如何使用 Babelfish for Aurora PostgreSQL 进行快速的数据库迁移
前言
关于本教程
时间 :50分钟
费用 :预估使用小于 $10
相关行业 :通用
相关产品 :Amazon Aurora PostgreSQL 兼容版
受众 :DBA/应用开发人员
级别 :初级
上次更新日期 :2023 年 3 月
1.1. 实验目的
全部打开- Babelfish for Aurora PostgreSQL 的架构和组件
- Babelfish 为应用迁移带来的快捷性和简便性
- 应用迁移到 Babelfish for Aurora PostgreSQL 的功能支持
- 数据迁移到 Babelfish for Aurora PostgreSQL 的方法
- 如何通过 Babelfish Compass 工具评估迁移的兼容性
- 应用切换及代码转换事宜
- Babelfish for Aurora PostgreSQL 平台的兼容性
- 如何在 Babelfish for Aurora PostgreSQL 平台上使用新的开发模式
- 如何使用 SQL Server 原生导入导出工具完成大量数据的迁移
数据库是通用应用系统的核心模块之一,在过去几十年里,商业数据库一直占据主导地位,但随着近些年来开源数据库的不断发展,其功能和性能几乎和商业数据库并驾齐驱,已经有越来越多的企业,选择使用开源数据库产品。
从商业的 Microsoft SQL Server 数据库迁移到开源数据库可能非常耗时且需耗费大量资源。迁移数据库时,您可以使用 AWS Database Migration Service (DMS) 自动迁移数据库架构和数据,但迁移应用程序本身时,通常需要完成更多的工作,包括重写与数据库交互的应用程序代码。
Babelfish for Aurora PostgreSQL 是 Amazon Aurora PostgreSQL 兼容版本的一项新功能,它让 Aurora 能够理解来自为 Microsoft SQL Server 编写的应用程序命令。借助 Babelfish,Aurora PostgreSQL 现在可以理解 SQL Server 专有的 SQL 语言 T-SQL,并支持相同的通信协议,您最初为 SQL Server 编写的应用程序现在可以与 Aurora 一起使用,并且所需进行的代码更改更少。因此,修改 SQL Server 2005 或更高版本上运行的应用程序并将其移动到 Aurora 所需的工作量将减少,从而可实现更快、风险更低且更具成本效益的迁移。
为了让您更深入地体验 Babelfish 的功能和熟悉相关操作,我们设计了这一个“使用 Babelfish 迁移 .NET 应用”的实验课程,通过这个实验,您将了解到以下内容:
在完成了相应的动手实验后,您将掌握以下内容:
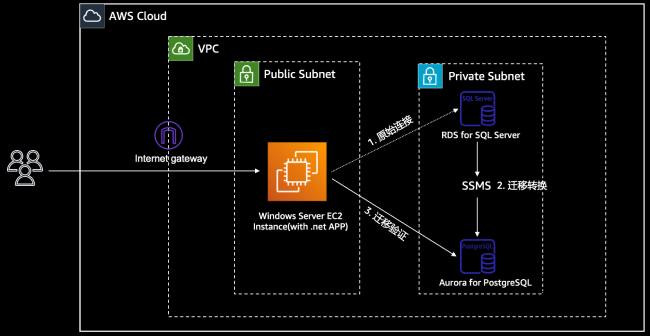
- VPC:包含公有和私有子网的虚拟私有网络环境
- EC2 实例:部署了.NET 应用以及数据库客户端工具的 Windows Server
- SQL Server 实例: RDS SQL Serves 数据库的节点
- Aurora for PostgreSQL 实例:Aurora for PostgreSQL 数据库集群的单节点
- C:\Demo\lab.txt - 内容包含实验 1 命令、实验 4 代码、实验 5 命令
- C:\Demo\BabelfishCompass - Babelfish Compass 评估工具
- C:\Demo\Data\init-data -SQL Server 和 Aurora PG 共用的初始化加载 SQL 脚本
- C:\Demo\Data\pg-fix -Aurora PG 使用的 SQL 更正脚本
环境架构
整个实验环境部署在亚马逊云科技公有云美国东部区域(us-east-1),整体架构如下图所示,主要的组件包括:
账号密码
|
操作类型 |
用户 |
密码 |
|
Windows on EC2远程桌面连接 |
administrator |
Work_123*$! |
|
RDS SQL Server 数据库连接 |
admin |
admin123 |
|
Aurora PostgreSQL数据库连接 |
postgres |
admin123 |
|
.net Web 应用登陆 |
0000 |
123456 |
工具和用途
以下工具已经在 EC2 上的 Windows server 中下载并安装配置好,无需下载
| Windows 桌面图标 | 
|

|

|
| 工具 | SQL Server Management Studio | dbeaver | IIS 管理器 |
| 用途 | 连接 RDS SQL Server | 连接 Aurora PostgreSQL | 管理.net web 应用 |
主要使用文件
以下文件和目录已经在 EC2 上的 Windows server 中放置好
2. 实验环境配置
全部打开- 如果没有 AWS Global 区域账号,请通过 Event Engine 申请临时的 AWS 操作权限以完成实验
- 通过AWS Cloudformation完成环境组件的部署
- 初始化数据导入及应用连接配置
在开始动手实验前,我们需要配置好实验环境,环境配置需要有 AWS Global 区域账号,具体的配置过程主要有以下几个步骤:
- 登陆 Event Engine 控制台
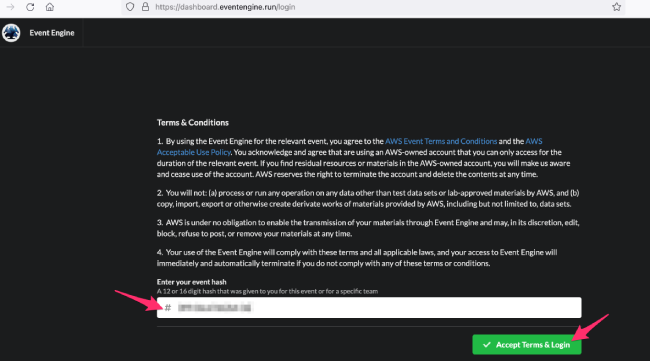
登陆 https://dashboard.eventengine.run/login,输入主持者发送的 Hash 号码,并点击下方的“Accept Terms & Login”
Event Engine 是 AWS 创建的一个工具,可为 Workshop 活动预置 AWS 账户。这些帐户将在workshop 开始后 24 小时自动终止,参与者不必担心留下任何东西。每个参与者都将收到他们自己的 Event Engine AWS 帐户。以下为激活实验账号的操作全过程。
2.点击 Email One-Time Password (OTP)/ 电子邮件一次性密码(OTP)
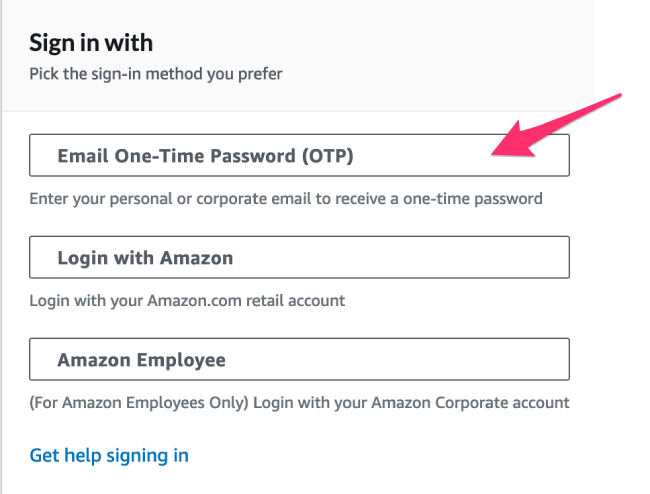
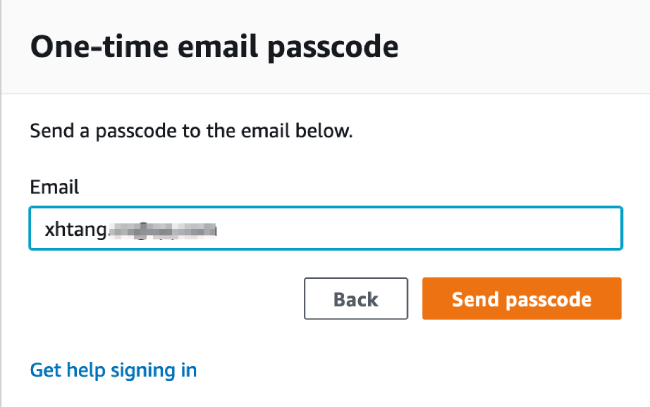
3. 输入您的电子邮件地址并点击 Send passcode / 发送密码
4. 检查您的邮箱,复制一次性密码,粘贴到页面中,点击 Sign in / 登陆
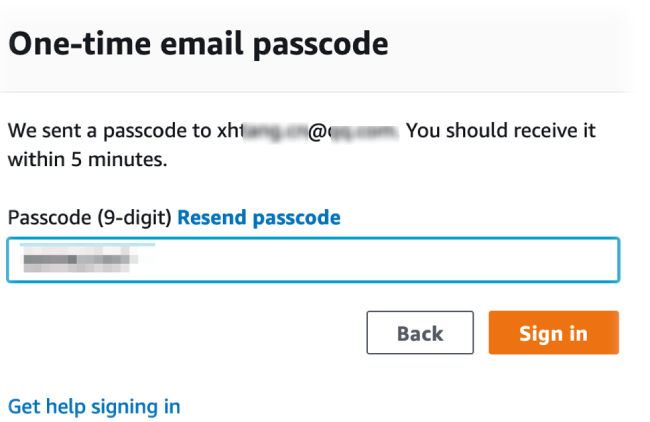
5. 登陆后在 Team Dashboard 面中点击 AWS Console
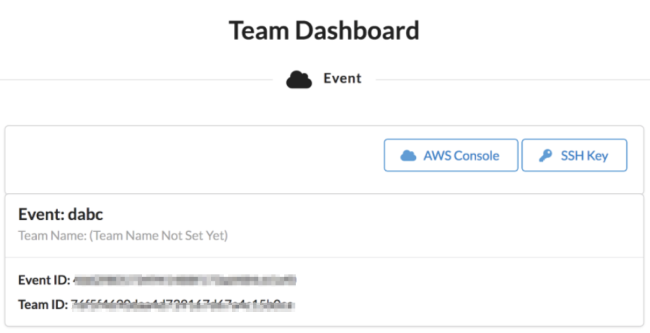
6. 在打开的页面中点击 Open AWS Console
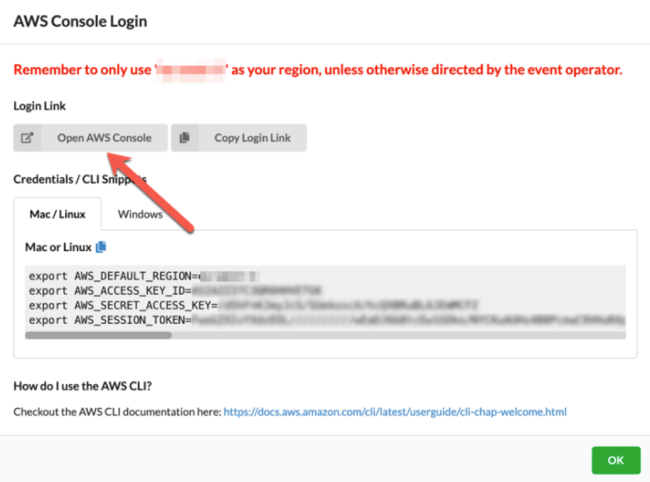
现在您可以在 AWS 服务控制台中查看并创建相关的服务以完成实验。
- 进入 CloudFormation 主页,在左侧菜单点击“Stacks”,在出现的页面中点击“Create stack”并选择“With new resources(standard)”,再点击页面中间的“Create stack”按钮
- 选择模版来源于“Amazon S3 URL”,输入 S3 中的地址:https://xiekl.s3.cn-northwest-1.amazonaws.com.cn/bingbing-dbwebniar/demo.yml 并点击下一步
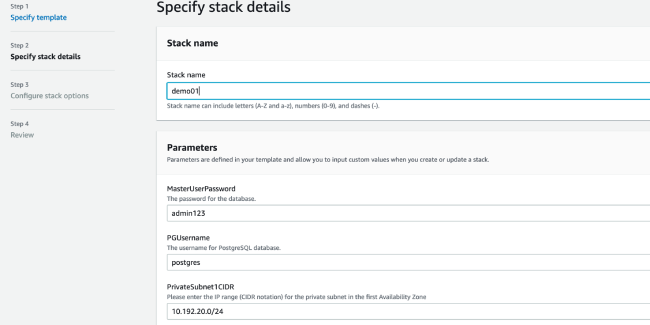
- 输入 CloudFormation 堆栈任务名称
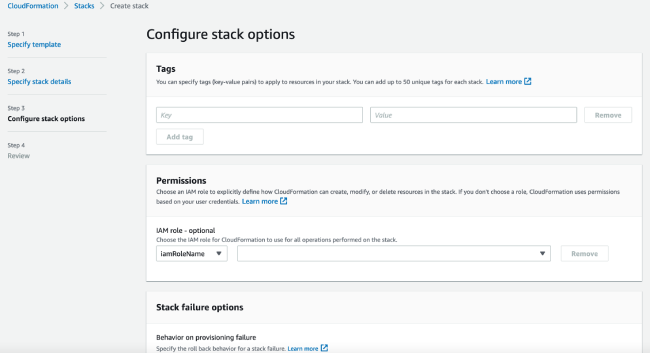
- 默认设置无需改动
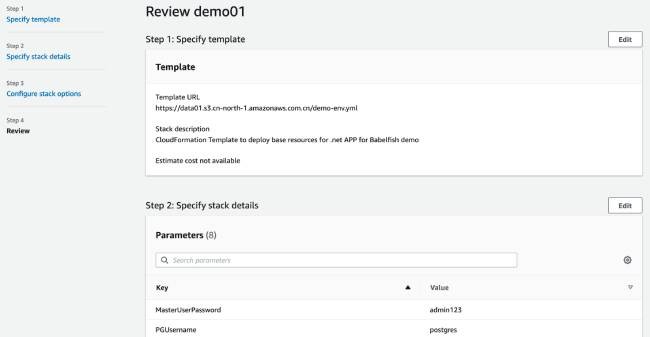
- 检查相关参数,并点击“Create stack”
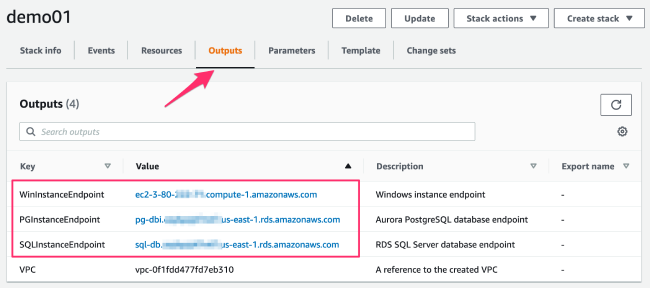
- 点击堆栈名显示详细信息,点击“Output”页面,查看实例的连接 Endpoint,并记录以备后续使用。这里有三个 Endpoint ,具体连接用途如下:
- WinInstanceEndpoint: Windows Server on EC2 远程桌面连接地址
- PGInstanceEndpoint: Aurora PostgreSQL 连接端点
- SQLInstanceEndpoint:RDS SQL Server 连接端点
AWS CloudFormation 是在 AWS 上实践基础设施即代码的重要服务之一,使用该服务,我们能够使用模板定义创建、配置云服务资源的操作,利用模板进行资源的创建能够减少重复的劳动,提高效率。本次实验使用 CloudFormation 部署 VPC 和相关的各个实例,实验中的所有操作都是在 us-east-1 区域中操作,请首先在账户的区域中确认当前使用区域为 us-east-1
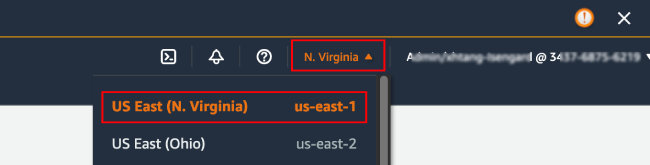
接下来的具体操作过程如下:
1.创建新的CloudFormation堆栈任务
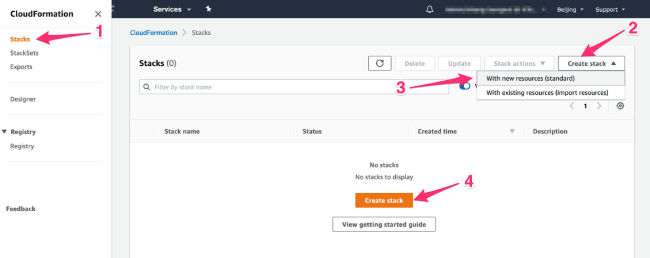
2. 第一步:准备模版
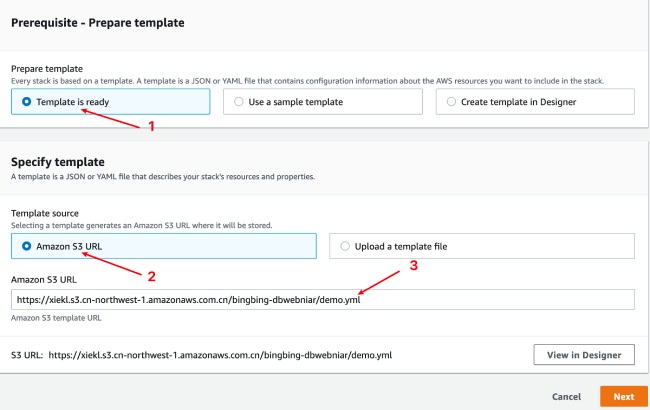
3. 第二步:配置堆栈信息
4. 第三步:配置堆栈选项
5. 第四步:审查堆栈任务
6. stack 创建过程基于网络状态大概等待十五分钟后,堆栈任务创建成功
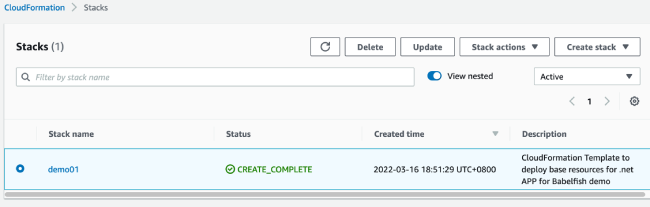
7. 查看 CloudFormation 堆栈任务的输出
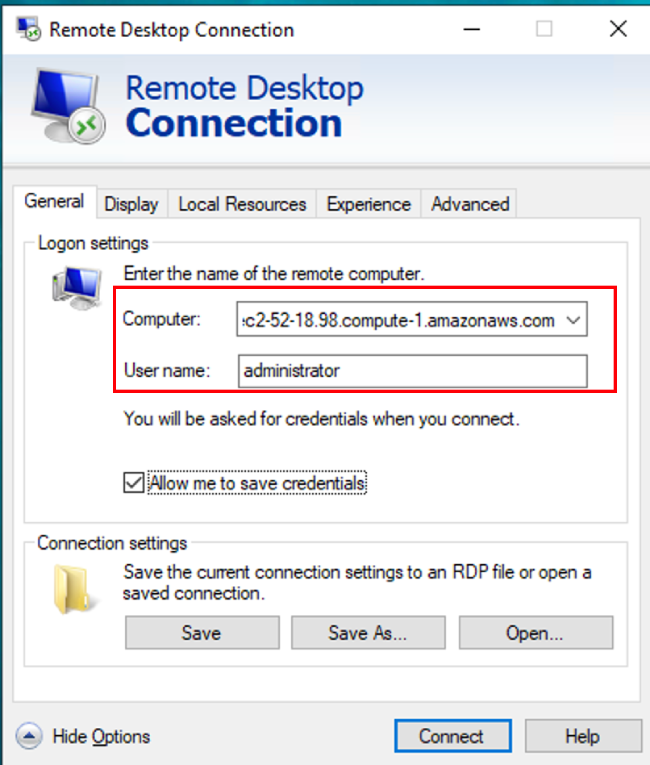
- 如使用Windows操作系统的话,打开远程桌面程序连接EC2实例(通常在Windows运行对话框中输入 mstsc 即可打开),如使用MacOS系统的话,安装微软远程桌面工具并连接EC2实例
- 连接地址:查看stack中输出的 WinInstanceEndpoint 信息
- 登陆用户:查看1.2 实验环境中 "Windows on EC2远程桌面连接用户" 信息
- 连接地址:查看stack中输出的 SQLInstanceEndpoint 信息,手工输入地址
- 登陆用户:查看1.2 实验环境中“RDS SQL Server 数据库连接”信息
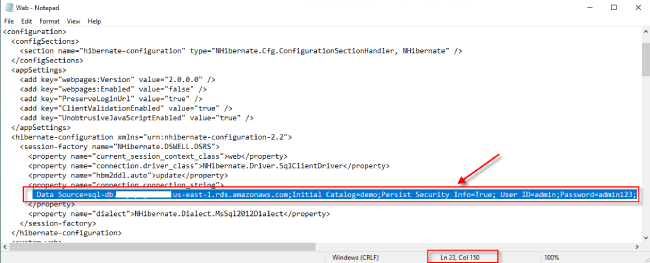
- 在 23 行修改数据库连接设置为 RDS SQL Server 的内容(参考步骤 2 所查看信息)
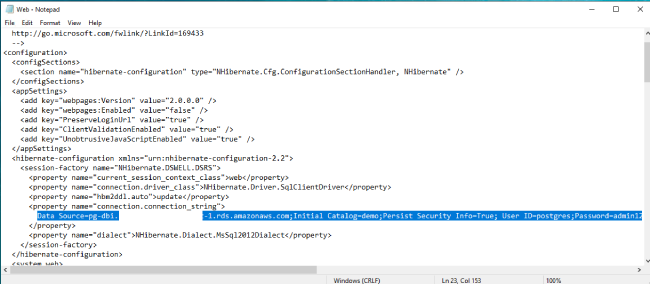
Data Source=数据库连接端点;Initial Catalog=demo;Persist Security Info=True; User ID=数据库用户名;Password=密码; - 登陆用户:查看 1.2 实验环境中“.net Web 应用登陆”信息
1. 实验的开始前,我们需要初始化环境,将应用配置为 .net + SQL Server 的架构。在上一步通过Cloudformation部署的EC2实例中已包含了相关的 .net 应用和数据库客户端,为了正常启动应用服务,需要连接RDS SQL Server数据库初始化数据。
2. 在远程桌面使用SQL Server Management Studio (SSMS) 登陆RDS SQL Servers
3. 登陆后,在菜单中依次选择“File”→“Open”→“File”
4 选择“C:\Demo\Data\init-data”文件打开
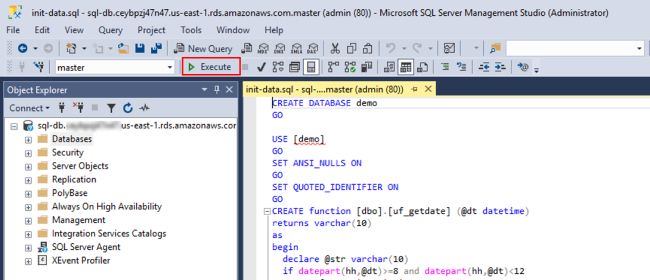
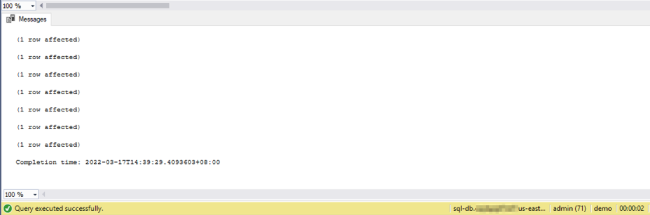
5. 在 SMSS 控制台上点击“Execute”执行
6. 等待 SQL 脚本执行完毕
7. 修改 APP 应用的配置文件 C:\web\Web.conf
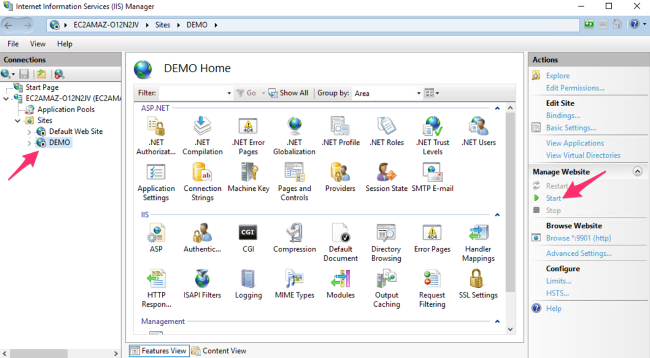
8. 打开 IIS 服务管理,启动 DEMO 的网站,并点击下面的“Browse Website”
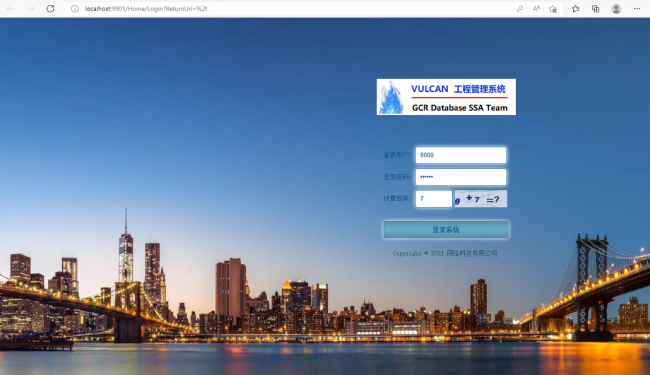
9..在自动打开的 Edge 浏览器地址中使用 WEB 应用账号登陆应用也可以手工输入应用的网址 http://localhost:9901
3. 实验 1 - Babelfish Compass 做迁移评估
全部打开- 在源库(SQL Server)上生成 DDL 脚本
- 执行 Babelfish Compass 程序生成评估报告
- 解读并分析评估报告
数据库的迁移是一项需要谨慎对待和全面考虑的工作,数据结构部分能较容易地评估迁移可行性,而更多的 SQL 程序对象如存储过程,函数,触发器等迁移则需要丰富的技术经验以及大量的时间成本才能完成。
Babelfish Compass 是一个开源工具,这个评估工具能评估 SQL Server 的 SQL/DDL 代码对 Babelfish 的支持级别。它会列出被评估的 SQL/DDL 代码中所有的 SQL 功能,还会告诉你最新版本的 Babelfish 是否支持这些功能。软件可在GITHUB页面下载,支持 Windows 和 Linux 平台,运行时需要预装 JAVA 环境。Babelfish Compass 工具和 JAVA 在此 Workshop 环境中已经下载并安装完毕,不需要其他的操作。
在第一个实验中,我们使用 Babelfish Compass 对当前的应用进行评估,熟悉如何生成评估结果并解读评估报告。完整的流程主要有以下几步:
- 选中数据库"demo"并按鼠标右键,菜单中依次选择“Tasks”→“Generate Scripts”
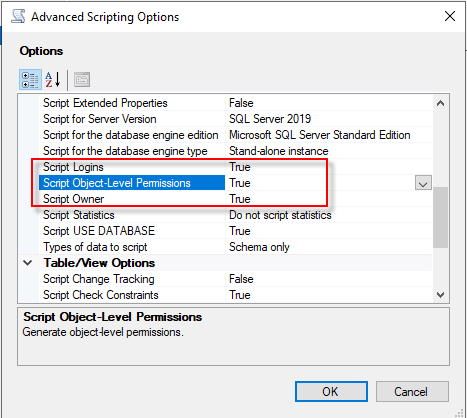
- Script Extended Properties – 选择 False
- Script Logins – 选择 True
- Script Object-Level-Permissions – 选择 True
- Script Owner – 选择 True
- Script Indexes – 选择 True
- Script Triggers – 选择 True
- 打开一个命令行窗口,进入Babelfish Compass 目录:cd C:\Demo\BabelfishCompass
- 执行命令:
.\BabelfishCompass.bat demo-report C:\Users\Administrator\Documents\script.sql -reportoption xref - 命令执行后生成报告并自动打开浏览器显示报告
- Babelfish Compass 报告主要包括如下图中所示的几部分:
- ALTER AUTHORIZATION 语法不支持,可以直接注释屏蔽
- SET ROWCOUNT 语法不支持,需改写
- ALTER ROLE 语法不支持,可以直接注释屏蔽
- 回到报告目录中,选择“X-ref: 'Not Supported' by SQL feature"
- 'Review Manually' - 语句可执行但需要人工再检查具体内容,如涉及动态 SQL 的语句,需要查看具体的动态SQL是否能支持
- 'Review Semantics' - 语句可执行但需要结合 SQL 语句查看语义,确保执行结果和SQL Server中相同,如 Select Top 语句且没有 Order by 的查询
- 'Review Performance' - 语句可执行但需要评估语句对性能是否有影响
- 'Ignored' - Babelfish 中不支持的选项,语句无需修改会自动忽略
- 对于不支持的特性,需要调整的,改写相关语句或寻找替代方法,下图显示的即为修改后的结果,在下一个实验中我们学习如何修改
1. 使用SQL Server Management Studio (SSMS) 登陆 SQL Servers
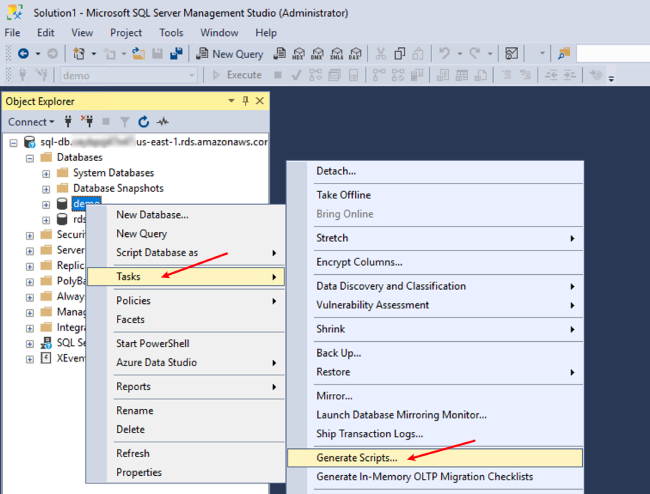
2. 在 Choose Objects(选择对象)页面中,首先勾选"Select specific database objects",再在下方点击选择"Select All"
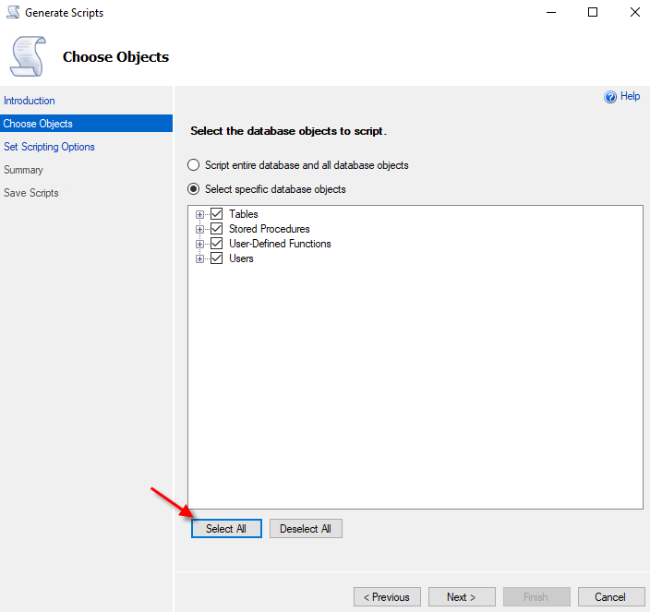
3. 在 Set Scripting Options(设置脚本选项)页面上,选择 Save as script files(保存为脚本),同时选择 Advanced(高级)按钮
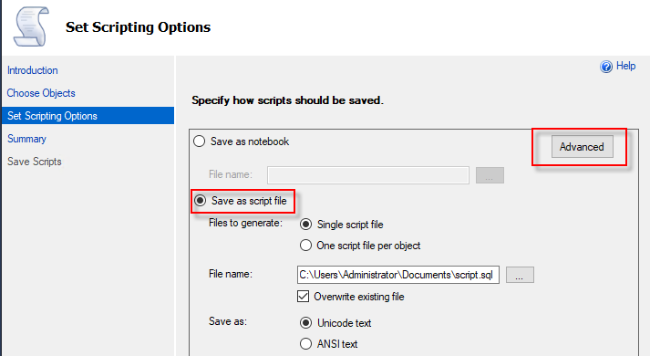
4. 在 Options 中由上至下设置以下选项:
5. 在脚本选项设置页面中点击"Next"按钮
6. 在 Summary 页面中点击"Next"按钮
7. 所有导出步骤完成后点击"Finish"按钮结束任务
8. 执行 Babelfish Compass 程序生成报告 (可拷贝 C:\Demo\lab.txt 的相关命令)
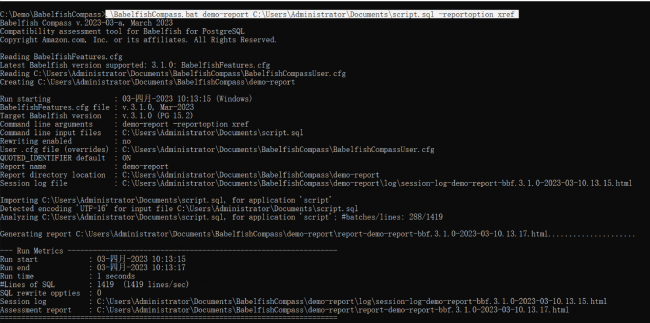
9. 报告解读

先查看 Assessment Summary(评估总结)和 Object Count(对象统计)
这一段显示总体情况:DDL 行数,支持和不支持的特性数量等信息,以及根据对象所列出的支持和不支持的特性数量
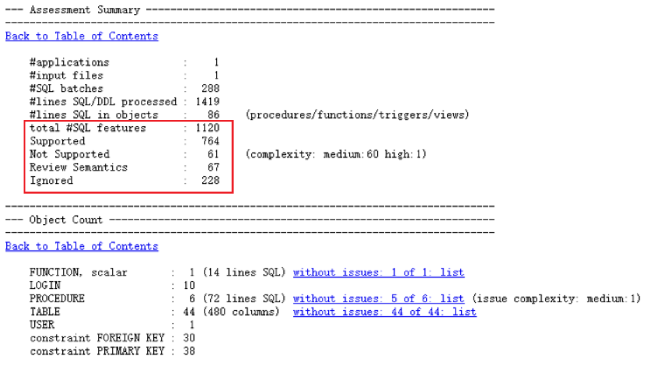
再查看不支持特性的描述“Summary of SQL Features 'Not Supported'”
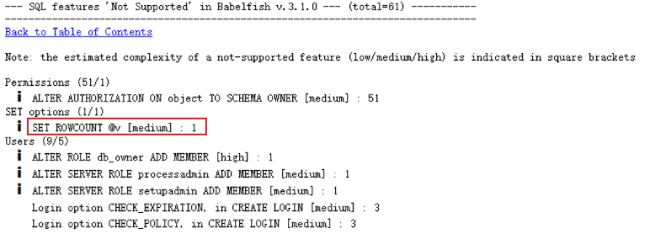
查看不支持特性涉及的具体 SQL 语句
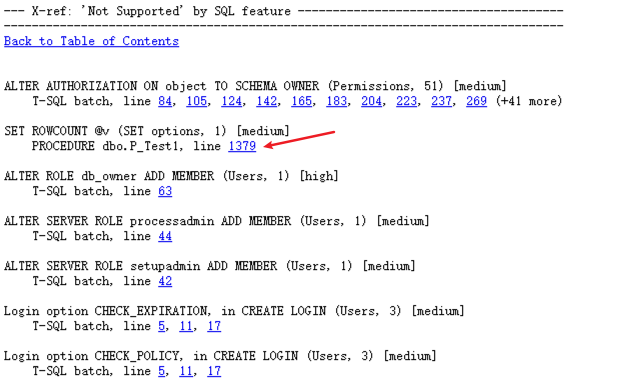
继续查看其他一些需要注意分类总结和详细类容
10. 根据评估报告进行相应调整
通过这个实验,让我们体会到 Babelfish Compass 是一个简单易用,快捷高效的针对 Babelfish 平台迁移的评估工具,它有助我们从总体上把握迁移的复杂性和进度。对于不支持的特性,即语法或语句,我们可以尝试通过改写或寻找替代方案的方式解决。
4. 实验 2 – 应用切换到 Aurora 平台
全部打开迁移项目中,经过前期的迁移评估和相应的代码调整及小数据量的测试后,可以启动正式的迁移过程。首先需要在目标库创建相关的 SCHEMA 及程序代码,数据的迁移可以使用 AWS Database Migration Service (AWS DMS)导入并设置 CDC 增量同步,并选择合适的时机进行数据库和应用的切换。
在这个实验中,我们使用从源库导出的包含数据的 DDL 脚本在目标库执行,并对不支持特性的部分 DDL 进行修改并应用到目标库上,最后通过修改数据库连接的方式完成整体应用的切换。
- 点击左侧的数据库连接,连接地址请查看 stack中output的PGInstanceEndpoint 信息,登陆用户请查看 1.2 实验环境中“Aurora PostgreSQL 数据库连接”信息
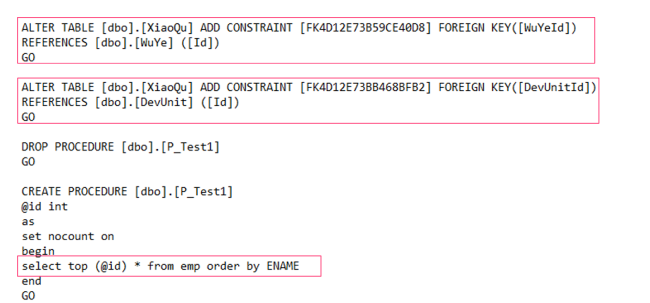
- SQL Server 中的 WITH CHECK ADD CONSTRAINT 语句即添加一个约束,并将其应用到已存在的数据中,当前 Babelfish for Aurora PostgreSQL 不支持此语句,在保证已有数据引用正确的情况下,可去掉 WITH CHECK,同时删除启用约束的语句 ALTER TABLE .. CHECK
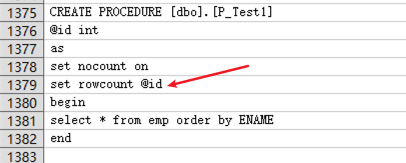
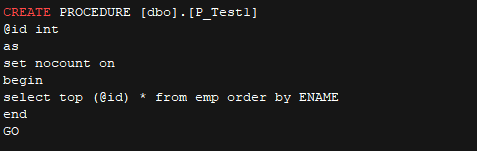
- SQL Server 中的 set rowcount 语句是在返回指定的行数之后停止处理查询,当前 Babelfish for Aurora PostgreSQL 不支持此语句,无法生效,但可编译通过。此种情况可以使用 TOP 语句改写。
- 在 23 行修改数据库连接设置为 Aurora for PostgreSQL
1. 使用 SQL Server Management Studio 连接 Aurora for PostgreSQL 实例
2. 菜单中依次选择“File”→“Open” →“File”,打开“C:\Demo\Data\init-data”文件
3. 在 SMSS 控制台中点击“Execute”按钮执行
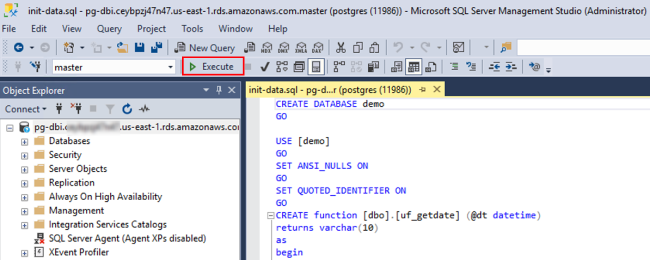
4. 执行完毕,在信息框中拉到报错的地方,查看具体错误信息
错误:“'ALTER TABLE WITH [NO]CHECK ADD' is not currently supported in Babelfish.”此错误即 Babelfish Compass 评估提示的兼容性问题之一
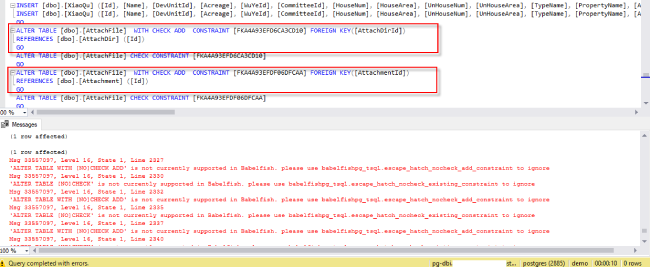
5. 解决DDL兼容性问题
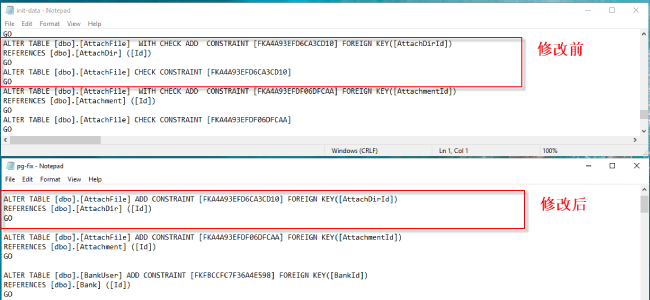
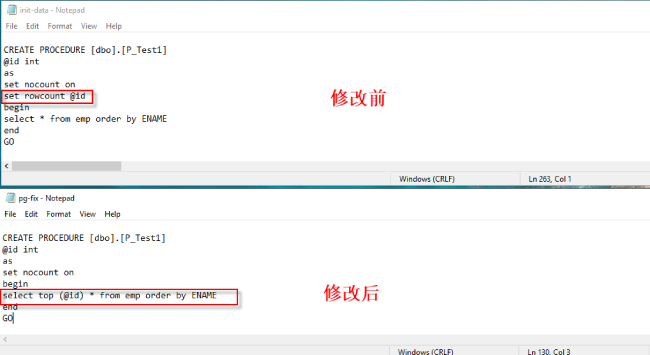
6. SMSS 中打开“C:\Demo\Data\pg-fix”文件执行修改脚本
7. 修改应用配置文件 C:\web\Web.conf
8. 在 IIS 管理中重新启动 DEMO 站点并登陆测试
通过应用切换实验,让我们进一步了解应用迁移的正确步骤:首先要结合 Babelfish Compass 的评估,对不兼容特性做好修复。迁移过程中,结合 bcp/DMS 等数据迁移工具,可以做到大数据量情况下最小化停机时间,避免影响生产业务。
5. 实验 3 – Aurora 平台的兼容性
全部打开Babelfish 是一种扩展,它的存储库是 PostgreSQL。Babelfish 支持 T-SQL 协议、T-SQL 语言、TDS 协议等。这就使我们可以使用 T-SQL 语法对 PostgreSQL 数据库进行操作。而这个插件的最强优势就是,以最大兼容性/最小更改去迁移 MSSQL 到 PostgreSQL。
Babelfish for Aurora PostgreSQL 试图尽可能兼容 Microsoft SQL Server,但当前仍有一些限制。要了解有关这些限制的更多信息,请查看 AWS 的官方文档以获取更详细的说明:https://docs.amazonaws.cn/AmazonRDS/latest/AuroraUserGuide/babelfish-compatibility.html
在本次实验中,我们会在.net应用中调用以下存储过程,这些存储过程从 SQL Server 源库中迁移而来,除了 p_test1 有修改外,其他都没有更改。下表为过程说明:
|
过程名 |
参数 |
效果 |
说明 |
|
p_test1 |
数字 |
显示指定的记录数 |
如何转换不支持语法 set rowcount |
|
p_test2 |
日期 |
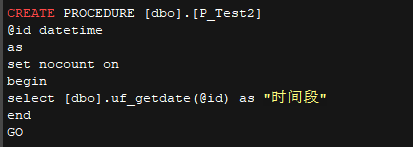
判断给定时间的时段 |
过程中调用自定义函数 |
|
p_test3 |
任意 |
显示连接数据库信息 |
显示当前连接的实例信息 |
|
p_getsal |
字符% |
显示员工工资 |
显示sql server支持的货币类型数据 |
|
p_sumsal |
字符% |
显示部门工资汇总 |
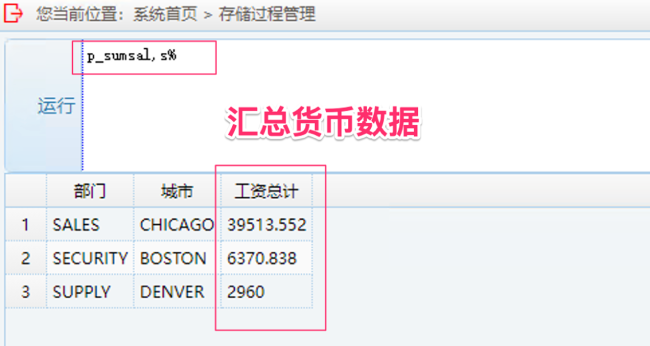
显示汇总货币字段数据 |
|
p_runtimes |
数字 |
插入数据 |
按次循环,1次1千条数据插入 |
p_test1 代码
• p_test2 和调用的自定义函数代码
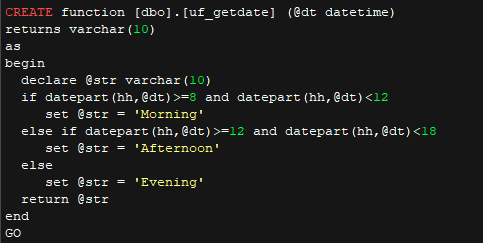
• p_test3 代码
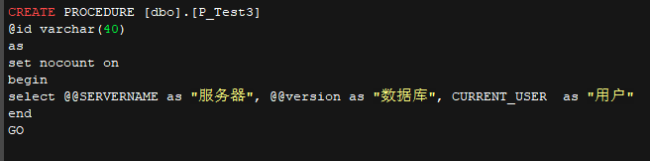
• p_getsal代码
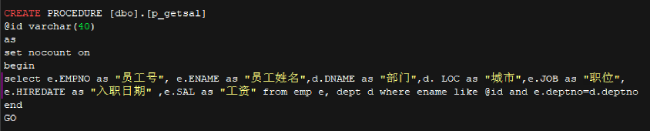
• p_sumsal 代码

• p_runtimes 代码
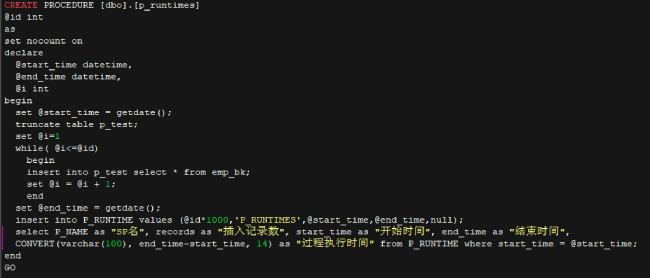
1. 在远程桌面上打开 Edge 浏览器,输入 http://localhost:9901,登陆 Web 应用登陆后在 Web 应用的左侧选择“数据库管理”→“存储过程管理” 菜单
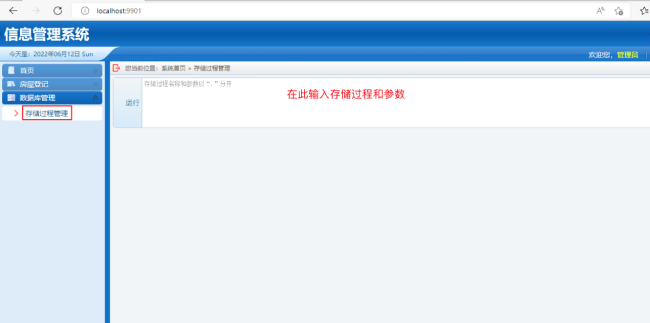
2. 在运行框中输入存储过程名,参数,然后点击“运行”,运行改写兼容性测试:输入 p_test1, 整数参数值,指定显示的行数
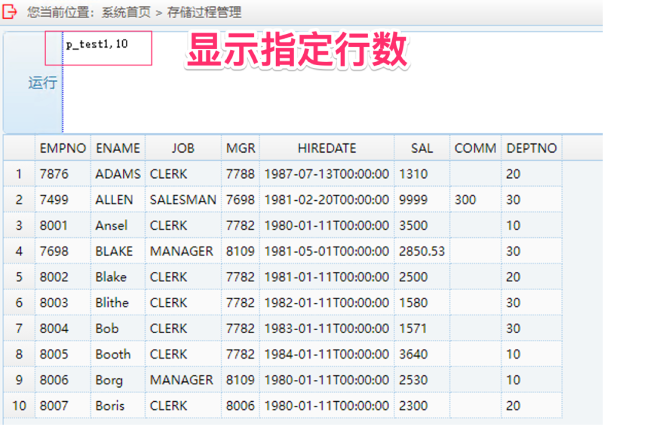
3. 运行自定义函数兼容测试:输入 p_test2, 时间日期格式参数
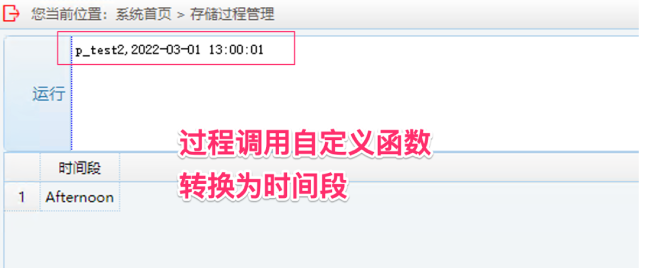
4. 运行后端数据连接检测:输入 p_test3,任意数值参数
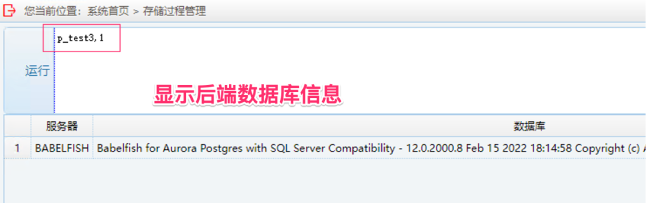
5. 运行 money 字段兼容性测试:输入 p_getsal, 字符加 % 为参数
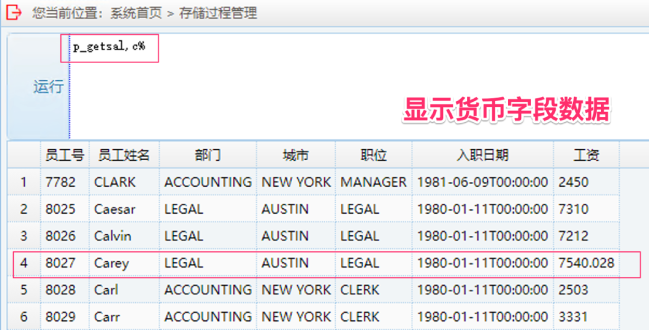
6. 运行 money 字段函数操作兼容性测试:输入 p_sumsal, 任意字符加 %
7. 运行性能测试:输入 p_runtimes, 插入执行次数

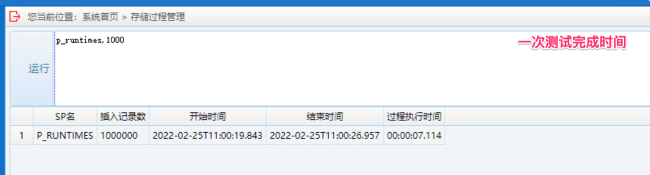
运行后显示插入记录数和执行时间
通过这个实验,使我们体会到 Babelfish for Aurora PostgreSQL 能兼容大部分的 T-SQL 代码,可以非常方便地将基于 SQL Serve 开发的应用顺利迁移过来,迁移后的 .NET Web 应用使用功能正常。而对于当前不支持的某些 T-SQL 代码,可以使用改写等方式进行替换。更多的兼容性改写案例请参考博客:使用 Babelfish 加速迁移 SQL Server 的代码转换实践
6. 实验 4 – 两种平台的开发模式
全部打开- 使用 SQL Server 驱动开发 T-SQL 代码
- 使用开源驱动开发 PL/pgSQL 代码
- 在 PostgreSQL 开发的代码,使用 SQL Server 驱动调用
随着业务的发展及应用现代化的需求,您可以选择在 Babelfish for Aurora PostgreSQL 平台的开发模式。通常来说,有以下几种开发模式:

在这一个实验中,首先我们在 Aurora PostgreSQL 中创建一个自定义函数,然后用 SMSS 连接到 SQL Server 中调用此函数;另外,我们在 PostgreSQL 中创建第二个自定义函数,使用 T-SQL 语法和函数,并在 PostgreSQL 中调用。通过验证这些代码是否调用执行成功,来展示不同开发模式的可行性。
- 连接地址请查看 stack 中 output 的 PGInstanceEndpoint 信息
- 登陆用户请查看 1.2 实验环境中 Aurora PostgreSQL 数据库连接”信息
- 登陆的数据库选择 babelfish_db
- 此函数返回数组为查询 dept 表的所有内容
- 登陆后选择"demo"数据库,点击鼠标右键,打开一个新的查询
- 在dbeaver的查询页面中输入以下代码(代码可从C:\Demo\lab.txt 中拷贝),创建自定义函数 check_date(), 此函数显示当前时间和输入的 N 天前的时间差
- select public.check_date(1) as "1 Day", public.check_date(5) as "5 Days"
1. 在远程桌面上打开 dbeaver,通过 PostgreSQL 驱动登陆 Aurora PostgreSQL
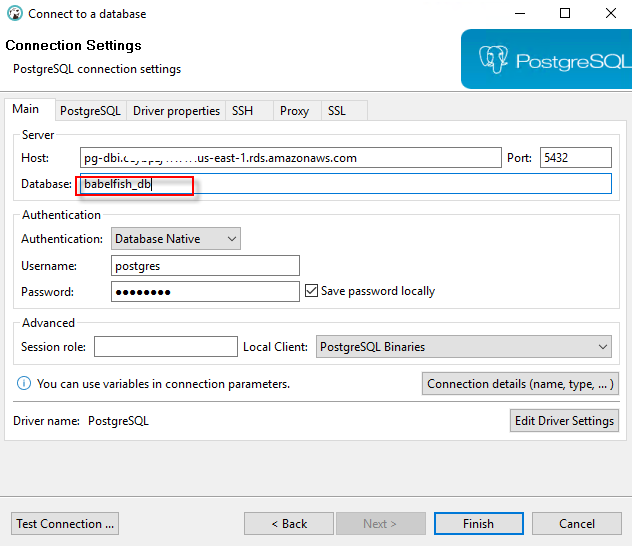
2. 在dbeaver的查询页面中输入以下代码,创建自定义函数 getcity()(代码可从C:\Demo\lab.txt 中拷贝)
create or replace function dbo.getcity() returns setof dbo.dept as
$$
begin return query select * from dbo.dept;
end;
$$
language plpgsql;

3. 使用 SMSS 通过 SQL Server 驱动登陆
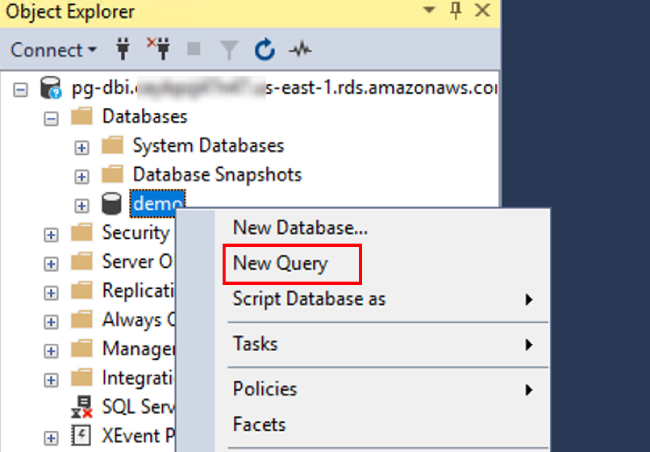
调用在 PostgreSQL 中创建的自定义函数 getcity(),显示执行成功 select * from dbo.getcity()
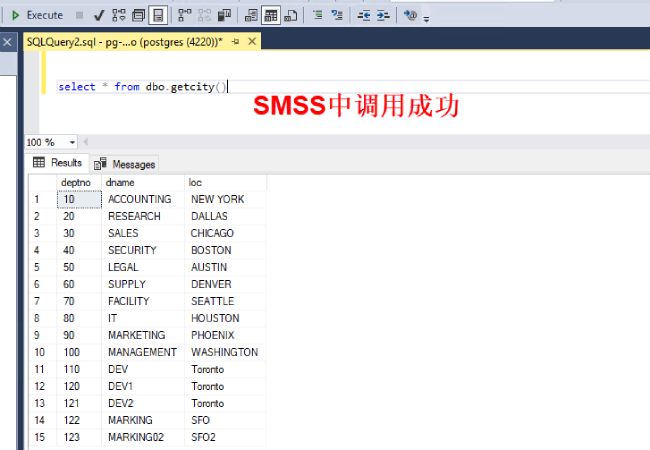
4. 打开 dbeaver,通过 PostgreSQL 驱动登陆 Aurora PostgreSQL
CREATE FUNCTION public.check_date("@rq" int) RETURNS int
LANGUAGE pltsql
AS '{"version_num": "1", "typmod_array": ["-1", "-1"], "original_probin": ""}', 'BEGIN
DECLARE @h1 int
set @h1 = datediff(hour,getdate()-@rq,getdate());
RETURN(@h1)
END';
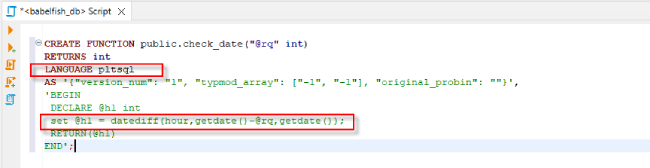
5. 在 Aurora PostgreSQL 中执行含有 T-SQL 函数的代码
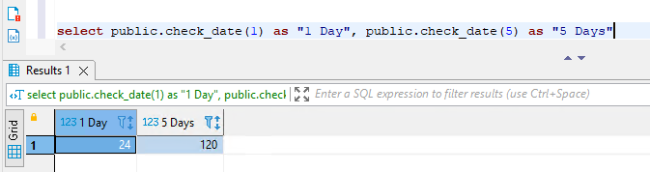
执行后显示正确的结果
通过这个实验,让我们了解到 Babelfish for Aurora PostgreSQL 支持不同的开发模式:支持在 SQL Server 侧或者 PostgreSQL 侧的代码开发,也可以在 SQL Server 中调用 PostgreSQL 上开发的代码,客户可以根据业务发展需求而灵活选择。同时,这种开发模式也提供了多一种 Babelfish 不支持特性的改写方式,即在 PostgreSQL 一侧使用相关特性来开发,再在 Babelfish 中调用。
7. 实验 5 - 使用原生 bcp 工具迁移数据
全部打开由于 Babelfish 是运行在 PostgreSQL 之上的扩展,数据实际存放在 PostgreSQL 数据库的表中,显而易见它不支持常规的 SQL Server 数据库备份和恢复方式来迁移,数据迁移是以表和其他对象的级别做迁移。有多种方法可以将数据从现有 SQL Server 迁移到 Amazon Aurora 数据库群集,具体取决于迁移时间、数据规模、成本大小等考虑。您可以使用原生的 SQL Server 工具如 SQL Server Management Studio (SSMS)、bcp 实用工具以及 SQL Server Integration Services (SSIS) 来迁移 SQL Server 的数据到 Babelfish 中。另外,一些常用的数据库管理工具,例如 DBeaver、DbVisualizer 和 Navicat for SQL Server 等也都带有数据导出导入功能。除此之外,使用 ETL 工具来迁移数据也是一种可行方法。
在这一个实验中,我们使用原生 bcp 工具来迁移一张大表,源表的大小如下图所示:
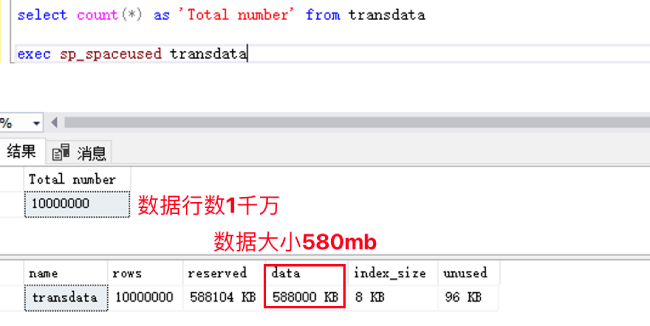
表数据已经通过 bcp 导出为格式文件存放在 c:\demo\transdata.csv,我们的实验将在 Babelfish for Aurora PostgreSQL 上创建表并导入数据
- 登陆后选择 "demo" 数据库,点击鼠标右键,打开一个新的查询
- 打开 c:\demo\lab.txt,拷贝 lab5 的建表语句粘贴到 SMSS 查询窗口,点击 “Execute” 按钮执行,创建了导入数据的目标表
1. 使用 SMSS 通过 SQL Server 驱动登陆到 Babelfish for Aurora PostgreSQL

2. 打开 windows 命令行程序,进入到 c:\demo目录,执行下面的bcp 命令导入数据到目标表中
bcp transdata in transdata.csv -w -b 10000 -m 1000 -E -e err1.log -S "pg端点" -U "postgres" -P "admin123" -d "demo"
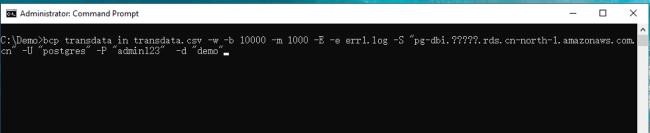
以上命令相关参数说明:
-w:使用 Unicode 字符执行大容量复制操作
-b:指定每批导入数据的行数
-E:指定导入数据文件中的标识值用于标识列
-m:指定取消 bcp 操作之前可能出现的语法错误的最大数目
-e:指定错误文件的完整路径
3. 等待 bcp 命令导入数据完成,案例中的1千万行数据导入大约在几十秒左右
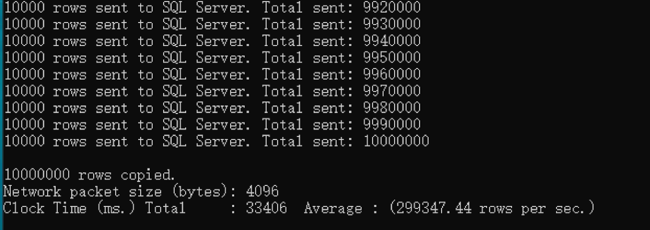
4. 在目标库中验证表的行数及自增字段值是否正确
在 SMSS 中执行以下两个查询进行验证:
select count(*) from transdata
select min(empno),max(empno) from transdata
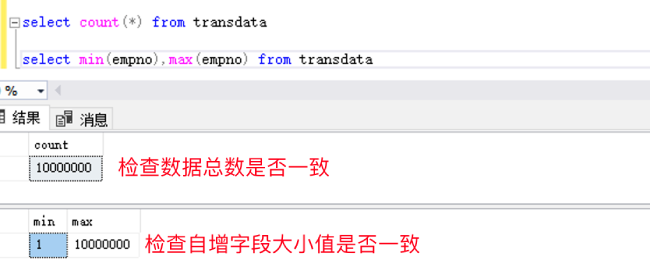
通过这个实验,让我们了解到使用原生 bcp 工具可以非常方便地迁移大量数据到 Babelfish for Aurora PostgreSQL 上。除此之外,还有多种数据迁移方法,如何选择,要从性能、功能、成本和简易性等多个方面考虑。更多的信息请参考博客:适用于 Babelfish 为目标的 SQL Server 数据迁移方法
8. 清理实验环境
全部打开完成全部实验后,需要清理相关的实验环境。清理步骤如下:
1. 在 CloudFormation 控制台的堆栈页面中,选择要删除的堆栈。该堆栈当前必须处于运行状态。在堆栈详细信息窗格中,选择 Delete (删除)
2. 在系统提示时,选择 Delete stack (删除堆栈)
3. 等待大约 10分 钟后,查看堆栈信息显示删除成功栈,此实验正式完成。