Mise en route / Ateliers / …
Déploiement d'un modèle de machine learning vers un point de terminaison d'inférence en temps réel
DIDACTICIEL
Présentation
Dans ce didacticiel, vous apprenez à déployer un modèle de machine learning (ML) entraîné vers un point de terminaison d'inférence en temps réel à l'aide d'Amazon SageMaker Studio.
Amazon SageMaker Studio est un environnement de développement intégré (IDE) pour le ML qui fournit une interface de bloc-notes Jupyter entièrement gérée dans laquelle vous pouvez effectuer des tâches de bout en bout du cycle de vie du ML, y compris le déploiement de modèles.
SageMaker propose différentes options d'inférence pour prendre en charge un large éventail de cas d'utilisation :
- SageMaker Real-Time Inference (Inférence en temps réel SageMaker) pour les charges de travail nécessitant une faible latence de l'ordre de quelques millisecondes
- SageMaker Serverless Inference (Inférence sans serveur SageMaker) pour les charges de travail présentant des schémas de trafic intermittents ou peu fréquents
- SageMaker Asynchronous Inference (Inférence asynchrone SageMaker) pour les inférences avec des charges utiles importantes ou nécessitant des temps de traitement longs
- SageMaker batch transform (Transformation par lots SageMaker) pour exécuter des prédictions sur des lots de données
Dans ce didacticiel, vous utilisez l'option Real-Time Inference (Inférence en temps réel) pour déployer un modèle XGBoost de classification binaire qui a déjà été entraîné sur un jeu de données de synthèse de sinistres d'assurance automobile. Le jeu de données se compose de détails et de caractéristiques extraites de tableaux de sinistres et de clients, ainsi que d'une colonne fraud (fraude) indiquant si un sinistre est frauduleux ou non. Le modèle prédit la probabilité qu'un sinistre soit frauduleux. Vous jouez le rôle d'un ingénieur en machine learning pour déployer ce modèle et exécuter des échantillons d'inférences.
Qu'allez-vous accomplir ?
Avec ce guide, vous allez :
- Créer un modèle SageMaker à partir d'un artefact de modèle entraîné
- Configurer et déployer un point de terminaison d'inférence en temps réel pour servir le modèle
- Appeler le point de terminaison pour exécuter des échantillons de prédictions en utilisant des données de test
- Attacher une politique de mise à l'échelle automatique au point de terminaison pour gérer les changements de trafic
Prérequis
Pour pouvoir démarrer ce guide, vous avez besoin de ce qui suit :
- Un compte AWS : si vous n'en avez pas encore, suivez les instructions du guide de mise en route Configuration de votre environnement pour une présentation rapide.
Expérience AWS
Débutant
Durée
25 minutes
Coût de réalisation
Consultez la tarification de SageMaker pour estimer le coût de ce didacticiel.
Éléments requis
Vous devez être connecté à un compte AWS.
Services utilisés
Inférence en temps réel Amazon SageMaker, Amazon SageMaker Studio
Date de la dernière mise à jour
19 mai 2022
Implémentation
Étape 1 : configuration de votre domaine Amazon SageMaker Studio
Avec Amazon SageMaker, vous pouvez déployer un modèle visuellement à l'aide de la console ou par programmation à l'aide de SageMaker Studio ou des blocs-notes SageMaker. Dans ce didacticiel, vous déployez le modèle de manière programmatique à l'aide d'un bloc-notes SageMaker Studio, ce qui nécessite un domaine SageMaker Studio.
Un compte AWS ne peut avoir qu'un seul domaine SageMaker Studio par région. Si vous possédez déjà un domaine SageMaker Studio dans la région USA Est (Virginie du Nord), suivez le Guide de configuration de SageMaker Studio pour joindre les politiques AWS IAM requises à votre compte SageMaker Studio, puis sautez l'étape 1 et passez directement à l'étape 2.
Si vous ne disposez pas d'un domaine SageMaker Studio existant, poursuivez avec l'étape 1 pour exécuter un modèle AWS CloudFormation qui crée un domaine SageMaker Studio et ajoute les autorisations requises pour la suite de ce didacticiel.
Choisissez le lien de la pile AWS CloudFormation. Ce lien ouvre la console AWS CloudFormation et crée votre domaine SageMaker Studio ainsi qu'un utilisateur nommé studio-user. Il ajoute également les autorisations requises à votre compte SageMaker Studio. Dans la console CloudFormation, confirmez que USA Est (Virginie du Nord) est la région affichée dans le coin supérieur droit. Le nom de la pile doit être CFN-SM-IM-Lambda-Catalog, et ne doit pas être modifié. Cette pile prend environ 10 minutes pour créer toutes les ressources.
Cette pile repose sur l'hypothèse que vous avez déjà configuré un VPC public dans votre compte. Si vous ne disposez pas d'un VPC public, veuillez consulter la rubrique VPC with a single public subnet (VPC avec un seul sous-réseau public) pour savoir comment créer un VPC public.

Sélectionnez I acknowledge that AWS CloudFormation might create IAM resources (J'accepte qu'AWS CloudFormation puisse créer des ressources IAM), puis choisissez Create stack (Créer la pile).

Dans le volet CloudFormation, choisissez Stacks (Piles). Il faut environ 10 minutes pour que la pile soit créée. Lorsque la pile est créée, son statut passe de CREATE_IN_PROGRESS (Création en cours) à CREATE_COMPLETE (Création terminée).

Étape 2 : configuration d'un bloc-notes SageMaker Studio
Au cours de cette étape, vous lancez un nouveau bloc-notes SageMaker Studio, installez les bibliothèques open source nécessaires et configurez les variables SageMaker requises pour récupérer l'artefact du modèle entraîné depuis Amazon Simple Storage Service (Amazon S3). Mais comme l'artefact de modèle ne peut pas être directement déployé pour l'inférence, vous devez d'abord créer un modèle SageMaker à partir de l'artefact de modèle. Le modèle créé contient le code d'entraînement et d'inférence que SageMaker utilise pour le déploiement du modèle.
Saisissez SageMaker Studio dans la barre de recherche de la console, puis choisissez SageMaker Studio.

Choisissez USA Est (Virginie du Nord) dans la liste déroulante Region (Région) située dans le coin supérieur droit de la console SageMaker. Pour Launch app (Lancer l'application), sélectionnez Studio pour ouvrir SageMaker Studio à l'aide du profil studio-user.

Ouvrez l'interface SageMaker Studio. Dans la barre de navigation, choisissez File (Fichier), New (Nouveau), Notebook (Bloc-notes).

Dans la boîte de dialogue Set up notebook environment (Configuration de l'environnement du bloc-notes), sous Image, sélectionnez Data Science (Science des données). Le noyau Python 3 est sélectionné automatiquement. Choisissez Select (Sélectionner).

Le kernel (noyau) dans le coin supérieur droit du bloc-notes devrait maintenant afficher Python 3 (Data Science) (Python 3 [Science des données]).

Copiez et collez l'extrait de code suivant dans une cellule du bloc-notes, et appuyez sur Shift+Enter (Maj+Entrée) pour exécuter la cellule actuelle afin de mettre à jour la bibliothèque aiobotocore, qui est une API permettant d'interagir avec de nombreux services AWS. Ignorez tout avertissement de redémarrage noyau ou toute erreur de conflit de dépendance.
%pip install --upgrade -q aiobotocoreVous devez également instancier l'objet client S3 et les emplacements dans votre compartiment S3 par défaut, où les métriques et les artefacts de modèle sont chargés. Pour ce faire, copiez et collez le code suivant dans une cellule du bloc-notes et exécutez-le. Remarquez que le compartiment d'écriture sagemaker-<votre-région>-<votre-identifiant-de-compte> est automatiquement créé par l'objet de session SageMaker à la ligne 16 du code ci-dessous. Les jeux de données que vous utilisez pour vous entraîner existent dans un compartiment S3 public nommé sagemaker-sample-files, qui a été spécifié comme le compartiment de lecture à la ligne 29. L'emplacement dans le compartiment est spécifié par le préfixe de lecture.
import pandas as pd
import numpy as np
import boto3
import sagemaker
import time
import json
import io
from io import StringIO
import base64
import pprint
import re
from sagemaker.image_uris import retrieve
sess = sagemaker.Session()
write_bucket = sess.default_bucket()
write_prefix = "fraud-detect-demo"
region = sess.boto_region_name
s3_client = boto3.client("s3", region_name=region)
sm_client = boto3.client("sagemaker", region_name=region)
sm_runtime_client = boto3.client("sagemaker-runtime")
sm_autoscaling_client = boto3.client("application-autoscaling")
sagemaker_role = sagemaker.get_execution_role()
# S3 locations used for parameterizing the notebook run
read_bucket = "sagemaker-sample-files"
read_prefix = "datasets/tabular/synthetic_automobile_claims"
model_prefix = "models/xgb-fraud"
data_capture_key = f"{write_prefix}/data-capture"
# S3 location of trained model artifact
model_uri = f"s3://{read_bucket}/{model_prefix}/fraud-det-xgb-model.tar.gz"
# S3 path where data captured at endpoint will be stored
data_capture_uri = f"s3://{write_bucket}/{data_capture_key}"
# S3 location of test data
test_data_uri = f"s3://{read_bucket}/{read_prefix}/test.csv"Étape 3 : création d'un point de terminaison pour l'inférence en temps réel
Dans SageMaker, il existe plusieurs méthodes pour déployer un modèle entraîné vers un point de terminaison d'inférence en temps réel : le kit SDK SageMaker, le kit SDK AWS – Boto3, et la console SageMaker. Pour en savoir plus, veuillez consulter la rubrique Deploy Models for Inference (Déploiement de modèles pour inférence) dans le Guide du développeur Amazon SageMaker. Le kit SDK SageMaker présente plus d'abstractions que le kit SDK AWS – Boto3, ce dernier exposant des API de niveau inférieur pour un meilleur contrôle du déploiement des modèles. Dans ce didacticiel, vous déployez le modèle à l'aide du kit SDK AWS – Boto3. Il y a trois étapes à suivre de manière séquentielle pour déployer un modèle :
- Créer un modèle SageMaker à partir de l'artefact de modèle
- Créer une configuration de point de terminaison pour spécifier les propriétés, notamment le type et le nombre d'instances
- Créer le point de terminaison à l'aide de la configuration du point de terminaison
Pour créer un modèle SageMaker en utilisant l'artefact du modèle entraîné stocké dans S3, copiez et collez le code suivant. La méthode create_model prend comme paramètres le conteneur Docker contenant l'image d'entraînement (pour ce modèle, le conteneur XGBoost) et l'emplacement S3 de l'artefact du modèle.
# Retrieve the SageMaker managed XGBoost image
training_image = retrieve(framework="xgboost", region=region, version="1.3-1")
# Specify a unique model name that does not exist
model_name = "fraud-detect-xgb"
primary_container = {
"Image": training_image,
"ModelDataUrl": model_uri
}
model_matches = sm_client.list_models(NameContains=model_name)["Models"]
if not model_matches:
model = sm_client.create_model(ModelName=model_name,
PrimaryContainer=primary_container,
ExecutionRoleArn=sagemaker_role)
else:
print(f"Model with name {model_name} already exists! Change model name to create new")
Vous pouvez vérifier le modèle créé dans la console SageMaker, dans la section Models (Modèles).

Une fois le modèle SageMaker créé, copiez et collez le code suivant pour utiliser la méthode Boto3 create_endpoint_config afin de configurer le point de terminaison. Les principales entrées de la méthode create_endpoint_config sont le nom de la configuration du point de terminaison et les informations sur les variantes, telles que le type et le nombre d'instances d'inférence, le nom du modèle à déployer et la part de trafic que le point de terminaison doit gérer. En plus de ces paramètres, vous pouvez également configurer la capture de données en spécifiant une DataCaptureConfig. Cette fonctionnalité vous permet de configurer le point de terminaison en temps réel pour capturer et stocker les demandes et/ou les réponses dans Amazon S3. La capture des données est l'une des étapes de la mise en place de la surveillance du modèle, et lorsqu'elle est combinée avec des métriques de référence et des tâches de surveillance, elle vous aide à surveiller les performances du modèle en comparant les métriques des données de test avec les références. Cette surveillance est utile pour programmer le recyclage du modèle en fonction de la dérive du modèle ou des données et à des fins d'audit. Dans la configuration actuelle, l'entrée (données de test entrantes) et la sortie (prédictions du modèle) sont capturées et stockées dans votre compartiment S3 par défaut.
# Endpoint Config name
endpoint_config_name = f"{model_name}-endpoint-config"
# Endpoint config parameters
production_variant_dict = {
"VariantName": "Alltraffic",
"ModelName": model_name,
"InitialInstanceCount": 1,
"InstanceType": "ml.m5.xlarge",
"InitialVariantWeight": 1
}
# Data capture config parameters
data_capture_config_dict = {
"EnableCapture": True,
"InitialSamplingPercentage": 100,
"DestinationS3Uri": data_capture_uri,
"CaptureOptions": [{"CaptureMode" : "Input"}, {"CaptureMode" : "Output"}]
}
# Create endpoint config if one with the same name does not exist
endpoint_config_matches = sm_client.list_endpoint_configs(NameContains=endpoint_config_name)["EndpointConfigs"]
if not endpoint_config_matches:
endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[production_variant_dict],
DataCaptureConfig=data_capture_config_dict
)
else:
print(f"Endpoint config with name {endpoint_config_name} already exists! Change endpoint config name to create new")Vous pouvez vérifier la configuration du point de terminaison créé dans la console SageMaker, dans la section Endpoint configurations (Configurations des points de terminaison).

Copiez et collez le code suivant pour créer le point de terminaison. La méthode create_endpoint prend la configuration du point de terminaison comme paramètre, et déploie le modèle spécifié dans la configuration du point de terminaison dans une instance de calcul. Il faut environ 6 minutes pour déployer le modèle.
endpoint_name = f"{model_name}-endpoint"
endpoint_matches = sm_client.list_endpoints(NameContains=endpoint_name)["Endpoints"]
if not endpoint_matches:
endpoint_response = sm_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name
)
else:
print(f"Endpoint with name {endpoint_name} already exists! Change endpoint name to create new")
resp = sm_client.describe_endpoint(EndpointName=endpoint_name)
status = resp["EndpointStatus"]
while status == "Creating":
print(f"Endpoint Status: {status}...")
time.sleep(60)
resp = sm_client.describe_endpoint(EndpointName=endpoint_name)
status = resp["EndpointStatus"]
print(f"Endpoint Status: {status}")Pour vérifier l'état du point de terminaison, choisissez l'icône des SageMaker resources (Ressources SageMaker). Pour SageMaker resources (Ressources SageMaker), sélectionnez Endpoints (Points de terminaison) et pour le nom, sélectionnez fraud-detect-xgb-endpoint.

Étape 4 : appel du point de terminaison de l'inférence
Une fois que l'état du point de terminaison est passé à InService (En service), vous pouvez invoquer le point de terminaison à l'aide de l'API REST, du kit SDK AWS – Boto3, de SageMaker Studio, de l'AWS CLI ou du kit SDK Python de SageMaker. Dans ce didacticiel, vous utilisez le kit SDK AWS – Boto3. Avant d'appeler un point de terminaison, il est important que les données de test soient formatées de manière appropriée pour le point de terminaison en utilisant la sérialisation et la désérialisation. La sérialisation est le processus de conversion des données brutes dans un format tel que .csv, en flux d'octets que le point de terminaison peut utiliser. La désérialisation est le processus inverse de la conversion du flux d'octets en format lisible par l'homme. Dans ce didacticiel, vous invoquez le point de terminaison en envoyant les cinq premiers échantillons d'un jeu de données de test. Pour invoquer le point de terminaison et obtenir les résultats de la prédiction, copiez et collez le code suivant. Comme la demande au point de terminaison (jeu de données de test) est au format .csv, un processus de sérialisation csv est utilisé pour créer la charge utile. La réponse est ensuite désérialisée en un tableau de prédictions. Une fois l'exécution terminée, la cellule renvoie les prédictions du modèle et les véritables balises pour les échantillons de test. Remarquez que le modèle XGBoost renvoie des probabilités au lieu des balises de classe réelles. Le modèle a prédit une très faible probabilité que les échantillons de test soient des sinistres frauduleux et les prédictions sont en ligne avec les balises réelles.
# Fetch test data to run predictions with the endpoint
test_df = pd.read_csv(test_data_uri)
# For content type text/csv, payload should be a string with commas separating the values for each feature
# This is the inference request serialization step
# CSV serialization
csv_file = io.StringIO()
test_sample = test_df.drop(["fraud"], axis=1).iloc[:5]
test_sample.to_csv(csv_file, sep=",", header=False, index=False)
payload = csv_file.getvalue()
response = sm_runtime_client.invoke_endpoint(
EndpointName=endpoint_name,
Body=payload,
ContentType="text/csv",
Accept="text/csv"
)
# This is the inference response deserialization step
# This is a bytes object
result = response["Body"].read()
# Decoding bytes to a string
result = result.decode("utf-8")
# Converting to list of predictions
result = re.split(",|\n",result)
prediction_df = pd.DataFrame()
prediction_df["Prediction"] = result[:5]
prediction_df["Label"] = test_df["fraud"].iloc[:5].values
prediction_df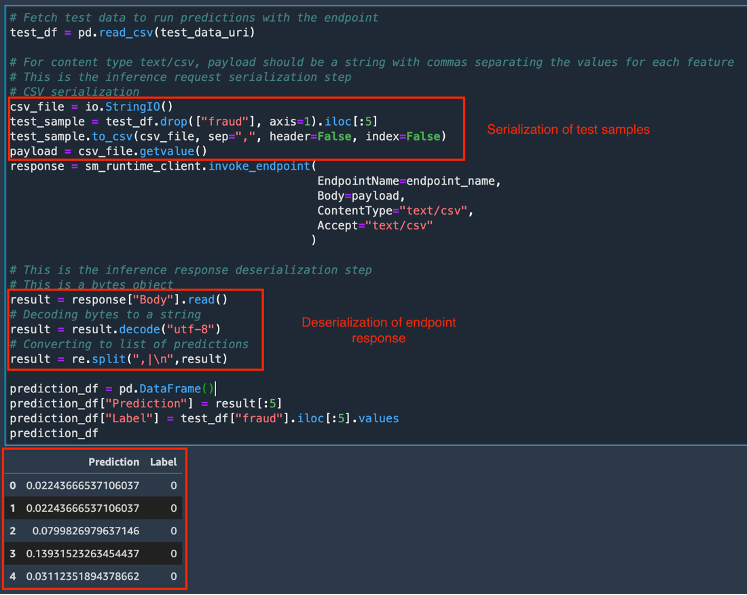
Pour surveiller les métriques d'appel des points de terminaison à l'aide d'Amazon CloudWatch, ouvrez la console SageMaker. Sous Inference, sélectionnez Endpoints (Points de terminaison), fraud-detect-xgb-endpoint.

Sur la page Endpoint Details (Détails du point de terminaison), sous Monitor (Surveiller), choisissez View invocation metrics (Afficher les métriques d'appel). Au départ, il se peut que vous ne voyiez qu'un seul point dans le tableau des métriques. Mais après plusieurs appels, vous verrez une ligne similaire à celle de la capture d'écran de l'exemple.

La page Metrics (Métriques) présente plusieurs métriques de performance des points de terminaison. Vous pouvez choisir différentes périodes de temps, comme 1 heure ou 3 heures, pour visualiser les performances du point de terminaison. Sélectionnez n'importe quelle métrique pour voir sa tendance sur la période choisie. Dans l'étape suivante, vous choisissez l'une de ces métriques pour définir des politiques de mise à l'échelle automatique.

Comme la capture de données a été établie dans la configuration du point de terminaison, vous avez la possibilité d'inspecter les données utiles envoyées au point de terminaison en même temps que sa réponse. Les données capturées prennent un certain temps pour être entièrement chargées sur S3. Copiez et collez le code suivant pour vérifier si la capture des données est terminée.
from sagemaker.s3 import S3Downloader
print("Waiting for captures to show up", end="")
for _ in range(90):
capture_files = sorted(S3Downloader.list(f"{data_capture_uri}/{endpoint_name}"))
if capture_files:
capture_file = S3Downloader.read_file(capture_files[-1]).split("\n")
capture_record = json.loads(capture_file[0])
if "inferenceId" in capture_record["eventMetadata"]:
break
print(".", end="", flush=True)
time.sleep(1)
print()
print(f"Found {len(capture_files)} Data Capture Files:")Les données capturées sont stockées dans un fichier distinct pour chaque appel de point de terminaison dans S3 en JSON Lines, un format délimité par des retours à la ligne pour stocker des données structurées où chaque ligne est une valeur JSON. Copiez et collez le code suivant pour récupérer les fichiers de capture de données.
capture_files = sorted(S3Downloader.list(f"{data_capture_uri}/{endpoint_name}"))
capture_file = S3Downloader.read_file(capture_files[0]).split("\n")
capture_record = json.loads(capture_file[0])
capture_record
Copiez et collez le code suivant pour décoder les données dans les fichiers capturés en utilisant base64. Le code récupère les cinq échantillons de test qui ont été envoyés en tant que charge utile, ainsi que leurs prédictions. Cette fonctionnalité est utile pour inspecter les charges des points de terminaison avec les réponses du modèle et surveiller les performances du modèle.
input_data = capture_record["captureData"]["endpointInput"]["data"]
output_data = capture_record["captureData"]["endpointOutput"]["data"]
input_data_list = base64.b64decode(input_data).decode("utf-8").split("\n")
print(input_data_list)
output_data_list = base64.b64decode(output_data).decode("utf-8").split("\n")
print(output_data_list)
Étape 5 : configuration de la mise à l'échelle automatique pour le point de terminaison
Les charges de travail qui utilisent des points de terminaison d'inférence en temps réel ont généralement de faibles exigences en matière de latence. Qui plus est, lorsque le trafic atteint des pics, les points de terminaison de l'inférence en temps réel peuvent subir une surcharge de l'unité centrale, une latence élevée ou des interruptions de service. Il est donc important de faire évoluer la capacité pour gérer efficacement les changements de trafic avec une faible latence. La mise à l'échelle automatique d'inférence SageMaker surveille vos charges de travail et ajuste dynamiquement le nombre d'instances pour maintenir des performances de point de terminaison constantes et prévisibles, et ce à faible coût. Lorsque la charge de travail augmente, la mise à l'échelle automatique met davantage d'instances en ligne, et lorsque la charge de travail diminue, elle supprime les instances inutiles, ce qui vous aide à réduire vos coûts de calcul. Dans ce didacticiel, vous utilisez le kit SDK AWS – Boto3 pour configurer la mise à l'échelle automatique de votre point de terminaison. SageMaker propose plusieurs types de mise à l'échelle automatique : mise à l'échelle par suivi des objectifs, mise à l'échelle par étapes, mise à l'échelle à la demande et mise à l'échelle programmée. Dans ce didacticiel, vous utilisez une politique de suivi des objectifs et d'échelonnement, qui est déclenchée lorsqu'une métrique d'échelonnement choisie dépasse un seuil cible choisi.
La mise à l'échelle automatique peut être configurée en deux étapes. Tout d'abord, vous configurez une politique de mise à l'échelle avec les détails du nombre minimal, souhaité et maximal d'instances par point de terminaison. Copiez et collez le code suivant pour configurer une politique de suivi des objectifs et d'échelonnement. Le nombre maximal spécifié d'instances est lancé lorsque le trafic dépasse les seuils choisis, que vous choisissez à l'étape suivante.
resp = sm_client.describe_endpoint(EndpointName=endpoint_name)
# SageMaker expects resource id to be provided with the following structure
resource_id = f"endpoint/{endpoint_name}/variant/{resp['ProductionVariants'][0]['VariantName']}"
# Scaling configuration
scaling_config_response = sm_autoscaling_client.register_scalable_target(
ServiceNamespace="sagemaker",
ResourceId=resource_id,
ScalableDimension="sagemaker:variant:DesiredInstanceCount",
MinCapacity=1,
MaxCapacity=2
)Copiez et collez le code suivant pour créer la politique de mise à l'échelle. La métrique choisie est SageMakerVariantInvocationsPerInstance, qui représente le nombre moyen de fois par minute où chaque instance d'inférence d'une variante de modèle est appelée. Lorsque ce nombre franchit le seuil choisi de 5, la mise à l'échelle automatique est déclenchée.
# Create Scaling Policy
policy_name = f"scaling-policy-{endpoint_name}"
scaling_policy_response = sm_autoscaling_client.put_scaling_policy(
PolicyName=policy_name,
ServiceNamespace="sagemaker",
ResourceId=resource_id,
ScalableDimension="sagemaker:variant:DesiredInstanceCount",
PolicyType="TargetTrackingScaling",
TargetTrackingScalingPolicyConfiguration={
"TargetValue": 5.0, # Target for avg invocations per minutes
"PredefinedMetricSpecification": {
"PredefinedMetricType": "SageMakerVariantInvocationsPerInstance",
},
"ScaleInCooldown": 600, # Duration in seconds until scale in
"ScaleOutCooldown": 60 # Duration in seconds between scale out
}
)Copiez et collez le code suivant pour récupérer les détails de la politique de mise à l'échelle.
response = sm_autoscaling_client.describe_scaling_policies(ServiceNamespace="sagemaker")
pp = pprint.PrettyPrinter(indent=4, depth=4)
for i in response["ScalingPolicies"]:
pp.pprint(i["PolicyName"])
print("")
if("TargetTrackingScalingPolicyConfiguration" in i):
pp.pprint(i["TargetTrackingScalingPolicyConfiguration"])Copiez et collez le code suivant pour soumettre le point de terminaison à un test de contrainte. Le code s'exécute pendant 250 secondes et appelle le point de terminaison de manière répétée, en envoyant des échantillons sélectionnés de manière aléatoire à partir du jeu de données de test.
request_duration = 250
end_time = time.time() + request_duration
print(f"Endpoint will be tested for {request_duration} seconds")
while time.time() < end_time:
csv_file = io.StringIO()
test_sample = test_df.drop(["fraud"], axis=1).iloc[[np.random.randint(0, test_df.shape[0])]]
test_sample.to_csv(csv_file, sep=",", header=False, index=False)
payload = csv_file.getvalue()
response = sm_runtime_client.invoke_endpoint(
EndpointName=endpoint_name,
Body=payload,
ContentType="text/csv"
)Vous pouvez surveiller les métriques du point de terminaison à l'aide d'Amazon CloudWatch. Pour obtenir une liste des métriques disponibles pour les points de terminaison, y compris l'appel, veuillez consulter la rubrique Métriques d'appel des points de terminaison de SageMaker. Dans la console SageMaker, sous Inference, choisissez Endpoints (Points de terminaison), fraud-detect-xgb-endpoint. Sur la page Endpoints details (Détails du point de terminaison), naviguez jusqu'à la section Monitor (Surveiller), et choisissez View invocation metrics (Afficher les métriques d'appel). Sur la page Metrics (Métriques), sélectionnez InvocationsPerInstance (il s'agit d'une métrique de surveillance que vous avez choisie lors de la configuration de la politique de mise à l'échelle) et Invocations (Appels) dans la liste des métriques, puis choisissez l'onglet Graphed metrics (Graphique des métriques).

Sur la page Graphed metrics (Graphique des métriques), vous pouvez inspecter visuellement le modèle de trafic reçu par le point de terminaison, et changer la granularité temporelle, par exemple de 5 minutes par défaut à 1 minute. L'ajout de la deuxième instance par la mise à l'échelle automatique peut prendre quelques minutes. Une fois la nouvelle instance ajoutée, vous pouvez constater que les appels par instance représentent la moitié du nombre total des appels.

Lorsque le point de terminaison reçoit la charge utile augmentée, vous pouvez vérifier l'état du point de terminaison en exécutant le code ci-dessous. Ce code vérifie quand le statut du point de terminaison passe de InService à Updating (en cours de mise à jour) et garde la trace du nombre d'instances. Après quelques minutes, vous pouvez voir le statut passer de InService à Updating et revenir à InService mais avec un nombre d'instances plus élevé.
# Check the instance counts after the endpoint gets more load
response = sm_client.describe_endpoint(EndpointName=endpoint_name)
endpoint_status = response["EndpointStatus"]
request_duration = 250
end_time = time.time() + request_duration
print(f"Waiting for Instance count increase for a max of {request_duration} seconds. Please re run this cell in case the count does not change")
while time.time() < end_time:
response = sm_client.describe_endpoint(EndpointName=endpoint_name)
endpoint_status = response["EndpointStatus"]
instance_count = response["ProductionVariants"][0]["CurrentInstanceCount"]
print(f"Status: {endpoint_status}")
print(f"Current Instance count: {instance_count}")
if (endpoint_status=="InService") and (instance_count>1):
break
else:
time.sleep(15)
Étape 6 : nettoyage des ressources
Une bonne pratique consiste à supprimer les ressources que vous n'utilisez plus afin de ne pas encourir de frais imprévus.
Supprimez le modèle, la configuration du point de terminaison et le point de terminaison que vous avez créés dans ce didacticiel en exécutant le bloc-notes suivant. Si vous ne supprimez pas le point de terminaison, votre compte continue à accumuler des frais pour l'instance de calcul fonctionnant au point de terminaison.
# Delete model
sm_client.delete_model(ModelName=model_name)
# Delete endpoint configuration
sm_client.delete_endpoint_config(EndpointConfigName=endpoint_config_name)
# Delete endpoint
sm_client.delete_endpoint(EndpointName=endpoint_name)Pour supprimer le compartiment S3, procédez comme suit :
- Ouvrez la console Amazon S3. Sur la barre de navigation, choisissez Buckets (Compartiments), sagemaker-<votre-région>-<votre-identifiant-de-compte>, puis cochez la case à côté de fraud-detect-demo. Puis choisissez Delete (Supprimer).
- Dans la boîte de dialogue Delete objects (Supprimer des objets), vérifiez que vous avez sélectionné le bon objet à supprimer et saisissez permanently delete (supprimer définitivement) dans la case de confirmation des Permanently delete objects (Supprimer définitivement des objets).
- Une fois que cette opération est terminée et que le compartiment est vide, vous pouvez supprimer le compartiment sagemaker-<votre-région>-<votre-identifiant-de-compte> en suivant à nouveau la même procédure.

Le noyau de Science des données utilisé pour exécuter l'image du bloc-notes dans ce didacticiel accumule les charges jusqu'à ce que vous arrêtiez le noyau ou que vous effectuiez les étapes suivantes pour supprimer les applications. Pour en savoir plus, veuillez consulter la rubrique Shut Down Resources (Arrêt des ressources) dans le Guide du développeur Amazon SageMaker.
Pour supprimer les applications SageMaker Studio, procédez comme suit : dans la console SageMaker Studio, choisissez studio-user, puis supprimez toutes les applications répertoriées sous Apps (Applications) en choisissant Delete app (Supprimer l'application). Attendez que le Status (Statut) de l'état passe à Deleted (Supprimé).

Si vous avez utilisé un domaine SageMaker Studio existant à l'étape 1, ignorez le reste de l'étape 6 et passez directement à la section de conclusion.
Si vous avez exécuté le modèle CloudFormation à l'étape 1 pour créer un domaine SageMaker Studio, poursuivez les étapes suivantes pour supprimer le domaine, l'utilisateur et les ressources créés par le modèle CloudFormation.
Pour ouvrir la console CloudFormation, saisissez CloudFormation dans la barre de recherche de la console AWS, puis choisissez CloudFormation dans les résultats de la recherche.

Dans le volet CloudFormation, choisissez Stacks (Piles). Dans la liste déroulante Status (Statut), sélectionnez Active (Actif). Sous Stack name (Nom de la pile), choisissez CFN-SM-IM-Lambda-Catalog pour ouvrir la page des détails de la pile.

Sur la page de détails de la pile CFN-SM-IM-Lambda-Catalog, choisissez Delete (Supprimer) pour supprimer la pile ainsi que les ressources qu'elle a créées à l'étape 1.

Conclusion
Félicitations ! Vous avez terminé le didacticiel Déploiement d'un modèle de machine learning vers un point de terminaison d'inférence en temps réel.
Dans ce didacticiel, vous avez créé un modèle SageMaker et l'avez déployé vers un point de terminaison d'inférence en temps réel. Vous avez utilisé le kit SDK AWS – API Boto3 pour appeler le point de terminaison et le tester en exécutant des exemples d'inférences tout en tirant parti de la fonctionnalité de capture de données pour enregistrer les charges utiles et les réponses du point de terminaison dans S3. Enfin, vous avez configuré la mise à l'échelle automatique en utilisant une métrique d'appel de point de terminaison cible pour gérer les fluctuations du trafic.
Vous pouvez poursuivre votre parcours de machine learning avec SageMaker en suivant la section des prochaines étapes ci-dessous.
Entraîner un modèle de deep learning
Créer un modèle ML automatiquement
Trouver d'autres didacticiels pratiques