亚马逊AWS官方博客
借助 Lambda 将 CloudWatch 的监控数据和 Open-Falcon 集成
随着企业或机构在AWS上的工作负载不断增加,每个用户的环境部署和使用的架构及服务都各不相同,尤其是大型企业用户。而AWS提供了各种各样不同级别的服务以提升用户在业务开发和迭代上的敏捷性,但如何对现有资源的使用情况进行监控,并保障业务的连续性变成一大挑战。从运营的角度来说,越多越多的用户希望在AWS上提升自己的监控能力,增加效率,对业务系统的运营情况能做到主动通知,并结合原有数据中心的监控系统,做到运维监控一体化,慢慢过渡到智能化运维阶段。以下方案以Open-Falcon为例,将为大家介绍如何通过AWS Lambda将AWS 平台上CloudWatch产生的服务告警数据发送到本地部署的监控系统中。
监控服务介绍
Amazon CloudWatch
AWS上提供了监控的服务Amazon CloudWatch ,它是一个面向开发运营工程师、开发人员、站点可靠性工程师 (SRE) 和 IT 经理的监控和可视化服务。CloudWatch 为用户提供相关数据,以监控应用程序、响应系统范围的性能变化、优化资源利用率,并在统一视图中查看运营状况。它以日志、指标和事件三种形式收集监控和运营数据,帮助用户能够统一查看在 AWS 和本地服务器上运行的资源、应用程序和服务。同时用户可以使用 CloudWatch 检测环境中的异常行为、设置警报、执行自动化操作、排查问题等。具体的工作方式如下:
 CloudWatch和大多数的AWS服务都已经集成,同时支持以agent的形式运行在本地机房的服务器上,用户完全可以使用CloudWatch来建设统一的监控平台。对于事件警报响应也支持通过SNS Topic的形式触发Lambda以实现定制化的业务逻辑需求,比如通过Chime、Slack或微信等形式发送相关警报到相关责任人或团队。
CloudWatch和大多数的AWS服务都已经集成,同时支持以agent的形式运行在本地机房的服务器上,用户完全可以使用CloudWatch来建设统一的监控平台。对于事件警报响应也支持通过SNS Topic的形式触发Lambda以实现定制化的业务逻辑需求,比如通过Chime、Slack或微信等形式发送相关警报到相关责任人或团队。

AWS Lambda
AWS Lambda 是一项高可用的serverless计算服务,可使用户无需预配置或管理服务器即可运行代码。用户可以运行Lambda以响应事件,在使用时只需负责自己写的代码(支持如Node.js、Python、Java等7种编程语言),通过代码来实现业务逻辑。 Lambda按请求次数收费,每一百万次请求仅需要¥1.36,因此也非常适合用于监控警报处理的场景。
Open-Falcon
Open-Falcon是一款企业级、高可用、可扩展的开源监控方案,由小米开发,在目前流行的三大开源运维监控工具Zabbix、Nagios、Open-Falcon中属于后起之秀,目前很多国内大型公司都在使用Open-Falcon的监控方案。它可以从运营级别(基本配置即可),以及应用级别(二次开发,通过端口进行日志上报),对服务器、操作系统、中间件、应用进行全面的监控及报警。更多介绍请参考Open-Falcon。
方案架构
Open-Falcon 监控的模式主要分为两种,集中式采集和分布式采集,前者使用采集器通过SNMP或其它如telnet等方式进行数据采集,后者使用agent或定制化脚本(符合业务的需求,如取http服务的特定header或数据库的表内容)的方式进行数据采集。
在AWS上提供的服务和传统数据中心的服务模式对比也主要分为两类,虚拟机资源EC2和AWS的托管服务,如RDS、ElastiCache、ElastiSearch等。根据使用场景,运维监控的架构设计如下:

对于EC2,用户有访问EC2的操作系统及以上的权限,使用和本地机房一样的监控模式,满足运维监控一体化的目的。同时也可以使用CloudWatch监控服务作为补充。
对于其他AWS托管服务,用户有访问服务的权限,业务服务监控使用和本地机房一样的监控模式,AWS维护的操作系统及底层基础设施使用CloudWatch的监控能力来补充。
通过在CloudWatch中创建警报来根据指标(如CPU、disk utilization或service failover等)生成相关警报,并将警报通过SNS Topic的方式发送到Lambda,Lambda在接收后根据具体配置将警报发送到统一监控平台Open-Falcon,最后通过Open-Falcon中的关联的CMDB将告警信息发送到责任人或团队。
方案测试
以EC2为例,测试如何通过CloudWatch监控EC2的CPU使用率,并在CPU使用率高于90%的时候发送警报。
CloudWatch的配置
(1) 在CloudWatch管理控制界面中创建警报

(2)选择指标,点击下一步
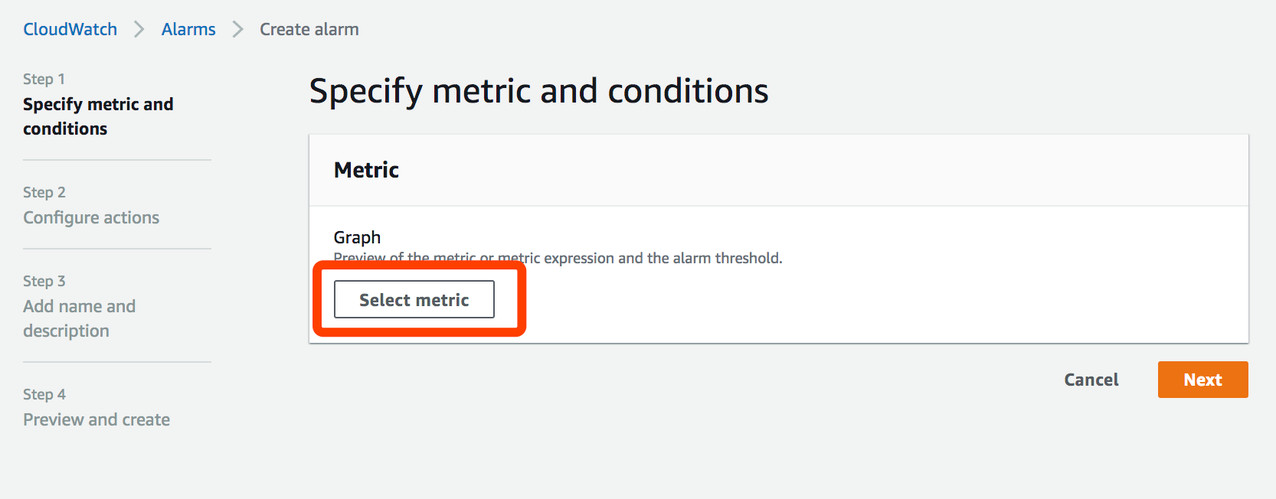
(3)在弹出的窗口中选择EC2,并根据instance的CPUUtilization选择指标


(4)根据实际情况配置监控周期。为了简化测试,我们设置为1分钟(当前Instance已经启用CloudWatch详细监控),在Conditions里面配置相应值 90

(5)在Steps2的配置界面创建或选中一个已经配置好的SNS Topic

(6)配置一个警报名称,点击下一步并检查,点击完成创建CloudWatch警报

Lambda配置
(1)在Lambda的管理控制界面点击创建函数
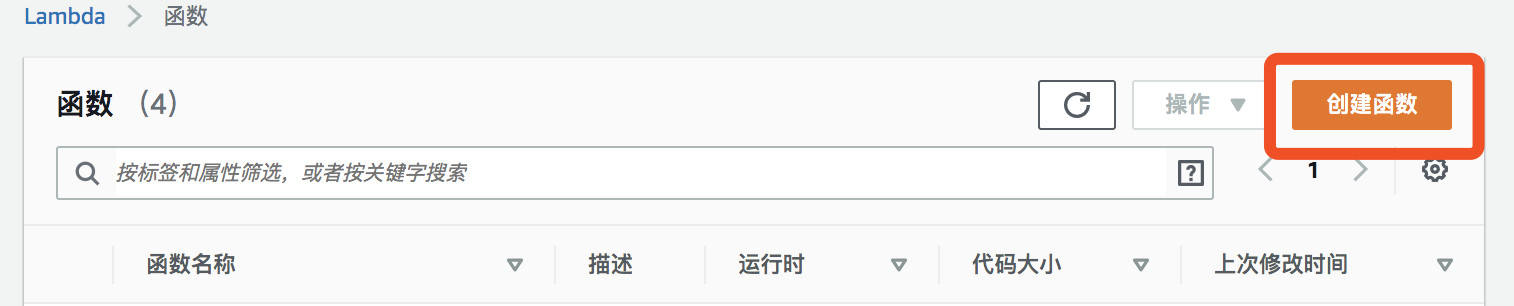
(2)输入函数名称,在运行中选择Python3.8
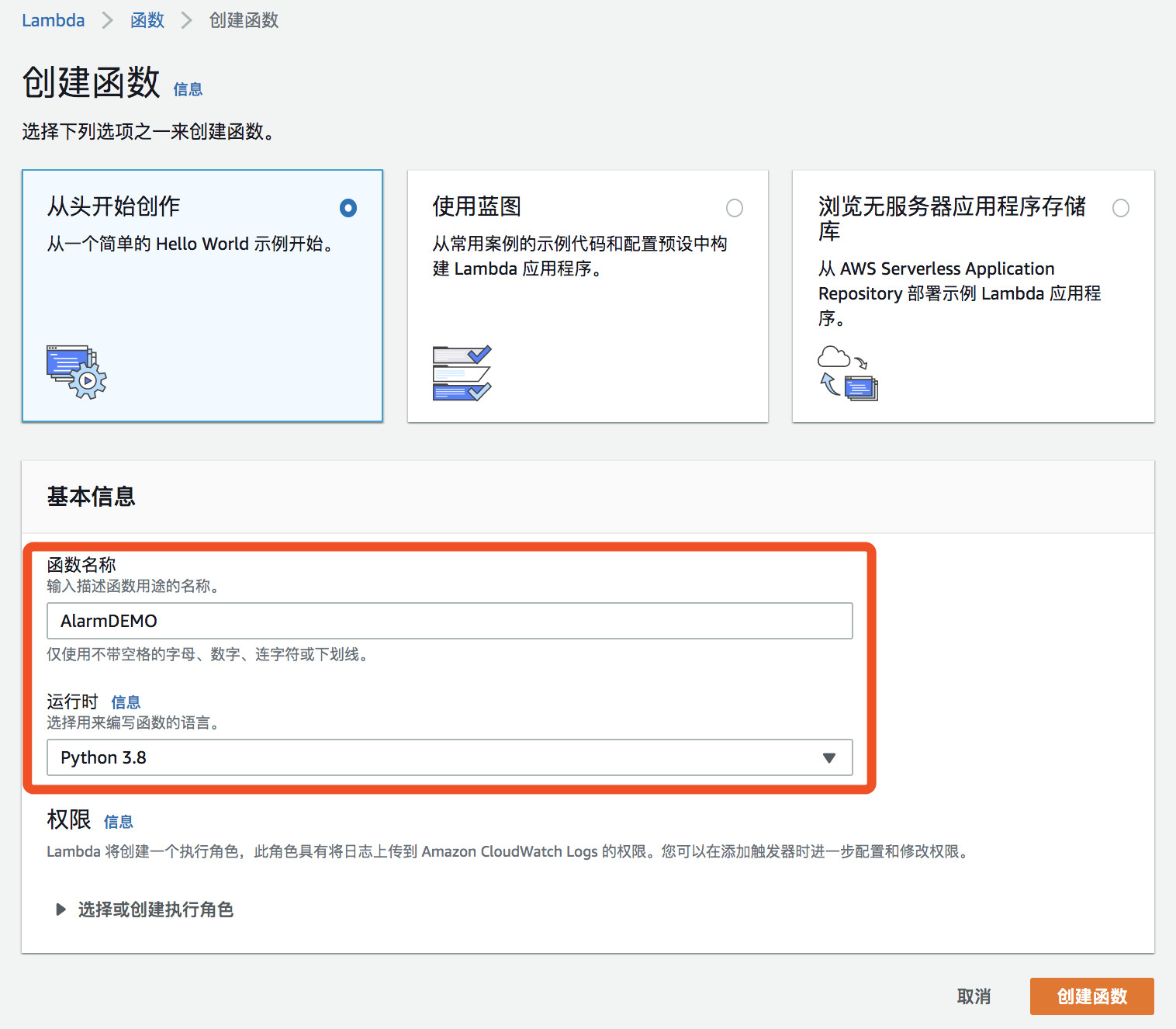
注意:
Lambda是一个全托管的服务,没有固定的公网IP,如果监控系统的API接口有安全上的限制,比如仅允许某个固定IP准入,则您可能需要将Lambda放在一个私有子网中,并通过部署在公有子网的NAT Gateway出去,这样可以保证Lambda有一个固定的EIP。
具体操作是您需要在创建函数的后在权限中赋予Lambda角色一个EC2的权限,并将Lambda函数添加到一个VPC中,本文不在阐述。
(3)在创建好的Lambda函数中选择添加触发器

(4)在触发器配置中选定SNS,并找到在CloudWatch警报中配置的SNS Topic

(5)添加Lambda Layer。

(6)本次演示是使用的requests模块,默认的boto3里面已经不再提供requests模块,因此我们需要手工添加一个Lambda Layer来支持requests调用。具体如何通过创建requests layer并附加到一个Lambda上,请参考博客使用AWS Lambda 的“层 (Layer) ”功能实现依赖包管理
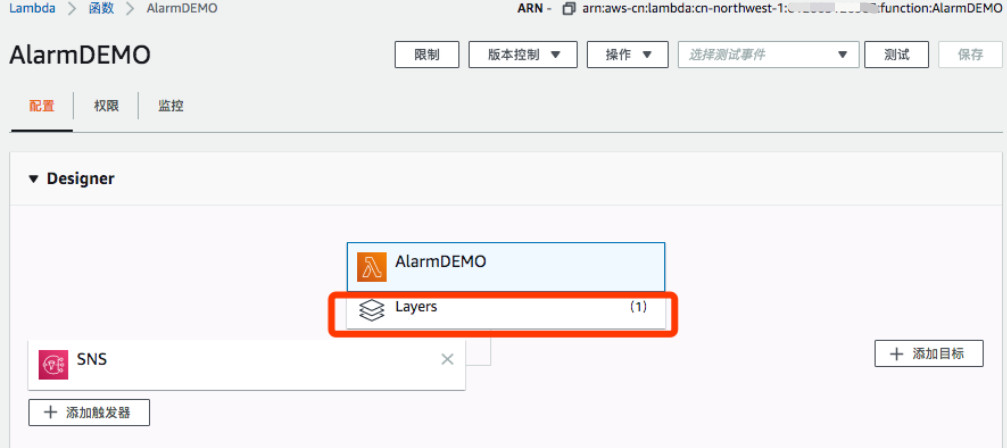
(7)添加代码
注意:
本次lambda函数中仅提取了alarmName(告警名称)、instanceid(实例ID)和alarmnmetric(指标名称)信息,其他信息需要根据实际监控平台的字段按照对应格式逐一填入。
所有的指标信息可以通过print(message)方式获取,具体指标范例如下:
所有的配置完成。
测试
(1)在instance i-123456789012345上创建一个test.sh文件,并通过如下代码将CPU的使用率提升到100%,使用方式为#sh test.sh 1, 1为第几个CPU。
(2)在CloudWatch收集到足够的性能指标数据后,在CloudWatch日志中的Lambda 日志里可以发现Lambda已经执行,并且数据已经成功从SNS中取出,发送到Open-Falcon监控平台

(3)Open-Falcon上接收到监控告警信息

总结
简而言之,AWS 平台上的服务非常灵活,用户可以根据Amazon CloudWatch来构建统一监控平台,也可以仅使用其部分监控和告警的能力来集成到本地监控系统,实现运维监控一体化的目标。AWS Lambda可以通过定制化的方式来满足不同业务场景的需求,也可以和其他相关服务集成进一步提升运维自动化的能力,例如集成chatbot技术实现在CPU达到阀值后通过聊天的方式和运维负责人沟通是否自动调整配置等。