亚马逊AWS官方博客
使用 Amazon EMR Studio 探索 Apache Hudi 核心概念 (4) – Clustering
Clustering 是 Hudi 在 0.7.0 版本引入的一项特性,用于优化文件布局,提升读写性能,现在它已经成为 Hudi 的一项重要性能优化手段。本文我们会通过 Notebook 介绍并演示 Clustering 的运行机制,帮助您理解其工作原理和相关配置。
1. 运行 Notebook
本文使用的 Notebook 是:《Apache Hudi Core Conceptions (5) – COW: Clustering》,对应文件是:5-cow-clustering.ipynb,请先修改 Notebook 中的环境变量 S3_BUCKET,将其设为您自己的 S3 桶,并确保用于数据准备的Notebook:《Apache Hudi Core Conceptions (1) – Data Preparation》已经至少执行过一次。Notebook 使用的 Hudi 版本是 0.12.1,Spark 集群建议配置 32 vCore / 128 GB 及以上。
2. 核心概念
通常,数据采集倾向于将数据并行写入多个小文件,这样可以提升写入吞吐量,让下游及早获得采集数据;但对于查询来说,大量的小文件会严重影响读取性能;另一方面,在数据采集时,数据是按到达的先后顺序存储的,这种数据分布无法被查询引擎有效利用,如果数据能按查询频率最高的条件列排序后再存储则可以显著提升部分查询的性能,这里有两方面的原因:一是排序后可以利用谓词下推和 Data Skip 技术跳过大量不相关的数据,二是有一个为人所熟知的理论:统计显示,当一条记录被访问后,与之“临近”的数据也将很快被访问到,现代文件系统(例如 HDFS)一般都有 Block Cache,已读取的数据块会被缓存在内存中,访问临近数据时效率会非常高。这里的“临近”就取决于我们如何对数据进行排序。所以,对于一个湖仓系统来说,在数据接入和数据查询两种场景下,对文件大小和数据排布是有不同要求或偏好的,在数据只有一份,配置也只有一份的情况下,系统可优化的空间非常有限,用户只能在接入性能和查询性能之间进行权衡。
针对这种“两难”局面,Hudi 的 Clustering 给出了一套相对完善的解决方案,它的核心思想是:在数据接入时,允许并行写入多个小文件,以提升写入性能,同时通过一个异步(也可以同步执行,但不推荐)进程或线程周期性地将小文件合并成大文件并在这一过程中对数据按特定的列重新排序,这样在解决小文件问题的同时又改善了查询性能。实际上,Clustering 是一种通用的数据布局优化手段,Spark SQL/Hive 中的 cluster by 和 Cassandra 中的 clustering key 都是 Clustering 思想的具体实现,只是 Hudi 的 Clustering 除了这一标准功能外还多了一项合并小文件的工作。以下是与 Clustering 有关的几项重要配置,在后面的介绍中我们会逐一介绍它们的作用:
| 配置项 | 默认值 |
| hoodie.clustering.inline | false |
| hoodie.clustering.schedule.inline | false |
| hoodie.clustering.async.enabled | false |
| hoodie.clustering.inline.max.commits | 4 |
| hoodie.clustering.async.max.commits | 4 |
| hoodie.clustering.plan.strategy.small.file.limit | 314572800 ( 300MB ) |
| hoodie.clustering.plan.strategy.target.file.max.bytes | 1073741824 ( 1GB ) |
| hoodie.clustering.plan.strategy.sort.columns | – |
| hoodie.parquet.small.file.limit | 104857600 ( 100MB ) |
2.1. 排期与执行
Clustering 的执行机制和 Compaction 非常类似,也是分为:排期(Schedule)和执行(Execute)两个阶段。排期阶段的主要工作是划定哪些文件将参与 Clustering,然后生成一个计划(Clustering Plan)保存到 Timeline 里,此时在 Timeline 里会出现一个名为 replacecommit 的 Instant,状态是 REQUESTED;执行阶段的主要工作是读取这个计划(Clustering Plan)并执行它,执行完毕后,Timeline 中的 replacecommit 就会变成 COMPLETED 状态。
2.2. 同步与异步
和 Compaction 一样,Clustering 的运行模式也分为:同步、异步以及半异步三种模式(“半异步”模式是本文使用的一种叫法,为的是和同步、异步两种模式的称谓对齐,Hudi 官方文档对这一模式有介绍,但没有给出命名),它们之间的差异主要体现在从(达到规定阈值的某次)提交(Commit)到排期(Schedule)再到执行(Execute)三个阶段的推进方式上。在 Hudi 的官方文档中,交替使用了 Sync/Async和Inline/Offline 两组词汇描述推进方式,这两组词汇是有微妙差异的,为了表述严谨,我们使用同步/异步和立即/另行这两组中文术语与之对应。以下是 Clustering 三种运行模式的详细介绍。
- 同步模式(Inline Schedule,Inline Execute)

同步模式可概括为:立即排期,立即执行(Inline Schedule,Inline Execute)。在该模式下,当累积的提交(Commit)次数到达一个阈值时,会立即触发 Clustering 的排期与执行(排期和执行是连在一起的),而这个阈值是由配置项 hoodie.clustering.inline.max.commits 控制的,默认值是 4,即:默认情况下,每提交 4 次就(有可能)会触发并执行一次 Clustering。锁定同步模式的配置是:
| 配置项 | 设定值 |
| hoodie.clustering.inline | true |
| hoodie.clustering.schedule.inline | false |
| hoodie.clustering.async.enabled | false |
- 异步模式(Offline Schedule,Offline Execute)

异步模式可概括为:另行排期,另行执行(Offline Schedule,Offline Execute)。在该模式下,任何提交都不会直接触发和执行 Clustering,除非使用了支持异步 Clustering 的 Writer,否则用户需要自己保证有一个独立的进程或线程负责定期执行 Clustering 操作。Hudi 提供了三种运行异步 Clustering 的方式:
- 通过 hudi-cli 或直接提交 Spark 作业驱动异步 Clustering
- 在 HoodieDeltaStreamer 中配置并运行异步 Clustering
- 在 Spark Structured Streaming 中配置并运行异步 Clustering
在后面的测试用例中,我们将使用第一种方式演示如何进行异步的 Clustering 排期与执行。和同步模式类似的是,在异步模式下,只有累积到足够的提交(Commit)次数时才会触发排期,这个值是由配置项 hoodie.clustering.async.max.commits 设定的,默认值也是 4,即:默认情况下,每提交 4 次就(有可能)会触发并执行一次 Clustering。
如果对比一下 Compaction,我们就会发现,此时 Clustering 和 Compaction 在设计上开始出现了一些差异。在 Compaction 中,与提交次数有关的配置项只有一个,即:hoodie.compact.inline.max.delta.commits,该项对于 Compaction 的同步、异步和半异步模式都有效,而在 Clustering 中,针对同步和异步则提供了两个不同的配置项:hoodie.clustering.inline.max.commits 和 hoodie.clustering.async.max.commits。
在异步模式下,由于发起排期和提交之间没有必然的协同关系,所以在发起排期时,Timeline 中可能尚未积累到足够数量的提交,或者提交数量已经超过了规定阈值,如果是前者,不会产生排期计划,如果是后者,排期计划会将所有累积的提交涵盖进来,在这一点上,Clustering 和 Compaction 的处理方式是一致的。锁定异步模式的配置是:
| 配置项 | 设定值 |
| hoodie.clustering.inline | false |
| hoodie.clustering.schedule.inline | false |
| hoodie.clustering.async.enabled | true |
- 半异步模式(Inline Schedule,Offline Execute)

半异步模式可概括为:立即排期,另行执行(Inline Schedule,Offline Execute),即:排期会伴随提交自动触发,但执行还是通过前面介绍的三种异步方式之一去完成。
在半异步模式下,Clustering 和 Compaction 在设计上出现了更显著的差异。Compaction 的半异步模式,即:Inline Schedule, Offline Execute,其排期周期会受 hoodie.compact.inline.max.delta.commits 的控制,即:排期会根据累积的提交次数周期性触发;而 Clustering 的半异步模式则采用了完全不同的做法,不管是 hoodie.clustering.inline.max.commits 还是 hoodie.clustering.async.max.commits 都对它不起作用,该模式下,每一次提交都会(尝试)生成排期计划,没有配置项能改变这个排期周期,初次了解到这一状况时,很多人会感到困惑,因为这样会变成每提交一次就得进行一次 Clustering,这肯定是不合理的。
实际情况是,排期还会受到另外一个因素的影响:如果当前 Timelines 中有积压的排期计划(即状态为 REQUESTED 的 replacecommit),Hudi 不会再生成新的排期,直到它被执行掉,这就相当于将排期的周期“挂靠”到了执行周期上。举个例子:假设一个 Hudi 的客户端使用半异步模式向某张表持续写入数据,每分钟内会产生若干次提交,与此同时,一个异步进程每分钟会进行一次 Offline Execute,在这个场景下,每次 Execute 完成时,Timeline 中那个 pending 的排期计划就会被 consume 掉(replacecommit 从 REQUESTED 变成了 COMPLETED),于是,紧接着的下一次提交会立即生成新的排期计划,这个排期计划会将此前一分种内提交的小文件全部涵盖在内,等到一分钟后再次启动 Offline Execute 时,这批小文件就被打包成大文件了。
简单总结一下半异步的设计思想:它在每次提交时都会尝试生成排期,如果此前已经生成了排期且尚未执行,则放弃排期,等待其被执行,当异步进程或线程完成执行作业时,紧接着的下一次提交会立即生成新的排期,这样,整个 Clustering 的“节奏”就由异步的执行程序来掌控了。锁定半异步模式的配置是:
| 配置项 | 设定值 |
| hoodie.clustering.inline | false |
| hoodie.clustering.schedule.inline | true |
| hoodie.clustering.async.enabled | false |
2.3. 排期策略
前面在介绍 hoodie.clustering.inline.max.commits 和 hoodie.clustering.async.max.commits 时,我们说在达到这些阈值时“有可能”会触发 Clustering,因为是否会生成一个 Clustering 排期还取决于排期策略。
实际上,Clustering 在排期和执行上都有可插拔的策略,以及在执行期间如何应对数据更新也有相应的更新策略,执行策略和更新策略较为简单,使用默认配置即可,本文不再赘述,详情可参考官方文档。本文着重介绍一下排期策略。Hudi 有三种 Clustering 排期策略可供选择:
- SparkSizeBasedClusteringPlanStrategy:该策略为默认的排期策略,它会筛选出符合条件的小文件(就是看文件大小,小于 clustering.plan.strategy.small.file.limit 规定值的文件就是小文件),然后将选出的小文件分成多个 Group,Group 的数量和大小都是可配置的,划分 Group 的目的是提升 Clustering 的并行度。注意:该策略将会扫描全部分区。
- SparkRecentDaysClusteringPlanStrategy:该策略会在此前 N 天的分区内查找小文件,对于使用日期作分区,且数据增量是可预期的数据表来说,这种策略是非常适合的。如果在这种情况下使用默认排期策略,就会扫描全部分区,给系统带来没有必要的负载。
- SparkSelectedPartitionsClusteringPlanStrategy:该策略允许我们针对特定的分区进行 Clustering,这可能会应用在运维或某些具有独特业务特征的数据表上。
下面,我们看一下排期策略会使用到的和文件大小相关的配置项,在接下来的测试用例中,也会使用到它们:
| 配置项 | 默认值 |
| hoodie.clustering.plan.strategy.small.file.limit | 314572800 ( 300MB ) |
| hoodie.clustering.plan.strategy.target.file.max.bytes | 1073741824 ( 1GB ) |
hoodie.clustering.plan.strategy.small.file.limit 在前面已经提及,只有小于该值的文件才会被视为小文件,从而参与到 Clustering 中,默认值是 300MB;hoodie.clustering.plan.strategy.target.file.max.bytes 用于限制 Clustering 生成的文件大小,默认是 1GB,即:经 Clustering 合并后的数据文件最大不会超过 1GB,如果数据总量大于 1GB,会均分为多个文件。
2.4. 排序列
配置项 hoodie.clustering.plan.strategy.sort.columns 用于指定在 Clustering 过程中针对哪个列重新进行排序,这也是前文重点解释的 Clustering 能提升数据读取性能的关键。该列的选择对提升查询效率非常重要,通常会选择查询频率最高的条件列。尽管该配置项支持多列,但如果配置了两个或更多列的话,对于那些排在第一列后面的列来说,以它们为条件的查询并不能从中获得太多收益,这和在 HBase 中拼接列值到 Rowkey 中以提升检索性能是一样的。不过,Hudi 提供了以 z-order 和 hilbert 为代表的空间填充曲线技术用于解决多列排序问题。
2.5. 关闭小文件检查
最后,也许应该是最先提醒的一点:关闭 Parquet 的小文件检查,即:将 hoodie.parquet.small.file.limit 置为0。介绍到这里的时候,相信你应该能理解为什么要这样做了:将该项置为 0 意味着所有的文件都会被视作大文件,任何数据的写入都不再发生 Copy On Write 的 Copy 动作,而是直接写入新文件,这将大大减轻写入负担,由此产生的大量小文件就是 Clustering 要去解决的事情了。
3. 同步Clustering
3.1. 关键配置
《Apache Hudi Core Conceptions (5) – COW: Clustering》的第 1 个测试用例基于 COW 表演示了同步 Clustering 的运行机制。测试用的数据表有如下几项关键配置:
| 配置项 | 默认值 | 设定值 |
| hoodie.clustering.inline | false | true |
| hoodie.clustering.schedule.inline | false | false |
| hoodie.clustering.async.enabled | false | false |
| hoodie.clustering.inline.max.commits | 4 | 3 |
| hoodie.clustering.plan.strategy.small.file.limit | 314572800 ( 300MB ) | 209715200 ( 200MB ) |
| hoodie.clustering.plan.strategy.target.file.max.bytes | 1073741824 ( 1GB ) | 314572800 ( 300MB ) |
| hoodie.clustering.plan.strategy.sort.columns | ||
| hoodie.parquet.small.file.limit | 104857600 ( 100MB ) | 0 |
| hoodie.copyonwrite.record.size.estimate | 1024 | 175 |
这些配置项在介绍概念时都已提及,通过这个测试用例将会看到它们组合起来的整体效果。
3.2. 测试计划
该测试用例会先后插入三批数据,然后进行同步的 Clustering 排期和执行,过程中将重点观察时间线和文件布局的变化,整体测试计划如下表所示:
| 步骤 | 操作 | 数据量(单分区) | 文件系统 |
| 1 | Insert | 96MB | +1 Small File |
| 2 | Insert | 213MB | +1 Max File +1 Small File |
| 3 | Insert | 182MB | +1 Max File +1 Small File +2 Clustered Files |
提示:我们将使用色块标识当前批次的 Instant 和对应存储文件,每一种颜色代表一个独立的 File Group。
3.3. 第 1 批次
第 1 批次单分区写入了 96MB 数据,Hudi 将其写入到一个 Parquet 文件中,第一个 File Group 随之产生。

3.4. 第 2 批次
第 2 批次单分区写入了 213MB 数据,由于数据表关闭了小文件检查,即:将 hoodie.parquet.small.file.limit 设为了 0,所以这批数据全部都会写入新文件,由于总体积超过了 120MB,所以将分成两个文件写入,第二和第三个 File Group 出现。

3.5. 第 3 批次
第 3 批次单分区写入了 182MB 数据,和上一批次一样,因为总体积超过了 120MB,所以分成两个文件写入,第四和五个 File Group 出现。由于该表被设置为同步 Clustering 模式且最大提交次数是 3,所以此次提交触发了 Clustering 机制,自动发起了名为 replacecommit 的第四次提交,第四次提交将 5 个小于 200MB 的文件打包,经重新排序后,写入到了两个新文件中,一个 220MB,另一个 269MB,完成了一次标准的 Clustering 操作:

和 COW 写 Parquet 文件不同的是,Clustering 倾向于将数据均匀分布到生成的文件中,以使它们大小相同或接近,而不是写满一个 300MB 的 Max File 和一个 189MB 的 Small File。

3.6. 复盘
最后,让我们将此前的全部操作汇总在一起,重新看一下整体的时间线和最后的文件布局:

4. 异步 Clustering
4.1. 关键配置
《Apache Hudi Core Conceptions (5) – COW: Clustering》的第 2 个测试用例基于 COW 表演示了异步 Clustering 的运行机制。测试用的数据表有如下几项关键配置:
| 配置项 | 默认值 | 设定值 |
| hoodie.clustering.inline | false | false |
| hoodie.clustering.schedule.inline | false | false |
| hoodie.clustering.async.enabled | false | true |
| hoodie.clustering.async.max.commits | 4 | 3 |
| hoodie.clustering.plan.strategy.small.file.limit | 314572800 ( 300MB ) | 209715200 ( 200MB ) |
| hoodie.clustering.plan.strategy.target.file.max.bytes | 1073741824 ( 1GB ) | 314572800 ( 300MB ) |
| hoodie.clustering.plan.strategy.sort.columns | ||
| hoodie.parquet.small.file.limit | 104857600 ( 100MB ) | 0 |
| hoodie.copyonwrite.record.size.estimate | 1024 | 175 |
这些配置项在介绍概念时都已提及,通过这个测试用例将会看到它们组合起来的整体效果。
4.2. 测试计划
该测试用例会先后插入三批数据,然后进行异步的 Clustering 排期和执行,过程中将重点观察时间线和文件布局的变化,整体测试计划如下表所示:
| 步骤 | 操作 | 数据量(单分区) | 文件系统 |
| 1 | Insert | 96MB | +1 Small File |
| 2 | Insert | 213MB | +1 Max File +1 Small File |
| 3 | Insert | 182MB | +1 Max File +1 Small File |
| 4 | Offline Schedule | N/A | N/A |
| 5 | Offline Execute | 491MB | +2 Clustered Files |
由于该测试用例的前三步操作与第 3 节(第 1 个测试用例)完全一致,所以不再赘述,我们会从第 4 步操作(Notebook 的 3.8 节)开始解读。
4.3. 异步排期
在完成了和第 3 节完全一样的前三批操作后,时间线和文件系统的情形如下:

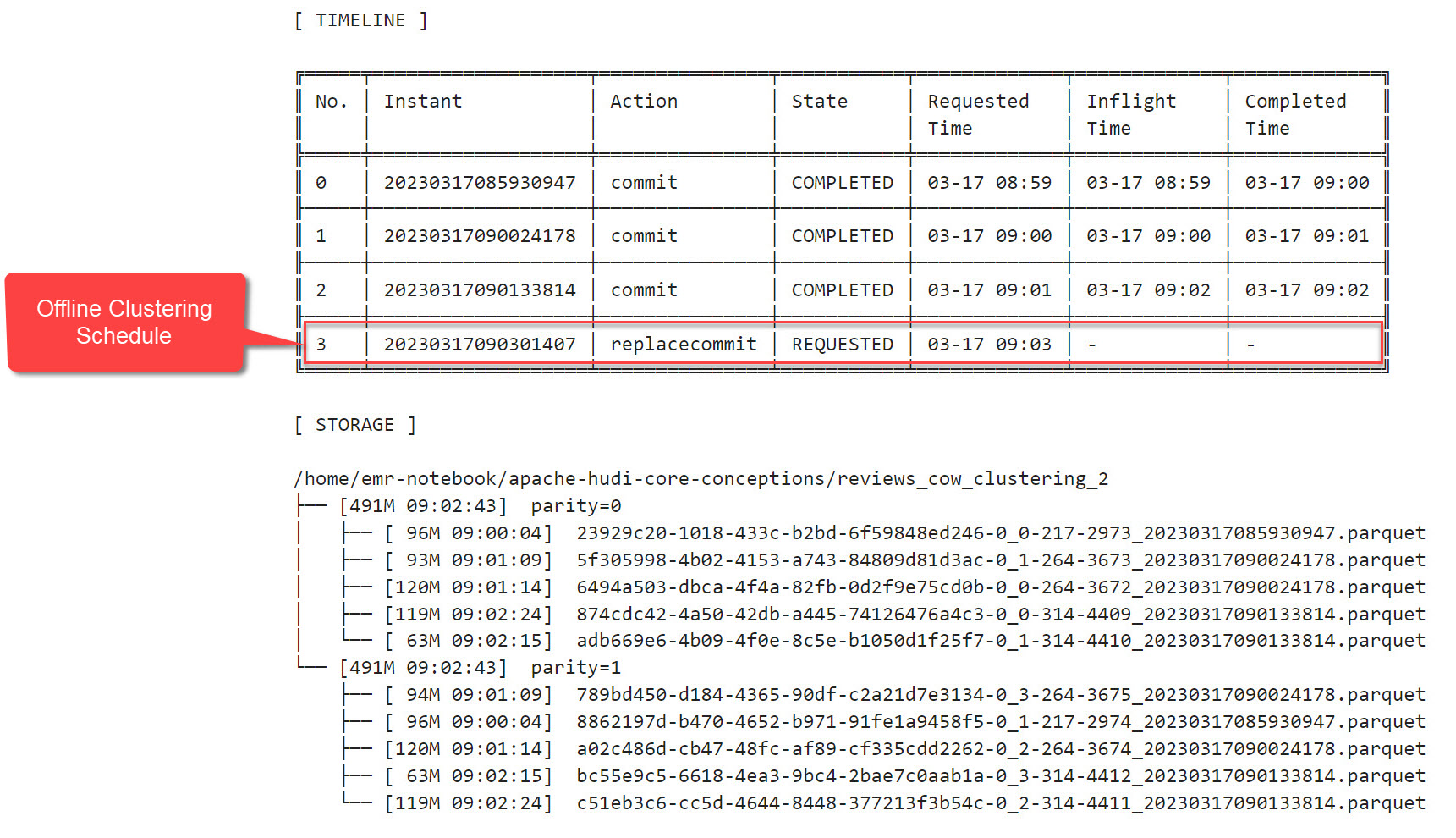
这和 3.5 节执行后的状况非常不同,没有发生 Clustering,连排期也没有看到,因为我们关闭了 hoodie.clustering.inline。于是,在接下来的第 4 步操作中(Notebook 的 3.8 节),我们通过 spark-submit 手动发起了一个排期作业(–mode ‘schedule’):
执行后,文件布局没有变化,但是在时间线中出现了一个状态为 REQUESTED 的 replacecommit:
4.4. 异步执行
第 5 步操作(Notebook 的 3.9 节)通过 spark-submit 手动发起了一个执行作业(–mode ‘execute’):
执行后,原 replacecommit 状态由 REQUESTED 变为 COMPLETED,原 5 个小于 200MB 的文件被打包,经重新排序后写入两个 245MB 的大文件:

4.5. 异步排期 + 异步执行
异步的排期和执行可以通过一个命令一步完成,《Apache Hudi Core Conceptions (5) – COW: Clustering》的第 3 个测试用例演示了这一操作。它的前三步操作与第 2 个测试用例一样,在第四步时,使用了“排期 + 异步”一起执行的方式(–mode ‘scheduleAndExecute’)一步完成了 Clustering 操作,命令如下:
5. 半异步 Clustering
5.1. 关键配置
《Apache Hudi Core Conceptions (5) – COW: Clustering》的第 4 个测试用例基于 COW 表演示了半异步 Clustering 的运行机制。测试用的数据表有如下几项关键配置:
| 配置项 | 默认值 | 设定值 |
| hoodie.clustering.inline | false | false |
| hoodie.clustering.schedule.inline | false | true |
| hoodie.clustering.async.enabled | false | false |
| hoodie.clustering.plan.strategy.small.file.limit | 314572800 ( 300MB ) | 209715200 ( 200MB ) |
| hoodie.clustering.plan.strategy.target.file.max.bytes | 1073741824 ( 1GB ) | 314572800 ( 300MB ) |
| hoodie.clustering.plan.strategy.sort.columns | ||
| hoodie.parquet.small.file.limit | 104857600 ( 100MB ) | 0 |
| hoodie.copyonwrite.record.size.estimate | 1024 | 175 |
这些配置项在介绍概念时都已提及,通过这个测试用例将会看到它们组合起来的整体效果。
5.2. 测试计划
由于半异步模式的执行机制与同步和纯异步都有不小的差异,所以测试计划也做出了一些相应的调整,以便能展示它的全貌,整体测试计划如下:
| 步骤 | 操作 | 数据量(单分区) | 文件系统 |
| 1 | Insert | 96MB | +1 Small File |
| 2 | Insert | 213MB | +1 Max File +1 Small File |
| 3 | Insert | 182MB | +1 Max File +1 Small File |
| 4 | Offline Execute | 96MB | +1 Clustered File |
| 5 | Insert | 14.6MB | +1 Small File |
| 6 | Offline Execute | 503MB | +2 Clustered Files |
5.3. 第 1 次同步排期
如前文所述,在半异步模式下,每次提交都会尝试生成排期计划,这一点,在测试用例的第一批次(Notebook 5.5 节)插入中就表现了出来:

初次提交时,Timeline 上没有未处理的排期,Hudi 会立即生成排期计划,而在这个排期计划里,只是一个 96MB 的数据文件(只看单分区),所以可以推断:这个排期计划执行完毕后,依然只会生成一个相同大小的数据文件。
在第二批次(Notebook 5.6 节)插入后,Timeline 中并没有生成新的排期,原因是当前 Timeline 中存在未处理的排期计划,第三批次(Notebook 5.7 节)同样如此:

5.4. 第 1 次异步执行
完成了三个批次的插入后,测试用例在第四步(Notebook 5.8 节)发起了一次异步执行。由于此时的这个排期计划是在第一批次提交时生成的,当时只有一个 96MB 的小文件(只看单分区)可以参与 Clustering,所以结果就是又生成了一个同样大小的文件:

尽管这一行为在当下看起来有些怪异,但它的整体逻辑是没有问题的,这只是半异步模式下短暂出现的“空转”现象,在后续的排期中会慢慢正常起来。
5.5. 第 2 次同步排期
完成第四步(Notebook 5.8 节)的异步执行后,Timeline 中就没有待执行的排期计划了,于是在第五步(Notebook 5.9 节)插入操作完成后,随即生成了第 2 次排期:

此次排期将会覆盖此前所有提交生成的文件(包括第 1 次 Clustering 生成的那个 96MB 的文件),因为它们全都是没有超过 200MB 的小文件。
5.6. 第 2 次异步执行
第六步(Notebook 5.10 节)发起了第 2 次异步执行,不同于第1次执行,这次的操作效果已经是一次符合预期的标准 Clustering了:

关联阅读
使用 Amazon EMR Studio 探索 Apache Hudi 核心概念 (1) – File Layouts
使用 Amazon EMR Studio 探索 Apache Hudi 核心概念 (2) – File Sizing
使用 Amazon EMR Studio 探索 Apache Hudi 核心概念 (3) – Compaction