Fonctions de périphérie
Présentation
Les fonctions de périphérie sont de puissants outils de développement qui permettent d'ajouter une logique personnalisée à la périphérie avec CloudFront. Les fonctions de périphérie permettent aux développeurs d'enrichir les applications Web tout en réduisant la latence et de créer des applications entièrement distribuées. Les fonctions de périphérie peuvent être utilisées pour :
- Implémenter une logique HTTP avancée. CloudFront vous fournit des règles natives telles que la redirection de HTTP vers HTTPs, le routage vers différentes origines en fonction du chemin de la requête, etc. Les fonctions de périphérie vous permettent d'aller au-delà des fonctionnalités natives de CloudFront pour implémenter une logique HTTP avancée telle que la normalisation des clés de cache, la réécriture des URL, les opérations HTTP CRUD, etc.
- Réduction de la latence des applications. Certaines logiques d'application peuvent être déchargées de l'origine vers la périphérie pour bénéficier de la mise en cache (par exemple, les tests A/B) ou pour être exécutées au plus près des utilisateurs (par exemple, les redirections HTTP, le raccourcissement d'URL, le rendu HTML). Dans une architecture à microservices ou à microfront, vous pouvez utiliser les fonctions de périphérie pour implémenter une logique commune (par exemple, autorisation et authentification) une fois au point d'entrée de l'application au lieu de l'implémenter séparément dans chaque composant.
- Protection de périmètre de l'application. Les fonctions de périphérie peuvent être utilisées pour appliquer des contrôles de sécurité tels que le contrôle d'accès et le blocage géographique avancé à la périphérie. Cela vous permet de réduire la surface d'attaque de votre point d'origine et de supprimer les coûts de mise à l'échelle inutiles.
- Routage des demandes. Vous pouvez utiliser les fonctions de périphérie pour acheminer chaque requête HTTP vers une origine spécifique en fonction de la logique de l’application. Cela peut être utile pour des scénarios tels que le basculement avancé, l’équilibrage de charge d’origine, les architectures multirégionales, les migrations, le routage des applications, etc.
Types de fonctions de périphérie avec CloudFront
CloudFront vous propose deux types de fonctions de périphérie : les Fonctions CloudFront et Lambda@Edge. Les fonctions CloudFront offrent des temps de démarrage inférieurs à une milliseconde et se mettent à échelle immédiatement pour traiter des millions de requêtes par seconde, ce qui les rend idéales pour une logique légère (normalisation du cache, réécriture d'URL, manipulation des demandes, autorisation, etc.). Lambda@Edge est une extension d'AWS Lambda, exécutée de manière distribuée dans les caches périphériques régionaux. Lambda@Edge offre une plus grande puissance de calcul et des fonctionnalités avancées telles que les appels réseau externes, mais pour un coût et une latence plus élevés. Cette documentation fournit des détails sur les différences entre les deux environnements d'exécution.
Les fonctions de périphérie peuvent être utilisées soit pour manipuler les requêtes et les réponses HTTP en vol, soit simplement pour mettre fin à des demandes et générer des réponses au lieu de les acheminer en amont dans CloudFront. Les fonctions de périphérie peuvent être configurées pour être exécutées lors de différents événements au cours du cycle de vie d'une requête sur CloudFront :
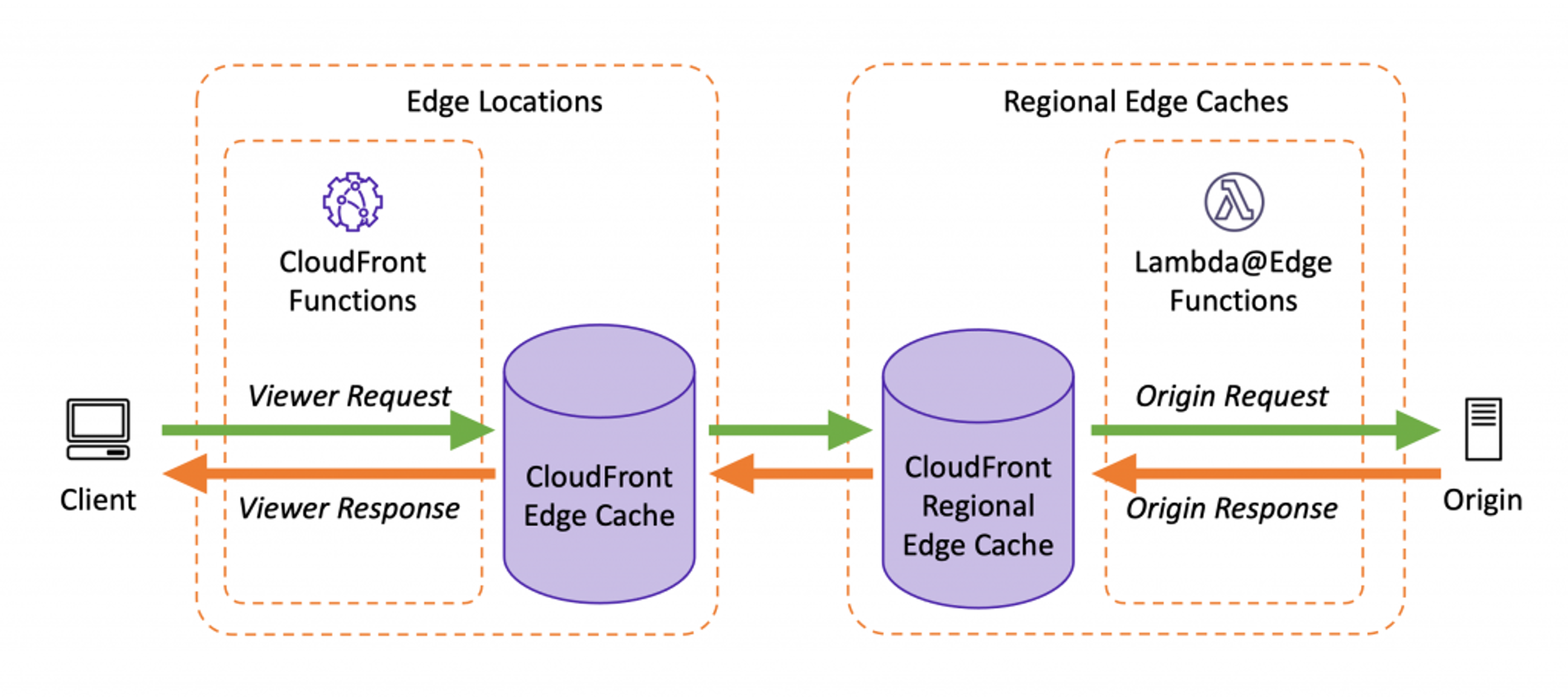
- Événements du visualiseur : exécutés pour chaque requête, avant de vérifier le cache de CloudFront. Idéal pour la normalisation du cache, l'autorisation ou le placement de cookies uniques. Les fonctions CloudFront ne sont autorisées que sur les événements des spectateurs.
- Événements d’origine : exécutés en cas d’échec du cache, avant d’aller à l’origine pour récupérer les fichiers. Idéal pour générer du contenu ou manipuler des réponses avant de le mettre en cache.
Gardez en tête les pratiques exemplaires ci-dessous :
- Associez une fonction de périphérie au comportement de cache le plus spécifique, afin d’éviter des coûts d’exécution inutiles.
- Utilisez le mode d’exécution de la fonction de périphérie le plus optimal pour votre cas. Par exemple, si votre logique peut être implémentée à l’aide des Fonctions CloudFront ou de Lambda@Edge sur les événements du spectateur, utilisez CloudFront Functions. Si votre logique peut être implémentée avec les Fonctions CloudFront sur les événements du spectateur, ou avec Lambda@Edge sur les événements d’origine, utilisez CloudFront Functions, sauf si le taux d’accès au cache est très élevé.
- Découvrez les restrictions relatives aux fonctions de périphérie lorsque vous concevez votre application. Notez que, lors des événements de visualisation, vous pouvez utiliser Lambda@Edge ou les Fonctions CloudFront, mais pas les deux (par exemple, Lambda@Edge sur l’événement de demande de l’utilisateur et les Fonctions CloudFront sur l’événement de réponse de l’utilisateur).
Fonctions CloudFront
Les fonctions CloudFront sont écrites en JavaScript, peuvent être entièrement créées et testées dans la console CloudFront et les API, et peuvent être enregistrées dans les journaux CloudWatch dans la région us-east-1. En tant que développeur, vous devez écrire des fonctions dont l'utilisation du calcul est inférieure à 80 %. Les exécutions dépassant les quotas d'utilisation de calcul seront limitées par CloudFront, ce qui peut être surveillé à l'aide des métriques CloudWatch.
Ce guide du modèle de programmation vous aide à écrire des fonctions CloudFront. Vous trouverez ci-dessous un exemple de fonction permettant de rediriger les utilisateurs venant d’Allemagne vers du contenu allemand localisé :
function handler(event) {
var request = event.request;
var headers = request.headers;
var host = request.headers.host.value;
var country = 'DE';
var newurl = `https://${host}/de/index.html`;
if (headers['cloudfront-viewer-country']) {
var countryCode = headers['cloudfront-viewer-country'].value;
if (countryCode === country) {
var response = {
statusCode: 302,
statusDescription: 'Found',
headers: { location: { value: newurl } },
};
return response;
}
}
return request;
}Les Fonctions CloudFront permet également de découpler et de stocker les données persistantes séparément de votre code via CloudFront KeyValueStore. Le KeyValueStore est particulièrement idéal dans les situations où les données intégrées, telles que les mappages de redirection groupés, vous obligent à dépasser le quota de taille de la fonction. Il présente également l’avantage de vous permettre la mise à jour de vos données persistantes sans avoir à modifier votre fonction.
Lambda@Edge
Les fonctions Lambda@Edge peuvent être écrites en NodeJS ou en Python. Ils vous permettent de bénéficier de la puissance d'un conteneur Lambda avec une mémoire configurable (jusqu'à 10 Go). Comme elle est basée sur AWS Lambda, une fonction Lambda@Edge est créée dans la console Lambda, et exclusivement dans la région us-east-1. Lorsque vous avez fini de le créer et de le déployer sur votre distribution CloudFront, CloudFront est répliqué à l'échelle mondiale vers ses caches périphériques régionaux. Pour associer une fonction Lambda@Edge à un comportement de cache CloudFront, vous devez d'abord publier une nouvelle version de celle-ci, puis la déployer dans votre comportement de cache cible. Chaque mise à jour d'une fonction Lambda@edge déclenche un nouveau déploiement CloudFront (contrairement aux Fonctions CloudFront où seule l'association initiale déclenche un déploiement CloudFront). Lorsque vous développez des fonctions Lambda@Edge, tenez compte des points suivants :
- Découvrez les bonnes pratiques d'utilisation de Lambda@Edge, notamment en ce qui concerne la gestion de la simultanéité des exécutions. La simultanéité mesure le nombre de conteneurs Lambda exécutés simultanément par région de cache périphérique régional. Dans chaque région, la concurrence Lambd@Edge comporte des quotas en termes de vitesse d'explosion et de limite absolue.
- Découvrez les bonnes pratiques pour récupérer des données externes à partir de votre fonction Lambda@Edge.
- Les journaux Lambda@Edge sont envoyés aux journaux CloudWatch de la région où ils ont été exécutés avec un nom de groupe de journaux préfixé par us-east-1. Si vous devez centraliser les journaux Lambda@Edge dans une seule région, envisagez la solution d'agrégation de journaux Lambda @Edge suivante. Notez que chaque exécution de fonction génère des journaux dans CloudWatch Logs (contrairement aux Fonctions CloudFront, où les journaux ne sont générés que lorsqu'ils sont écrits explicitement dans le code de la fonction). Vous pouvez désactiver les journaux Lambda@Edge en supprimant les autorisations d'envoi de journaux à CloudWatch à partir du rôle IAM associé.
Ce guide du modèle de programmation vous aide à écrire des fonctions Lambda@Edge. Vous trouverez ci-dessous un exemple de fonction qui redirige les requêtes en fonction d’une redirection stockée dans un compartiment S3 :
const aws = require('aws-sdk');
const s3 = new aws.S3({ region: 'us-east-1' });
const s3Params = {
Bucket: 'redirections-configuration',
Key: 'redirects.json',
};
const TTL = 5000; // TTL of 5 seconds
async function fetchRedirectionsFromS3() {
const response = await s3.getObject(s3Params).promise();
return JSON.parse(response.Body.toString('utf-8')).map(
({ source, destination }) => ({
source: new RegExp(source),
destination,
})
);
}
let redirections;
function fetchRedirections() {
if (!redirections) {
redirections = fetchRedirectionsFromS3();
setTimeout(() => {
redirections = undefined;
}, TTL);
}
return redirections;
}
exports.handler = async event => {
const request = event.Records[0].cf.request;
try {
const redirects = await fetchRedirections();
for (const { source, destination } of redirects) {
if (source.test(request.uri)) {
return {
status: '302',
statusDescription: 'Found',
headers: {
location: [{ value: destination }],
},
};
}
}
return request;
} catch (_error) {
return request;
}
};