Blog de Amazon Web Services (AWS)
Nueva funcionalidad en AWS DataSync: Mueva datos entre AWS y otras ubicaciones públicas
Preparación del agente DataSync
Mediante la consola EC2, inicio una instancia de EC2 con el ID del AMI especificado en la propiedad Value (valor) del parámetro. Para la configuración de red, utilizo una subred pública y la opción de asignar automáticamente una dirección IP pública. La instancia EC2 necesita acceso a las redes tanto del origen como del destino de una tarea de transferencia de datos. Otro requisito para la instancia es poder recibir tráfico HTTP de DataSync para activar el agente.
Al utilizar AWS DataSync en una nube privada virtual (VPC) basada en el servicio Amazon VPC, es una buena práctica utilizar VPC endpoints para conectar el agente con el servicio DataSync. En la consola de VPC, selecciono Endpoints en el panel de navegación y, a continuación, Create endpoint (crear endpoint). Introduzco un nombre para el endpoint y selecciono la categoría AWS services (servicios de AWS).
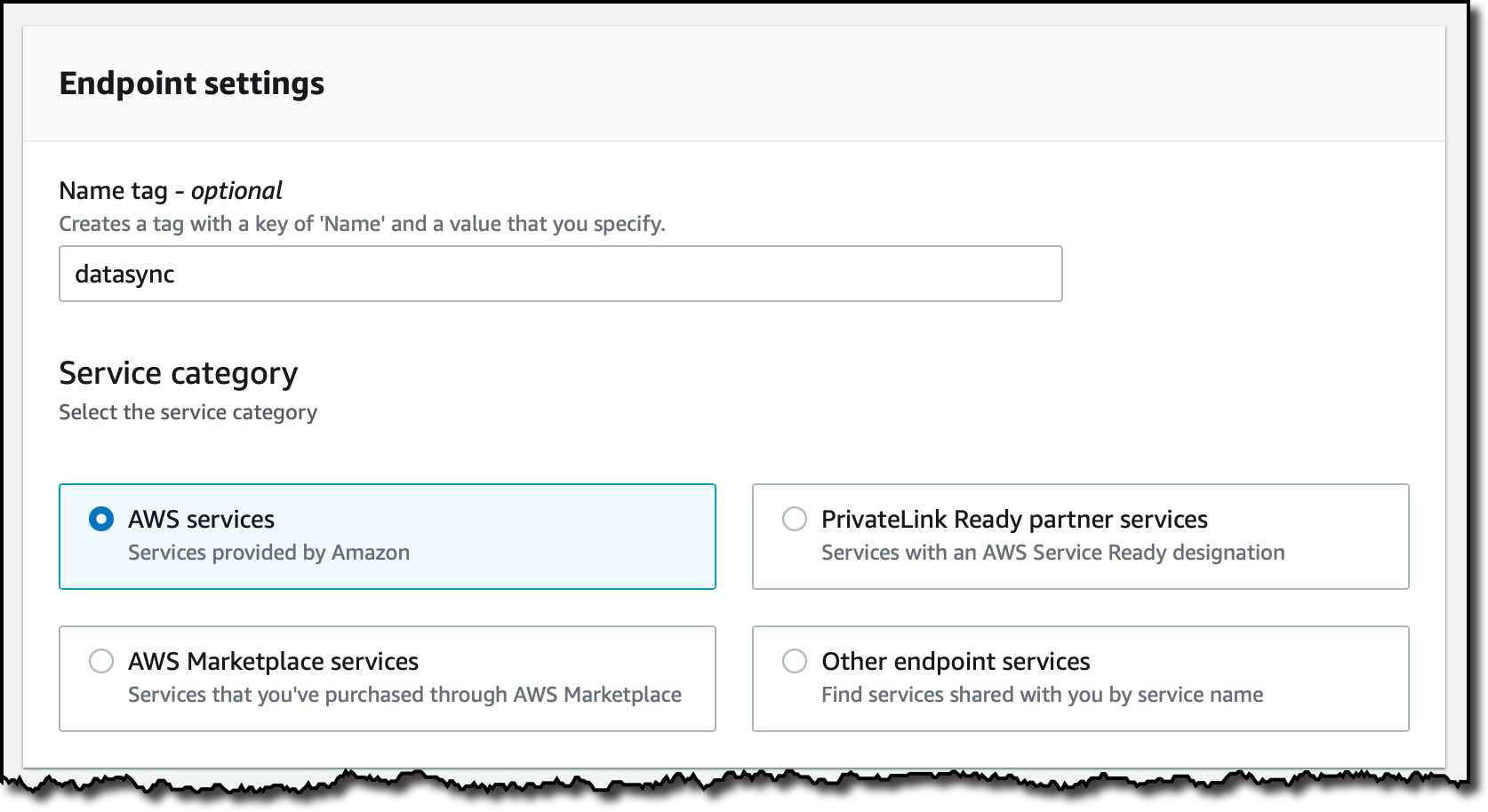
En la sección Services (servicios), busco DataSync.

A continuación, selecciono la misma VPC en la que inicié la instancia de EC2.

Para reducir el tráfico entre zonas de disponibilidad (cross-AZ), elijo la misma subred utilizada para la instancia EC2.

El agente DataSync que se ejecuta en la instancia EC2 necesita acceso de red al VPC endpoint. Para simplificar, utilizo el grupo de seguridad predeterminado (default) de la VPC para ambos. Creo el VPC endpoint y, después de unos minutos, está listo para usarse.

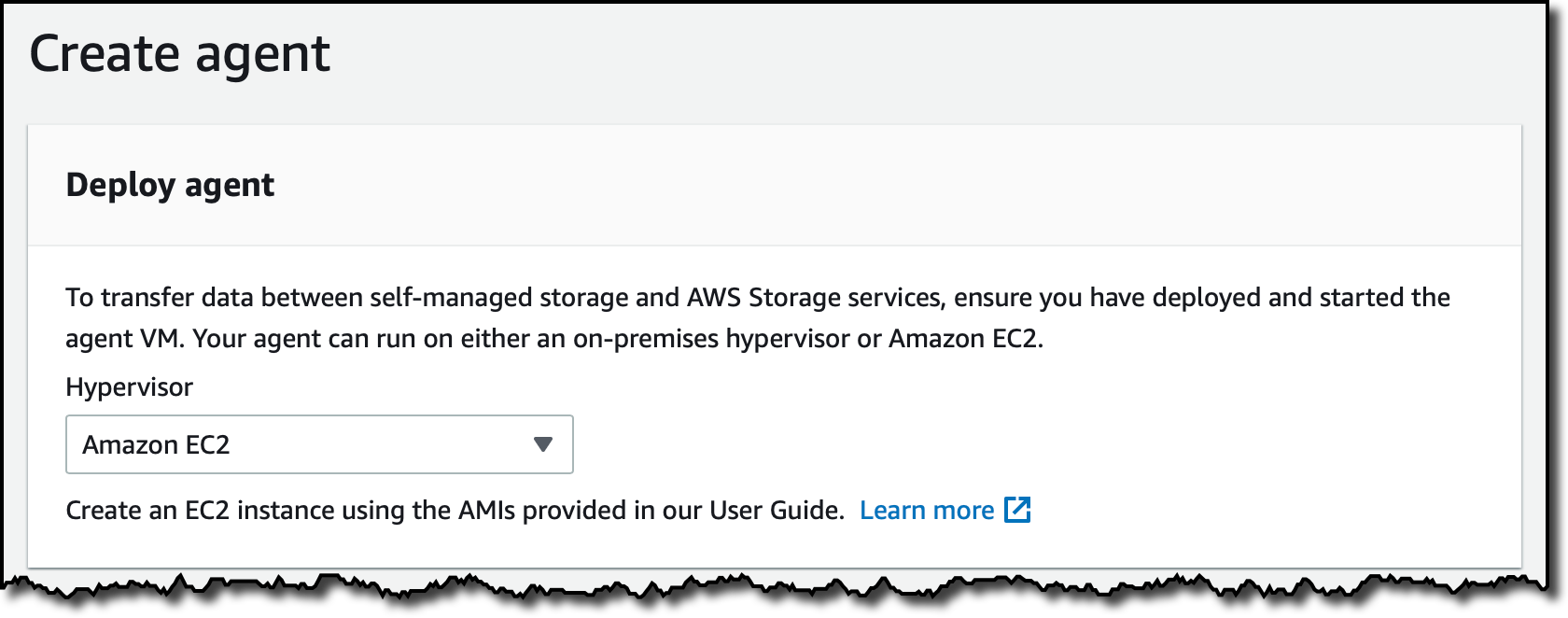
En la consola de AWS DataSync, selecciono Agents (agentes) en el panel de navegación y, a continuación, Create agent (crear agente). Selecciono Amazon EC2 para el Hypervisor.
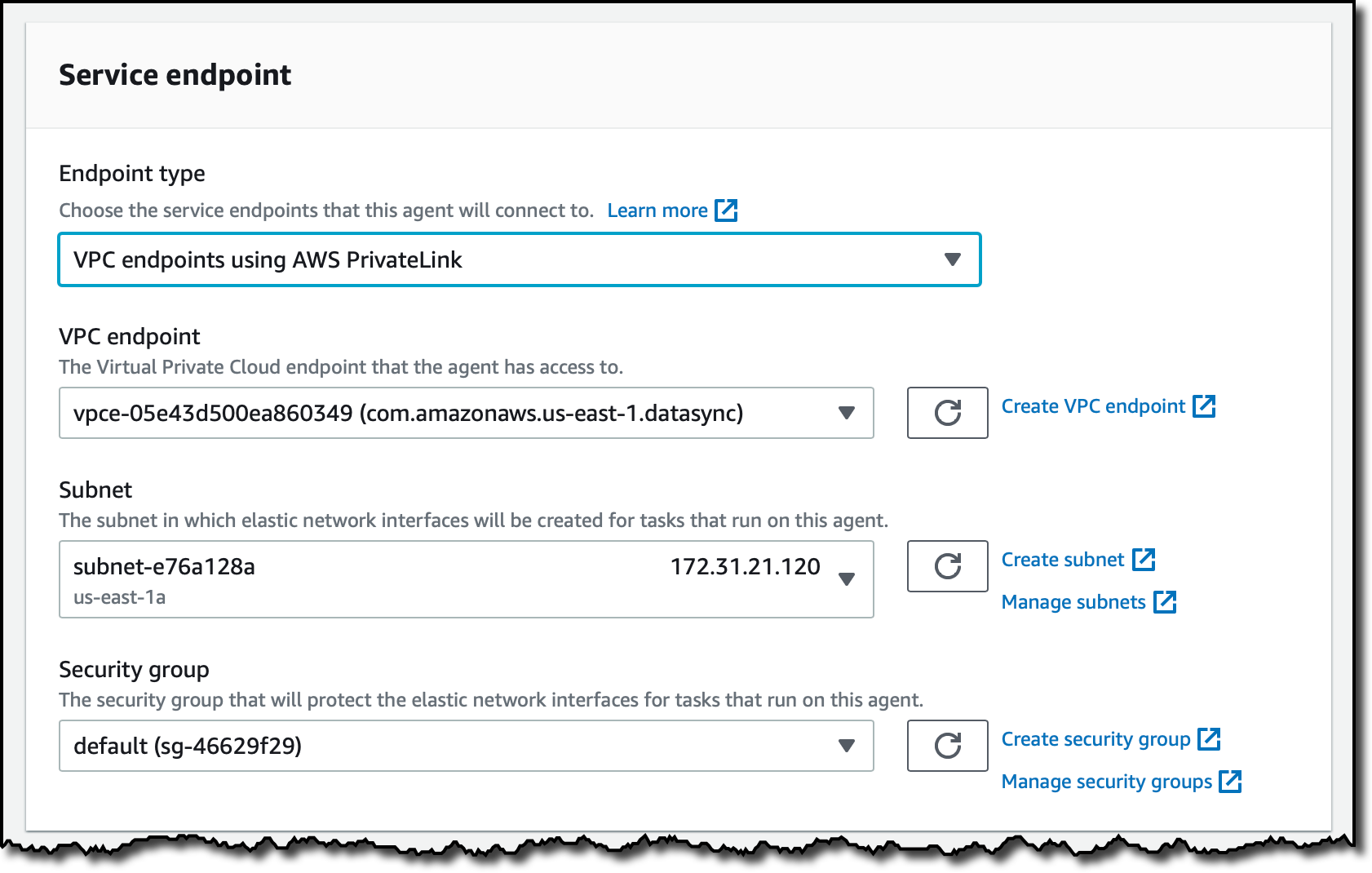
Elijo VPC endpoints using AWS PrivateLink (VPC endpoints utilizando AWS PrivateLink) para el Endpoint type (tipo de endpoint). Selecciono el VPC endpoint que creé anteriormente, y la misma Subnet (subred) y el mismo Security group (grupo de seguridad) que usé para el VPC endpoint.
Elijo la opción de Automatically get the activation key (obtener automáticamente la clave de activación) y escribo la IP pública de la instancia EC2. A continuación, elijo Get key (Obtener clave).
 Una vez activado el agente DataSync, ya no necesito el acceso HTTP y lo elimino de los grupos de seguridad de la instancia de EC2. Ahora que el agente DataSync está activo, puedo configurar tareas y ubicaciones para mover mis datos.
Una vez activado el agente DataSync, ya no necesito el acceso HTTP y lo elimino de los grupos de seguridad de la instancia de EC2. Ahora que el agente DataSync está activo, puedo configurar tareas y ubicaciones para mover mis datos.
Transferencia de datos de Google Cloud Storage a Amazon S3
Tengo algunas imágenes en un depósito de Google Cloud Storage y quiero sincronizar esos archivos con un depósito de S3. En la consola de Google Cloud, abro la configuración del bucket. Allí creo una cuenta de servicio con permisos de Storage Object Viewer y tomo nota de las credenciales (access key y secret) para acceder al bucket mediante programación.
De vuelta en la consola de AWS DataSync, selecciono Tasks (tareas) y, a continuación, Create task (crear tarea).
Para configurar el origen de la tarea, creo una ubicación. Selecciono Object storage (almacenamiento de objetos) para el Location type (tipo de ubicación) y elijo el agente que acabo de crear. Para el Server (servidor), utilizo storage.googleapis.com. A continuación, introduzco el nombre del bucket de Google Cloud y la carpeta donde están almacenadas mis imágenes.

Para la sección de Authentication (autenticación), introduzco el access key (clave de acceso) y el secret (secreto) que anoté cuando creé la cuenta de servicio. Elijo Next (siguiente).

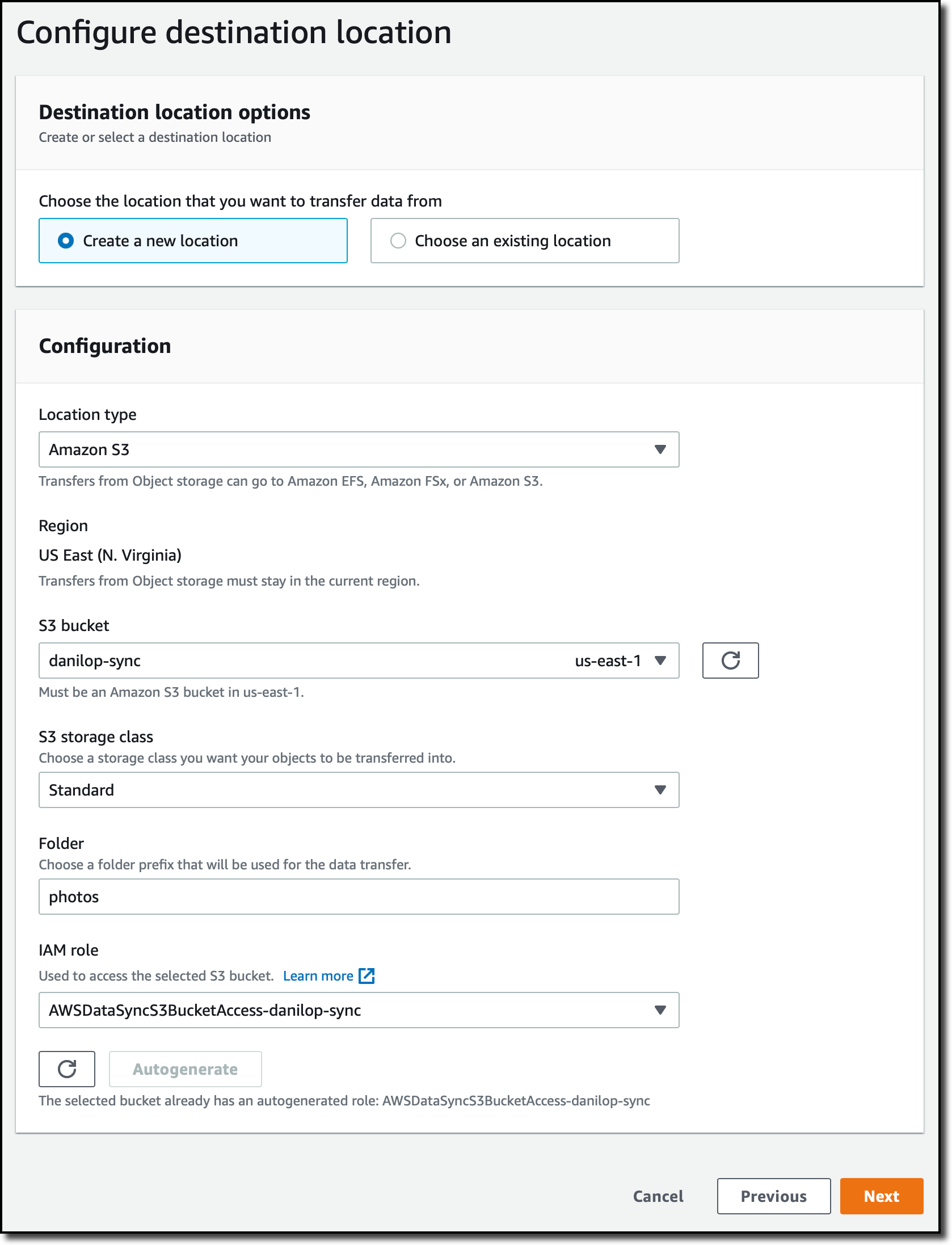
Para configurar el destino de la tarea, creo otra ubicación. Esta vez, selecciono Amazon S3 como Location Type (tipo de ubicación). Elijo el bucket S3 de destino e introduzco una carpeta que se usará como prefijo para los archivos transferidos al bucket. Utilizo el botón Autogenerate (generar automáticamente) para crear el rol de IAM que otorgará permisos a DataSync para acceder al bucket de S3.
En el siguiente paso, configuro los ajustes de la tarea. Introduzco un nombre para la tarea. De manera opcional, puedo ajustar la forma en que DataSync verifica la integridad de los datos transferidos o asigna un ancho de banda para la tarea.
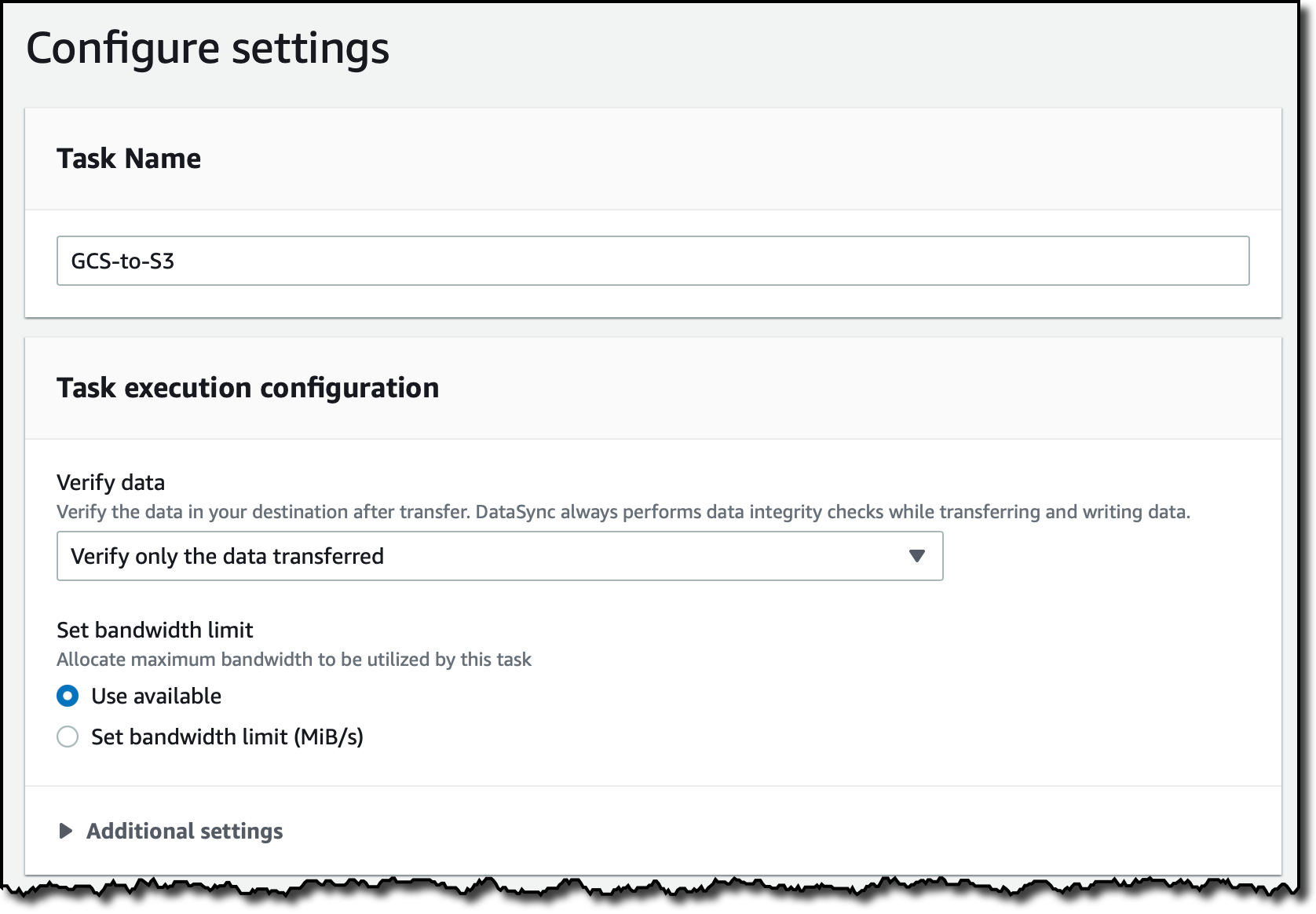
También puedo elegir qué datos escanear y qué transferir. De forma predeterminada, se escanean todos los datos de origen y solo se transfieren los datos que han cambiado. En la sección de Additional settings (configuración adicional), desactivo la opción Copy object tag (copiar etiquetas de objetos) porque actualmente Google Cloud Storage no admite etiquetas.

Puedo seleccionar la programación utilizada para ejecutar esta tarea. De momento, lo dejo en Not scheduled (sin programar), y lo iniciaré manualmente.
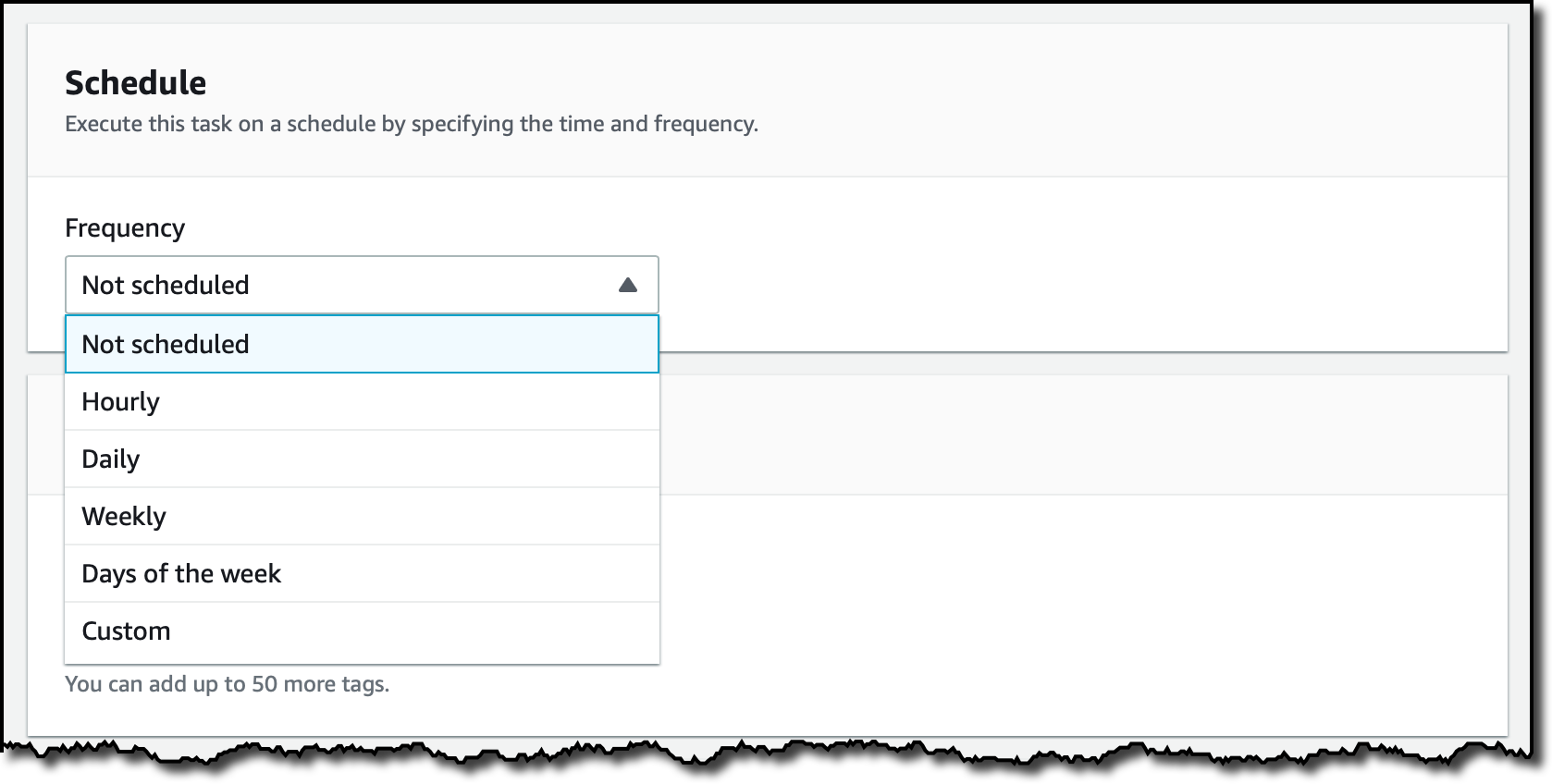
Para el registro, o logs, utilizo el botón Autogenerate (generar automáticamente) para crear un log group (grupo de registro) para DataSync. Elijo Next (siguiente).

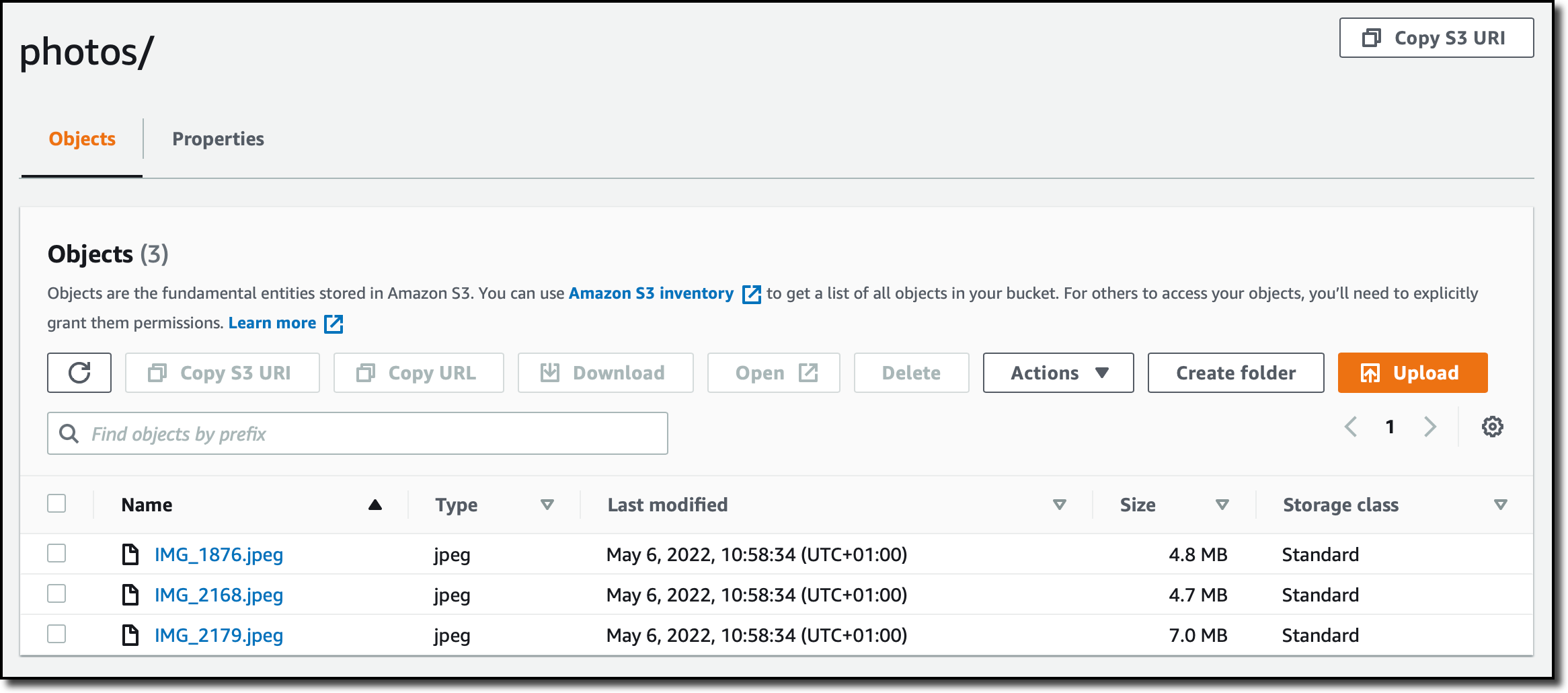
Reviso las configuraciones y creo la tarea. Ahora empiezo la tarea de transferencia de datos desde la consola. Después de unos minutos, los archivos se sincronizan con mi bucket de S3 y puedo acceder a ellos desde la consola de S3.
Mover datos de Azure Files a Amazon FSx para Windows File Server
Tomo muchas fotografías y también tengo algunas imágenes en un archivo compartido de Azure. Quiero sincronizar esos archivos con un sistema de archivos Amazon FSx para Windows. En la consola de Azure, selecciono el recurso compartido de archivos y pulso el botón Connect (conectar) para generar un script de PowerShell que compruebe si se puede acceder a esta cuenta de almacenamiento a través de la red.
De este script, obtengo la información que necesito para configurar la ubicación de DataSync:
- SMB Server (servidor SMB)
- Share Name (nombre del recurso compartido)
- User (usuario)
- Password (contraseña)
De vuelta en la consola de AWS DataSync, selecciono Tasks (tareas) y, a continuación, Create task (crear tarea).
Para configurar el origen de la tarea, creo una ubicación. Selecciono Server Message Block (SMB) para el Location Type (tipo de ubicación) y el agente que he creado anteriormente. A continuación, utilizo la información que encontré en el script para introducir la dirección del SMB Server (servidor SMB), el Share name (nombre del recurso compartido) y el User/Password (usuario/contraseña) que utilizaré para la autenticación.
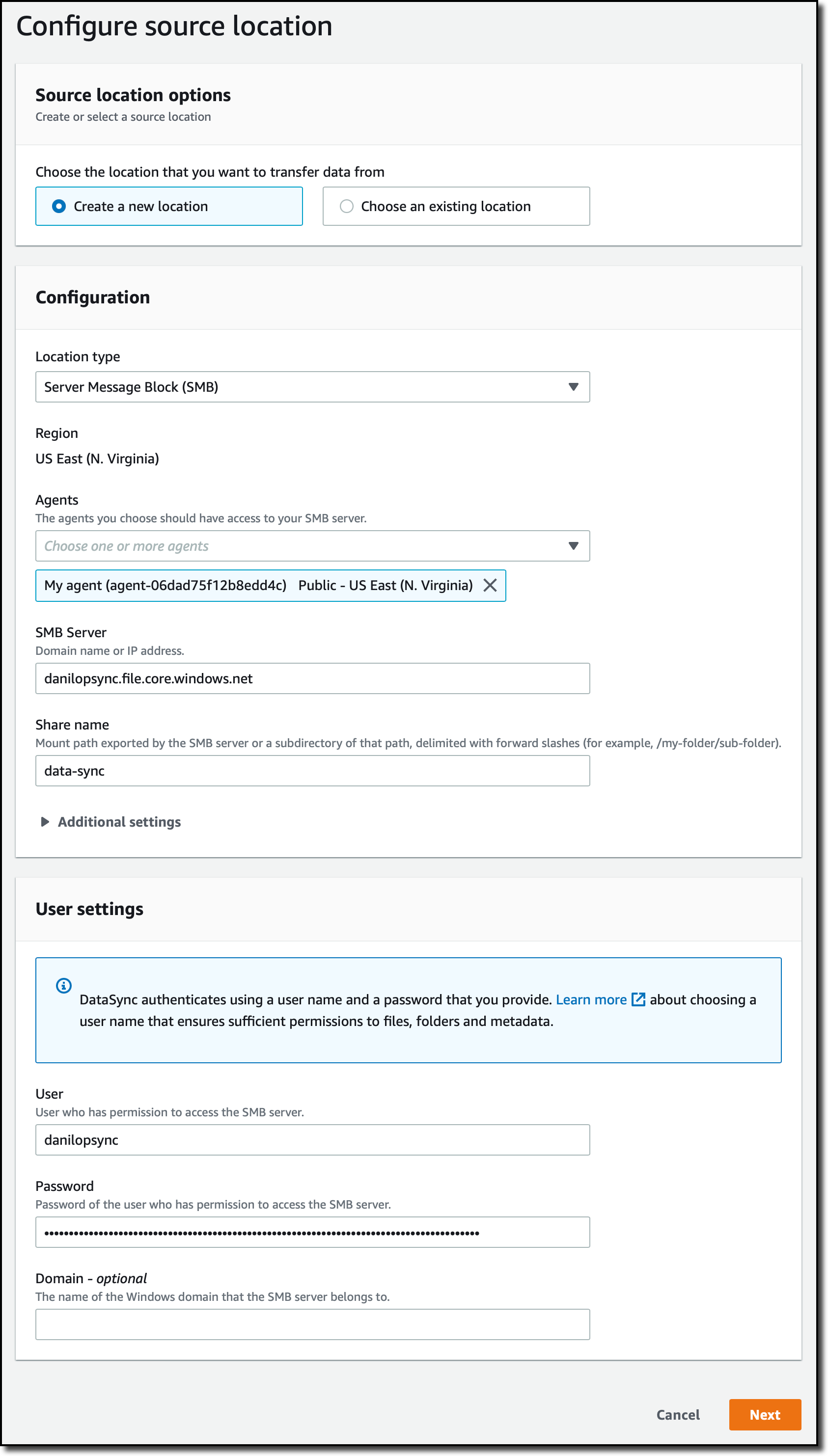
Para configurar el destino de la tarea, vuelvo a crear una ubicación. Esta vez, elijo Amazon FSx para el Location type (tipo de ubicación). Selecciono un sistema de archivos FSx para Windows que he creado anteriormente y utilizo el nombre de recurso compartido predeterminado. Utilizo el grupo de seguridad predeterminado para conectarme al sistema de archivos. Como utilizo AWS Directory Service para Microsoft Active Directory con FSx para Windows File Server, utilizo las credenciales de un usuario miembro de los grupos de AWS Delegated FSx Administrators y Domain Admins. Para obtener más información, consulte Creando una ubicación para FSx para Windows File Server en la documentación.

En el siguiente paso, introduzco un nombre para la tarea y dejo todas las demás opciones con sus valores predeterminados de la misma manera que hice para la tarea anterior.
Reviso las configuraciones y creo la tarea. Ahora empiezo la tarea de transferencia de datos desde la consola. Después de unos minutos, los archivos se sincronizan con mi recurso compartido del sistema de archivos FSx para Windows. Monto el sistema de archivos compartido con una instancia EC2 de Windows y veo que mis imágenes están allí.

Al crear una tarea, puedo reutilizar las ubicaciones existentes. Por ejemplo, si quiero sincronizar archivos de Azure Files con mi bucket de S3, puedo seleccionar rápidamente las dos ubicaciones correspondientes que he creado para esta publicación.
Disponibilidad y precios
Puede mover sus datos mediante la consola de AWS DataSync, la interfaz de línea de comandos (CLI) de AWS o los SDK de AWS para crear tareas que muevan datos entre el almacenamiento de AWS y los buckets de Google Cloud Storage o los sistemas de archivos de Azure Files. Mientras se ejecutan las tareas, puede monitorear el progreso desde la consola de DataSync o mediante CloudWatch.
No hay cambios en los precios de DataSync con estas nuevas capacidades. La transferencia de datos hacia y desde Google Cloud o Microsoft Azure mantienen la misma tarifa que todas las demás fuentes de datos compatibles con DataSync en la actualidad.
Es posible que Google Cloud o Microsoft Azure apliquen cargos por transferencia de datos. Dado que DataSync comprime los datos al copiarlos entre el agente y AWS, es posible que pueda reducir las tarifas de salida implementando el agente DataSync en un entorno de Google Cloud o Microsoft Azure.
Cuando utilice DataSync para transferir datos de AWS a Google Cloud o Microsoft Azure, se le cobrará por la transferencia de datos de EC2 a Internet. Consulte los precios de Amazon EC2 para obtener más información.
Automatice y acelere la forma en que mueve los datos con AWS DataSync.
— Danilo
Este artículo fue traducido del Blog de AWS en Inglés
Acerca del autor
 Danilo Poccia trabaja con empresas emergentes y de cualquier tamaño para apoyar su innovación. Como Chief Evangelist (EMEA) en Amazon Web Services, aprovecha su experiencia para ayudar a las personas a hacer realidad sus ideas, centrándose en las arquitecturas sin servidor y la programación basada en eventos, así como en el impacto técnico y empresarial del machine learning y el edge computing. Es el autor de AWS Lambda in Action de Manning.
Danilo Poccia trabaja con empresas emergentes y de cualquier tamaño para apoyar su innovación. Como Chief Evangelist (EMEA) en Amazon Web Services, aprovecha su experiencia para ayudar a las personas a hacer realidad sus ideas, centrándose en las arquitecturas sin servidor y la programación basada en eventos, así como en el impacto técnico y empresarial del machine learning y el edge computing. Es el autor de AWS Lambda in Action de Manning.
Traductor
 Marcelo Ahuerma ha participado en diversos proyectos de migración hacia la nube de AWS, en sus roles como líder en áreas de tecnología y Seguridad Informática durante su trayectoria laboral en México. Actualmente es un arquitecto de soluciones en el sector público de Amazon Web Services, donde principalmente apoya y guía a clientes del sector de tecnologías para la educación (EdTech) en Estados Unidos, para optimizar sus cargas de trabajo aprovechando los servicios de AWS.
Marcelo Ahuerma ha participado en diversos proyectos de migración hacia la nube de AWS, en sus roles como líder en áreas de tecnología y Seguridad Informática durante su trayectoria laboral en México. Actualmente es un arquitecto de soluciones en el sector público de Amazon Web Services, donde principalmente apoya y guía a clientes del sector de tecnologías para la educación (EdTech) en Estados Unidos, para optimizar sus cargas de trabajo aprovechando los servicios de AWS.