Créer des tableaux de bord pour une visibilité opérationnelle
Distribution de logiciel et opérations de logiciels | NIVEAU 300
Introduction
Chacun de nous utilise des applications sur son ordinateur portable, sa tablette et son smartphone. Il ne nous est guère difficile de voir si l'appareil est sous tension et si la connexion au réseau Wi-Fi est active. Nous savons que toutes les notifications critiques dont les avertissements de faible espace libre sur le disque, seront affichées à l'écran. Pour tout dire, la vitesse et la réactivité générales de l'interface utilisateur (IU) peuvent indiquer si l'appareil dispose de suffisamment de ressources, comme la mémoire ou le CPU, pour faire fonctionner nos applications.
Quiconque a déjà eu à fournir une assistance technique à distance pour les appareils a déjà fait face à la difficulté de détecter et de diagnostiquer les problèmes lorsque l'on ne peut pas voir et interagir directement avec l'appareil. C'est précisément ce même type de défi qui se pose à nous lorsqu'il s'agit de gérer des services basés sur le cloud : comment contrôler ces services à distance et comment savoir si nos clients sont satisfaits ?
Pour observer un service à hôte unique, nous pouvons nous connecter à cet hôte, exécuter divers outils de surveillance de l'exécution et inspecter les journaux en vue de déterminer la cause racine de ce qui se passe sur l'hôte. Toutefois, les solutions à hôte unique ne sont viables que pour les services les plus simples et non critiques. On retrouve, à l'autre extrême, les microservices distribués à plusieurs niveaux qui fonctionnent sur des centaines ou des milliers de serveurs, de conteneurs ou d'environnements sans serveur.
Comment Amazon arrive-t-il à surveiller le comportement réel de tous les services cloud qui fonctionnent dans plusieurs zones de disponibilité dans de nombreuses régions du monde ? La surveillance automatisée, les processus d'assainissement automatisés (par exemple, le déplacement du trafic) et les systèmes de déploiement automatisés sont essentiels pour détecter et résoudre la grande majorité des problèmes à cette échelle. Pour de nombreuses raisons, nous devons cependant être en mesure de voir, à tout moment, ce que font ces services, ces flux de travail et ces déploiements.
Dashboarding chez Amazon
Les tableaux de bord nous servent de mécanisme pour relever le défi de la maîtrise de l'activité dans nos services cloud. Les tableaux de bord sont les vues côté humain de nos systèmes. Ils fournissent des résumés concis du comportement du système en affichant des métriques de séries chronologiques, des journaux, des traces et des données d'alarme.
Chez Amazon, nous utilisons le terme « dashboarding » pour désigner le processus de création, d'utilisation et de maintenance permanente de ces tableaux de bord. Le dashboarding est devenu une activité de premier ordre, car il est aussi essentiel au succès de nos services que d'autres activités quotidiennes de diffusion et d'exploitation de logiciels, à savoir la conception, le codage, la création, le test, le déploiement et le développement de nos services.
Nous n'attendons pas de nos opérateurs qu'ils surveillent les tableaux de bord en permanence, bien entendu. Ces tableaux passent généralement inaperçus. En fait, nous nous sommes aperçus que tout processus opérationnel nécessitant une consultation manuelle des tableaux de bord échoue en raison d'une erreur humaine, quelle que soit la fréquence de consultation des tableaux de bord. Pour parer à ce risque, nous avons créé des alarmes automatisées qui évaluent en permanence les données de surveillance les plus importantes provenant de nos systèmes. En règle générale, il s'agit de métriques qui avertissent de l'imminence d'une limite (détection proactive, avant l'impact) ou du fait que le système est déjà fragilisé de manière inattendue (détection réactive, après l'impact).
Ces alarmes peuvent exécuter des processus de correction automatisés et informer nos opérateurs qu'il y a un problème. La notification oriente l'opérateur vers les tableaux de bord et les runbooks précis à utiliser. Lorsque je suis d'astreinte et qu'une notification d'alarme me signale un problème, je peux rapidement utiliser des tableaux de bord connexes pour quantifier l'impact sur le client, valider ou trier la cause racine, atténuer et réduire le délai de reprise. L'alarme peut avoir déjà déclenché un processus automatique de correction. Même dans ce cas, j'ai besoin de voir ce que fait le processus automatique, son effet sur le système et, dans des circonstances exceptionnelles, faire avancer le processus en fournissant une confirmation humaine des étapes critiques pour des raisons de sécurité.
Amazon fait généralement appel à plusieurs opérateurs d'astreinte pour gérer un événement en cours. Il est possible que les opérateurs utilisent des tableaux de bord différents au fur et à mesure qu'ils accomplissent une série de tâches. Il peut s'agir de quantifier l'impact sur les clients, de trier, de remonter à la cause racine de l'événement à travers plusieurs services, d'observer les processus de correction automatisés, et d'exécuter et de valider les mesures d'atténuation basées sur le runbook. Parallèlement, les équipes de pairs et les parties prenantes au sein des entreprises utilisent également des tableaux de bord pour suivre l'impact en cours pendant l'événement. Ces différents participants communiquent en utilisant des outils de gestion des incidents, des salons de discussion (avec des bots comme AWS Chatbot), et des conférences téléphoniques. Chaque partie prenante apporte un point de vue différent sur les données qu'elle voit dans les tableaux de bord.
Les équipes d'Amazon et de grandes organisations tiennent également des réunions hebdomadaires d'évaluation des opérations, auxquelles participent des dirigeants, des gestionnaires et de nombreux ingénieurs. Au cours de ces réunions, nous utilisons une roue de la chance pour choisir des tableaux de bord d'audit de haut niveau. Les parties prenantes passent en revue l'expérience de nos clients et les principaux objectifs de niveau de service, notamment la disponibilité et la latence. Les tableaux de bord d'audit de ces parties prenantes montrent généralement les données opérationnelles de toutes les zones de disponibilité et régions.
Lors de la planification et de la prévision des capacités à long terme, Amazon recourt en outre à des tableaux de bord qui donnent un aperçu des métriques de haut niveau en matière d'activité, d'utilisation et de capacité que notre système génère sur des intervalles de temps plus longs.
Types de tableaux de bord
Les tableaux de bord sont utilisés pour contrôler manuellement les services. Cependant, il n'existe pas de modèle universel pour tous les cas d'utilisation. Nous utilisons, pour la plupart des systèmes, de nombreux tableaux de bord dont chacun offre une vue différente du système. Grâce à ces différentes vues, différents utilisateurs peuvent comprendre comment nos systèmes se comportent sous différents angles et à différents intervalles de temps.
Les données que chaque public souhaite consulter peuvent varier considérablement d'un tableau de bord à l'autre. Nous avons appris à nous concentrer sur le public visé lorsque nous concevons des tableaux de bord. Le choix des données à introduire dans chaque tableau de bord est fonction des personnes qui utiliseront l'utiliseront et des raisons pour lesquelles elles le feront. Vous avez probablement entendu dire que chez Amazon, nous travaillons à rebours du client. La création de tableaux de bord en est une parfaite illustration. Nous créons des tableaux de bord en fonction des besoins des utilisateurs attendus et de leurs exigences spécifiques.
Le diagramme suivant illustre comment différents tableaux de bord fournissent différentes vues sur le système dans son ensemble :
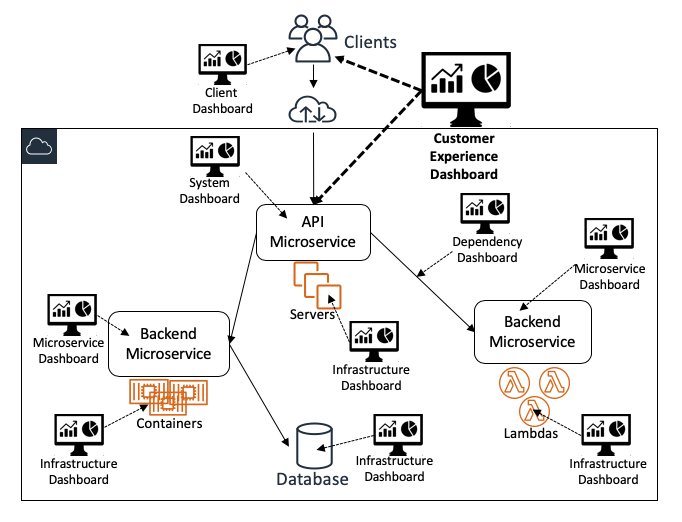
Tableaux de bord de haut niveau
Tableaux de bord de l'expérience client
Chez Amazon, nos tableaux de bord les plus importants et les plus utilisés sont les tableaux de bord pour l'expérience client. Il s'agit de tableaux de bord conçus pour être utilisés par un large groupe d'utilisateurs, dont les opérateurs de services et de nombreuses autres parties prenantes. Ils présentent efficacement des métriques sur la santé globale du service et le respect des objectifs. Ils affichent les données de surveillance provenant du service lui-même et également des instruments du client, des testeurs en continu (tels que les canaris synthétiques Amazon CloudWatch) et des systèmes de remédiation automatisés. Ces tableaux de bord contiennent également des données qui aident les utilisateurs à répondre aux questions sur la profondeur et l'ampleur de l'impact. Certaines de ces questions seront probablement « Combien de clients sont touchés » et « Quels clients sont les plus touchés ? »
Tableaux de bord de niveau système
Les points d'entrée de nos services en ligne sont généralement des points de terminaison d'interface utilisateur et d'API. Les tableaux de bord dédiés au niveau du système doivent donc contenir suffisamment de données pour que les opérateurs puissent voir comment se comportent le système et ses points de terminaison orientés client. Ces tableaux de bord affichent principalement les données de surveillance au niveau de l'interface. Ces tableaux de bord affichent trois catégories de données de surveillance pour chaque API :
- Données de surveillance des entrées. Il peut s'agir du nombre de demandes reçues ou de travaux interrogés dans les files d'attente/flux, des percentiles de la taille en octets de la demande et du nombre d'échecs d'authentification/autorisation.
- Données de surveillance du traitement. Il peut s'agir du chemin logique métier multimodal/nombres d'exécutions au niveau de la branche, des nombres de demandes de microservices au niveau du backend/défaillance/percentiles de latence, de sorties de journaux de défaillances et d'erreurs, et de données de trace de demande.
- Données de surveillance des sorties. Il peut s'agir du nombre de types de réponses (avec des ventilations pour les réponses aux erreurs/défaillance par client), la taille des réponses et des percentiles pour l'octet du temps d'écriture de la première réponse et le temps d'écriture de la réponse complète.
En règle générale, nous cherchons à maintenir ces tableaux de bord au niveau le plus élevé possible, tant au niveau de l'expérience client qu'au niveau du système. Nous évitons délibérément la tentation d'ajouter trop de métriques à ces tableaux de bord. En effet, une surcharge d'informations peut détourner l'attention du message essentiel que ces tableaux de bord doivent transmettre.
Tableaux de bord des instances de service
Nous créons des tableaux de bord pour faciliter une évaluation rapide et complète de l'expérience du client au sein d'une seule instance de service (partition ou cellule). Avec cette vision restrictive, les opérateurs qui travaillent sur une seule instance de service ne sont pas surchargés de données non pertinentes provenant d'autres instances de service.
Tableaux de bord pour audit des services
Nous créons également des tableaux pour l'expérience client qui affichent intentionnellement des données pour toutes les instances d'un service, dans toutes les zones de disponibilité et les régions. Les opérateurs utilisent ces tableaux de bord d'audit de service pour vérifier les alarmes automatisées dans toutes les instances de service. Ces alarmes peuvent également être passées en revue lors des réunions opérationnelles hebdomadaires mentionnées plus haut.
Tableaux de bord de planification et de prévision des capacités
Pour les cas d'utilisation à plus long terme, nous créons aussi des tableaux de bord pour la planification et la prévision des capacités pour mieux apprécier la croissance de nos services.
Tableaux de bord de bas niveau
Les API d'Amazon sont généralement mises en œuvre en orchestrant les requêtes à travers les microservices de backend. Ces microservices peuvent appartenir à différentes équipes, chacune étant responsable d'un aspect spécifique du traitement de la demande. À titre d'exemple, certains microservices sont dédiés à l'authentification et à l'autorisation des demandes, à l'application des restrictions/limites, au comptage de l'utilisation, à la création/mise à jour/suppression des ressources, à la récupération des ressources dans les banques de données et au lancement de flux de travail asynchrones. Habituellement, les équipes créent au moins un tableau de bord spécifique au microservice qui indique les métriques pour chaque API ou unité de travail si le service traite les données de manière asynchrone.
Tableaux de bord spécifiques aux microservices
Les tableaux de bord des microservices présentent normalement des données de suivi spécifiques à la mise en œuvre. Une connaissance approfondie du service est donc nécessaire. Ces tableaux de bord sont surtout utilisés par les équipes propriétaires des services. Néanmoins, nos services étant fortement instrumentés, nous devons présenter les données de ces instruments de manière à ne pas surcharger les opérateurs. Voilà pourquoi ces tableaux de bord affichent généralement certaines données sous forme agrégée. Les opérateurs qui identifient des anomalies dans les données agrégées utilisent généralement divers autres outils d'exploration approfondie. Ils exécutent notamment des requêtes ad hoc sur les données de surveillance sous-jacentes qui désagrègent les données, suivent les demandes et révèlent des données connexes ou corrélées.
Tableaux de bord pour les infrastructures
Nos services s'exécutent sur une infrastructure AWS qui émet généralement des métriques. Par conséquent, nous disposons également de tableaux de bord dédiés aux infrastructures. Ces tableaux de bord se concentrent principalement sur les métriques émises par les ressources de calcul sur lesquelles nos systèmes sont exécutés : instances Amazon Elastic Compute Cloud (EC2), conteneurs Amazon Elastic Container Service (ECS)/Amazon Elastic Kubernetes Service (EKS) et fonctions AWS Lambda. Des métriques telles que l'utilisation du processeur, le trafic réseau, les entrées/sorties de disque et l'utilisation de l'espace sont couramment utilisées dans ces tableaux de bord. Il en est de même pour tout cluster connexe, pour l'Auto Scaling et les métriques de quota pertinentes pour ces ressources de calcul.
Tableaux de bord pour les dépendances
Outre les ressources de calcul, les microservices dépendent d'autres microservices, dans de nombreux cas. Même si les équipes qui possèdent ces dépendances ont déjà leurs propres tableaux de bord, chaque propriétaire de microservice crée généralement des tableaux de bord dédiés aux dépendances afin de bénéficier d'une vue sur le comportement des dépendances en amont (par exemple, les proxies et les équilibreurs de charge) et en aval (par exemple, les magasins de données, les files d'attente et les flux), tel que mesuré par leur service. Ces tableaux de bord peuvent aussi être utilisés pour suivre d'autres métriques essentielles à l'instar des dates d'expiration des certificats de sécurité et de l'utilisation d'autres quotas de dépendance.
Conception des tableaux de bord
Chez Amazon, nous considérons qu'il est quasi impossible de réussir la création d'un tableau de bord sans une présentation cohérente des données. Pour être efficace, la cohérence doit être assurée tant au sein de chaque tableau de bord qu'entre l'ensemble des tableaux de bord. Au fil des ans, nous avons identifié, adapté et affiné un ensemble commun d'idiomes et de conventions de conception qui, selon nous, rendent les tableaux de bord accessibles au public le plus large, ce qui, en fin de compte, augmente leur valeur pour notre organisation. Nous sommes allés plus loin en trouvant des moyens subtils de mesurer et d'améliorer ces conventions de conception au fil du temps. Par exemple, si un nouvel opérateur peut rapidement comprendre et utiliser les données présentées dans les tableaux de bord pour apprendre comment fonctionne un service, cela signifie que ces tableaux de bord présentent les bonnes informations de la bonne manière.
Lors de la conception de tableaux de bord, la tendance générale est surestimer ou de sous-estimer la connaissance du domaine de l'utilisateur cible. Il est facile de créer un tableau de bord qui sied parfaitement à son créateur. Cependant, il se peut que ce tableau de bord ne soit pas utile aux utilisateurs. Nous utilisons la technique du travail à rebours depuis le client (dans ce cas, les utilisateurs du tableau de bord) pour éliminer ce risque.
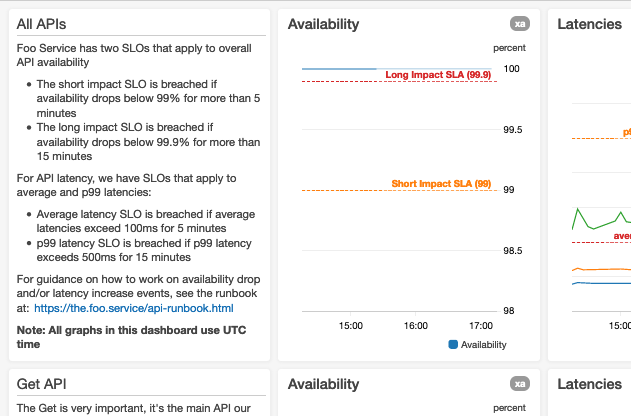
Nous avons adopté une convention de conception qui standardise la présentation des données dans un tableau de bord. Les tableaux de bord sont rendus selon le schéma haut/bas, et les utilisateurs ont tendance à prendre les graphiques initialement rendus (visibles lorsque le tableau de bord se charge) pour les plus importants. Par conséquent, notre convention de conception conseille de placer les données les plus importantes en haut du tableau de bord. Nous avons constaté que les graphiques de disponibilité agrégés/résumés et les graphiques de percentile de latence de bout en bout sont généralement les tableaux de bord les plus importants pour les services Web.
Voici une capture d'écran du haut d'un tableau de bord pour un Foo Service imaginaire :
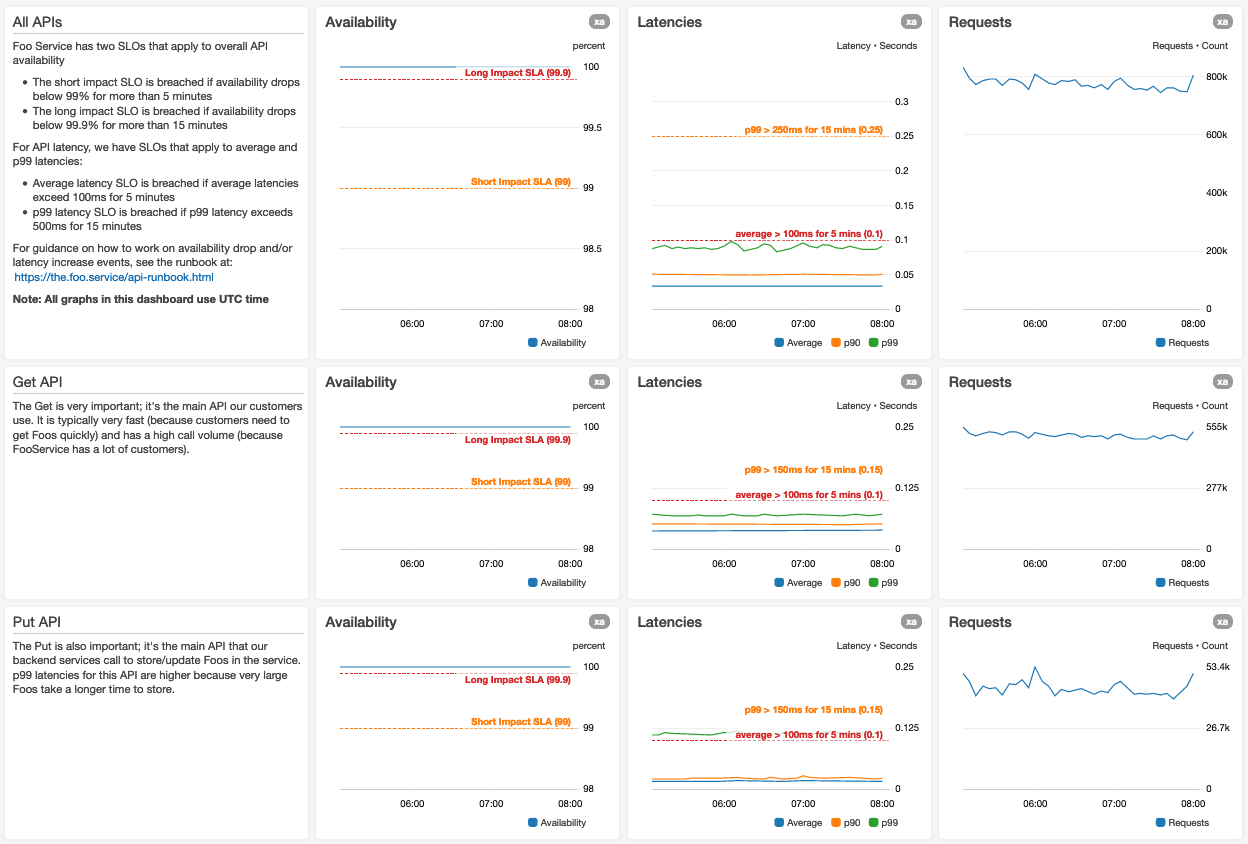
Nous utilisons de plus grands graphiques pour les métriques les plus importantes
Il peut arriver qu'un graphique comporte de nombreuses métriques. Dans ce cas, nous nous assurons que les légendes du graphique ne compriment pas verticalement ou horizontalement les données visibles du graphique. Si nous utilisons des requêtes de recherche dans des graphiques, nous nous assurons de prendre en compte un ensemble de résultats de métriques plus important que la normale.
Nous présentons des graphiques pour la résolution minimale d'affichage attendue
Le but est d'éviter d'obliger les utilisateurs à faire défiler les pages horizontalement. Un opérateur d'astreinte sur un ordinateur portable à 3 heures du matin pourrait ne pas remarquer la barre de défilement horizontale en l'absence d'un indice visuel évident indiquant la présence de plus de graphiques à droite.
Nous affichons le fuseau horaire
Pour les tableaux de bord qui affichent des données de date et d'heure, nous nous assurons que le fuseau horaire correspondant est visible dans le tableau de bord. Quant à ceux qui sont utilisés simultanément par des opérateurs de différents fuseaux horaires, nous utilisons par défaut un fuseau horaire (UTC) auquel tous les utilisateurs peuvent se référer. Ainsi, les utilisateurs peuvent communiquer entre eux en utilisant un seul fuseau horaire, ce qui leur évite de perdre du temps et de faire des conversions mentales excessives de fuseaux horaires.
Nous utilisons l'intervalle de temps et la période de points de données les plus courts
Nous utilisons, par défaut, l'intervalle de temps et la période des points de données pertinents pour les cas d'utilisation les plus courants. Nous veillons à ce que tous les graphiques d'un tableau de bord affichent initialement les données pour la même plage de temps et la même résolution. Nous estimons qu'il est avantageux que tous les graphiques d'une section du tableau de bord aient la même taille horizontale. Cela favorise la corrélation temporelle entre les graphiques.
Nous évitons également de tracer trop de points de données dans les graphiques, car cela ralentit le temps de chargement du tableau de bord. Par ailleurs, nous avons observé que l'affichage d'un nombre excessif de points de données peut rendre les anomalies moins visibles aux utilisateurs. Par exemple, un graphique d'un intervalle de trois heures de points de données d'une résolution d'une minute avec seulement 180 valeurs par métrique donnera un rendu clair, même dans les petits widgets du tableau de bord. Ce nombre de points de données fournit également un contexte suffisant aux opérateurs qui trient les événements opérationnels en cours.
Nous offrons la possibilité d'ajuster l'intervalle de temps et la période métrique
Nos tableaux de bord fournissent des contrôles permettant d'ajuster rapidement l'intervalle de temps et la période métrique pour tous les graphiques. D'autres rapports de résolution d'intervalle x que nous utilisons couramment dans nos tableaux de bord sont :
- 1 heure x 1 minute (60 points de données) – utile pour zoomer afin d'observer les événements en cours
- 12 heures x 1 minute (720 points de données)
- 1 jour x 5 minutes (288 points de données) – utile pour visualiser les tendances quotidiennes
- 3 jours x 5 minutes (864 points de données)
- 1 semaine x 1 heure (168 points de données) – utile pour visualiser les tendances hebdomadaires
- 1 mois x 1 heure (744 points de données)
- 3 mois x 1 jour (90 points de données) – utile pour visualiser les tendances trimestrielles
- 9 mois x 1 jour (270 points de données)
- 15 mois x 1 jour (450 points de données) – utile pour les examens des capacités à long terme
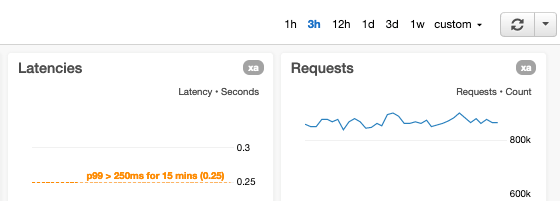
Nous annotons les graphiques avec des seuils d'alarme
Nous annotons les graphiques avec des lignes horizontales si les seuils d'alarme sont statiques lorsque nous représentons graphiquement des métriques qui ont des alarmes automatiques liées. Si les seuils d'alarme sont dynamiques, c'est-à-dire basés sur des prévisions ou des prédictions générées par l'intelligence artificielle (IA) ou le machine learning (ML), nous affichons les métriques réelles et les seuils dans le même graphique. Si un graphique comporte un paramètre qui mesure un aspect du service ayant des limites connues (comme une limite « maximale testée » ou une limite de ressources matérielles), nous annotons le graphique d'une ligne horizontale indiquant où se trouvent les limites connues ou testées. Pour les métriques qui ont des objectifs, nous ajoutons des lignes horizontales pour rendre ces objectifs immédiatement visibles à l'utilisateur.
Nous évitons d'ajouter des lignes horizontales aux graphiques qui utilisent déjà un axe des ordonnées (axe des y) à gauche et à droite
Si vous ajoutez des lignes horizontales à ces graphiques, les utilisateurs pourraient avoir du mal à savoir à quel axe des y se rapporte la ligne horizontale. Pour éviter cette ambiguïté, nous séparons les graphiques de ce type en deux graphiques qui n'utilisent qu'un seul axe horizontal et n'ajoutent les lignes horizontales qu'au graphique approprié.
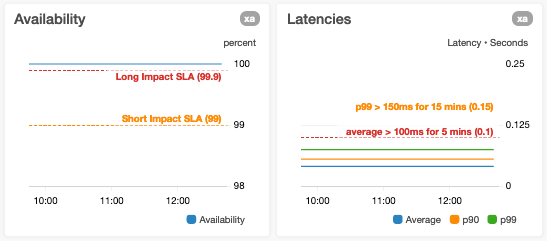
Nous évitons de surcharger un axe des y avec des métriques multiples qui ont des plages de valeurs très disparates
Nous évitons cette situation, car elle risque de réduire la visibilité de la variance d'une ou plusieurs métriques. C'est notamment le cas lorsque nous traçons les latences p0 (minimum) et p100 (maximum) sur le même graphique, où les valeurs des points de données p100 peuvent être supérieures d'un ordre de grandeur à celles des points de données p0.
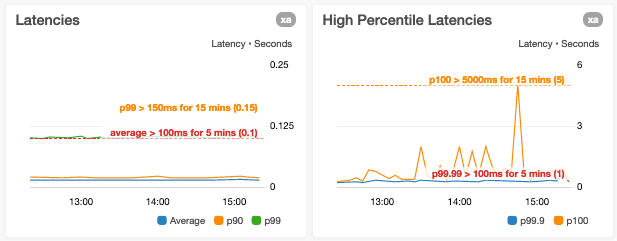
Nous évitons de réduire les limites de l'axe des y à la seule plage de valeurs actuelle des points de données
Un graphique dont la plage de l'axe des y est limitée aux valeurs des points de données peut donner à une métrique une apparence beaucoup plus variable qu'elle ne l'est en réalité.
Nous évitons de surcharger les graphiques individuels
Nous voulons nous assurer que nous n'avons pas trop de statistiques ou de métriques sans rapport dans un seul graphique. Par exemple, lorsque nous ajoutons des graphiques pour le traitement des demandes, nous créons généralement des graphiques adjacents distincts dans le tableau de bord pour les éléments suivants :
- Disponibilité % (défaillances/demandes * 100)
- p10, Moyenne, latences p90
- p99,9 et latences maximales (p100)
Nous ne supposons pas que l'utilisateur sache exactement ce que chaque métrique ou widget signifie
Ceci s'applique en particulier aux métriques spécifiques à la mise en œuvre. Nous voulons fournir un contexte suffisant dans le texte du tableau de bord, par exemple avec un texte de description à côté ou en dessous de chaque graphique. L'opérateur peut lire ce texte pour comprendre ce que signifie le système métrique. L'opérateur peut alors interpréter ce qui est « normal » et les implications d'un graphique « non normal ». Nous fournissons dans le présent texte des liens vers des ressources connexes qu'un opérateur peut utiliser pour déterminer la cause racine. Voici quelques exemples des types de liens que nous fournissons :
- Vers les runbooks. Pour les experts, le tableau de bord peut être le runbook.
- Vers les tableaux de bord « d'exploration approfondie » connexes.
- Vers des tableaux de bord équivalents pour d'autres clusters ou partitions.
- Vers les pipelines de déploiement.
- Pour obtenir les coordonnées des dépendances.
Nous utilisons des widgets de statut d'alarme, de nombres simples et/ou de graphiques de séries chronologiques, le cas échéant
Selon les cas d'utilisation du tableau de bord, nous constatons que l'affichage d'un widget qui contient un seul chiffre – par exemple, la dernière valeur d'une métrique ou un état d'alarme – est parfois plus approprié que l'affichage d'un graphique complexe de séries chronologiques de tous les points de données récents.

Nous évitons de nous fier à des graphiques qui présentent des métriques éparses
On entend par « métriques éparses » des métriques qui ne sont émises que lorsque certaines conditions d'erreur existent. Bien qu'il puisse être efficace d'instrumenter les services pour qu'ils n'émettent ces métriques qu'en cas de nécessité, les utilisateurs du tableau de bord peuvent être déroutés par des graphiques vides ou presque vides. Face à de telles métriques lors de la conception de tableaux de bord, nous modifions généralement le service afin d'émettre continuellement des valeurs sûres (c'est-à-dire zéro) pour ces mesures en l'absence de la condition d'erreur. Les opérateurs peuvent alors facilement comprendre que l'absence de données signifie que le service n'émet pas correctement la télémétrie.
Nous ajoutons des graphiques supplémentaires qui affichent des métriques par mode
Nous le faisons lorsque nous affichons des graphiques pour des métriques qui regroupent le comportement multimodèle dans nos systèmes. Voici quelques circonstances dans lesquelles nous pourrions le faire :
- Si un service prend en charge des demandes de taille variable, nous pourrions créer un graphique pour les temps de latence totaux des demandes. Nous pouvons également créer des graphiques qui affichent des métriques pour les demandes de petite, moyenne et grande taille.
- Si un service exécute les demandes de manière variable en fonction des valeurs (ou combinaisons) des paramètres d'entrée, nous pourrions alors ajouter des graphiques pour les métriques qui capturent chaque mode d'exécution.
Maintenance du tableau de bord
La création de tableaux de bord qui présentent de nombreuses vues de nos systèmes n'est qu'une première étape. En effet, comme nos systèmes évoluent et se développent en permanence, les tableaux de bord doivent évoluer avec eux au fil de l'ajout de nouvelles fonctionnalités et de l'amélioration des architectures. L'entretien et la mise à jour des tableaux de bord font partie intégrante de notre processus de développement. Nos développeurs se posent la question suivante avant d'effectuer des modifications et lors de la révision des codes : « Dois-je mettre à jour des tableaux de bord ? » Ils sont habilités à apporter des modifications aux tableaux de bord avant que les changements sous-jacents ne soient déployés. Cela permet d'éviter la situation où un opérateur doit mettre à jour les tableaux de bord pendant ou après le déploiement d'un système pour valider le changement en cours.
Si un tableau de bord contient des informations beaucoup plus détaillées que la normale, il se peut que les opérateurs se fient à ce tableau de bord pour la détection manuelle des anomalies au lieu d'automatiser les alarmes et les mesures correctives. Nous vérifions continuellement nos tableaux de bord afin de déterminer si nous pouvons réduire cet effort manuel en améliorant l'instrumentation de nos services et en renforçant notre système d'alarme automatisé. Nous éliminons ou mettons à jour activement les graphiques qui n'apportent plus de valeur ajoutée aux tableaux de bord.
En permettant à nos développeurs de mettre à jour les tableaux de bord, nous nous assurons de disposer d'un ensemble complet et identique de tableaux de bord pour nos environnements de préproduction (alpha, bêta ou gamma). Nos pipelines de déploiement automatisés déploient d'abord les changements aux environnements de préproduction. Nos équipes doivent donc être capables de valider facilement les changements dans ces environnements de test en utilisant les tableaux de bord associés (et les alarmes automatisées) d'une manière qui est exactement cohérente avec la manière dont ils seront validés lorsque les changements seront transmis à nos environnements de production.
La plupart des systèmes évoluent en permanence au fil de la mise à jour des exigences, de l'ajout de nouvelles fonctionnalités et de la modification des architectures logicielles pour s'adapter aux changements d'échelle dans le temps. Nos tableaux de bord sont une composante essentielle de nos systèmes. Voilà pourquoi nous suivons le processus Infrastructure-as-Code (IaC) pour leur maintenance. Ce processus garantit que nos tableaux de bord sont maintenus dans des systèmes de contrôle de version et que les changements sont déployés dans nos tableaux de bord en utilisant les mêmes outils que nos développeurs et opérateurs utilisent pour nos services.
Lors de l'autopsie d'un événement opérationnel inattendu, nos équipes examinent si des améliorations des tableaux de bord (et des alarmes automatisées) auraient pu prévenir l'événement, identifier la cause racine plus rapidement ou réduire le délai moyen de reprise. En règle générale, nous nous posons la question suivante : « Rétrospectivement, les tableaux de bord ont-ils clairement montré l'impact sur le client, aidé les opérateurs à trianguler pour déterminer la cause racine ultime et aidé à mesurer le délai de reprise ? » Si la réponse à l'une de ces questions est négative, alors nos autopsies comprennent des actions visant à affiner ces tableaux de bord.
Conclusion
Chez Amazon, nous prenons en charge des services à grande échelle dans le monde entier. Nos systèmes automatisés surveillent, détectent, alertent et remédient en permanence à tout problème qui survient. Nous devons être en mesure de contrôler, faire une exploration approfondie, d'auditer et d'examiner ces services et ces systèmes automatisés. À cet effet, nous créons et entretenons des tableaux de bord qui fournissent de nombreuses vues différentes de nos systèmes. Nous concevons ces tableaux de bord pour des publics à la fois variés et spécifiques en travaillant à rebours à partir des utilisateurs des tableaux de bord. Pour rendre les tableaux de bord plus faciles à comprendre pour les opérateurs et les propriétaires de services, nous utilisons un ensemble cohérent d'idiomes et de conventions de conception afin de garantir la convivialité et l'utilité des tableaux de bord.
Nos tableaux de bord offrent de nombreuses perspectives et points de vue différents sur le fonctionnement des services AWS. Ils jouent un rôle essentiel dans la proposition d'une expérience client exceptionnelle en aidant les équipes d'Amazon à comprendre nos services, les exploiter et les mettre à l'échelle. Nous espérons que cet article vous aidera dans la conception, la création et la maintenance de vos propres tableaux de bord. Si vous souhaitez voir un exemple de création de tableaux de bord à l'aide des services AWS, regardez cette courte vidéo et consultez ce guide en libre-service.
À propos de l’auteur
John O'Shea est ingénieur principal chez Amazon Web Services. En ce moment, il travaille principalement sur Amazon CloudWatch et d'autres services de surveillance et d'observabilité internes à Amazon.

Rubriques connexes
Avez-vous trouvé les informations que vous recherchiez ?
Faites-nous part de vos commentaires afin que nous puissions améliorer le contenu de nos pages