Défis liés aux systèmes distribués
ARCHITECTURE | NIVEAU 200
Introduction
Les systèmes distribués sont devenus la norme chez Amazon à partir du moment où nous avons ajouté un deuxième serveur. Lorsque j’ai fait mes débuts chez Amazon, en 1999, nous avions tellement peu de serveurs que nous pouvions leur donner des noms comme « fishy » ou « online-01 ». Pour autant, même en 1999, l’informatique distribuée n’avait rien de facile. Déjà à l’époque, les défis posés par les systèmes distribués impliquaient la latence, le dimensionnement, la compréhension des API de mise en réseau, la transformation et le rétablissement de données, et la complexité des algorithmes comme Paxos. La taille des systèmes a rapidement évolué à la hausse et ceux-ci sont devenus plus distribués. Nous sommes passés de cas périphériques théoriques à des occurrences régulières.
Développer des modèles de services informatiques distribués, comme les réseaux téléphoniques longue distance ou les services Amazon Web Services (AWS), est une tâche difficile. L’informatique distribuée est également plus bizarre et moins intuitive que les autres formes d’informatique, car elle implique deux problèmes interdépendants. Dans les systèmes distribués, les problèmes les plus sérieux viennent des échecs indépendants et du non-déterminisme. En plus des échecs informatiques classiques typiques dont les ingénieurs ont l’habitude, les échecs dans les systèmes distribués peuvent se produire de bien d’autres façons. Et pire encore : il était parfois impossible de savoir si une panne s'était produite.
Dans la bibliothèque des créateurs Amazon, nous expliquons comment AWS gère les problèmes complexes de développement et d’opérations posés par les systèmes distribués. Avant de nous pencher plus en avant sur ces techniques (nous le ferons dans d’autres articles), il peut être judicieux de revoir les concepts qui expliquent en partie pourquoi l’informatique distribuée est si… bizarre. Nous allons tout d’abord voir quels sont les différents types de systèmes distribués.
Types de systèmes distribués
Les systèmes distribués se caractérisent en fait par la difficulté de leur implémentation. D’un côté, nous avons les systèmes distribués hors ligne. Ils comprennent les systèmes de traitement par lots, les clusters d’analyse de Big Data, les fermes de rendu des images de film, les clusters de repliement des protéines, etc. Bien qu’ils soient loin d’être simples à mettre en œuvre, les systèmes distribués hors connexion offrent presque tous les avantages de l’informatique distribuée (capacité de mise à l’échelle et tolérance aux pannes) et ce, pratiquement sans aucun des inconvénients (modes de défaillance complexes et non-déterminisme).
Au milieu du spectre se trouvent les systèmes distribués en temps réel souples. Ce sont des systèmes critiques qui doivent continuellement produire ou mettre à jour des résultats, mais ils disposent d’un laps de temps relativement long pour le faire. Des exemples de ces systèmes incluent des générateurs d'index de recherche, des systèmes qui recherchent des serveurs endommagés, des rôles pour Amazon Elastic Compute Cloud (Amazon EC2), etc. Un indexeur de recherche peut être déconnecté (selon l'application) pendant 10 minutes à de nombreuses heures sans impact excessif sur le client. Les rôles pour Amazon EC2 doivent transmettre des informations d'identification mises à jour à (pratiquement) chaque instance EC2, mais le processus est long, car les anciennes informations d'identification n'expireront pas avant un certain temps.
À l'extrémité la plus éloignée et la plus difficile du spectre se trouvent les systèmes distribués en temps réel durs. Ceux-ci sont souvent appelés services de demande/réponse. Chez Amazon, lorsque nous pensons à la création d'un système distribué, le premier type auquel nous pensons est le système en temps réel dur. Malheureusement, les systèmes distribués en temps réel durs sont les plus difficiles à obtenir. Cela s'explique par le fait que les demandes arrivent de manière imprévisible et que les réponses doivent être données rapidement (par exemple, le client attend activement la réponse). De nombreux exemples incluent les serveurs Web frontaux, le pipeline de commandes, les transactions par carte de crédit, toutes les API AWS, la téléphonie, etc. Les systèmes distribués en temps réel durs sont l’axe principal de cet article.
Les systèmes en temps réel durs sont étranges.
Dans une intrigue de la bande dessinée Superman, le héros rencontre un alter ego appelé Bizarro qui vit sur une planète (Bizarro World) où c’est le monde à l’envers. Bizarro est un peu similaire à Superman, mais il fait en réalité partie des méchants. C'est la même chose pour les systèmes distribués en temps réel durs. Ils ressemblent dans une certaine mesure à l'informatique classique, mais ils sont en réalité différents et se trouvent, franchement, un peu du côté obscur.
Le développement de systèmes distribués en temps réel durs est étrange pour une raison : la mise en réseau des demandes/réponses. Nous ne parlons pas des détails essentiels des TCP/ IP, DNS, sockets ou autres protocoles similaires. Ces sujets sont potentiellement complexes à comprendre, mais ils ressemblent à d’autres problèmes difficiles en informatique.
Ce qui rend difficiles les systèmes distribués en temps réel durs, c’est que le réseau permet d’envoyer des messages d’un domaine d’erreur à un autre. L’envoi d’un message peut sembler anodin. En fait, l'envoi de messages constitue le moment où tout commence à devenir plus compliqué que la normale.
Pour prendre un exemple simple, observez l'extrait de code suivant issu d'une implémentation de Pac-Man. Destiné à être exécuté sur un seul ordinateur, il n’envoie aucun message sur aucun réseau.
board.move(pacman, user.joystickDirection())
ghosts = board.findAll(":ghost")
for (ghost in ghosts)
if board.overlaps(pacman, ghost)
user.slayBy(":ghost")
board.remove(pacman)
return
Imaginons à présent que nous devons développer une version réseau de ce code en conservant l’objet « board » sur un serveur distinct. Chaque appel passé à l’objet « board », tel que findAll(), entraîne l’envoi et la réception de messages entre deux serveurs.
Lorsqu’un message de demande/réponse est envoyé entre deux serveurs, le même ensemble de huit étapes, au minimum, doit toujours être appliqué. Pour comprendre le code Pac-Man en réseau, examinons les bases de la messagerie de demande/réponse.
Messagerie dans un réseau
Messagerie de demande/réponse sur un réseau
Une action de demande/réponse circulaire implique toujours les mêmes étapes. Comme indiqué dans le diagramme suivant, le client de la machine CLIENT envoie une demande MESSAGE via le réseau NETWORK à la machine serveur SERVER, qui répond avec le message REPLY, également via le réseau NETWORK
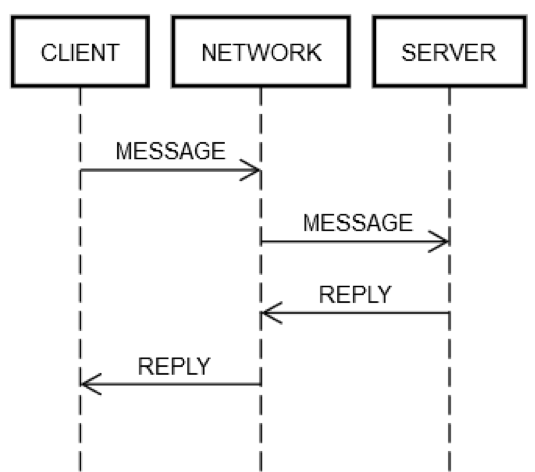
Dans le cas heureux où tout fonctionne correctement, les étapes suivantes se produisent :
-
POST REQUEST : CLIENT place la demande MESSAGE sur NETWORK.
-
DELIVER REQUEST : NETWORK envoie MESSAGE à SERVER.
-
VALIDATE REQUEST : SERVER valide MESSAGE.
-
UPDATE SERVER STATE : SERVER met à jour son état, si besoin, en fonction de MESSAGE.
-
POST REPLY : SERVER place la réponse REPLY sur NETWORK.
-
DELIVER REPLY : NETWORK livre REPLY à CLIENT.
-
VALIDATE REPLY : CLIENT valide REPLY.
-
UPDATE CLIENT STATE : CLIENT met à jour son état, si besoin, en fonction de REPLY.
Ce sont beaucoup d'étapes pour un si petit aller-retour ! Ces étapes constituent néanmoins la définition de la communication demande/réponse sur un réseau. Il n'y a aucun moyen d'ignorer l'une d'elles. Par exemple, il est impossible d'ignorer l'étape 1. Le client doit placer MESSAGE sur le réseau NETWORK, de quelque façon que ce soit. Physiquement, cela signifie l'envoi de paquets via une carte réseau, ce qui entraîne le passage des signaux électriques sur des câbles via une série de routeurs constituant le réseau entre CLIENT et SERVER. Cette étape est distincte de l'étape 2, car l'étape 2 pourrait échouer pour des raisons indépendantes, telles que la perte soudaine de l'alimentation de SERVER et l'incapacité d'accepter les paquets entrants. La même logique peut être appliquée aux autres étapes.
Ainsi, une seule demande/réponse sur le réseau fait éclater un élément (appelant une méthode) en huit éléments. Pire encore, comme indiqué ci-dessus, CLIENT, SERVER et NETWORK peuvent échouer indépendamment les uns des autres. Le code des ingénieurs doit prendre en charge l’une des étapes décrites précédemment. Cela est rarement vrai pour l’ingénierie classique. Pour comprendre pourquoi, examinons l’expression suivante de la version du code pour une machine unique.
board.find("pacman")
Techniquement, il existe plusieurs façons étranges de voir ce code échouer au moment de l’exécution, même si l’implémentation de board.find est elle-même sans bogues. Par exemple, le processeur peut surchauffer spontanément lors de l'exécution. L'alimentation électrique de la machine peut tomber en panne, également spontanément. Le noyau pourrait paniquer. La mémoire pourrait devenir pleine et certains objets que board.find tente de créer ne peuvent pas être créés. Ou le disque de la machine sur laquelle il tourne pourrait devenir plein, et board.find pourrait ne pas réussir à mettre à jour certains fichiers de statistiques, puis renvoyer une erreur, même si le cas ne devrait probablement pas se présenter. Un rayon gamma pourrait frapper le serveur et retourner un peu en RAM. Mais, la plupart du temps, les ingénieurs ne s'inquiètent pas de ces éléments. Par exemple, les tests unitaires ne couvrent jamais le scénario « Que se passe-t-il si le processeur échoue ? » et ne couvrent que rarement les scénarios de mémoire insuffisante.
En ingénierie typique, ces types de pannes se produisent sur une seule machine, c'est-à-dire un seul domaine d'erreur. Par exemple, si la méthode board.find échoue parce que le processeur grille spontanément, on peut raisonnablement supposer que la machine entière est en panne. Il n'est même pas possible d'un point de vue conceptuel de traiter cette erreur. Des hypothèses similaires peuvent être établies sur les autres types d'erreurs répertoriées plus haut. Vous pourriez essayer d'écrire des tests pour certains de ces cas, mais l'ingénierie typique n'a guère d'intérêt. Si ces échecs se produisent, on peut raisonnablement supposer que tout le reste échouera aussi. Techniquement, on dit qu'ils partagent tous un destin commun. Le partage d’un destin commun réduit énormément les différents modes de défaillance qu’un ingénieur doit gérer.
Traitement d’une panne
Gestion des modes de défaillance dans les systèmes distribués en temps réel durs
Les ingénieurs travaillant sur des systèmes de distribution en temps réel durs doivent tester tous les aspects de la défaillance d'un réseau, car les serveurs et le réseau ne partagent pas le même destin. Contrairement au cas d'une machine unique, en cas de défaillance du réseau, la machine client continuera à fonctionner. Si la machine distante échoue, la machine client continuera à fonctionner, et ainsi de suite.
Pour tester de manière exhaustive les cas d'échec des étapes de demande/réponse décrites précédemment, les ingénieurs doivent supposer que chaque étape pourrait échouer. Ils doivent également s'assurer que le code (sur le client et le serveur) se comporte toujours correctement à la lumière de ces échecs.
Examinons une action demande/réponse circulaire dans laquelle certains éléments ne fonctionnent pas :
-
POST REQUEST échoue : NETWORK n’a pas distribué le message (par exemple, un routeur intermédiaire est tombé en panne juste au mauvais moment) ou SERVER l’a explicitement rejeté.
-
DELIVER REQUEST échoue : NETWORK livre avec succès le MESSAGE à SERVER, mais celui-ci rencontre un incident après la réception du MESSAGE.
-
VALIDATE REQUEST échoue : SERVER décide que MESSAGE est non valide. La cause peut être presque n’importe quoi. Par exemple, des paquets endommagés, des versions de logiciels incompatibles ou des bogues sur le client ou le serveur.
-
UPDATE SERVER STATE échoue : SERVER tente de mettre à jour son état, mais cela ne fonctionne pas.
-
PUBLIER LA RÉPONSE échoue : indépendamment du fait que le serveur tente de répondre avec succès ou échec, le serveur peut ne pas envoyer la réponse. Par exemple, sa carte réseau risque de griller au mauvais moment.
-
LIVRER LA RÉPONSE échoue : le RÉSEAU pourrait ne pas réussir à répondre au CLIENT comme indiqué précédemment, même si le RÉSEAU fonctionnait auparavant.
-
VALIDE LA RÉPONSE échoue : le CLIENT décide que cette RÉPONSE est non valide.
-
METTRE À JOUR L’ÉTAT DU CLIENT échoue : le CLIENT peut recevoir la RÉPONSE du message, mais ne parvient pas à mettre à jour son propre état, ne comprend pas le message (en raison de son incompatibilité) ou échoue pour une quelconque autre raison.
Ce sont ces modes de défaillance qui rendent l'informatique distribuée si dure. Je les appelle les huit modes d'échec de l'apocalypse. Examinons à nouveau cette expression du code Pac-Man à la lumière de ces modes de défaillance.
board.find("pacman")
Cette expression se développe dans les activités suivantes du côté client :
-
Publiez un message, tel que {action: "find", name: "pacman", userId: "8765309"}, sur le réseau, à destination de la machine Board.
-
Si le réseau est indisponible ou si la connexion à la machine Board est explicitement refusée, générez une erreur. Ce cas est quelque peu spécial parce que le client sait, de manière déterministe, que la demande n'aurait pas pu être reçue par la machine serveur.
-
Attendez une réponse.
-
Si aucune réponse n'est jamais reçue, le délai d'attente est atteint. Dans cette étape, la temporisation signifie que le résultat de la demande est UNKNOWN. Cela peut avoir eu lieu ou non. Le client doit gérer UNKNOWN correctement.
-
Si une réponse est reçue, déterminez s'il s'agit d'une réponse positive, d'une réponse erronée ou incompréhensible/corrompue.
-
S'il ne s'agit pas d'une erreur, annulez la réponse et transformez-la en objet que le code peut comprendre.
-
S’il s’agit d’une erreur ou d’une réponse incompréhensible, générez une exception.
-
Quel que soit le système utilisé, l’exception doit déterminer si elle doit réessayer la demande ou abandonner et arrêter le jeu.
L’expression démarre également les activités suivantes côté serveur :
-
Recevoir la demande (cela peut ne pas se produire du tout).
-
Valider la demande.
-
Rechercher l'utilisateur pour voir s'il est toujours en vie. (Le serveur a peut-être abandonné l'utilisateur parce qu'il n'a pas reçu de message depuis trop longtemps.)
-
Mettre à jour la table keep-alive pour l'utilisateur afin que le serveur sache qu'il est (probablement) toujours là.
-
Recherchez la position de l'utilisateur.
-
Publiez une réponse avec un contenu semblable à ce qui suit : {xPos: 23, yPos: 92, clock: 23481984134}.
-
Toute autre logique de serveur doit gérer correctement les effets futurs du client. Par exemple, ne pas recevoir le message, le recevoir mais ne pas le comprendre, le recevoir et connaître des incidents, ou le gérer avec succès.
En résumé, une expression dans un code normal se transforme en quinze étapes supplémentaires dans un code de systèmes distribués en temps réel durs. Cette expansion est due aux huit points différents auxquels chaque communication circulaire entre client et serveur peut échouer. Toute expression représentant un aller-retour sur le réseau, telle que board.find("pacman"), a pour résultat ce qui suit.
(error, reply) = network.send(remote, actionData)
switch error
case POST_FAILED:
// handle case where you know server didn’t get it
case RETRYABLE:
// handle case where server got it but reported transient failure
case FATAL:
// handle case where server got it and definitely doesn’t like it
case UNKNOWN: // i.e., time out
// handle case where the only thing you know is that the server received
// the message; it may have been trying to report SUCCESS, FATAL, or RETRYABLE
case SUCCESS:
if validate(reply)
// do something with reply object
else
// handle case where reply is corrupt/incompatible
Cette complexité est inévitable. Si le code ne gère pas tous les cas correctement, le service échouera de manière étrange. Imaginez que vous essayiez d’écrire des tests pour tous les modes de défaillance qu’un système client/serveur, tel que l’exemple Pac-Man, pourrait rencontrer !
Test
Tester des systèmes distribués en temps réel strict
Tester la version mono-machine unique de l'extrait de code Pac-Man est comparativement simple. Créez différents objets Board, affectez-leur différents états, créez des objets User avec différents états, etc. Les ingénieurs réfléchiraient le plus possible aux conditions périphériques et utiliseraient peut-être des tests génératifs ou un fuzzer.
Dans le code Pac-Man, l'objet board est utilisé à quatre endroits. Dans la version Pac-Man distribuée, ce code comporte quatre points qui ont cinq résultats possibles, comme illustré précédemment (POST_FAILED, RETRYABLE, FATAL, UNKNOWN ou SUCCESS). Ceux-ci multiplient considérablement l'espace d'états des tests. Par exemple, les ingénieurs des systèmes distribués en temps réel durs doivent gérer de nombreuses permutations. Imaginons que l'appel à board.find() échoue avec le résultat POST_FAILED. Vous devez ensuite tester ce qu'il se passe lorsqu'il échoue avec le résultat RETRYABLE, puis avec le résultat FATAL, etc.
Mais même ces tests sont insuffisants. Dans le code typique, les ingénieurs peuvent supposer que si board.find() fonctionne, le prochain appel passé à board, board.move(), fonctionnera également. Dans l'ingénierie des systèmes distribués en temps réel durs, il n'existe aucune garantie de ce type. La machine serveur pourrait échouer indépendamment à tout moment. Par conséquent, les ingénieurs doivent écrire des tests pour les cinq cas pour chaque appel passé à board. Supposons qu'un ingénieur propose 10 scénarios à tester dans la version de machine unique de Pac-Man. Toutefois, dans la version des systèmes distribués, ils doivent tester chacun de ces scénarios 20 fois. Ce qui signifie que le nombre de ballons de la matrice de test passe de 10 à 200 !
Mais attendez, il y a plus encore. L’ingénieur peut également être propriétaire du code serveur. Quelle que soit la combinaison des erreurs côté client, réseau et serveur, elles doivent être vérifiées afin que le client et le serveur ne se retrouvent pas dans un état corrompu. Le code serveur pourrait ressembler à ce qui suit.
handleFind(channel, message)
if !validate(message)
channel.send(INVALID_MESSAGE)
return
if !userThrottle.ok(message.user())
channel.send(RETRYABLE_ERROR)
return
location = database.lookup(message.user())
if location.error()
channel.send(USER_NOT_FOUND)
return
else
channel.send(SUCCESS, location)
handleMove(...)
...
handleFindAll(...)
...
handleRemove(...)
...
Il existe quatre fonctions côté serveur à tester. Supposons que chaque fonction, sur une machine unique, comporte cinq tests chacune. Cela représente 20 tests sur place. Étant donné que les clients envoient plusieurs messages au même serveur, les tests doivent simuler des séquences de différentes demandes pour s'assurer que le serveur reste robuste. Par exemple, les demandes peuvent inclure find, move, remove et findAll.
Supposons qu'une construction comporte 10 scénarios différents avec une moyenne de trois appels dans chaque scénario. Ce sont 30 tests supplémentaires. Mais un scénario doit également tester les cas d'échec. Pour chacun de ces tests, vous devez simuler ce qu'il se passe si le client reçoit l'un des quatre types d'échec (POST_FAILED, RETRYABLE, FATAL et UNKNOWN), puis rappelle le serveur avec une demande non valide. Par exemple, un client peut appeler find avec succès, mais parfois, il obtient UNKNOWN lorsqu'il appelle move. Il pourrait alors rappeler find pour une raison quelconque. Le serveur gère-t-il ce cas correctement ? Probablement, mais vous ne le saurez pas à moins de le tester. Ainsi, comme pour le code côté client, la matrice de test côté serveur déborde également de complexité.
Traitement des inconnues inconnues
Traitement des inconnues inconnues
Il est incroyable de prendre en compte toutes les permutations d'échecs qu'un système distribué peut rencontrer, en particulier lorsque les demandes sont multiples. Une des méthodes que nous avons trouvées pour aborder l'ingénierie distribuée est de nous méfier de tout. Chaque ligne de code, à moins qu'elle ne puisse pas causer la communication avec le réseau, ne fait pas ce qu'elle est censée faire.
Peut-être que l'élément le plus difficile à gérer est le type d'erreur UNKNOWN décrit dans la section précédente. Le client ne sait pas toujours si la demande a abouti. Peut-être a t-il déplacé Pac-Man (ou, dans un service bancaire, retiré de l'argent du compte bancaire de l'utilisateur), ou peut-être pas. Comment les ingénieurs devraient-ils gérer de tels éléments ? Difficilement, car les ingénieurs sont humains et les humains ont tendance à lutter contre la véritable incertitude. Les humains ont l’habitude de voir du code comme celui-ci.
bool isEven(number)
switch number % 2
case 0
return true
case 1
return false
Les humains comprennent ce code, car il fait ce à quoi il ressemble. Par contre, ils ont des difficultés avec la version distribuée du code, qui distribue une partie du travail à un service.
bool distributedIsEven(number)
switch mathServer.mod(number, 2)
case 0
return true
case 1
return false
case UNKNOWN
return WHAT_THE_FARG?
Il est presque impossible pour un humain de comprendre comment traiter correctement UNKNOWN. Qu'est-ce qu'UNKNOWN signifie vraiment ? Le code doit-il réessayer ? Si oui, combien de fois ? Combien de temps faut-il attendre entre les tentatives ? Le résultat est pire lorsque le code a des effets secondaires. Dans une application de budgétisation exécutée sur un seul ordinateur, il est facile de retirer de l’argent d’un compte, comme le montre l’exemple suivant.
class Teller
bool doWithdraw(account, amount)
switch account.withdraw(amount)
case SUCCESS
return true
case INSUFFICIENT_FUNDS
return false
Toutefois, la version distribuée de cette application est étrange à cause de l’erreur UNKNOWN.
class DistributedTeller
bool doWithdraw(account, amount)
switch this.accountService.withdraw(account, amount)
case SUCCESS
return true
case INSUFFICIENT_FUNDS
return false
case UNKNOWN
return WHAT_THE_FARG?
Trouver comment gérer le type d’erreur UNKNOWN est l’une des raisons pour lesquelles, en ingénierie distribuée, les choses ne sont pas toujours ce qu’elles semblent être.
Moteurs Herd
Groupes de systèmes distribués en temps réel durs
Les huit modes de défaillance de l'apocalypse peuvent se produire à n'importe quel niveau d'abstraction dans un système distribué. L'exemple précédent était limité à une machine client unique, à un réseau et à une machine serveur unique. Même dans ce scénario simpliste, la matrice des états de défaillance a débordé de complexité. Les systèmes distribués réels ont des matrices d'état d'échec plus complexes que l'exemple de la machine client unique. Les systèmes distribués réels sont constitués de plusieurs machines pouvant être visualisées à plusieurs niveaux d'abstraction :
-
Machines individuelles
-
Groupes de machines
-
Groupes de groupes de machines
-
Et ainsi de suite (éventuellement)
Par exemple, un service créé sur AWS peut regrouper des machines dédiées à la gestion des ressources situées dans une zone de disponibilité particulière. Il peut également y avoir deux autres groupes de machines qui gèrent deux autres zones de disponibilité. Ensuite, ces groupes peuvent être regroupés dans un groupe de régions AWS. Et ce groupe de régions peut communiquer (logiquement) avec d’autres groupes de régions. Malheureusement, même à ce niveau plus élevé et plus logique, tous les mêmes problèmes s’appliquent.
Supposons qu’un service ait regroupé quelques serveurs dans un seul groupe logique, GROUP1. Le groupe GROUP1 peut parfois envoyer des messages à un autre groupe de serveurs, GROUP2. Ceci est un exemple d'ingénierie distribuée récursive. Tous les modes d'échec de réseau décrits précédemment peuvent s'appliquer ici. Imaginons que GROUP1 souhaite envoyer une demande à GROUP2. Comme le montre le diagramme suivant, l’interaction demande/réponse sur deux machines est identique à celle de la machine unique décrite précédemment.
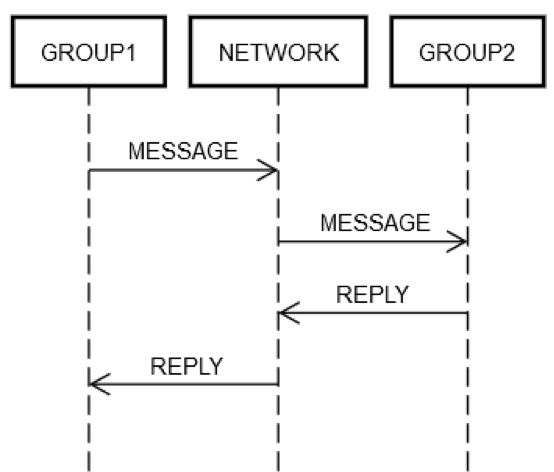
D’une manière ou d’une autre, certaines machines du GROUP1 doivent envoyer un message sur le réseau, NETWORK, adressé (logiquement) à GROUP2. Certaines machines du GROUP2 doivent traiter la demande, etc. Le fait que GROUP1 et GROUP2 soient constitués de groupes de machines ne change en rien les principes fondamentaux. GROUP1, GROUP2 et NETWORK peuvent toujours échouer indépendamment les uns des autres.
Toutefois, cela n'est pas seulement vrai au niveau du groupe. Il existe également une interaction de machine à machine au sein de chaque groupe. Par exemple, GROUP2 peut être structuré comme indiqué dans le diagramme suivant.
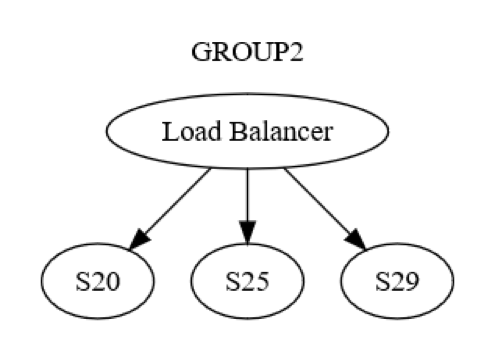
Tout d’abord, un message est envoyé à GROUP2, via l’équilibreur de charge, à une machine (disons S20) au sein du groupe. Les concepteurs du système savent que S20 peut échouer pendant la phase UPDATE STATE. Par conséquent, S20 peut avoir besoin de transmettre le message à au moins une autre machine, soit l'un de ses pairs, soit une machine d'un groupe différent. Comment S20 fait-il cela ? En envoyant un message de demande/réponse à S25 par exemple, comme indiqué dans le diagramme suivant.
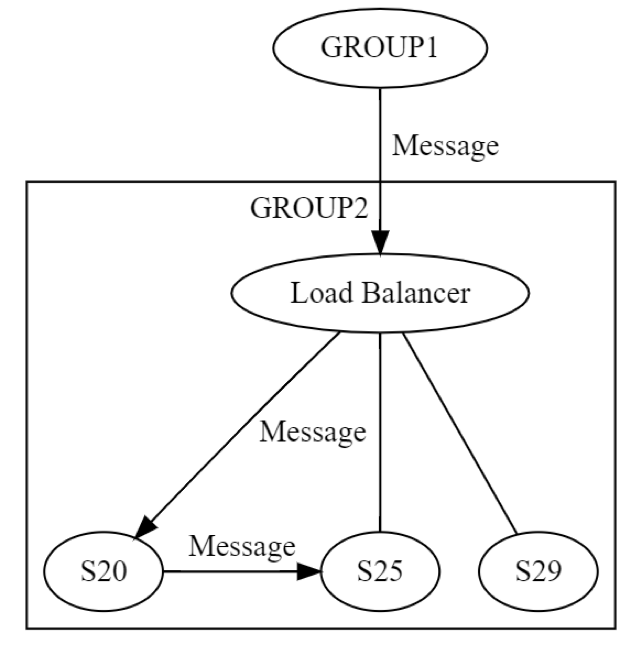
Ainsi, S20 exécute la mise en réseau de manière récursive. Les huit mêmes défaillances peuvent à nouveau se produire indépendamment. L'ingénierie distribuée se produit deux fois, au lieu d'une fois. Le message de GROUP1 à GROUP2, au niveau logique, peut échouer de huit manières différentes. Ce message aboutit à un autre message, qui peut lui-même échouer, de manière indépendante, des huit manières décrites précédemment. Tester ce scénario impliquerait au moins les éléments suivants :
-
Un test pour les huit modes d’échec de la messagerie au niveau du groupe de GROUP1 à GROUP2.
-
Un test pour les huit modes d’échec de la messagerie au niveau du serveur de S20 à S25.
Cet exemple de messagerie demande/réponse montre pourquoi le test des systèmes distribués reste un problème particulièrement épineux, même après plus de 20 ans d’expérience. Les tests sont complexes compte tenu de l'étendue des cas en périphérie, mais ils sont particulièrement importants dans ces systèmes. Les bogues peuvent prendre beaucoup de temps à apparaître après le déploiement des systèmes. De plus, les bogues peuvent avoir un impact imprévisible sur un système et ses systèmes adjacents.
Bogues distribués
Les bogues distribués sont souvent latents
Si un échec devait éventuellement se produire, il est généralement admis qu’il vaut mieux le faire le plus tôt possible. Par exemple, il est préférable de rechercher un problème d’échelle dans un service, ce qui nécessitera six mois pour résoudre le problème, au moins six mois avant que ce service n’atteigne une telle échelle. De même, il est préférable de rechercher les bogues avant qu’ils n’affectent la production. Si les bogues affectent la production, il est préférable de les localiser rapidement, avant qu'ils ne touchent de nombreux clients ou n'aient d'autres effets néfastes.
Les bogues distribués, c'est-à-dire ceux qui résultent de l'absence de gestion de toutes les permutations de huit modes de défaillance de l'apocalypse, sont souvent critiques. Les exemples rencontrés au fil du temps sont nombreux dans les grands systèmes distribués, des systèmes de télécommunication aux systèmes Internet principaux. Non seulement ces pannes sont généralisées et coûteuses, mais elles peuvent aussi être causées par des bogues affectant la production plusieurs mois plus tôt. Il faut ensuite un certain temps pour déclencher la combinaison de scénarios menant réellement à la survenue de ces bogues (et à leur propagation dans l'ensemble du système).
Les bogues distribués se propagent de manière épidémique.
Laissez-moi vous décrire un autre problème fondamental pour les bogues distribués :
-
Les bogues distribués impliquent nécessairement l’utilisation du réseau.
-
Par conséquent, les bogues distribués sont plus susceptibles de se propager à d’autres machines (ou groupes de machines), car, par définition, ils impliquent déjà le seul élément qui relie les machines entre elles.
Amazon a également rencontré ces bogues distribués. La défaillance de www.amazon.com à l'échelle du site est un exemple ancien, mais pertinent. L'échec était dû à la défaillance d'un serveur unique dans le service de catalogue distant lorsque son disque était plein.
En raison d'une mauvaise gestion de cette condition d'erreur, le serveur de catalogue distant a commencé à renvoyer des réponses vides à chaque demande reçue. Il a également commencé à les renvoyer très rapidement, car il est beaucoup plus rapide de ne rien renvoyer que d'envoyer un contenu (du moins, cela l'a été dans ce cas). Entre temps, l'équilibreur de charge entre le site Web et le service de catalogue distant n'a pas remarqué que toutes les réponses étaient vides. Mais, il a remarqué qu'elles étaient incroyablement plus rapides que celles de tous les autres serveurs de catalogue distants. Ainsi, il a envoyé une énorme quantité de trafic de www.amazon.com au serveur de catalogue distant dont le disque était plein. En réalité, tout le site Web était en panne, car un des serveurs distants ne pouvait afficher aucune information sur le produit.
Nous avons rapidement trouvé le serveur défaillant et l'avons retiré du service pour restaurer le site Web. Ensuite, nous avons poursuivi notre processus habituel consistant à déterminer les causes racines et à identifier les problèmes afin d'empêcher que la situation ne se reproduise. Nous avons partagé ces leçons sur Amazon afin d'éviter que d'autres systèmes ne rencontrent le même problème. En plus de tirer ces leçons spécifiques à propos de ce mode de défaillance, cet incident a été un excellent exemple de la façon dont les modes de défaillance se propagent rapidement et de manière imprévisible dans les systèmes distribués.
Récapitulatif
Résumé des problèmes dans les systèmes distribués
En bref, l'ingénierie pour les systèmes distribués est difficile pour les raisons suivantes :
-
Les ingénieurs ne peuvent pas combiner de conditions d'erreur. Au lieu de cela, ils doivent prendre en compte de nombreuses permutations d'échecs. La plupart des erreurs peuvent survenir à tout moment, indépendamment de (et donc potentiellement en combinaison avec) toute autre condition d’erreur.
-
Le résultat de toute opération sur le réseau peut être UNKNOWN, auquel cas la demande peut avoir abouti, échoué ou avoir été reçue, mais ne pas avoir été traitée.
-
Les problèmes distribués surviennent à tous les niveaux logiques d’un système distribué, pas seulement sur les machines physiques de faible niveau.
-
Les problèmes distribués s’aggravent aux niveaux supérieurs du système, en raison de la récursivité.
-
Les bogues distribués apparaissent souvent longtemps après leur déploiement sur un système.
-
Les bogues distribués peuvent se propager sur un système entier.
-
Plusieurs des problèmes ci-dessus découlent des lois de la physique des réseaux, qui ne peuvent pas être changées.
Le simple fait que l'informatique distribuée soit difficile (et étrange) ne signifie pas qu'il n'existe aucun moyen de s'attaquer à ces problèmes. Dans la bibliothèque des créateurs Amazon, nous étudions en détail comment AWS gère les systèmes distribués. Nous espérons que certaines leçons que nous avons apprises et partagées vous seront utiles dans le cadre de vos projets de création pour vos clients.
À propos de l’auteur
Jacob Gabrielson est ingénieur principal senior chez Amazon Web Services. Il travaille chez Amazon depuis 17 ans, principalement sur des plateformes internes de microservices. Ces huit dernières années, il a travaillé sur EC2 et ECS, notamment sur les systèmes de déploiement de logiciels, les services de plan de contrôle, le marché des instances Spot, Lightsail et, plus récemment, les conteneurs. Jacob est passionné par la programmation des systèmes, les langages de programmation et l'informatique distribuée. Le comportement bimodal des systèmes est ce qui le rebute le plus, en particulier en cas d'échec. Il a obtenu une licence en informatique à l'université de Washington de Seattle.

Avez-vous trouvé les informations que vous recherchiez ?
Faites-nous part de vos commentaires afin que nous puissions améliorer le contenu de nos pages