Utiliser le délestage pour éviter la surcharge
Distribution de logiciel et opérations de logiciels | NIVEAU 400
Introduction
J’ai travaillé, pendant quelques années, dans l’équipe des Cadres de service d’Amazon. Notre équipe a écrit des outils pour aider les propriétaires de services AWS, tels qu'Amazon Route 53 et Elastic Load Balancing, à créer des services plus rapidement, plus faciles à appeler pour les clients. D'autres équipes Amazon ont fourni aux propriétaires de services des fonctions telles que les calculs, l'authentification, la surveillance et la génération de bibliothèques clients et de documentation. Pour éviter à chaque équipe de service d'avoir à intégrer ces fonctions à leurs services manuellement, l'équipe Cadres de service effectuait cette intégration une fois et présentait la fonction à chaque service à travers la configuration.
L'un des défis que nous avons dû relever était de déterminer comment fournir des valeurs par défaut sensibles, en particulier pour les fonctions qui étaient liées aux performances et à la disponibilité. Par exemple, nous ne pouvions pas définir un délai côté client par défaut facilement, car notre cadre ne savait pas du tout quelles pouvaient être les caractéristiques de latence d'une API. Il n'aurait pas non plus été plus facile pour les propriétaires ou les clients de les trouver, c'est pourquoi nous avons continué à chercher et nous avons fait quelques découvertes utiles petit à petit.
L'un des problèmes récurrents avec lequel nous avions du mal était la détermination du nombre de connexions par défaut que le serveur permettrait d'ouvrir aux clients simultanément. Ce paramètre était conçu pour empêcher un serveur de prendre trop de travail et de devenir surchargé. Plus précisément, nous souhaitions configurer le nombre maximal de connexions pour le serveur proportionnellement aux connexions maximales de l'équilibreur de charge. À ce moment-là, Elastic Load Balancing n'était pas encore sorti, donc les équilibreurs de charge de matériel étaient largement utilisés.
Nous avons cherché à aider les propriétaires et les clients de services Amazon à trouver la valeur idéale de connexions maximales à définir pour l'équilibreur de charge, ainsi que la valeur correspondante à définir pour les cadres que nous fournissions. Nous avons décidé que si nous trouvions comment utiliser le jugement humain pour faire un choix, nous pourrions alors développer un logiciel pour émuler ce jugement.
Déterminer la valeur idéale s'est révélé être compliqué. Lorsque le nombre de connexions maximales était trop bas, l'équilibreur de charge pouvait arrêter l'augmentation du nombre de requêtes, même lorsque le service avait une grande capacité. Lorsque le nombre de connexions maximales était trop élevé, les serveurs devenaient lents et ne répondaient plus. Lorsque le nombre de connexions maximales était parfaitement réglé pour une charge de travail donnée, la charge de travail ou les performances de la dépendance changeaient. Les valeurs devenaient alors à nouveau incorrectes, entraînant des pannes et des surcharges évitables.
Au final, nous avons découvert que le concept de connexions maximales n'était pas assez précis et n'était pas la solution. Dans cet article, nous allons décrire d’autres approches utiles que nous avons découvertes, telles que le délestage.
L’anatomie d’une surcharge
Chez Amazon, nous évitons la surcharge en concevant nos systèmes pour qu'ils puissent se mettre à l'échelle de manière proactive, avant qu'ils ne se retrouvent en surcharge. Cependant, les systèmes nécessitent une protection en couches, ce qui commence par la mise à l'échelle automatique, mais inclut également des mécanismes pour éliminer la charge excédentaire, la capacité à surveiller ces mécanismes et, surtout, des tests en continu.
Lorsque nous avons testé la charge de nos services, nous avons découvert que la latence d'un serveur à faible utilisation était plus basse que sa latence à utilisation élevée. Sous des surcharges, les conflits de threads, les changements de contexte, le nettoyage de la mémoire et les conflits d'E/S s'intensifiaient. Les services finissaient par atteindre un point d'inflexion où leurs performances commençaient à se dégrader encore plus rapidement.
La théorie derrière ces observations est connue sous le nom de Loi de l'évolutivité universelle, dérivée de la Loi d'Amdahl. Selon cette théorie, même si le débit d'un système peut augmenter grâce à la parallélisation, il sera toujours au final limité par le débit des points de sérialisation (c'est-à-dire par les tâches qui ne peuvent pas être parallélisées).
Malheureusement, non seulement le débit est limité par les ressources d'un système, mais il se dégrade généralement lorsque le système est surchargé. Lorsqu'un système reçoit plus de travail que ses ressources ne peuvent en prendre en charge, il devient lent. Les ordinateurs prennent du travail même lorsqu'ils sont surchargés, mais ils passent plus de temps à changer de contexte et deviennent inutiles, car trop lents.
Dans un système distribué où un client communique avec un serveur, le client tend à s'impatienter et à arrêter d'attendre la réponse du serveur après un certain temps. Cette durée est appelée « délai ». Lorsqu'un serveur est tellement surchargé que sa latence dépasse le délai de son client, les requêtes commencent à échouer. Le graphique suivant montre comment le temps de réponse des serveurs augmente lorsque le débit fourni (en transactions par seconde) augmente, et que le temps de réponse finit par atteindre un point d’inflexion où la situation se détériore rapidement.
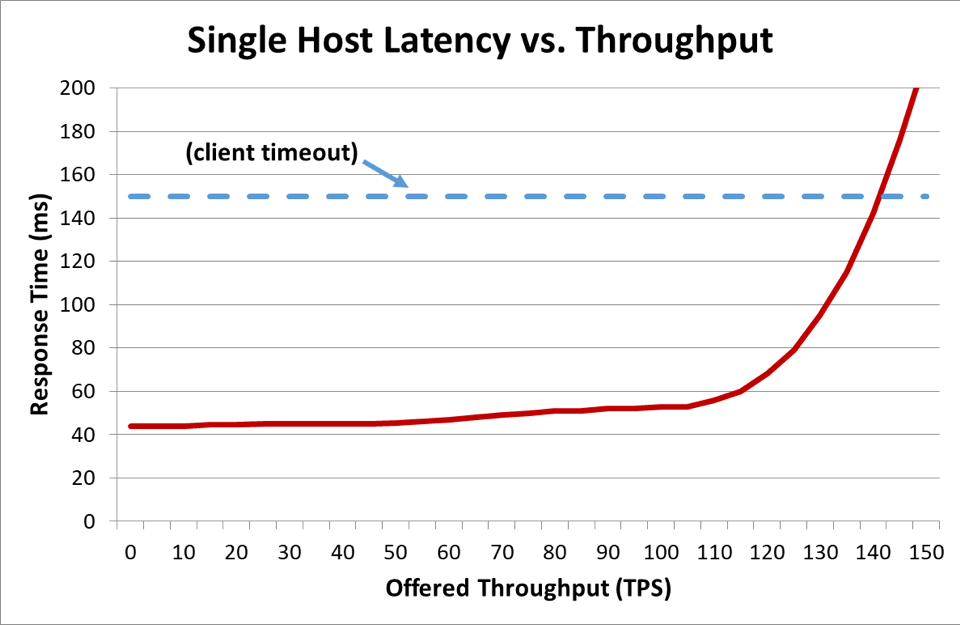
Dans le graphique ci-dessus, il est clair que quelque chose ne va pas lorsque le temps de réponse dépasse le délai client, mais on ne sait pas dans quelle mesure. Pour le montrer, nous pouvons tracer la disponibilité perçue par le client le long du tracé de la latence. Au lieu d'utiliser une mesure de temps de réponse générique, nous pouvons utiliser un temps de réponse médian. Le temps de réponse médian signifie que 50 % des requêtes ont été plus rapides que la valeur médiane. Si la latence médiane du service est égale au délai client, la moitié des requêtes ont dépassé le délai et la disponibilité est donc de 50 %. Ainsi, l'augmentation d'une latence transforme un problème de latence en problème de disponibilité. Voici un graphique de ce qu’il se passe :
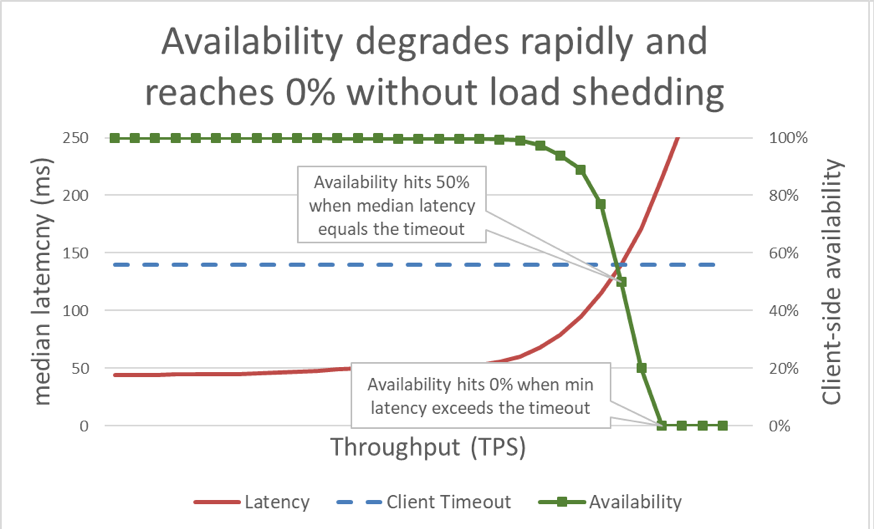
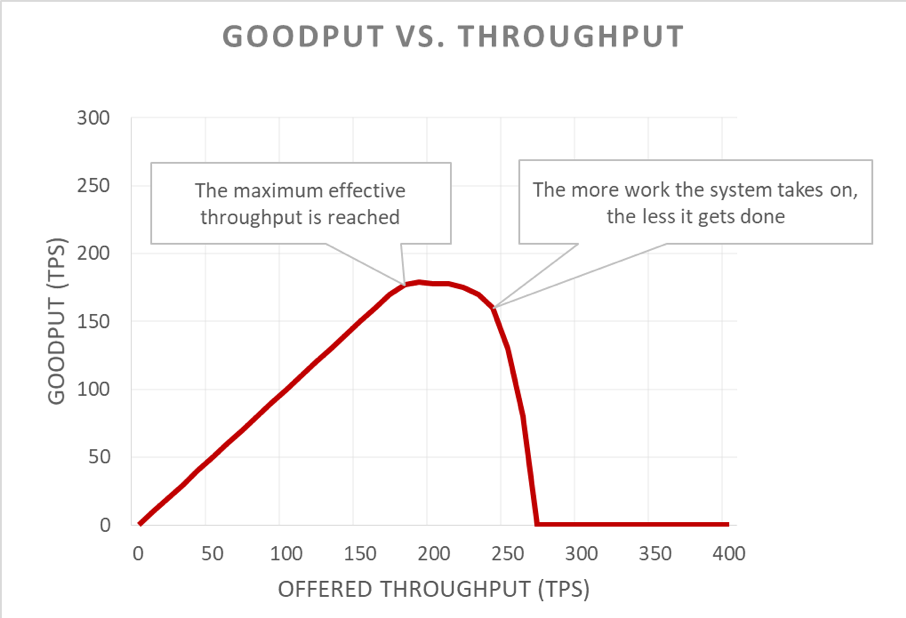
Malheureusement, ce graphique est difficile à lire. Nous pouvons décrire plus simplement le problème de disponibilité en distinguant le débit utile du débit. Le débit est le nombre total de requêtes par seconde que le serveur reçoit. Le débit utile est la partie du débit qui est traitée sans erreurs et avec une latence assez basse pour que le client puisse profiter de la réponse.
Boucles de rétroaction positives
La partie insidieuse d'une situation de surcharge est son amplification en boucle de rétroaction. Lorsque le délai client expire, le client reçoit une erreur, ce qui est négatif. Pire encore, tous les progrès réalisés par le serveur jusqu'alors pour répondre à la requête sont perdus. Et dans une situation de surcharge, où la capacité est limitée, il ne faut surtout pas qu'un système perde le travail effectué.
En outre, la situation empire lorsque le client tente de renvoyer sa requête, ce qui est souvent le cas. Ainsi, la charge fournie sur le système multiplie. Et si une architecture axée sur les services a un graphe d'appel assez poussé (c'est-à-dire qu'un client appelle un service, qui appelle d'autres services, qui appellent à leur tour d'autres services) et que chaque couche effectue un certain nombre de tentatives, une surcharge sur la couche de fond entraîne des tentatives en cascade, amplifiant ainsi la charge fournie de manière exponentielle.
Lorsque ces facteurs sont combinés, la surcharge crée sa propre boucle de rétroaction et le système entre dans un état de surcharge permanent.
Éviter la perte du travail
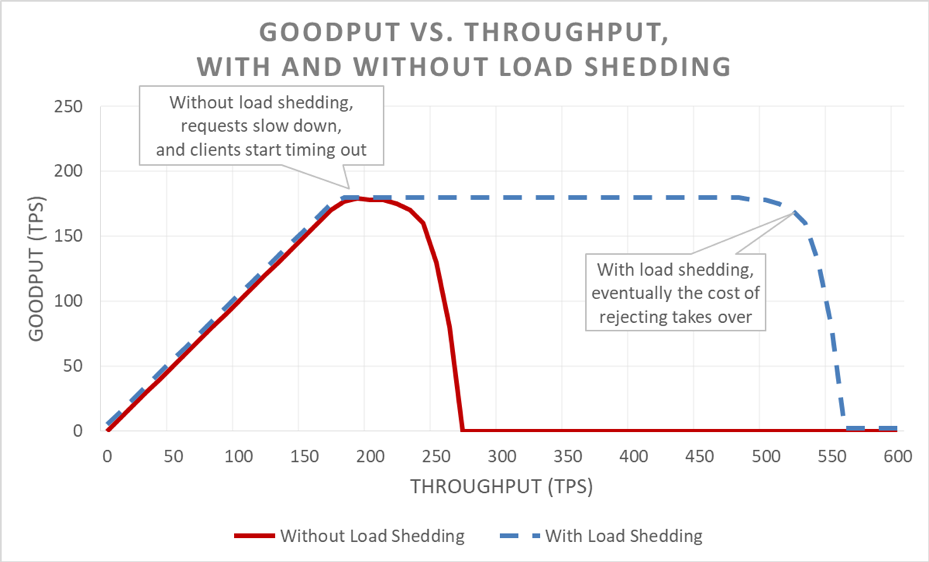
Le délestage est simple en apparence. Lorsqu'un serveur est presque en surcharge, il est censé rejeter les demandes excédentaires afin de pouvoir se concentrer sur les requêtes qu'il décide de recevoir. Le but du délestage est de conserver une latence faible pour les requêtes que le serveur décide d'accepter, de manière à ce que ce dernier réponde avant le délai client. Avec cette approche, le serveur garde une disponibilité élevée pour les requêtes qu’il accepte, et seule la disponibilité du trafic excédentaire est affectée.
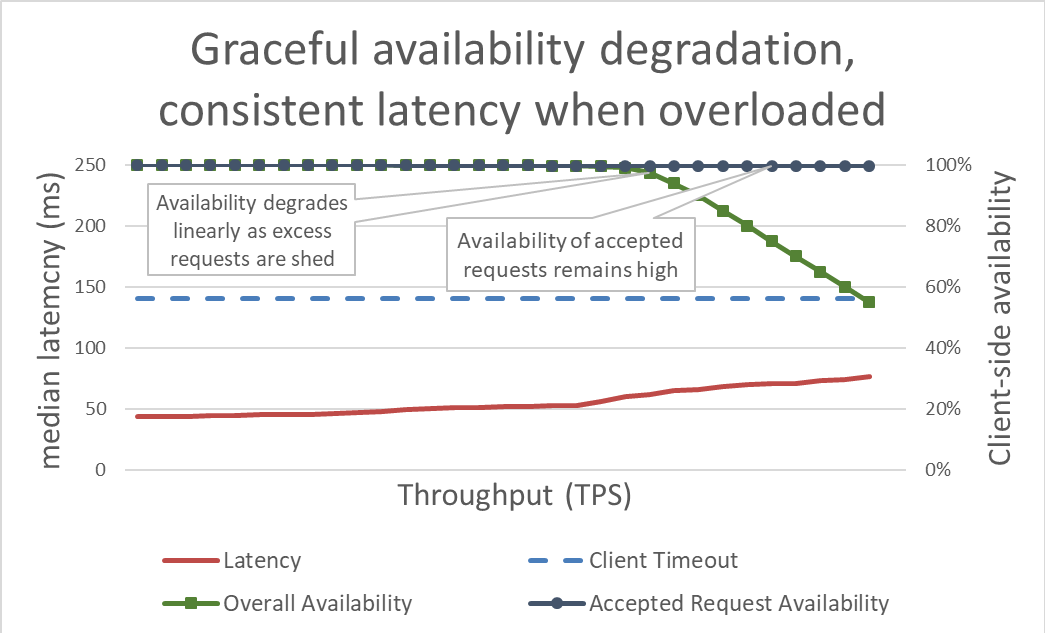
Avec une latence sous contrôle grâce au délestage de l’excédent, le système est plus disponible. Cependant, les avantages de cette approche sont difficiles à voir dans le graphique précédent. La ligne de la disponibilité générale tend à baisser, ce qui peut sembler être mauvais signe. L'essentiel est que les requêtes que le serveur a décidé d'accepter restent disponibles parce qu'elles ont été servies rapidement.
Le délestage permet au serveur de garder un bon débit utile et de compléter autant de requêtes que possible, même lorsque le débit fourni augmente. Toutefois, l’action de délestage n’est pas gratuite, donc le serveur finit par tomber dans la loi d’Amdahl et son débit utile chute.
Test
Lorsque je parle du délestage à d'autres ingénieurs, je souligne généralement le fait que s'ils n'ont pas testé la charge de leur service jusqu'au point de rupture et bien au-delà, ils devraient considérer que le service échouera de la pire manière possible. Chez Amazon, nous passons énormément de temps à tester la charge de nos services. Générer des graphiques comme ceux précédemment présentés dans cet article nous aide à comprendre les performances de surcharge et à suivre les conséquences des changements apportés à nos services au fil du temps.
Il existe de multiples types de tests de charge. Certains tests de charge s'assurent qu'une flotte se met automatiquement à l'échelle lorsque la charge augmente, alors que d'autres utilisent une taille de flotte fixe. Si dans un test de surcharge, la disponibilité d'un serveur se dégrade rapidement et arrive à zéro alors que le débit augmente, c'est un signe fiable que le service nécessite des mécanismes de délestage supplémentaires. Le résultat idéal d'un test de charge est lorsque le débit atteint un plateau alors que le service est presque totalement utilisé, et qu'il reste stable même lorsque du débit est ajouté.
Les outils comme Chaos Monkey aident à effectuer des tests techniques de chaos sur des services. Par exemple, ils peuvent surcharger le CPU ou introduire une perte de paquets pour simuler les conditions de surcharge. Une autre technique de test que nous utilisons consiste à prendre un test ou un canary de génération de test existante, commander une charge constante (plutôt qu'une charge croissante) vers un environnement de test, mais commencer à retirer les serveurs de cet environnement de test. De cette manière, nous augmentons le débit fourni par instance et testons ainsi le débit d'instance. Cette technique d'augmentation artificielle de la charge en diminuant les tailles de flottes est utile pour tester un service isolé, mais ne remplace pas totalement les tests de charge complets. Un test de charge complet de bout en bout augmente également la charge des dépendances du service, dévoilant ainsi parfois d'autres goulots d'étranglement.
Au cours des tests, nous nous assurons de mesurer la disponibilité et la latence perçues par le client, en plus de la disponibilité et de la latence côté serveur. Lorsque la disponibilité côté client commence à augmenter, nous poussons la charge bien au-delà de ce point. Si le délestage fonctionne, le débit utile reste stable, même lorsque le débit fourni dépasse largement les disponibilités mises à l'échelle du service.
Il est indispensable de tester les charges avant d'explorer des mécanismes pour éviter les surcharges. Chaque mécanisme ajoute de la complexité. Par exemple, pensez à toutes les options de configuration des cadres de service que j'ai mentionnées au début de l'article, et à la difficulté de trouver les bonnes valeurs par défaut. Chaque mécanisme destiné à éviter les surcharges ajoute différentes protections et présente une efficacité limitée. À travers les tests, les équipes peuvent détecter les goulots d’étranglement de leurs systèmes et déterminer les combinaisons de protection nécessaires pour gérer les surcharges.
Visibilité
Chez Amazon, quelles que soient les techniques que nous utilisons pour protéger nos services contre la surcharge, nous réfléchissons attentivement aux métriques et à la visibilité dont nous avons besoin lorsque ces mesures contre la surcharge prennent effet.
Lorsque la protection contre la baisse de tension rejette une requête, la disponibilité du service diminue. Lorsqu'un service perçoit mal sa disponibilité et rejette une requête alors qu'il a assez de disponibilité (par exemple, lorsque le nombre de connexions maximales est défini trop bas), il génère un faux positif. Nous nous efforçons de maintenir le taux de faux positifs des services à zéro. Si une équipe découvre que le taux de faux positifs de son service est souvent supérieur à zéro, soit le service est mal configuré, soit les hôtes sont constamment et légitimement surchargés, ce qui peut cacher un problème d'équilibre de charge ou de mise à l'échelle. Dans ce type de situation, il faut modifier les performances d'application ou passer à des types d'instances plus grandes qui peuvent gérer les déséquilibres de charge plus facilement.
En matière de visibilité, lorsque le délestage rejette des requêtes, nous nous assurons d'avoir les bons instruments pour savoir qui était le client, quelle était l'opération appelée et toute autre information pouvant nous aider à améliorer nos mesures de protection. Nous utilisons également des alarmes pour détecter si les contre-mesures rejettent des volumes de trafic importants. En cas de baisse de tension, notre priorité est d'ajouter de la capacité et de traiter le goulot d'étranglement actuel.
Il y a un autre aspect subtile mais important à prendre en compte en ce qui concerne la visibilité dans le délestage. Nous avons découvert qu'il est important de ne pas polluer les métriques de latence de nos services avec une latence de requêtes échouées. Après tout, la latence de délestage d'une requête devrait être bien inférieure à celle d'autres requêtes. Par exemple, si le délestage d'un service représente 60 % de son trafic, la latence médiane du service peut sembler très bonne, même si sa latence de requêtes réussies est très mauvaise, parce qu'elle est sous-évaluée en raison des requêtes en échec rapide.
Effets du délestage sur la mise à l'échelle automatique et les échecs de zone de disponibilité
S'il est mal configuré, le délestage peut désactiver la mise à l'échelle automatique réactive. Imaginons l'exemple suivant : un service est configuré pour une mise à l'échelle réactive basée sur le CPU et présente également un délestage configuré pour rejeter les requêtes à une cible CPU similaire. Dans ce cas, le système de délestage réduit le nombre de requêtes pour conserver une charge CPU basse, et la mise à l'échelle réactive ne recevra ou n'obtiendra jamais un signal retardé pour lancer de nouvelles instances.
Nous faisons également attention à prendre en compte la logique de délestage lorsque nous définissons des limites de mise à l'échelle automatique pour la prise en charge des échecs de zone de disponibilité. Les services sont mis à l'échelle au point qu'une zone de disponibilité avec les bonnes capacités peut devenir indisponible tout en conservant nos objectifs de latence. Les équipes Amazon voient souvent les métriques de système comme des CPU pour estimer à quel point un service s'approche de sa limite de capacité. Cependant, avec le délestage, une flotte peut bien plus s'approcher du point où les requêtes doivent être rejetées que ce que le système indique, et peut ne pas avoir la capacité excédentaire fournie pour gérer un échec de zone de disponibilité. Avec le délestage, nous devons nous assurer avec certitude de tester nos services à la panne pour comprendre la capacité et l'espace libre de notre flotte à tout moment.
En fait, nous pouvons utiliser le délestage pour réduire les coûts en façonnant un trafic en période creuse et non essentiel. Par exemple, si une flotte gère un trafic de site Web pour amazon.com, elle peut décider que le trafic d'analyse de recherche ne vaut pas le coût de mise à l'échelle pour une redondance de zone de disponibilité complète. Cependant, nous faisons très attention avec cette approche. Toutes les requêtes n'ont pas le même coût, et prouver qu'un service devrait fournir une redondance de zone de disponibilité pour le trafic humain et pour le délestage le trafic d'analyse de recherche excédentaire en même temps nécessite une conception attentive, un test en continu et doit être accepté par l'entreprise. Or, si les clients d'un service ne savent pas qu'un service est configuré ainsi, son comportement en cas d'échec de zone de disponibilité pourrait ressembler à une grave chute massive de disponibilité au lieu d'un délestage de charge non critique. Pour cette raison, dans une architecture axée sur les services, nous essayons de pousser ce type de conception aussi tôt que possible (comme dans le service qui reçoit la requête initiale de la part du client) au lieu d’essayer de prendre des décisions de priorité globales à travers la pile.
Mécanismes de délestage
En ce qui concerne le délestage et les scénarios imprévisibles, il est également important de se concentrer sur les nombreuses conditions prévisibles qui mènent à la baisse de tension. Chez Amazon, les services conservent assez de capacité pour gérer les échecs de zone de disponibilité sans avoir à ajouter davantage de capacité. Ils utilisent les limitations pour garantir une équité parmi les clients.
Cependant, malgré ces protections et ces pratiques opérationnelles, les services ont une certaine capacité à des moments donnés, et peuvent donc devenir surchargés pour de nombreuses raisons. Ces raisons incluent les hausses de trafic inattendues, les pertes soudaines de capacité de flotte (dues à des mauvais déploiements ou non), des clients qui passent de requêtes peu onéreuses (comme les lectures en cache) à des requêtes onéreuses (comme les défauts ou les écritures de cache). Lorsqu'un service devient surchargé, il doit terminer les requêtes qu'il a prises. Autrement dit, les services doivent se protéger des baisses de tension. Dans la suite de cette rubrique, nous allons aborder quelques facteurs et techniques que nous avons utilisés au fil des années pour gérer les surcharges.
Comprendre les coûts des requêtes abandonnées
Nous nous assurons de tester la charge de nos services bien au-delà du point où le débit utile atteint un plateau. L'une des principales motivations de cette approche est de nous assurer que lorsque nous abandonnons des requêtes lors d'un délestage, le coût de cet abandon soit le plus bas possible. Nous avons vu qu'il était facile de rater un relevé de journal ou un réglage de socket accidentel, pouvant entraîner un abandon de requête bien plus cher que ce qu'il ne devrait.
Dans de rares cas, abandonner une requête rapidement peut être plus cher que de la conserver. Dans ces cas, nous ralentissons les requêtes rejetées pour correspondre (au minimum) à la latence des réponses réussies. Cependant, il est important de le faire lorsque le coût de conservation des requêtes est aussi bas que possible, par exemple, lorsqu'elles n'attachent pas un thread d'application.
Priorités des requêtes
Lorsqu'un serveur est surchargé, il a la possibilité de trier les requêtes entrantes pour décider lesquelles accepter et lesquelles rejeter. La requête la plus importante qu'un serveur peut recevoir est une requête de ping de la part d'un équilibreur de charge. Si le serveur ne répond pas à temps aux requêtes de ping, l'équilibreur de charge arrête d'envoyer de nouvelles requêtes au serveur pendant un certain temps, et le serveur n'est pas utilisé. En cas de baisse de tension, il faut absolument éviter de réduire la taille de nos flottes. Au-delà des requêtes de ping, les options de priorité des requêtes varient d'un service à l'autre.
Imaginons un service Web qui fournit des données pour rendre amazon.com. Un appel de service qui prend en charge le rendu de page Web pour une analyse d'index de recherche sera probablement moins essentiel qu'une requête en provenance d'un humain. Il est important de répondre aux requêtes d'analyse, mais en principe, elles peuvent déplacées vers une période creuse. Cependant, dans un environnement complexe comme amazon.com où de nombreux services coopèrent, si les services utilisent l'heuristique de priorité conflictuelle, la disponibilité à l'échelle du système pourrait être affectée et le travail pourrait être perdu.
La priorité et les limitations peuvent être utilisées ensemble pour éviter les plafonds de limitations strictes tout en protégeant quand même un service contre la surcharge. Chez Amazon, lorsque nous permettons à nos clients de dépasser leurs limitations configurées, la priorité des requêtes de ces clients peut être baissée pus bas que les requêtes dans les quotas des autres clients. Nous dédions beaucoup de temps aux algorithmes de placement pour minimiser les probabilités qu'une capacité de pointe devienne indisponible, mais au vu des compromis, nous favorisons les surcharges fournies prévisibles par rapport aux surcharges imprévisibles.
Surveiller l'horloge
Si un service est à mi-chemin de répondre à une requête et qu'il remarque que le délai client est dépassé, il peut ignorer le reste du travail et échouer la requête à ce moment-là. Sinon, le serveur continue de travailler sur la requête et sa réponse tardive ne servira à rien. Du point de vue du serveur, sa réponse est réussie. Mais du point de vue du client, dont le délai est dépassé, il s'agit d'une erreur.
Il est possible d'éviter de perdre ce travail en permettant au client d'inclure des notes dans chaque requête afin d'indiquer au serveur combien de temps il est prêt à attendre. Le serveur peut évaluer ces notes et abandonner des requêtes vouées à l'échec à moindre coût.
Ces notes de délai peuvent être exprimées en heure absolue ou en durée. Malheureusement, nous savons par expérience que les serveurs des systèmes distribués ne savent pas se mettre d'accord sur l'heure qu'il est actuellement. Le service de synchronisation temporelle d’Amazon compense ce problème en synchronisant les horloges de vos instances Amazon Elastic Compute Cloud (Amazon EC2) avec une flotte d’horloges redondantes commandées par satellite et atomiques dans chaque région AWS. Il est important d'avoir des horloges bien synchronisées chez Amazon, notamment pour des raisons de journalisation. Comparer deux fichiers de journalisation sur des serveurs dont les horloges ne sont pas synchronisées rend la résolution encore plus dure qu'elle ne l'est.
Une autre façon de « surveiller l'horloge » consiste à mesurer une durée sur une seule machine. Les serveurs savent bien mesurer les durées écoulées localement parce qu'ils n'ont pas besoin de se mettre d'accord avec d'autres serveurs. Malheureusement, exprimer des délais en termes de durée présente des problèmes également. Tout d'abord, le minuteur utilisé doit être monotone et ne pas revenir en arrière lorsque le serveur se synchronise avec le protocole de temps réseau (NTP). Le problème bien plus difficile à résoudre est que pour mesurer une durée, le serveur doit savoir quand démarrer un chronomètre. Dans certaines situations de surcharge extrême, des volumes considérables de requêtes peuvent faire la queue dans des tampons Transmission Control Protocol (TCP). Par conséquent, le délai client est dépassé avant que le serveur lise les requêtes de ses tampons.
Dès lors que les systèmes chez Amazon expriment des notes de délai client, nous essayons de les appliquer transitivement. Lorsqu'une architecture axée sur les services incluent plusieurs sauts, nous diffusons le « temps restant » entre chaque saut pour qu'un service en aval à la fin d'une chaîne d'appel sache combien de temps il lui reste pour que sa réponse soit utile.
Une fois que le serveur connaît le délai client, il faut savoir où appliquer le délai dans l'implémentation du service. Si un service a une file d'attente de requêtes, nous en profitons pour évaluer le délai après avoir retiré chaque requête de la file d'attente, ce qui reste compliqué, car nous ne savons pas combien de temps les requêtes sont censées prendre. Certains systèmes gardent une estimation de la durée nécessaire pour répondre aux requêtes d'API, et ils abandonnent les requêtes tôt si le délai signalé par le client dépasse l'estimation de latence. En réalité, les choses sont rarement aussi simples. Par exemple, les cache-miss sont bien plus rapides que les défauts de cache, et l'estimateur ne sait pas s'il est face à un cache-miss ou à un défaut de cache. Autre exemple, les ressources backend d'un service peuvent être partitionnées, avec seulement quelques partitions lentes. Avec un peu d'ingéniosité, les solutions sont nombreuses, mais cette ingéniosité peut également engendrer des situations imprévisibles.
D'après notre expérience, appliquer des délais clients sur le serveur est bien mieux que l'autre solution, malgré les complexités et les compromis. Plutôt que d'accumuler les requêtes et de faire travailler le serveur sur des requêtes qui n'ont plus aucune utilité, nous avons jugé utile d'appliquer une « vie par requête » et d'abandonner des requêtes vouées à l'échec.
Finir ce qui a été commencé
Nous ne voulons pas perdre le travail utile, surtout en situation de surcharge. Abandonner le travail crée une boucle de rétroaction positive qui augmente la surcharge, étant donné que les clients retentent souvent les requêtes lorsqu'un service ne répond pas à temps. Lorsque cela se produit, une requête qui consomme beaucoup de ressources se transforme en de nombreuses requêtes qui consomment beaucoup de ressources, multipliant ainsi la charge sur le service. Lorsque les délais clients sont dépassés et que les clients tentent une nouvelle requête, ils arrêtent souvent d'attendre une réponse sur leur première connexion alors qu'ils effectuent une nouvelle requête sur une connexion séparée. Si le serveur termine la première requête et répond, le client peut ne pas écouter, parce qu'il attend maintenant une réponse de sa deuxième tentative de requête.
Ce problème de travail perdu explique pourquoi nous concevons des services pour effectuer un travail limité. Lorsque nous exposons une API qui peut renvoyer un large ensemble de données (ou n'importe quelle liste), nous l'exposons comme une API qui prend en charge la pagination. Ces API renvoient des résultats partiels et un jeton que le client peut utiliser pour demander plus de données. Nous trouvons cela plus facile d'estimer la charge supplémentaire sur un service lorsque le serveur gère une requête dont la limite est plus élevée que la quantité de bande passante de mémoire, de CPU et de réseau. Effectuer un contrôle des admissions est très difficile lorsqu'un serveur n'a aucune idée du temps nécessaire pour traiter une requête.
Il est possible de donner la priorité à des requêtes plus subtilement à travers l'utilisation des API du service par les clients. Par exemple, imaginons qu'un service a deux API : start() et end(). Pour terminer leur travail, les clients doivent pouvoir appeler les deux API. Dans ce cas, le service doit donner la priorité aux requêtes end() plutôt qu'aux requêtes start(). S'il donnait la priorité aux requêtes start(), les clients ne pourraient pas terminer le travail commencé, entraînant ainsi des baisses de tension.
La pagination est une autre façon de surveiller le travail perdu. Si un client doit effectuer plusieurs requêtes séquentielles pour paginer à travers les résultats d'un service, et qu'il voit un échec après page N-1 et abandonne les résultats, il perd les appels de service N-2 et toutes les tentatives qu'il a pu effectué en chemin. Cela suppose que tout comme les requêtes end(), les requêtes en première page devraient être moins prioritaires que les requêtes de pagination de pages suivantes. Cela souligne également pourquoi nous concevons des services pour effectuer un travail limiter et ne pas paginer sans fin à travers un service appelé pendant une opération de synchronisation.
Surveiller les files d'attente
Il est également utile de regarder la durée des requêtes lors de la gestion de files d'attente internes. De nombreuses architectures de service modernes utilisent des files d'attente en mémoire pour connecter des groupes de threads afin qu'ils traitent des requêtes à différentes étapes de travail. Un cadre de service Web avec un exécuteur se retrouvera probablement face à une file d'attente configurée. Avec n'importe quel service basé sur TCP, le système d'exploitation conserve un tampon pour chaque socket, et ces tampons peuvent contenir un volume très important de requêtes accumulées.
Lorsque nous retirons du travail des files d'attente, nous en profitons pour examiner la durée pendant laquelle le travail est resté dans la file d'attente. Au minimum, nous essayons d'enregistrer cette durée dans nos métriques de service. Outre la limitation de la taille des files d'attente, nous pensons qu'il est extrêmement important de définir une limitation de temps qu'une requête entrante peut rester dans une file d'attente avant que nous ne l'abandonnions. Ainsi, le serveur est libéré et peut travailler sur les nouvelles requêtes qui ont plus de chance d'être réussies. Pour pousser cette approche encore plus loin, si le protocole peut la prendre en charge, nous recherchons des manières d'utiliser une file d'attente dernier arrivé, premier sorti (LIFO) à la place. (Le traitement en pipeline HTTP/1.1 des requêtes sur une connexion TCP donnée ne prend pas en charge les files d'attente LIFO, mais le traitement en pipeline HTTP/2 le fait généralement.)
Les équilibreurs de charge peuvent également mettre en file d'attente des requêtes ou des connexions lorsque les services sont surchargés, à l'aide de la fonction surge queues (files d'attente surchargées). Ces files d'attente peuvent entraîner une baisse de tension, car lorsqu'un serveur obtient enfin une requête, il n'a aucune idée du temps que la requête a passé dans la file d'attente. Une mesure généralement sûre consiste à utiliser une configuration de débordement, qui effectue des échecs rapidement plutôt que de mettre d'ajouter des requêtes excédentaires à la queue. Chez Amazon, cette découverte a été réutilisée dans la génération suivante du service Elastic Load Balancing (ELB). L'équilibreur Classic Load Balancer utilisait une file d'attente surchargée, mais l'Équilibreur de charge d'application rejette le trafic excédentaire. Indépendamment de la configuration, les équipes Amazon surveillent les métriques d'équilibreur de charge pertinentes, comme la profondeur de files d'attente surchargées ou le nombre de débordements, pour leurs services.
D'après notre expérience, l'importance de surveiller les files d'attente ne peut pas être surestimée. Je suis souvent étonné de voir des files d'attente en mémoire que je n'aurais pas pensé à chercher instinctivement, dans les systèmes et les bibliothèques dont je dépends. Lors que je fouille dans les systèmes, je trouve utile de supposer qu'il existe des files d'attente, quelque part, dont je ne connais pas l'existence. Bien sûr, les tests de surcharge me fournissent plus d'informations utiles que la fouille de code, tant que je trouve les bons cas de test réalistes.
Protection contre la surcharge dans les couches inférieures
Les services sont constitués de plusieurs couches, en allant des équilibreurs de charge aux systèmes d'exploitation avec des capacités netfilter et iptables, en passant par les cadres de service et le code, et chaque couche fournit une certaine capacité pour protéger le service.
Les proxys HTTP comme NGINX prennent souvent en charge une fonction de connexions maximales (max_conns) pour limiter le nombre de requêtes ou de connexions actives à transmettre au serveur backend. Ce mécanisme peut être utile, mais nous avons appris à l'utiliser en dernier recours plutôt qu'en option de protection par défaut. Avec les proxys, il est difficile de donner la priorité au trafic important, et le suivi du nombre de requêtes brutes en vol fournit parfois des informations erronées quant à la surcharge d'un service.
Au début de cet article, je vous ai présenté la difficulté que j'avais rencontrée lorsque je travaillais dans l'équipe des Cadres de service. Nous essayions de fournir aux équipes Amazon une valeur par défaut recommandée de connexions maximale à configurer pour leurs équilibreurs de charge. Au final, nous avons proposé à nos équipes de définir un nombre maximal élevé de connexions pour leur équilibreur de charge et proxy et de laisser le serveur implémenter des algorithmes de délestage plus précis avec des informations locales. Cependant, il fallait que la valeur du nombre maximal de connexions ne dépasse pas le nombre de threads d'écouteurs, de processus d'écouteurs ou de descripteurs de fichier sur un serveur, pour que le serveur ait les ressources nécessaires pour gérer les requêtes de vérification de l'état essentielles provenant de l'équilibreur de charge.
Les fonctions des systèmes d'exploitation pour limiter l'utilisation des ressources des serveurs sont puissantes et peuvent être utiles en cas d'urgence. Et parce que nous savons que des situations de surcharge peuvent arriver, nous nous assurons de nous y préparer à l'aide des runbooks appropriés avec des commandes spécifiques sous la main. L'utilitaire iptables peut ajouter une limitation du nombre maximal de connexions acceptées par le serveur et peut rejeter les connexions excédentaires à un coût bien plus bas que n'importe quel processus de serveur. Il peut également être configuré avec davantage de contrôles sophistiqués, tels que l'autorisation de nouvelles connexions à un taux limité, voire même l'autorisation d'un taux de connexions limité ou le calcul du nombre d'adresses IP sources. Les filtres d'IP source sont puissants, mais ne s'appliquent pas aux équilibreurs de charge traditionnels. Cependant, un équilibreur Network Load Balancer ELB conserve l'IP source du mandataire, même au niveau de la couche du système d'exploitation à travers la virtualisation réseau, ce qui permet aux règles d'iptables comme les filtres d'IP sources de fonctionner comme prévu.
Protéger les couches
Dans certains cas, un serveur n'a plus assez de sources pour rejeter des requêtes sans ralentir. En sachant cela, nous recherchons les sauts entre un serveur et ses clients pour voir comment ils peuvent coopérer et permettre l'abandon de la charge excédentaire. Par exemple, plusieurs services AWS incluent des options de délestage par défaut. Lorsque nous sommes face à un service avec Amazon API Gateway, nous pouvons configurer un taux de requêtes maximales que n'importe quelle API acceptera. Lorsque nos services sont menés par une passerelle d'API, un Équilibreur de charge d'application ou à Amazon CloudFront, nous pouvons configurer AWS WAF pour abandonner le trafic excédentaire dans plusieurs dimensions.
La visibilité crée une tension difficile. Le rejet précoce est important, car c'est le moyen le plus économique d'abandonner le trafic excédentaire, mais il coûte en visibilité. C'est pourquoi nous protégeons les couches : pour laisser un serveur prendre plus de travail et abandonner l'excédent, et journaliser assez d'informations pour savoir quel trafic il abandonne. Étant donné qu’un serveur peut abandonner beaucoup de trafic, nous comptons sur la couche placée devant pour le protéger des volumes de trafic extrêmes.
Voir la surcharge autrement
Dans cet article, nous avons vu comment la nécessité de délestage apparaît lorsque les systèmes deviennent plus lents parce qu'ils ont davantage de travail simultané, tandis que des forces comme des limites et des conflits de ressources entrent en jeu. La boucle de rétroaction de surcharge est gérée par la latence, qui finit par entraîner une perte de travail, une amplification du taux de requêtes et même avantage de surcharge. Cette force, commandée par la loi de mise à l'échelle universelle et par la loi d'Amdahl, est importante à éviter en délestant l'excédent et en conservant des performances prévisibles et cohérentes en présence d'une surcharge. Se concentrer sur des performances prévisibles et cohérentes est un principe de conception clé sur lequel les services Amazon sont construits.
Par exemple, Amazon DynamoDB est un service de base de données qui fournit des performances prévisibles et une disponibilité à l'échelle. Même si une charge de travail explose rapidement et dépasse les ressources fournies, DynamoDB conserve une latence de débit utile prévisible pour cette charge de travail. Les facteurs comme DynamoDB autoscaling, la capacité adaptative et à la demande réagissent rapidement pour augmenter les taux de débit utile afin de s’adapter à une charge de travail. Pendant ce temps, le débit utile reste stable, conservant ainsi un service dans les couches au-dessus de DynamoDB avec des performances prévisibles également et améliorant la stabilité du système tout entier.
AWS Lambda fournit un exemple encore plus large de l'attention à apporter aux performances prévisibles. Lorsque nous utilisons Lambda pour implémenter un service, chaque appel d'API s'exécute dans son propre environnement d'exécution avec des quantités cohérentes de ressources de calcul qui lui sont allouées, et cet environnement d'exécution travaille uniquement sur une requête à la fois. Dans le paradigme basé sur serveur, en revanche, un serveur donné travaille sur plusieurs API.
Isoler chaque appel d'API à ses propres ressources indépendantes (calcul, mémoire, disque, réseau) contournera la loi d'Amdahl d'une façon ou d'une autre, car les ressources d'un appel d'API ne feront pas face aux ressources d'un autre appel d'API. Par conséquent, si le débit dépasse le débit utile, ce dernier restera stable au lieu de chuter comme il le fait dans un environnement plus traditionnel basé sur le serveur. Ce n'est pas une solution miracle, étant donné que les dépendances peuvent ralentir et entraîner l'augmentation de travail simultané. Cependant, dans ce scénario, au moins les types de conflits de ressources sur hôte que nous avons abordés dans cet article ne s'appliquent pas.
L'isolement de ressource est en quelque sorte subtile, mais constitue un avantage important pour les environnements de calcul modernes et sans serveur comme AWS Fargate, Amazon Elastic Container Service (Amazon ECS) et AWS Lambda. Chez Amazon, nous avons découvert que l'implémentation du délestage nécessite beaucoup de travail, de la configuration des groupes de threads à la sélection de la configuration parfaite du nombre de connexions maximales d'équilibreur de charge. Les bonnes valeurs par défaut pour ces types de configurations sont difficiles voire impossibles à trouver, car elles dépendant des caractéristiques opérationnelles propres à chaque système. Ces environnements de calcul modernes et sans serveur fournissent un isolement des ressources de niveau inférieur et exposent des nœuds de niveau supérieur, comme les limitations et les contrôles de simultanéité, pour se protéger contre la surcharge. En quelques sortes, au lieu de chercher la valeur de configuration par défaut idéale, nous pouvons complètement contourner cette configuration et nous protéger contre des catégories de surcharge sans aucune configuration.
Lectures complémentaires
- Loi universelle de capacité de mise à l’échelle
- Loi d’Amdahl
- Staged event-driven architecture (SEDA) (Architectures par étapes basées sur les événements [SEDA])
- Little’s law (loi de Little décrivant la simultanéité dans un système et comment déterminer la capacité des systèmes distribués)
- Telling Stories About Little’s Law (Témoignages sur la loi de Little), blog de Marc
- Elastic Load Balancing Deep Dive and Best Practices (Réflexion approfondie d’Elastic Load Balancing et bonnes pratiques), présentation à re:Invent 2016 (décrit l’évolution d’Elastic Load Balancing pour arrêter l’ajout de requêtes excédentaires dans les files d’attente)
- Burgess, Thinking in Promises: Designing Systems for Cooperation (Penser en promesses : concevoir les systèmes pour la coopération), O’Reilly Media, 2015
À propos de l’auteur
David Yanacek est ingénieur en chef senior et travaille sur AWS Lambda. David est développeur logiciel chez Amazon depuis 2006. Il a auparavant travaillé sur Amazon DynamoDB et AWS IoT, ainsi que sur les cadres de service Web internes et les systèmes d'automatisation d'opération des flottes. L’une des activités professionnelles préférées de David est d’effectuer des analyses de journaux et de parcourir des métriques opérationnelles dans le but de trouver des solutions pour que les systèmes s’exécutent de mieux en mieux au fil du temps.

Avez-vous trouvé les informations que vous recherchiez ?
Faites-nous part de vos commentaires afin que nous puissions améliorer le contenu de nos pages