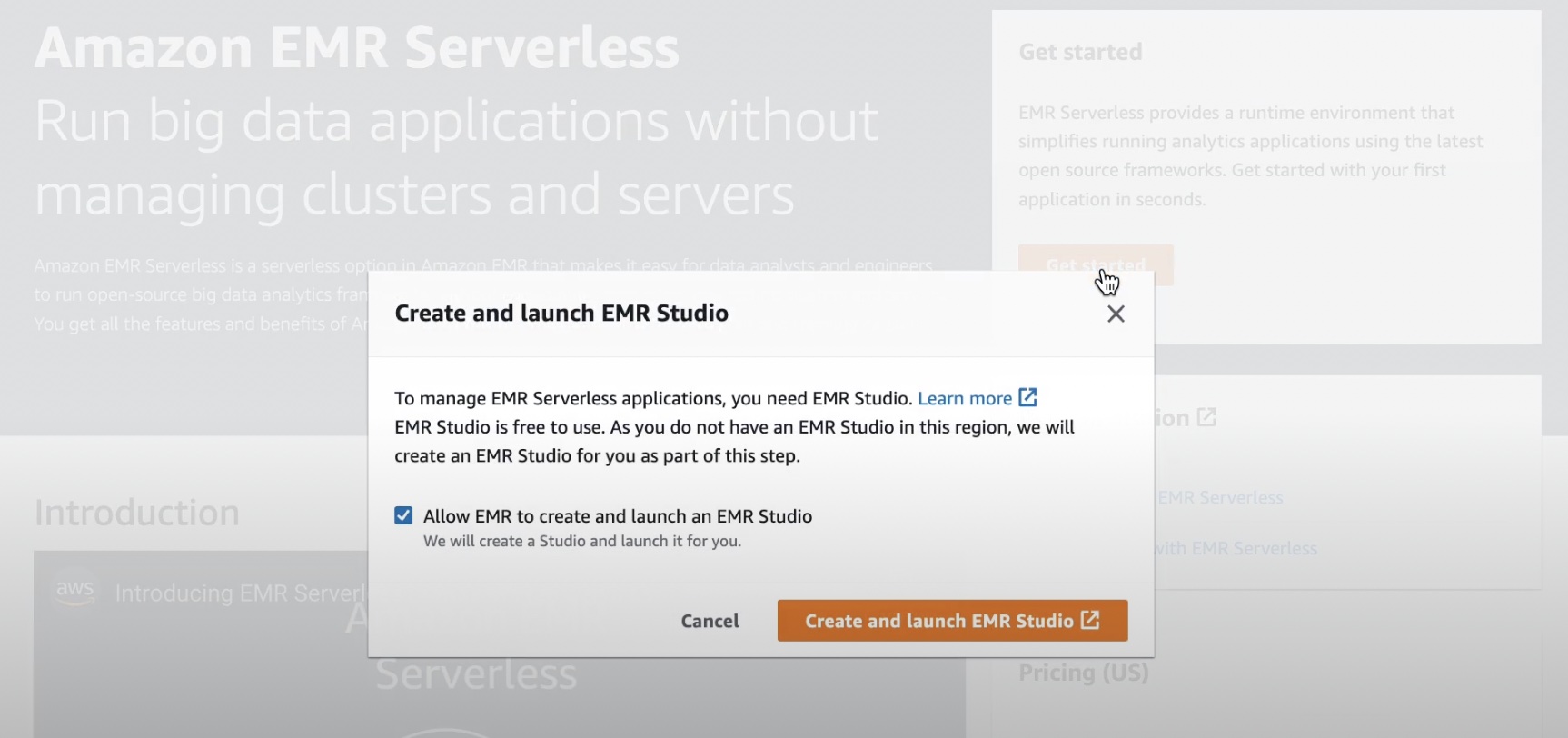
在 EMR Studio 中,当您在“Serverless”菜单中选择应用程序时,可以创建一个或多个 EMR Serverless 应用程序,然后为您的使用案例选择开源框架和版本。如果您想要单独的逻辑环境用于测试和生产或用于不同的业务线使用案例,则可以为每个逻辑环境创建单独的应用程序。
EMR Serverless 应用程序结合了 (a) 您希望用于开源框架版本的 EMR 发行版本和 (b) 您希望应用程序使用的特定运行时,例如 Apache Spark 或 Apache Hive。
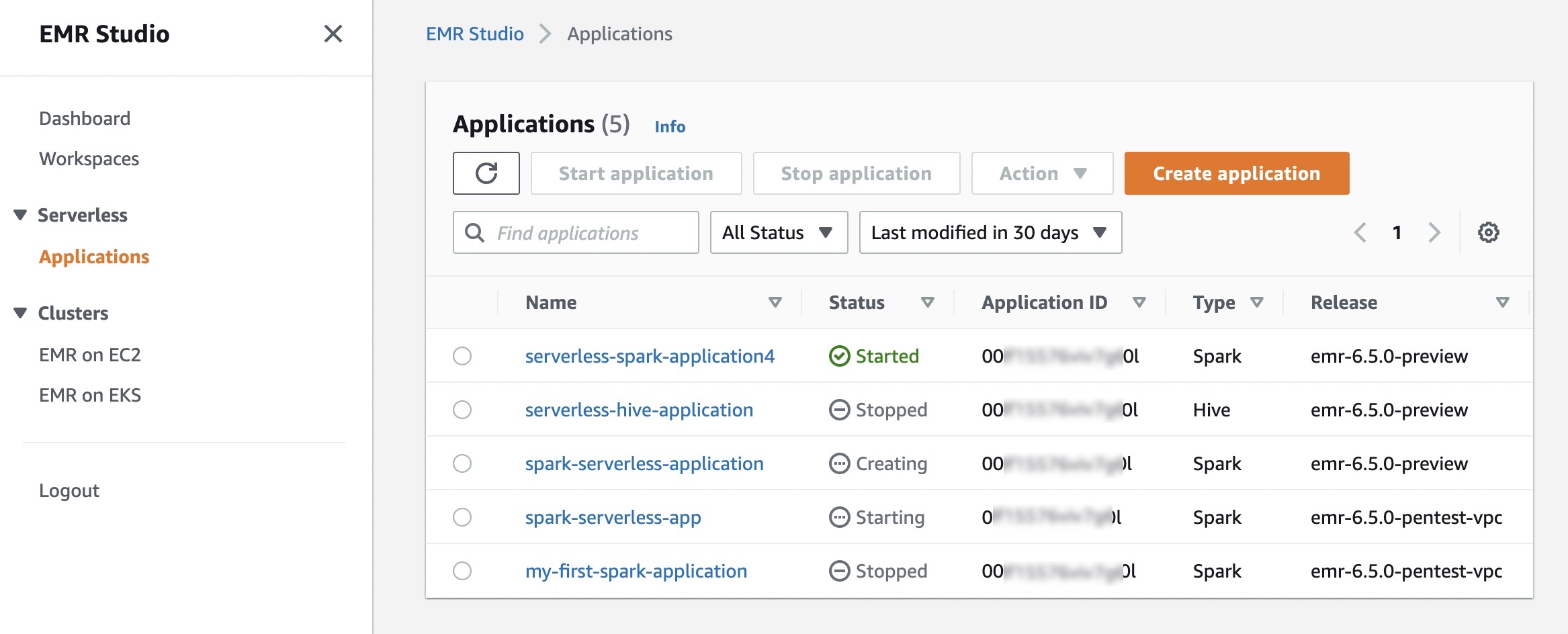
选择创建应用程序时,可以设置 Spark 或 Hive 应用程序的名称、类型以及支持的发行版本。您还可以为预初始化容量、应用程序限制和 Amazon Virtual Private Cloud (Amazon VPC) 连接选项选择默认或自定义设置的选项。每个 EMR Serverless 应用程序都与其他应用程序分隔开,并在安全的 VPC 中运行。
如果要立即启动作业,请使用默认选项。但是,在应用程序启动后,每个工作线程都会收取费用。要了解有关预初始化容量的更多信息,请参阅配置和管理预初始化容量。
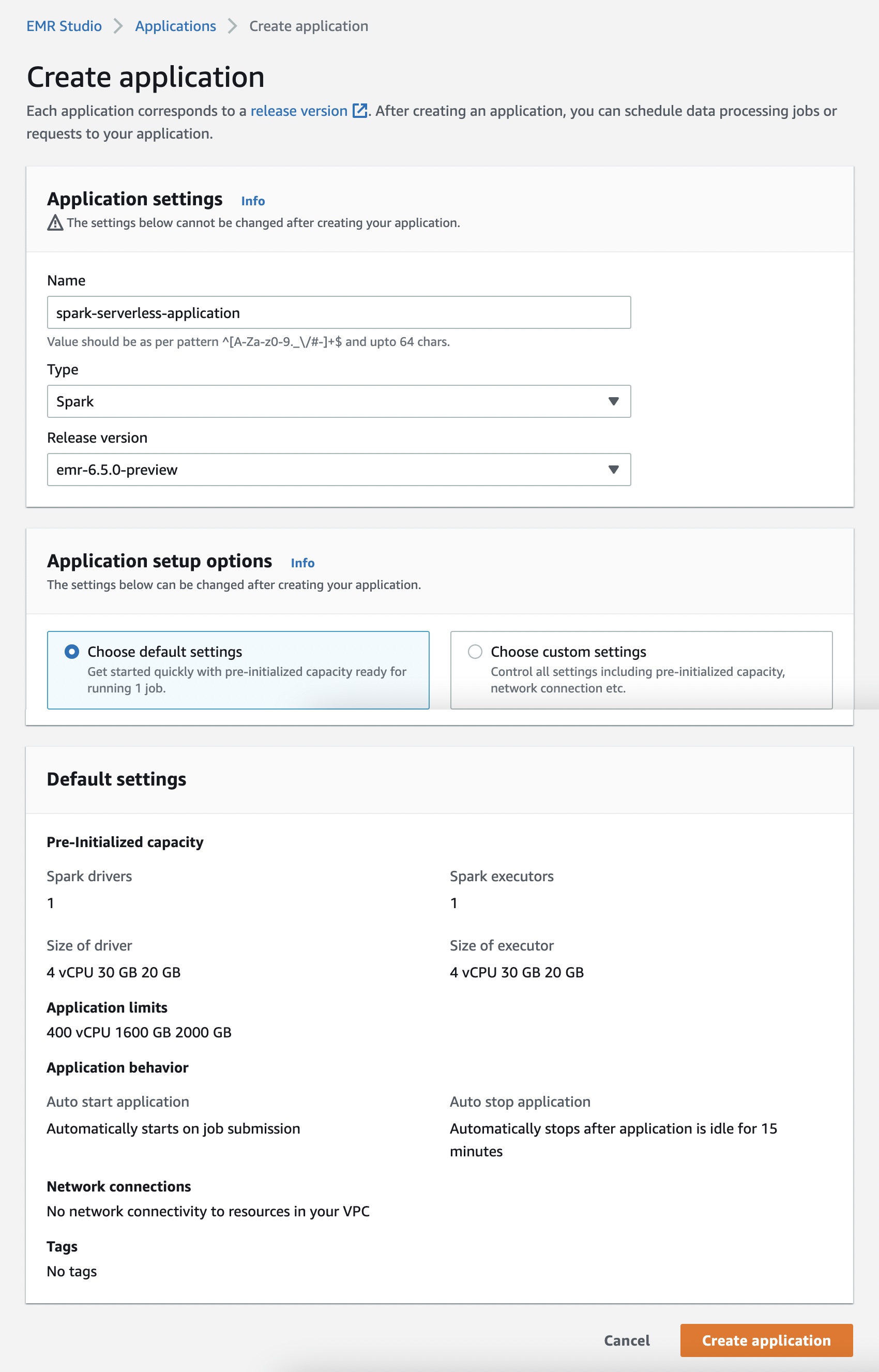
选择启动应用程序后,您的应用程序将设置为以 1 个 Spark 驱动程序加 1 个 Spark 执行程序的预初始化容量启动。默认情况下,您的应用程序配置为在作业提交后启动,在应用程序空闲状态超过 15 分钟时停止。
您可以通过选择选择自定义设置来自定义这些设置并设置不同的应用程序限制。
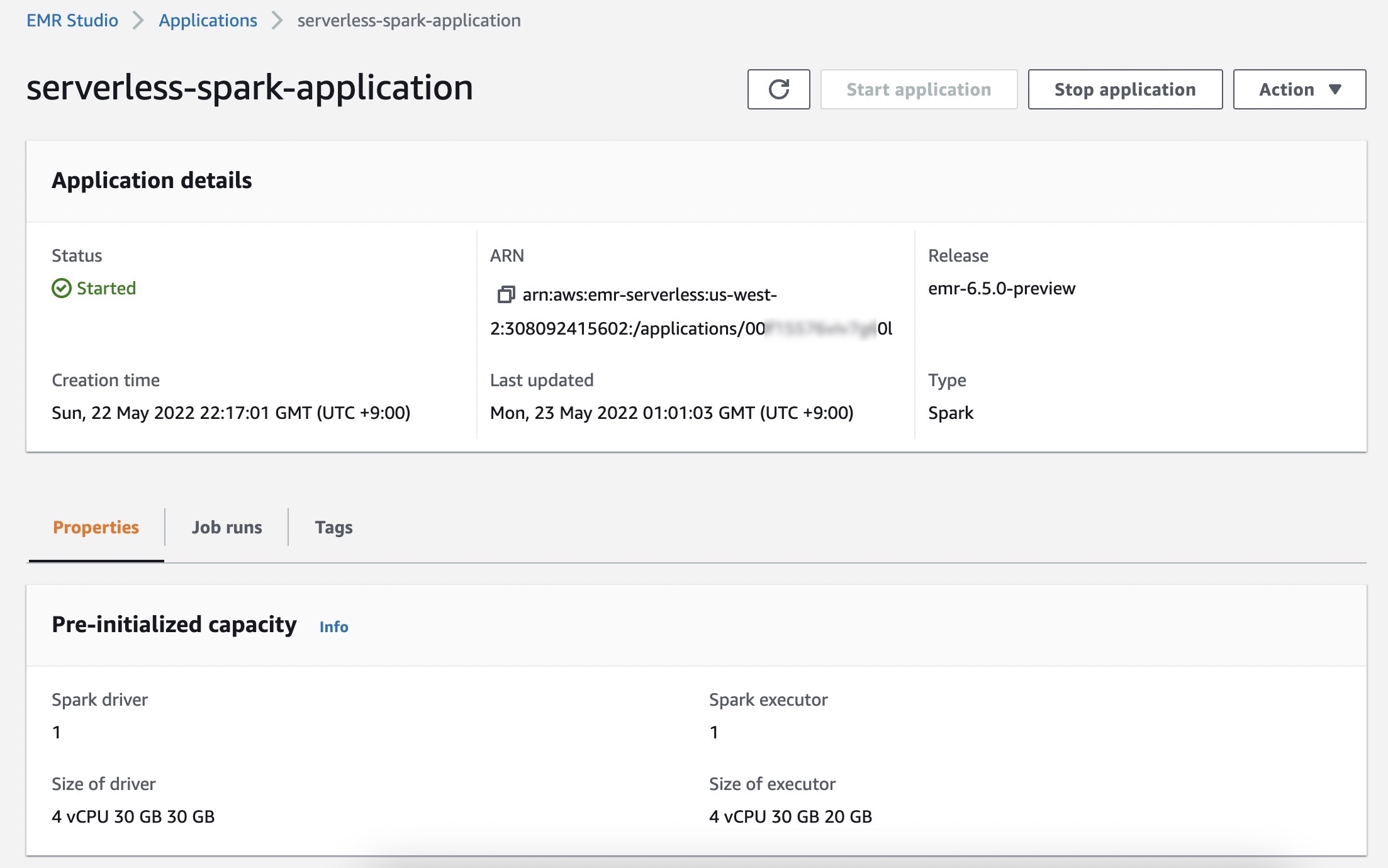
在作业运行菜单中,您可以看到应用程序的运行作业列表。
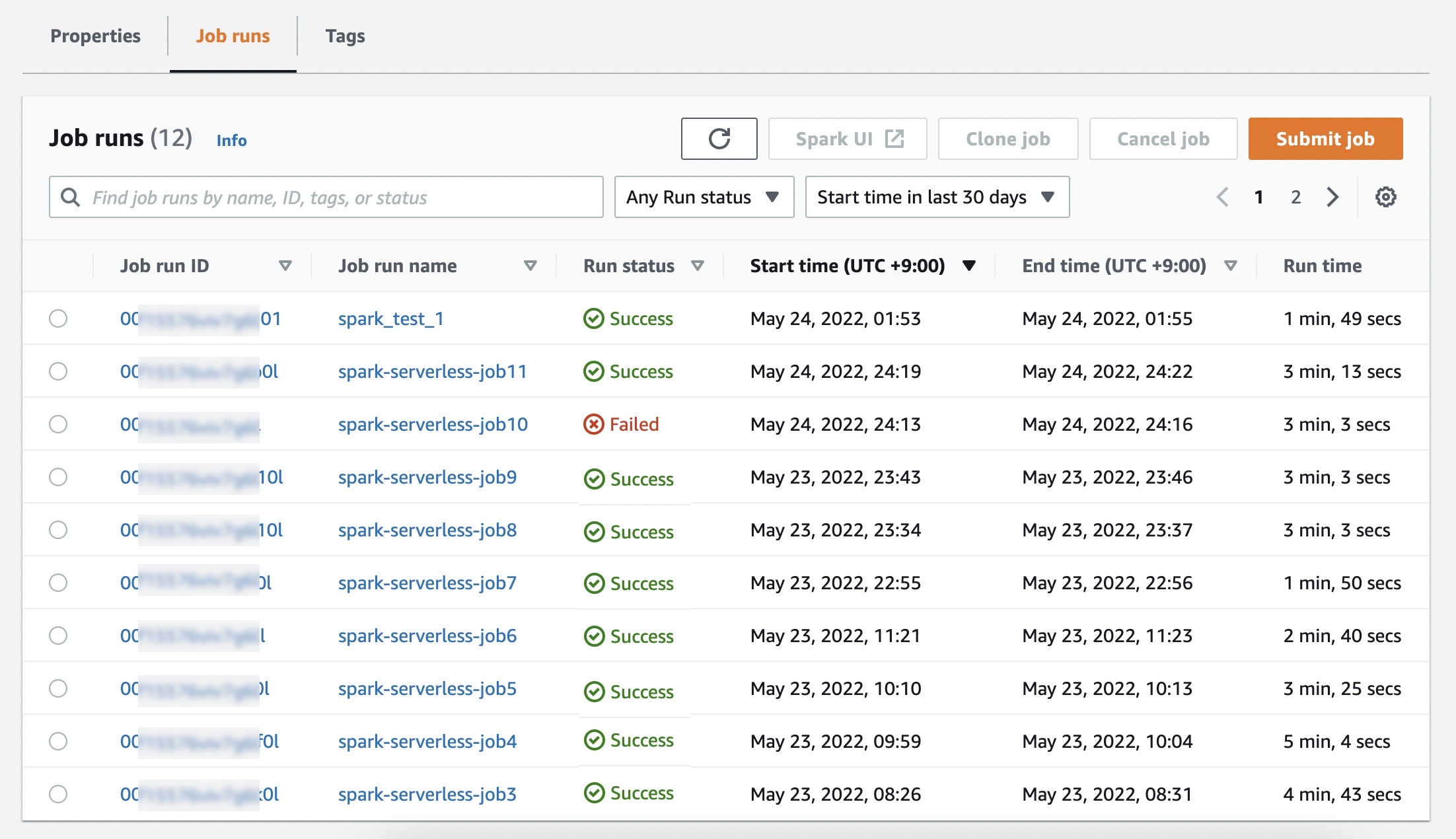
选择提交作业并设置作业详细信息,例如名称、作业使用的 AWS Identity and Access Management (IAM) 角色、脚本位置以及您希望运行的 Amazon Simple Storage Service (Amazon S3) 存储桶中的 JAR 或 Python 脚本参数。
如果您希望将 Spark 或 Hive 作业的日志提交到 S3 存储桶,则需要在运行 EMR Serverless 作业的同一区域中设置 S3 存储桶。
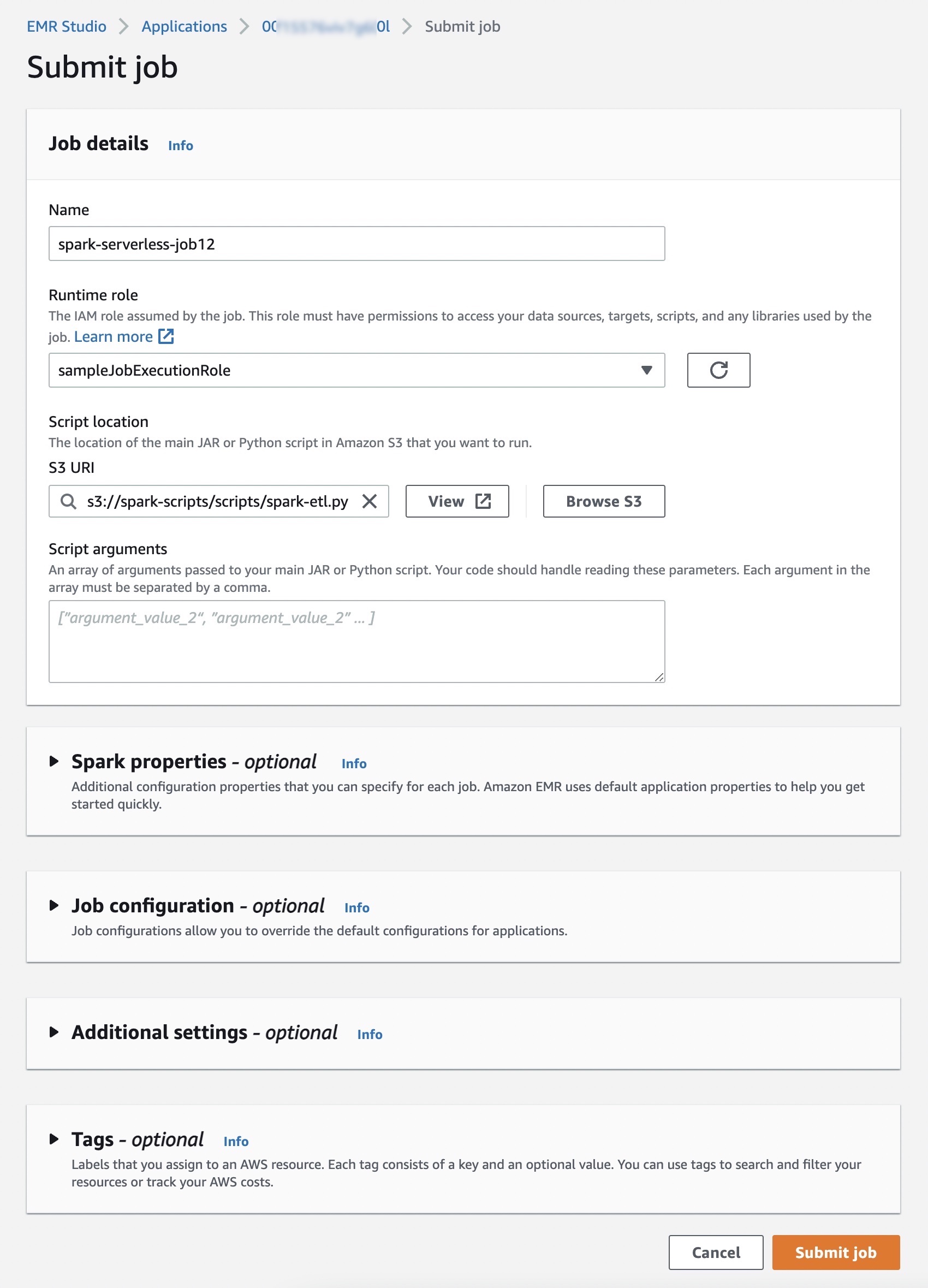
(可选)您可以设置可为每个作业指定的其他配置属性,例如 Spark 属性、覆盖应用程序默认配置的作业配置(例如将 AWS Glue 数据目录用作其元存储)、将日志存储到 Amazon S3 以及将日志保留 30 天。
以下是使用 StartJobRun API 运行 Python 脚本的示例。
$ aws emr-serverless start-job-run \
--application-id <application_id> \
--execution-role-arn <iam_role_arn> \
--job-driver '{
"sparkSubmit": {
"entryPoint": "s3://spark-scripts/scripts/spark-etl.py",
"entryPointArguments": "s3://spark-scripts/output",
"sparkSubmitParameters": "--conf spark.executor.cores=1 --conf spark.executor.memory=4g --conf spark.driver.cores=1 --conf spark.driver.memory=4g --conf spark.executor.instances=1"
}
}' \
--configuration-overrides '{
"monitoringConfiguration": {
"s3MonitoringConfiguration": {
"logUri": "s3://spark-scripts/logs/"
}
}
}'您可以在 S3 存储桶中查看任务结果。有关详细信息,您可以使用适用于 Spark 应用程序的 Spark UI 和作业运行菜单中的 Hive/Tez UI 来了解作业的运行方式,或者在作业失败时如何对其进行调试。
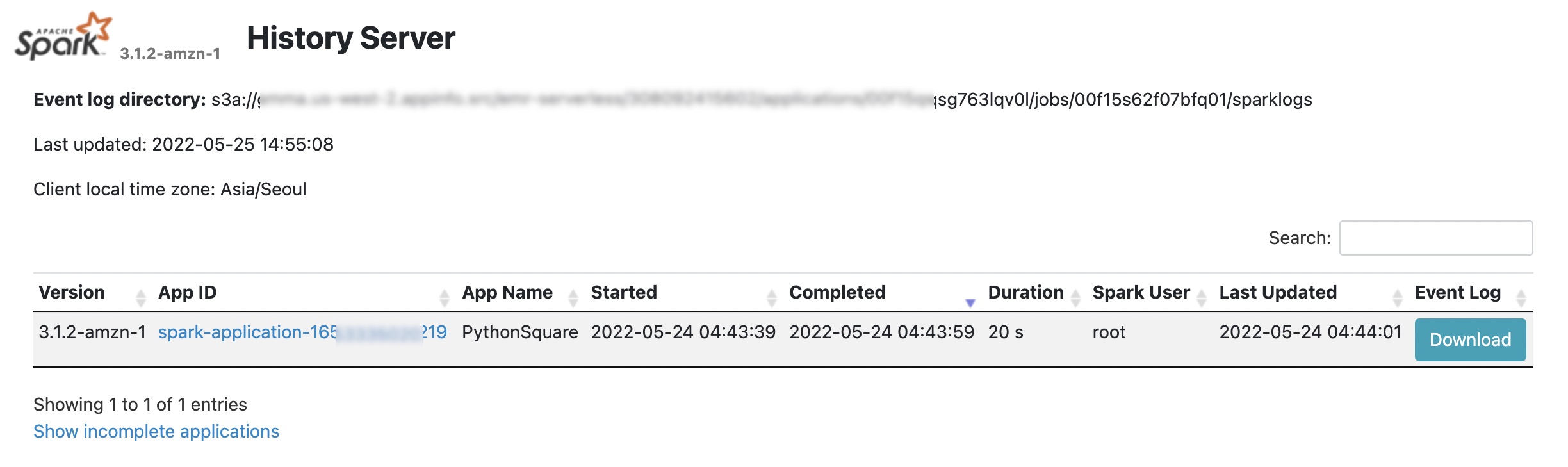
要进行更多调试,EMR Serverless 会将事件日志推送到 Spark 应用程序的 S3 日志目标位置中的 sparklogs 文件夹中。对于 Hive 应用程序,EMR Serverless 会持续将 Hive 驱动程序和 Tez 任务日志上传到 S3 日志目标位置的 HIVE_DRIVER 或 TEZ_TASK 文件夹中。要了解更多信息,请参阅 AWS 文档中的日志记录。
注意事项
使用 EMR Serverless,您可以获得运行 Amazon EMR 的所有好处。我想从预览版公告的 AWS 大数据博客中引用一些关于 EMR Serverless 的知识:
- 自动细粒度扩缩 — EMR Serverless 在处理作业的每个阶段自动纵向扩展工作线程,并在不需要时缩减工作线程。您需要为从工作线程开始运行到停止期间使用的总计 vCPU、内存和存储资源付费,四舍五入到最接近的秒(最小 1 分钟)。例如,您的作业在处理作业的前 10 分钟可能需要 10 个工作线程,在接下来的 5 分钟内需要 50 个工作线程。使用细粒度弹性伸缩,您只需为 10 分钟内 10 个工作线程及 5 分钟内 50 个工作线程付费即可。因此,您不必为未充分利用的资源付费。
- 应对可用区故障的弹性 — EMR Serverless 是一项区域性服务。当您向 EMR Serverless 应用程序提交作业时,该应用程序可以在区域的任何可用区中运行。如果可用区受损,则提交给您的 EMR Serverless 应用程序的作业将自动在另一个(运行状况良好)可用区中运行。在私有 VPC 中使用资源时,EMR Serverless 建议您为多个可用区指定私有 VPC 配置,以便 EMR Serverless 自动选择运行状况良好的可用区。
- 启用共享应用程序 — 向 EMR Serverless 应用程序提交作业时,您可以指定该作业必须使用的 IAM 角色,以便访问 AWS 资源,如 S3 对象。因此,不同的 IAM 主体可以在单个 EMR Serverless 应用程序上运行作业,且每个作业只能访问允许 IAM 主体访问的 AWS 资源。这样,您可以设置以下场景:具有预初始化工作线程池的单个应用程序可供多个租户使用,其中每个租户可以使用不同的 IAM 角色提交作业,但使用预初始化工作线程的公共池立即处理请求。
现已推出
Amazon EMR Serverless 现已在美国东部(弗吉尼亚州北部)、美国西部(俄勒冈州)、欧洲地区(爱尔兰)和亚太地区(东京)区域推出。使用 EMR Serverless,不存在预付费用,您只需为使用的资源付费。您需要为应用程序消耗的 vCPU、内存和存储资源量付费。有关定价详细信息,请参阅 EMR Serverless 定价页面。
要了解更多信息,请访问 Amazon EMR Serverless 用户指南以及使用 Apache Spark 和 Apache Hive 的示例代码。请将反馈发送至 Amazon EMR Serverless 的 AWS re:Post 或通过平时的 AWS 支持联系人发送反馈。
了解有关 Amazon EMR Serverless 的所有详细信息并立即开始使用。
— Channy