Sameer Malik 和 Christian Williams , Amazon Web Services (AWS) 的解决方案架构师许多 AWS 用户正在利用 AWS 产品组合中提供的托管服务产品来消除其日常工作中的大量无差别任务。 Amazon 关系数据库服务 (Amazon RDS) 是关系数据库部署的托管服务之一。 借助 Amazon RDS ,你可以显著降低管理和维护关系数据库的运营开销。
根据恢复时间目标(RTO)和恢复点目标(RPO)、成本计算以及设置和维护 DR 站点所涉及的管理任务,有多种方法可以实现灾难恢复(DR)解决方案。 本文将介绍如何使用“备份和还原”方法设置跨区域 DR (cross-region DR),这是一种经济高效的 DR 策略,可以满足不太严格的 RTO / RPO 。 (更多信息,请参阅本文末尾的 RTO 和 RPO 注意事项。)
备份和还原 DR 解决方案概述
在本文中,我们将介绍如何使用备份和还原 DR 方法自动化 Amazon RDS for Oracle 数据库的跨区域 DR 流程。 此策略使用 Amazon EBS snapshot 机制(包括 Amazon RDS 系统自动生成的和手动创建的快照)。 它还使用了其他的 AWS 工具,例如 Amazon RDS events , Amazon SNS topics 和 AWS Lambda 函数。 最终的状态是要形成一个自动化架构,它可以执行以下操作:
- 根据用户定义的计划生成快照。
- 将快照复制到第二个 DR 区域(快照复制的频率根据 RPO 要求确定)。
- 如果主区域出现故障,则还原最新的快照以在DR区域上启动另一个 Amazon RDS for Oracle 数据库实例。
该过程如下图所示:
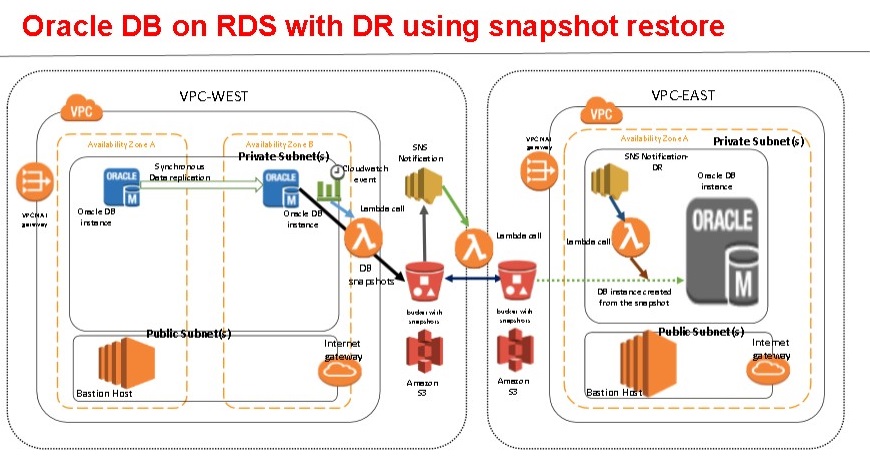
以下是本文中描述的必要步骤:
- 创建 Amazon SNS topics 以订阅 Amazon RDS 事件通知(在下一步中)。
- 在主数据库上启用 Amazon RDS 事件通知。
- 创建 Lambda 函数以执行以下操作:
- 启动主数据库的快照创建。
- 将新创建的快照复制到 DR 区域。
- 如果发生故障,则在 DR 区域中还原复制的快照。
- 启用 Amazon CloudWatch Events 以根据你的 RTO 要求制定初始快照创建计划。
- 可选:创建其他 Lambda 函数以删除旧快照。
步骤 1: 创建Amazon SNS topics
首先创建两个 Amazon SNS topics ,然后你可以使用这些 topic 订阅特定的 Amazon RDS 事件(在步骤2中),确保位于主数据库所在的区域。创建两个 Amazon SNS topic ,分别命名为 DB_Snapshot_initiated_primary_region and a second topic named DB_availability_error_primary_region.
步骤 2: 启用 Amazon RDS 事件通知
到这里,我们就可以启用 Amazon RDS 事件通知了。我们主要关注与主数据库 (Primary DB) 的运行状态相关的 backup 事件和 availability 事件。
下面的屏幕截图说明了如何为 Amazon RDS 实例选择特定事件。请确保你使用在步骤1下创建 topics 来订阅特定数据库实例的 availability 和 backup 事件种类。
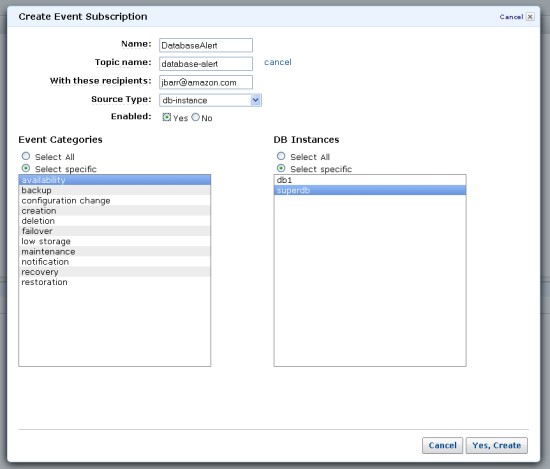
注意:你可以从任何已有 Amazon RDS 事件通知中选择 DR 相关事件以触发你的 DR 。 在此示例中,我们选择此事件作为模拟 DR 事件的触发器。 当 Amazon RDS 无法自动解决与数据库相关的问题时,通常会触发此事件。
步骤3: 创建 Lambda 函数
现在,你可以使用 Amazon SNS topic 自动启动 Lambda 函数。 在执行此操作之前,请确保你已经创建了具有足够 IAM 权限的角色,以创建、复制和还原 Amazon RDS 快照。 以下是示例 IAM policy 。 在授予权限时,请务必遵循“最小权限”原则。 本示例使用 "Resource": "*".
重要提示:此示例仅用于演示,生产环境中应使用更细粒度的资源标识符。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*"
},
{
"Action": [
"rds:AddTagsToResource",
"rds:CopyDBSnapshot",
"rds:CopyDBClusterSnapshot",
"rds:DeleteDBSnapshot",
"rds:CreateDBSnapshot",
"rds:CreateDBClusterSnapshot",
"rds:RestoreDBInstanceFromDBSnapshot",
"rds:Describe*",
"rds:ListTagsForResource"
],
"Effect": "Allow",
"Resource": "*"
}
]
}
步骤 3a : 开始快照创建
下一步是部署 Lambda 函数,以方便在区域2中调用快照创建、快照复制和快照恢复。 此特定部署使用 Python 2.7 作为 Lambda 函数的语言。 以下是快照创建函数的示例代码:
以下是快照创建函数的示例代码
import botocore
import datetime
import re
import logging
import boto3
region='us-west-1'
db_instance_class='db.m4.large'
db_subnet='default'
instances = ['master']
print('Loading function')
def lambda_handler(event, context):
source = boto3.client('rds', region_name=region)
for instance in instances:
try:
#timestamp1 = '{%Y-%m-%d %H:%M:%S}'.format(datetime.datetime.now())
timestamp1 = str(datetime.datetime.now().strftime('%Y-%m-%d-%H-%-M-%S')) + "lambda-snap"
snapshot = "{0}-{1}-{2}".format("mysnapshot", instance,timestamp1)
response = source.create_db_snapshot(DBSnapshotIdentifier=snapshot, DBInstanceIdentifier=instance)
print(response)
except botocore.exceptions.ClientError as e:
raise Exception("Could not create snapshot: %s" % e)
步骤 3b : 复制快照到 DR 区域
接下来,你创建一个 Lambda 函数用于将新创建的快照复制到区域2。 在此步骤中,除了为 Lambda 角色选择相同的设置外,你需要遵循与上一 Lambda 函数相同的配置设置并使用相同的语言 (Python 2.7) 。
import boto3
import botocore
import datetime
import re
import json
SOURCE_REGION = 'us-west-1'
TARGET_REGION = 'us-east-1'
iam = boto3.client('iam')
instances = ['master']
print('Loading function')
def byTimestamp(snap):
if 'SnapshotCreateTime' in snap:
return datetime.datetime.isoformat(snap['SnapshotCreateTime'])
else:
return datetime.datetime.isoformat(datetime.datetime.now())
def lambda_handler(event, context):
print("Received event: " + json.dumps(event, indent=2))
account_ids = []
try:
iam.get_user()
except Exception as e:
account_ids.append(re.search(r'(arn:aws:sts::)([0-9]+)', str(e)).groups()[1])
account = account_ids[0]
source = boto3.client('rds', region_name=SOURCE_REGION)
for instance in instances:
source_instances = source.describe_db_instances(DBInstanceIdentifier= instance)
source_snaps = source.describe_db_snapshots(DBInstanceIdentifier=instance)['DBSnapshots']
source_snap = sorted(source_snaps, key=byTimestamp, reverse=True)[0]['DBSnapshotIdentifier']
source_snap_arn = 'arn:aws:rds:%s:%s:snapshot:%s' % (SOURCE_REGION, account, source_snap)
target_snap_id = (re.sub('rds:', '', source_snap))
print('Will Copy %s to %s' % (source_snap_arn, target_snap_id))
target = boto3.client('rds', region_name=TARGET_REGION)
try:
response = target.copy_db_snapshot(
SourceDBSnapshotIdentifier=source_snap_arn,
TargetDBSnapshotIdentifier=target_snap_id,
CopyTags = True)
print(response)
except botocore.exceptions.ClientError as e:
raise Exception("Could not issue copy command: %s" % e)
copied_snaps = target.describe_db_snapshots(SnapshotType='manual', DBInstanceIdentifier=instance)['DBSnapshots']
步骤 3c : 在出现故障时还原 DR 区域的快照
接下来,你还需要部署还原 Lambda 函数以创建基于从区域1复制到区域2的快照的数据库。因为Amazon SNS topic 能够用于触发其他区域中的 Lambda 函数,你可以直接在 DR 区域部署此还原函数。
import boto3
import botocore
import datetime
import re
import logging
region='us-east-1'
db_instance_class='db.m4.large'
db_subnet='orcldbsng'
#db_subnet='subnet-12345d6a'
instances = ['master']
print('Loading function')
def byTimestamp(snap):
if 'SnapshotCreateTime' in snap:
return datetime.datetime.isoformat(snap['SnapshotCreateTime'])
else:
return datetime.datetime.isoformat(datetime.datetime.now())
def lambda_handler(event, context):
source = boto3.client('rds', region_name=region)
for instance in instances:
try:
source_snaps = source.describe_db_snapshots(DBInstanceIdentifier = instance)['DBSnapshots']
print "DB_Snapshots:", source_snaps
source_snap = sorted(source_snaps, key=byTimestamp, reverse=True)[0]['DBSnapshotIdentifier']
snap_id = (re.sub( '-\d\d-\d\d-\d\d\d\d ?', '', source_snap))
print('Will restore %s to %s' % (source_snap, snap_id))
response = source.restore_db_instance_from_db_snapshot(DBInstanceIdentifier=snap_id,DBSnapshotIdentifier=source_snap,DBInstanceClass=db_instance_class,DBSubnetGroupName=db_subnet,MultiAZ=False,PubliclyAccessible=False)
print(response)
except botocore.exceptions.ClientError as e:
raise Exception("Could not restore: %s" % e)
步骤 4: 制定快照创建计划
最后,为定期快照创建指定一个时间表。
如预期的那样,数据量较大的数据库可能需要额外的时间来创建快照并将该快照复制到第二个区域。要在循环调度上执行初始快照创建 Lambda 函数,可以使用 CloudWatch Events 。下面是一个为每4小时调用快照创建 Lambda 函数设置循环调度的示例 (OrclCreateSnapshot).
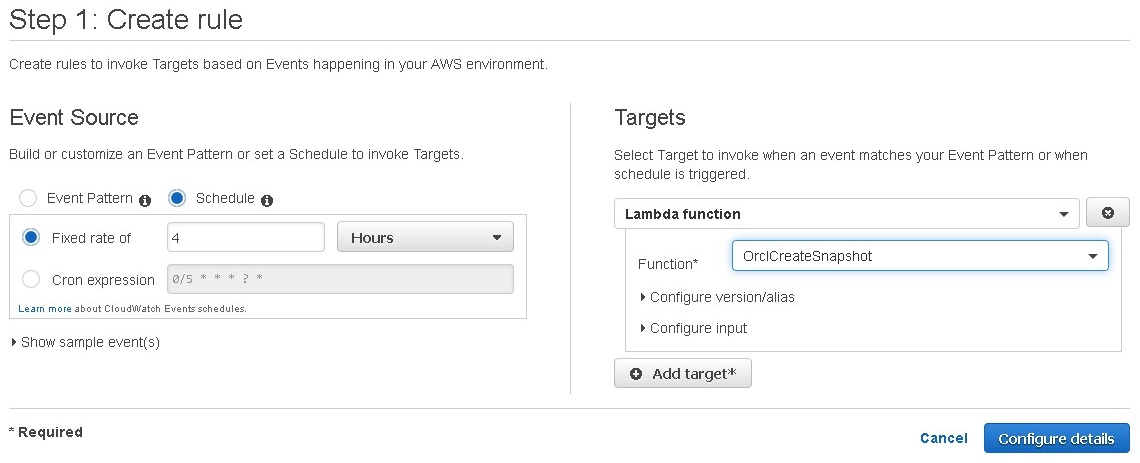
步骤 5: 删除旧快照(可选)
如果需要在每个区域中仅保留一定数量的快照,则可以使用以下 Lambda 函数根据保留要求删除旧快照。 此示例删除大于6天的快照。
import json
import boto3
from datetime import datetime, timedelta, tzinfo
class Zone(tzinfo):
def __init__(self,offset,isdst,name):
self.offset = offset
self.isdst = isdst
self.name = name
def utcoffset(self, dt):
return timedelta(hours=self.offset) + self.dst(dt)
def dst(self, dt):
return timedelta(hours=1) if self.isdst else timedelta(0)
def tzname(self,dt):
return self.name
UTC = Zone(10,False,'UTC')
# Setting the retention period to 6 days
#retentionDate = datetime.now(UTC) - timedelta(days=6)
retentionDate = datetime.now(UTC)
def lambda_handler(event, context):
print("Connecting to RDS")
rds = boto3.setup_default_session(region_name='us-east-1')
client = boto3.client('rds')
snapshots = client.describe_db_snapshots(SnapshotType='manual',DBInstanceIdentifier='master')
print('Deleting all DB Snapshots older than %s' % retentionDate)
for i in snapshots['DBSnapshots']:
if i['SnapshotCreateTime'] < retentionDate:
print ('Deleting snapshot %s' % i['DBSnapshotIdentifier'])
client.delete_db_snapshot(DBSnapshotIdentifier=i['DBSnapshotIdentifier'])
RPO 和 RTO 考虑
RPO – 需要着重指出:在数据库实例可以返回到“ available state ”之前,需要完成初始快照创建。这个“ available state ”是 DB 实例接受新的快照创建请求所需的状态。因此,我们建议你在 CloudWatch Events 中选择一个时间计划,该时间计划允许在使用 CloudWatch Events 调用另一个 Lambda 函数之前完成快照创建请求。我们强烈建议你对在主实例上创建手动快照进行计时,以获取在你的实际环境中可能的最小 RPO 值的度量标准。
RTO – 这是由你的体系结构中的诸多因素所决定的,例如数据库的大小、两个区域之间的距离、你选择还原数据库的实例类型等等。由于在计算“平均” RTO 时涉及的变量数量非常多,所以我们强烈建议测试你的 DR 解决方案,以获得针对你的特定场景的有效估计值。
成本考虑
导致此解决方案成本的主要因素有两个:快照本身的存储成本,以及在两个区域之间复制快照的数据传输成本。
就存储成本而言,对于一个区域的备份存储,不需要额外收费,最高为你的全部数据库存储的100%。由于我们在 DR 区域中没有 Amazon RDS 实例,这导致了在 Amazon S3 中的快照产生备份存储成本,这些成本按标准 Amazon S3 费率 计费。 此外,你还需要花费将快照从区域1中的 Amazon S3 复制到区域2的数据传输成本。
要获得全面的费用估算,请使用免费的 简单月度计算器 。
总结
正如你在本文中描述的步骤中所看到的,在 AWS 上为 Oracle 数据库部署 Amazon RDS 的自动 DR 解决方案是相当容易的。需要注意的是,在单 AZ (Single-AZ) DB 实例上创建 DB 快照会导致一个很短的 I/O 暂停,根据 DB 实例的大小和类型,这个暂停可以持续几秒到几分钟。如果你计划使用非常小的 RPO 并在当天进行多次备份,我们强烈建议你使用 高可用(Multi-AZ) DB 实例,它们并不受此 I/O 暂停的影响,因为备份是在备用服务器 (standby) 上进行的。
最后,看看 Amazon RDS 手动快照的当前限制,目前每个帐户允许有100个手动快照。为了避免维护过多的快照,建议考虑部署步骤5中提到的 Lambda 函数,并在预定的时间安排上运行 CloudWatch 事件。
我们希望这篇文章能给大家带来些许帮助,也非常期待了解你如何在特定的工作负载中实现这些建议。