Was ist Datenarchitektur?
Was ist Datenarchitektur?
Datenarchitektur ist das übergreifende Framework, das die Datenerfassung, -verwaltung und -nutzung eines Unternehmens beschreibt und regelt. Unternehmen verfügen heute über riesige Datenmengen, die aus verschiedenen Datenquellen stammen, und unterschiedliche Teams, die auf diese Daten für Analytik, Machine Learning, künstliche Intelligenz und andere Anwendungen zugreifen möchten. Moderne Datenarchitektur stellt ein zusammenhängendes System dar, das Daten zugänglich und nutzbar macht und gleichzeitig die Datensicherheit und -qualität gewährleistet. Sie definiert Richtlinien, Datenmodelle, Prozesse und Technologien, die es Unternehmen ermöglichen, Daten einfach zwischen Abteilungen zu verschieben und sicherzustellen, dass sie bei Bedarf verfügbar sind – einschließlich Echtzeitzugriff. Gleichzeitig wird die Einhaltung gesetzlicher Vorschriften in vollem Umfang unterstützt.
Was sind die Komponenten einer Datenarchitektur?
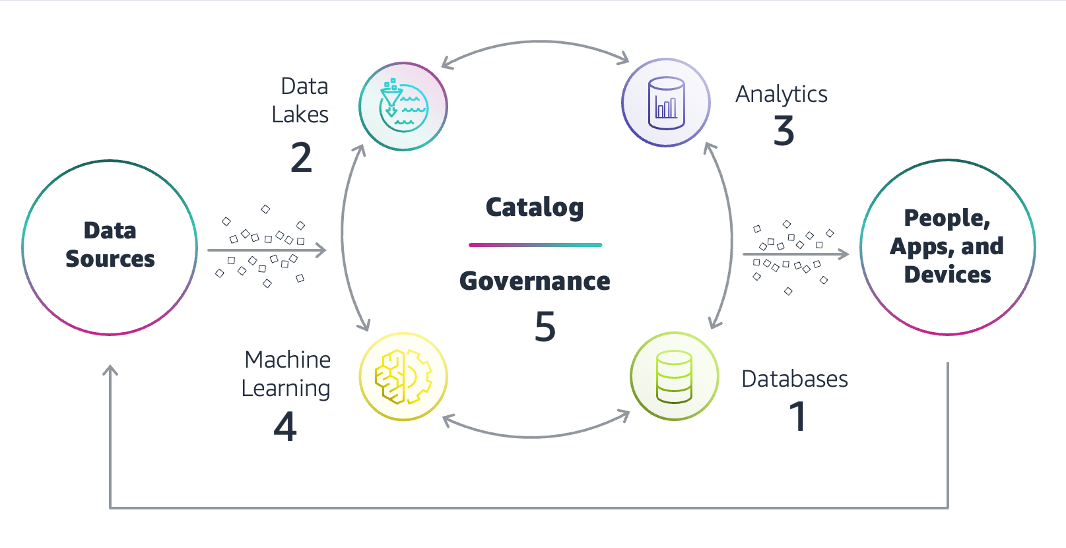
Nachfolgend sind die wichtigsten Komponenten der Datenarchitektur aufgeführt.
Datenquellen
Datenquellen können kundenorientierte Anwendungen, Überwachungs- und Telemetriesysteme, IoT-Geräte und intelligente Sensoren, Apps zur Unterstützung des Geschäftsbetriebs, interne Wissensspeicher, Datenarchive, Datenspeicher von Dritten und mehr sein. Sowohl strukturierte als auch unstrukturierte Daten gelangen mit unterschiedlichen Geschwindigkeiten, Mengen und Frequenzen in das Unternehmen.
Datenbanken
Speziell entwickelte Datenbanksysteme unterstützen moderne Anwendungen und ihre verschiedenen Features. Sie können relational oder nicht relational sein, wobei einige Daten als strukturierte Tabellen speichern und andere unstrukturierte Datentypen als Dokumente oder Schlüssel-Wert-Paare speichern. Datenbanken speichern in der Regel domainspezifische Daten, die sich auf einen engen Anwendungsfall beziehen. Die Daten können jedoch über das aktuelle System hinaus verwendet werden. Beispielsweise können Daten aus einer kundenorientierten App für Marketinganalytik oder -planung verwendet werden und müssen zur Verarbeitung aus der Datenbank entnommen werden. Ebenso müssen verarbeitete Daten von anderswo neu in die Datenbank einer Analytik- oder Machine-Learning-Anwendung (ML) geladen werden.
Data Lakes
Ein Data Lake ist ein zentrales Repository für die Speicherung von Rohdaten in großem Maßstab. Die Datenarchitektur beschreibt, wie Daten je nach Verwendungszweck von verschiedenen Datenbanken in den Data Lake und zurück in verschiedene Datenbanken übertragen werden. Der Data Lake speichert Daten in einem nativen oder offenen Format, sodass sie vor der Verwendung formatiert und bereinigt werden können. Er unterstützt die Datenintegration und baut Datensilos innerhalb eines Unternehmens auf.
Datenanalyse
Die Datenanalysekomponente umfasst traditionelle Data Warehouses, Batch-Reporting und Datenstreaming-Technologie für Warnmeldungen und Berichte in Echtzeit. Sie können für einmalige Abfragen und erweiterte Analytik-Anwendungsfälle verwendet werden. Analytik ist nicht durch Datensilos eingeschränkt, da die Datenarchitektur den Zugriff ermöglicht und allen mehr Freiheit bei der Nutzung der Datenbestände des Unternehmens bietet.
Künstliche Intelligenz
ML und KI sind entscheidend für eine moderne Datenstrategie, mit der Unternehmen zukünftige Szenarien vorhersagen und Informationen in Anwendungen integrieren können. Datenwissenschaftlerinnen bzw. -wissenschaftler verwenden Daten aus Lakes, um zu experimentieren, Anwendungsfälle im Bereich Intelligenz zu identifizieren und neue Modelle zu trainieren. Auch nach dem Training benötigen KI-Modelle ständigen Zugriff auf aktuelle Daten, um relevante und nützliche Ergebnisse zu generieren. Moderne Datenarchitekturen umfassen die gesamte Technologie und Infrastruktur, die das Training und die Inferenz von KI-Modellen unterstützt.
Daten-Governance
Data Governance bestimmt Rollen, Verantwortlichkeiten und Standards für die Datennutzung. Es beschreibt, wer mit welchen Daten, mit welchen Methoden und in welchen Situationen welche Maßnahmen ergreifen kann. Es umfasst sowohl Verwaltung von Datenqualität als auch Datensicherheit. Datenarchitektinnen und -architekten definieren Prozesse zur Prüfung und Nachverfolgung der Datennutzung, um die kontinuierliche Einhaltung gesetzlicher Vorschriften sicherzustellen.
Metadatenverwaltung ist ein integraler Bestandteil der Daten-Governance. Datenarchitektur umfasst Tools und Richtlinien zum Speichern und Teilen von Metadaten. Sie beschreibt Mechanismen zur Bereitstellung eines zentralen Metadatenspeichers, in dem unterschiedliche Systeme Metadaten speichern und erkennen und zur weiteren Abfrage und Verarbeitung von Datenbeständen verwenden können.
Wie wird Datenarchitektur implementiert?
Es ist eine bewährte Methode, Ihre moderne Datenarchitektur in Ebenen zu implementieren. Die Ebenen gruppieren Prozesse und Technologien auf der Grundlage unterschiedlicher Ziele. Die Implementierungsdetails sind flexibel, aber die Ebenen bestimmen die Technologieauswahl und die Art und Weise, wie sie integriert werden sollten.

Staging-Ebene
Die Staging-Ebene ist der Einstiegspunkt für Daten innerhalb der Architektur. Sie verarbeitet die Erfassung von Rohdaten aus verschiedenen Quellen, einschließlich strukturierter, halbstrukturierter und unstrukturierter Formate. Diese Ebene sollte so flexibel wie möglich sein.
Wenn das Schema (Datenformate und -typen) in dieser Ebene strikt durchgesetzt wird, sind nachgelagerte Anwendungsfälle begrenzt. Beispielsweise schließt die Durchsetzung aller Datumswerte im Format Monat, Jahr zukünftige Anwendungsfälle aus, die die Formatierung TT/MM/JJJJ erfordern. Gleichzeitig sollte es eine gewisse Konsistenz geben. Wenn beispielsweise Telefonnummern als Zeichenfolgen gespeichert und als solche verwendet werden, aber eine andere Datenquelle beginnt, dieselben Daten als numerische Daten zu generieren, führt dies dazu, dass Datenpipelines unterbrochen werden.
Um Flexibilität und Konsistenz in Einklang zu bringen, müssen Sie diese Ebene in zwei Unterschichten unterteilen.
Rohe Ebene
Die Rohebene speichert unveränderte Daten genau so, wie sie ankommen, wobei das ursprüngliche Format und die ursprüngliche Struktur ohne Transformationen beibehalten werden. Sie ist ein unternehmensweites Repository für Datenuntersuchung, -prüfung und -reproduzierbarkeit. Teams können Daten bei Bedarf in ihrem ursprünglichen Zustand erneut wiederaufgreifen und analysieren, um Transparenz und Rückverfolgbarkeit zu gewährleisten.
Standardisierte Schicht
Die standardisierte Ebene bereitet Rohdaten für den Verbrauch vor, indem sie Validierungen und Transformationen gemäß vordefinierter Standards anwendet. In dieser Ebene würden beispielsweise alle Telefonnummern in Zeichenfolgen, alle Zeitwerte in bestimmte Formate usw. konvertiert werden. Sie wird somit zur Schnittstelle für alle Benutzenden innerhalb des Unternehmens, um auf strukturierte, qualitätsgesicherte Daten zuzugreifen.
Die standardisierte Ebene der Datenarchitektur ist entscheidend für Self-Service-Business-Intelligence (BI), Routineanalytik und ML-Workflows. Sie setzt Schema-Standards durch und minimiert gleichzeitig Störungen, die durch Schemaänderungen verursacht werden.
Geformte Schicht
Die Datenintegration aus verschiedenen Quellen wird in der konformen Ebene abgeschlossen. Sie erstellt ein einheitliches Unternehmensdatenmodell für alle Domains. Beispielsweise können Kundendaten in verschiedenen Abteilungen unterschiedliche Details enthalten – Bestelldetails werden vom Vertrieb erfasst, die Finanzhistorie wird von der Buchhaltung erfasst und Interessen und Online-Aktivitäten werden vom Marketing erfasst. Die konforme Ebene sorgt für ein gemeinsames Verständnis solcher Daten im gesamten Unternehmen. Zu den Hauptvorteilen gehören:
-
Konsistente, einheitliche Definition der Hauptentitäten im gesamten Unternehmen.
-
Einhaltung der Datensicherheits- und Datenschutzbestimmungen.
-
Flexibilität, die unternehmensweite Einheitlichkeit mit domainspezifischer Anpassung durch zentralisierte und verteilte Muster in Einklang bringt.
Sie wird nicht direkt für operative Business Intelligence verwendet, unterstützt jedoch explorative Datenanalysen, Self-Service-BI und domainspezifische Datenanreicherung.
Angereicherte Ebene
Diese Ebene wandelt Daten aus der vorherigen Ebene in Datensätze um, die als Datenprodukte bezeichnet werden und auf bestimmte Anwendungsfälle zugeschnitten sind. Datenprodukte können von operativen Dashboards, die für die tägliche Entscheidungsfindung verwendet werden, bis hin zu detaillierten Kundenprofilen reichen, die mit personalisierten Empfehlungen oder Next-Best-Action-Erkenntnissen angereichert sind. Sie werden auf Grundlage ihres bestimmten Anwendungsfalls in verschiedenen Datenbanken oder Anwendungen gehostet.
Unternehmen katalogisieren die Datenprodukte in zentralisierten Datenverwaltungssystemen, damit sie für andere Teams auffindbar und zugänglich sind. Dies reduziert Redundanzen und stellt sicher, dass hochwertige, angereicherte Daten leicht zugänglich sind.
Welche Arten von Datenarchitektur gibt es?
Es gibt zwei verschiedene Ansätze für die konforme Ebene, die unterschiedliche Arten von Datenarchitektur erzeugen.
Zentralisierte Datenarchitektur
In zentralisierten Datenarchitekturen konzentriert sich die konforme Ebene auf die Erstellung und Verwaltung gemeinsamer Entitäten wie Kunden oder Produkte, die überall im Unternehmen verwendet werden. Die Entitäten sind mit einer begrenzten Anzahl generischer Attribute definiert, um die Datenverwaltung zu vereinfachen und eine breite Anwendbarkeit zu gewährleisten. Beispielsweise könnte eine Kundenentität Kernattribute wie Name, Alter, Beruf und Adresse enthalten.
Solche Datenarchitekturen unterstützen eine zentralisierte Daten-Governance, insbesondere für vertrauliche Informationen wie persönlich identifizierbare Informationen (PII) oder Zahlungskarteninformationen (PCI). Die zentralisierte Metadatenverwaltung stellt sicher, dass Daten effektiv katalogisiert und verwaltet werden, und sorgt mit Herkunftsnachverfolgung und Lebenszykluskontrollen für Transparenz und Sicherheit.
Dieses Modell vermeidet jedoch die Einbeziehung aller möglichen Attribute, da die zentrale Verwaltung komplexer Datenanforderungen die Entscheidungsfindung und Innovation verlangsamt. Stattdessen werden domainspezifische Eigenschaften, wie z. B. die Impressionen von Kundenkampagnen (nur für das Marketing erforderlich), in der angereicherten Ebene von den jeweiligen Geschäftsbereichen abgeleitet.
Data-Fabric-Technologien sind nützlich bei der Implementierung zentralisierter Datenarchitekturen.
Verteilte Datenarchitektur
Jede Domain erstellt und verwaltet ihre eigene konforme Ebene in verteilten Datenarchitekturen. Beispielsweise konzentriert sich das Marketing auf Attribute wie Kundensegmente, Kampagnenimpressionen und Konversionen, während die Buchhaltung Eigenschaften wie Bestellungen, Umsatz und Nettogewinn priorisiert.
Verteilte Datenarchitekturen ermöglichen Flexibilität bei der Definition von Entitäten und ihren Eigenschaften, führen jedoch zu mehreren Datensätzen für gemeinsame Entitäten. Auffindbarkeit und Governance dieser verteilten Datensätze werden durch einen zentralen Metadatenkatalog erreicht. Stakeholder können den entsprechenden Datensatz finden und verwenden und gleichzeitig die Datenaustauschprozesse überwachen.
Datamesh-Technologien sind nützlich bei der Implementierung verteilter Datenarchitekturen.
Was ist ein Datenarchitektur-Framework?
Ein Datenarchitektur-Framework ist ein strukturierter Ansatz zur Gestaltung einer Datenarchitektur. Es bietet eine Reihe von Prinzipien, Standards, Modellen und Tools, die effiziente Datenverwaltungsprozesse gewährleisten, die sich an den Geschäftszielen des Unternehmens orientieren. Sie können es sich als Standardvorlage vorstellen, die Datenarchitektinnen und -architekten verwenden, um qualitativ hochwertige und umfassende Datenarchitekturen zu erstellen.
Einige Beispiele für Datenarchitektur-Frameworks sind
Das DAMA-DMBOK-Framework
Das Data Management Body of Knowledge-Framework (DAMA-DMBOK) beschreibt bewährte Methoden, Prinzipien und Prozesse für eine effektives Datenverwaltung über den gesamten Lebenszyklus hinweg. Es unterstützt die Etablierung konsistenter Datenverwaltungsmethoden und gewährleistet gleichzeitig die Orientierung an Geschäftszielen. Durch die Behandlung von Datenbeständen als strategische Ressource bietet DAMA-DMBOK umsetzbare Leitlinien zur Verbesserung der Entscheidungsfindung und der betrieblichen Effizienz.
Das Zachman-Framework
Das Zachman-Framework ist ein Framework für die Unternehmensarchitektur, das ein Matrixformat verwendet, um die Verhältnisse verschiedener Perspektiven (z. B. Geschäftsinhabende, Designerinnen bzw. Designer und Entwicklung) und sechs Schlüsselfragen (Was, Wie, Wo, Wer, Wann und Warum) zu definieren. Unternehmen können visualisieren, wie Daten in ihren Gesamtbetrieb passen, und so sicherstellen, dass datenbezogene Prozesse sich an den Geschäftszielen und Systemanforderungen orientieren. Das Zachman-Framework ist weithin für seine Fähigkeit bekannt, unternehmensweite Daten- und Systemabhängigkeiten zu verdeutlichen.
TOGAF
Das Open Group Architecture Framework (TOGAF) behandelt die Datenarchitektur als eine wichtige Komponente eines umfassenden Systems und legt den Schwerpunkt auf die Erstellung von Datenmodellen, Datenflüssen und Governance-Strukturen, die die organisatorischen Anforderungen unterstützen. Es etabliert standardisierte Datenprozesse und gewährleistet so die Systeminteroperabilität und eine effiziente Datenverwaltung. Es ist besonders für große Unternehmen von Vorteil, die ihre IT- und Geschäftsstrategien über einen einheitlichen Ansatz aufeinander abstimmen möchten.
Wie verhält sich die Datenarchitektur im Vergleich zu anderen verwandten Begriffen?
Verschiedene Datenterminologien klingen ähnlich, haben aber völlig unterschiedliche Bedeutungen. Im Folgenden stellen wir einige Erklärungen zur Verfügung.
Datenarchitektur vs. Informationsarchitektur
Informationsarchitektur ist die Organisation und Präsentation von Informationen für Endbenutzende. Der Begriff bezieht sich auf Benutzeroberflächen, Websites oder Inhaltssysteme und hängt mit der Zugänglichkeit von Informationen für Endbenutzende zusammen. Prinzipien und Tools in der Informationsarchitektur konzentrieren sich auf Navigation, Kategorisierung und Durchsuchbarkeit – zum Beispiel innerhalb eines Online-Wissensspeichers oder einer Dokumentdatenbank.
Im Gegensatz dazu konzentriert sich die Datenarchitektur auf die Gestaltung und Verwaltung aller Unternehmensdaten. Sie befasst sich mit der gesamten technischen Dateninfrastruktur im Backend, während sich die Informationsarchitektur nur darauf konzentriert, wie Endbenutzende mit Informationen interagieren und diese interpretieren.
Datenarchitektur vs. Data Engineering
Data Engineering ist die praktische Umsetzung der Datenarchitektur. Datenarchitektinnen und -architekten stellen einen umfassenden Plan für die Verwaltung der Datenressourcen eines Unternehmens bereit. Sie entwerfen skalierbare Datensysteme, die sich an den Geschäftszielen und Sicherheitsrichtlinien orientieren. Data Engineers setzen den Plan um – sie erstellen, warten und optimieren Datenpipelines. Sie stellen sicher, dass Daten gemäß den Regeln der Datenarchitektur erfasst, bereinigt, transformiert und zur Analyse bereitgestellt werden.
Datenarchitektur vs. Datenmodellierung
Datenmodellierung ist ein Prozess innerhalb der Datenarchitektur, der eine visuelle Darstellung jeder Datensammlung erstellt. Dazu gehört die Erstellung konzeptioneller, logischer und physischer Datenmodelle, die die Daten in der Sammlung skizzieren. Ein logisches Datenmodell stellt Datenbeschränkungen, Entitätsnamen und Beziehungen für die plattformunabhängige Implementierung diagrammatisch dar. Ein physisches Datenmodell verfeinert das logische Datenmodell für die Implementierung über eine bestimmte Datentechnologie weiter.
Die Datenarchitektur hat einen viel größeren Geltungsbereich, der über die Datenmodellierung hinausgeht. Neben Datenattributen und Beziehungen definiert sie auch eine umfassende Strategie für die unternehmensweite Datenverwaltung. Sie umfasst Infrastruktur, Richtlinien und Technologien für die Datenintegration, die sich an den Unternehmenszielen orientieren.
Wie kann AWS Ihre Anforderungen an die Datenarchitektur unterstützen?
AWS bietet umfassende Analysedienste für jede Ebene Ihrer Datenarchitektur — von der Speicherung und Verwaltung bis hin zu Data Governance und KI. AWS bietet speziell entwickelte Services mit optimalem Preis-Leistungs-Verhältnis, bester Skalierbarkeit und niedrigsten Kosten. Lassen Sie uns annehmen,
- Datenbanken auf AWS umfassen über 15 speziell entwickelte Datenbankservices zur Unterstützung verschiedener relationaler und nichtrelationaler Datenmodelle.
- Data Lakes auf AWS umfassen Services, die unbegrenzten Rohdatenspeicher bereitstellen und sichere Data Lakes innerhalb von Tagen statt Monaten erstellen.
- Die Datenintegration mit AWS umfasst Services, die Daten aus mehreren Quellen zusammenführen, sodass Sie Daten in Ihrem gesamten Unternehmen transformieren, operationalisieren und verwalten können.
AWS Well-Architected unterstützt Cloud-Datenarchitekten beim Aufbau einer sicheren, leistungsstarken, belastbaren und effizienten Infrastruktur. Das AWS-Architekturzentrum umfasst Richtlinien basierend auf Anwendungsfällen für die Implementierung verschiedener moderner Datenarchitekturen in Ihrem Unternehmen.
Beginnen Sie mit der Datenarchitektur auf AWS, indem Sie noch heute ein kostenloses Konto erstellen.
Nächste Schritte mit AWS
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages