亚马逊AWS官方博客
由 AWS Graviton2 处理器提供支持的 AWS Lambda 函数 – 在 Arm 上运行函数并获得高达 34% 的性价比提升
我们的许多客户 (例如Formula One、Honeycomb、Intuit、SmugMug 和 Snap Inc.) 都将基于 ARM 的 AWS Graviton2 处理器用于他们的工作负载,享受更出色的性价比。从今日开始,您可以为自己的 AWS Lambda 函数获得同样的优势。现在,您可以配置在 x86 或 Arm/Graviton2 处理器上运行的新函数和现有函数。
有了这一选择,您可以通过两种方式节省成本。首先,由于采用 Graviton2 架构,您的函数可以更高效地运行。其次,您可为函数的运行时间支付更少的费用。实际上,由 Graviton2 提供支持的 Lambda 函数旨在以降低 20% 的成本提供高达 19%的性能提升。
使用 Lambda,您需要根据函数的请求数量和持续时间 (执行代码所需的时间) 以毫秒级粒度支付费用。对于使用 Arm/Graviton2 架构的函数,持续时间费用比 x86 的当前定价低 20%。使用预置并发的函数的持续时间费用也可减少 20%。
除了降低价格外,使用 Arm 架构的函数还受益于 Graviton2 处理器内置的性能和安全性。使用多线程和多处理或执行许多 I/O 操作的工作负载可能会缩短执行时间,从而降低成本。现在,您可以将 Lambda 函数与高达 10 GB 内存和 6 个 vCPU 结合使用,这一点特别有用。例如,您可以为 Web 和移动后端、微服务和数据处理系统获得更出色的性能。
如果您的函数未使用特定于架构的二进制文件,包括在其依赖项中,则可以从一种架构切换到另一种架构。许多使用解释语言 (例如 Node.js 和 Python) 的函数或编译为 Java 字节码的函数通常都是这种情况。
Arm 支持基于 Amazon Linux 2 构建的所有 Lambda 运行时 (包括自定义运行时),但已停止支持 的 Node.js 10 除外。如果函数包中有二进制文件,则需要为要使用的架构重新构建函数代码。打包为容器镜像的函数需要针对它们将要使用的架构 (x86 或 Arm) 进行构建。
要衡量架构之间的差异,您可以创建两个版本的函数,一个用于 x86,另一个用于 Arm。然后,您可以使用权重,通过别名向函数发送流量,在两个版本之间分配流量。在 Amazon CloudWatch 中,性能指标是按函数版本收集的,而您可以使用统计数据查看关键指标 (例如持续时间)。然后,您可以比较两种架构之间的平均持续时间和 p99 持续时间。
您还可以使用函数版本和加权别名来控制生产环境中的推出。例如,您可以将新版本部署到少量调用 (例如 1%) 中,然后将其增加到 100% 以进行完整部署。在推出期间,如果您的指标显示可疑内容 (例如错误数量增加),则可以降低权重或将权重设置为零。
让我们通过几个示例来了解这项新功能在实践中如何运作。
更改没有二进制依赖项的函数的架构
没有二进制依赖关系时,更改 Lambda 函数的架构就像拨动开关一样简单。例如,前段时间,我使用 Lambda 函数构建了一个测验应用程序。借助此应用程序,您可以使用 Web API 提问和回答问题。我使用 Amazon API Gateway HTTP API 来触发该函数。以下是 Node.js 代码,在其开始时包含一些示例问题:
const questions = [
{
question:
"Are there more synapses (nerve connections) in your brain or stars in our galaxy?",
answers: [
"More stars in our galaxy.",
"More synapses (nerve connections) in your brain.",
"They are about the same.",
],
correctAnswer: 1,
},
{
question:
"Did Cleopatra live closer in time to the launch of the iPhone or to the building of the Giza pyramids?",
answers: [
"To the launch of the iPhone.",
"To the building of the Giza pyramids.",
"Cleopatra lived right in between those events.",
],
correctAnswer: 0,
},
{
question:
"Did mammoths still roam the earth while the pyramids were being built?",
answers: [
"No, they were all exctint long before.",
"Mammooths exctinction is estimated right about that time.",
"Yes, some still survived at the time.",
],
correctAnswer: 2,
},
];
exports.handler = async (event) => {
console.log(event);
const method = event.requestContext.http.method;
const path = event.requestContext.http.path;
const splitPath = path.replace(/^\/+|\/+$/g, "").split("/");
console.log(method, path, splitPath);
var response = {
statusCode: 200,
body: "",
};
if (splitPath[0] == "questions") {
if (splitPath.length == 1) {
console.log(Object.keys(questions));
response.body = JSON.stringify(Object.keys(questions));
} else {
const questionId = splitPath[1];
const question = questions[questionId];
if (question === undefined) {
response = {
statusCode: 404,
body: JSON.stringify({ message: "Question not found" }),
};
} else {
if (splitPath.length == 2) {
const publicQuestion = {
question: question.question,
answers: question.answers.slice(),
};
response.body = JSON.stringify(publicQuestion);
} else {
const answerId = splitPath[2];
if (answerId == question.correctAnswer) {
response.body = JSON.stringify({ correct: true });
} else {
response.body = JSON.stringify({ correct: false });
}
}
}
}
}
return response;
};要开始我的测验,我要求提供问题 ID 列表。为此,我在 /questions 端点上使用带有 HTTP GET 的 curl 命令:
我计划在生产环境中使用此函数。我预计会有很多次调用,并且正在寻找优化成本的选项。在 Lambda 控制台中,我看到此函数正在使用 x86_64 架构。

因为此函数没有使用任何二进制文件,所以我将架构切换到 arm64 并受益于较低的价格。

架构的变化不会改变调用函数或将其响应传回的方式。这意味着与 API Gateway 的集成以及与其他应用程序或工具的集成不受此更改的影响,并且可以像以前一样继续工作。
我继续进行测验,但没有提示用于运行代码的架构在后端发生变化。我通过将答案编号 (从零开始) 添加到问题端点来回答上一个问题:
没错! Cleopatra lived closer in time to the launch of the iPhone than the building of the Giza pyramids.在消化这条信息的同时,我意识到已经完成了向 Arm 架构的函数迁移并优化了成本。
更改使用容器镜像打包的函数的架构
介绍使用容器镜像打包和部署 Lambda 函数的功能时,我使用 Node.js 函数做了演示,同时使用 PDFKit 模块生成 PDF 文件。让我们看看如何将此函数迁移到 Arm 架构。
每次调用该函数时,它都会创建一个包含 faker.js 模块生成的随机数据的新 PDF。该函数的输出使用 Amazon API Gateway 的语法,以 Base64 编码返回 PDF 文件。为方便起见,我在这里复制函数的代码 (app.js):
const PDFDocument = require('pdfkit');
const faker = require('faker');
const getStream = require('get-stream');
exports.lambdaHandler = async (event) => {
const doc = new PDFDocument();
const randomName = faker.name.findName();
doc.text(randomName, { align: 'right' });
doc.text(faker.address.streetAddress(), { align: 'right' });
doc.text(faker.address.secondaryAddress(), { align: 'right' });
doc.text(faker.address.zipCode() + ' ' + faker.address.city(), { align: 'right' });
doc.moveDown();
doc.text('Dear ' + randomName + ',');
doc.moveDown();
for(let i = 0; i < 3; i++) {
doc.text(faker.lorem.paragraph());
doc.moveDown();
}
doc.text(faker.name.findName(), { align: 'right' });
doc.end();
pdfBuffer = await getStream.buffer(doc);
pdfBase64 = pdfBuffer.toString('base64');
const response = {
statusCode: 200,
headers: {
'Content-Length': Buffer.byteLength(pdfBase64),
'Content-Type': 'application/pdf',
'Content-disposition': 'attachment;filename=test.pdf'
},
isBase64Encoded: true,
body: pdfBase64
};
return response;
};要运行这段代码,我需要 pdfkit、faker 和 get-stream npm 模块。这些软件包及其版本在 package.json 和 package-lock.json 文件中进行了描述。
我更新了 Dockerfile 中的 FROM 行,以便将适用于 Lambda 的 AWS 基础镜像用于 Arm 架构。如果有机会,我还将镜像更新为使用 Node.js 14 (当时我正在使用 Node.js 12)。这是我切换架构所需执行的唯一更改。
对于接下来的步骤,我遵循之前提到的文章。这次我使用 random-letter-arm 作为容器镜像的名称和 Lambda 函数的名称。首先,我构建镜像:
然后,我检查镜像以检查它是否使用了正确的架构:
为了确保该函数适用于新架构,我在本地运行容器。
由于容器镜像包含 Lambda 运行时接口仿真器,因此我可以在本地测试该函数:
成功了! 得到的响应是一个 JSON 文档,其中包含针对 API 网关的 base64 编码响应内容:
我确信自己的 Lambda 函数可以与 arm64 架构配合使用,因此我使用 AWS 命令行界面 (CLI) 创建新的 Amazon Elastic Container Registry 存储库:
我标记镜像并将其推送到存储库中:
在 Lambda 控制台中,我创建 random-letter-arm 函数,然后选择从容器镜像创建函数的选项。

我输入函数名称,浏览我的 ECR 存储库以选择 random-letter-arm 容器镜像,然后选择 arm64 架构。

我完成了函数的创建。然后,我添加 API Gateway 作为触发器。为简单起见,我让 API 的身份验证保持开放状态。

现在,我点击了几次 API 端点,然后下载一些用随机数据生成的 PDF 邮件:

此 Lambda 函数向 Arm 架构的迁移已完成。如果您有不支持目标架构的特定依赖项,则过程会有所不同。本地测试容器镜像的功能有助于您在流程的早期发现和修复问题。
将不同的架构与函数版本和别名进行比较
为了具备能够有意义地使用 CPU 的函数,我使用以下 Python 代码。它计算所有的质数,直到作为参数传递的限值。我在此处没有使用最佳的算法,即爱拉托逊斯筛法,但这对于有效利用内存来说是很好的折衷方案。为了清晰了解函数运作,我将函数使用的架构添加到函数的响应中。
import json
import math
import platform
import timeit
def primes_up_to(n):
primes = []
for i in range(2, n+1):
is_prime = True
sqrt_i = math.isqrt(i)
for p in primes:
if p > sqrt_i:
break
if i % p == 0:
is_prime = False
break
if is_prime:
primes.append(i)
return primes
def lambda_handler(event, context):
start_time = timeit.default_timer()
N = int(event['queryStringParameters']['max'])
primes = primes_up_to(N)
stop_time = timeit.default_timer()
elapsed_time = stop_time - start_time
response = {
'machine': platform.machine(),
'elapsed': elapsed_time,
'message': 'There are {} prime numbers <= {}'.format(len(primes), N)
}
return {
'statusCode': 200,
'body': json.dumps(response)
}我使用不同的架构创建了两个函数版本。

我在 x86 版本上使用 50% 权重的加权别名,并在 Arm 版本上使用 50% 权重来均匀分配调用。通过此别名调用函数时,在两个不同架构上运行的两个版本的执行概率相同。

我为函数别名创建了一个 API Gateway 触发器,然后使用笔记本电脑上的几个终端生成一些负载。每次调用都会计算最多一百万的素数。您可以在输出中看到如何使用两种不同的架构来运行该函数。
在执行这些过程中,Lambda 会将指标发送到 CloudWatch,函数版本 (ExecutedVersion) 将存储为其中一个维度。
为了更好地了解发生的情况,我创建了一个 CloudWatch 控制面板来监控两个架构的 p99 持续时间。通过这种方式,我可以比较这两个环境中此函数的性能,并就在生产环境中使用哪种架构做出明智的决定。

对于这种特定的工作负载,Graviton2 处理器上的功能运行速度要快得多,从而提供了更完善的用户体验和更低的成本。
将不同的架构与 Lambda Power Tuning 进行比较
由我的朋友 Alex Casalboni 创建的 AWS Lambda Power Tuning 开源项目使用不同的设置运行您的函数,并建议使用最小化成本和/或最大限度地提高性能的配置。该项目最近进行了更新,可让您在同一张图表上比较两个结果。这样就可方便地对比同一函数的两个版本,一个版本使用 x86,另一个版本使用 Arm。
例如,此图表比较了我在文章前面使用的素数计算函数的 x86 和 Arm/Graviton2 结果:
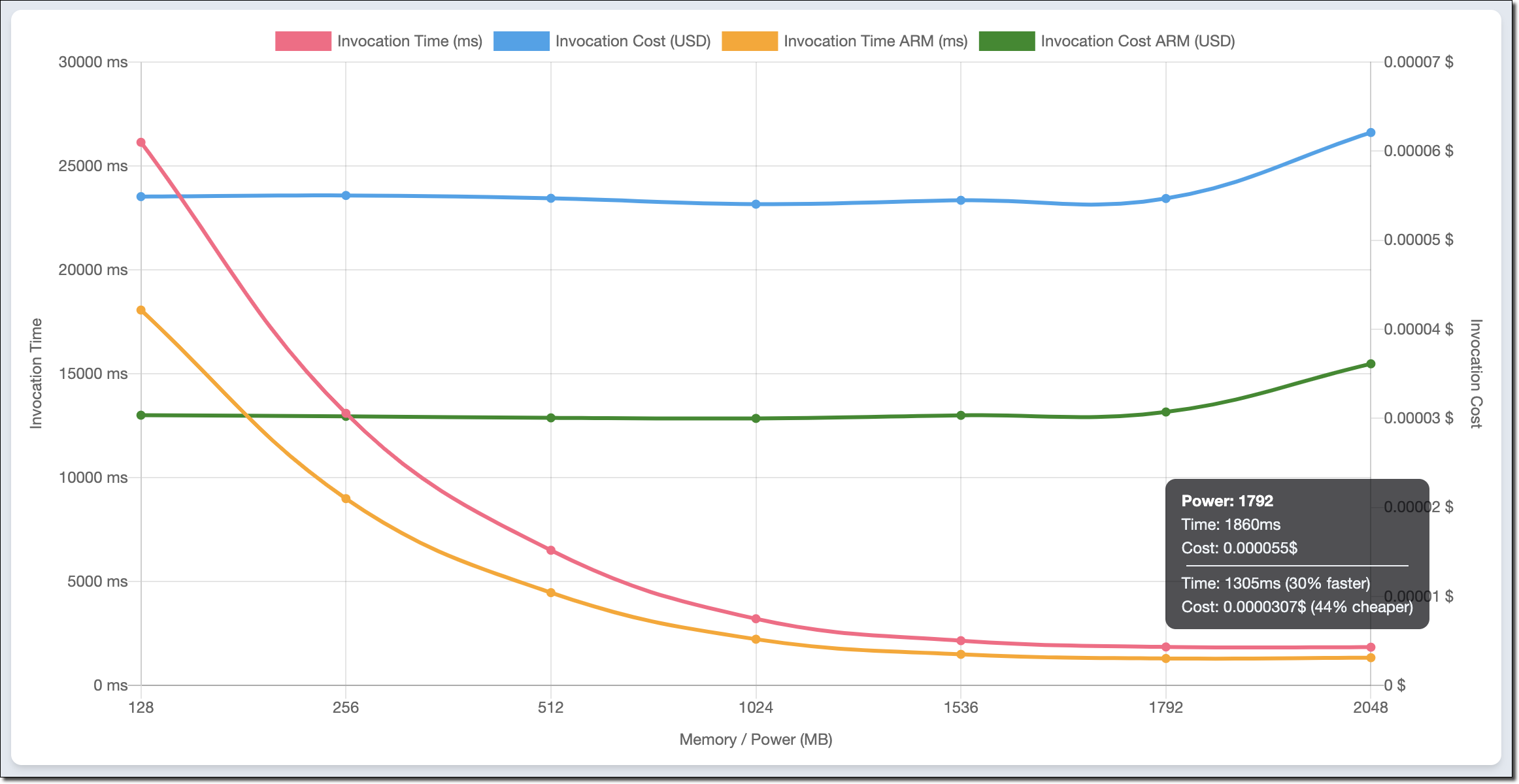
该函数使用单个线程。实际上,当内存配置为 1.8 GB 时,报告的两种架构的持续时间最短。除此之外,Lambda 函数可以访问多个 vCPU,但在这种情况下,函数无法使用额外的计算功率。出于同样的原因,内存高达 1.8 GB 时成本保持稳定。随着内存量的提升,成本会增加,因为此工作负载没有额外的性能优势。
我查看图表并将函数配置为使用 1.8 GB 内存和 Arm 架构。Graviton2 处理器显然为这种计算密集型功能提供了更出色的性能和更低的成本。
可用性和定价
您现在可以在美国东部 (弗吉尼亚北部)、美国东部 (俄亥俄)、美国西部 (俄勒冈)、欧洲 (法兰克福)、欧洲 (爱尔兰)、欧洲 (伦敦)、亚太地区 (孟买)、亚太地区 (新加坡)、亚太地区 (悉尼) 和亚太地区 (东京) 区域使用由 Graviton2 处理器提供支持的 Lambda 函数。
Arm 支持在 Amazon Linux 2 之上运行的以下运行时:
- Node.js 12 和 14
- Python 3.8 和 3.9
- Java 8 (
java8.al2) 和 11 - .NET Core 3.1
- Ruby 2.7
- 自定义运行时 (
提供 .al2)
您可以使用 AWS 无服务器应用程序模型 (SAM) 和 AWS Cloud Development Kit (AWS CDK) 来管理由 Graviton2 处理器提供支持的 Lambda 函数。还可以通过许多 AWS Lambda 合作伙伴获得支持,例如 AntStack、Check Point、Cloudwiry、Contino、Coralogix、Datadog、Lumigo、Pulumi、Slalom、Sumo Logic、Thundra 和 Xerris。
使用 Arm/Graviton2 架构的 Lambda 函数可提供高达 34% 的性价比提升。使用预置并发时,持续时间成本减少 20% 也适用。借助 Compute Savings Plans,您可以进一步将成本降低多达 17%。AWS 免费套餐中包含由 Graviton2 提供支持的 Lambda 函数,但不超过现有限制。有关更多信息,请参阅 AWS Lambda 定价页面。
您可以在 AWS Graviton2 入门存储库中找到有关为 AWS Graviton2 处理器优化工作负载的帮助。
— Danilo