Creazione di dashboard per visibilità operativa
Consegna e funzionamento del software | LIVELLO 300
Introduzione
Tutti utilizziamo applicazioni su computer, tablet e smartphone, ed è semplicissimo per noi vedere se un dispositivo è carico e se la connessione alla rete Wi-Fi funziona. Sappiamo anche che i nostri schermi ci mostreranno tutte le notifiche importanti, come gli avvisi dello spazio esaurito sul disco. In effetti, la velocità e il tempo di risposta generali dell'interfaccia utente (UI) possono essere un buon indicatore della quantità di risorse corretta o meno del dispositivo per poter eseguire le applicazioni, ad esempio della memoria e della CPU.
Ma chi ha fornito assistenza da remoto al dispositivo di un familiare sa benissimo che rilevare ed eseguire la diagnostica dei problemi è più complicato quando non vediamo né interagiamo con il dispositivo. Per questo, nel caso dei servizi su cloud ci sono delle difficoltà: come monitoriamo questi servizi da remoto e come sappiamo se i clienti sono soddisfatti?
Per osservare un servizio a host singolo, possiamo entrare nell'host, eseguire una serie di strumenti di monitoraggio del tempo di attività e controllare i log per determinare la causa principale del problema dell'host. Tuttavia, le soluzioni a host singolo sono sostenibili solo per i servizi più semplici e non critici. All'altro estremo ci sono i servizi multi-tier distribuiti che si eseguono su centinaia o migliaia di server, container o ambienti serverless.
In che modo Amazon può verificare se tutti i servizi basati sul cloud in esecuzione in più zone di disponibilità in molte regioni in tutto il mondo funzionano in modo efficace? I flussi di lavoro di monitoraggio automatico e correzione automatica (ad esempio lo spostamento del traffico) e i sistemi di distribuzione automatica sono fondamentali per rilevare e risolvere la maggior parte dei problemi su larga scala. Tuttavia, per molte ragioni dobbiamo ancora poter vedere quello che questi servizi, flussi di lavoro e distribuzioni fanno in ogni momento.
Uso delle dashboard in Amazon
Utilizziamo i pannelli di controllo come meccanismi per superare la difficoltà di gestire al meglio l'attività nei nostri servizi cloud. I pannelli di controllo sono le "visualizzazioni umane" nei nostri sistemi che forniscono resoconti concisi sui comportamenti del sistema mostrando dati relativi a parametri cronologici, log, tracce e avvisi.
In Amazon, quando parliamo di dashboarding ci riferiamo ai processi di creazione, utilizzo e manutenzione continua dei pannelli di controllo. Il dashboarding è diventato un'attività di prim'ordine perché è fondamentale per il successo dei nostri servizi nelle attività giornaliere operative e di consegna dei software, come la progettazione, la codifica, la creazione, i test, la distribuzione e il dimensionamento dei servizi.
Ma, ovviamente, non ci aspettiamo che gli operatori controllino i pannelli di controllo tutto il tempo. Nella maggior parte del tempo, nessuno controlla questi pannelli. Infatti, abbiamo scoperto che tutti i processi operativi che richiedono la revisione manuale dei pannelli di controllo falliscono a causa di un errore umano, indipendentemente da quanto frequentemente viene controllato il pannello. Per affrontare i rischi, abbiamo creato avvisi automatici che valutano costantemente i dati di monitoraggio più importanti che vengono emessi dai nostri sistemi. Generalmente, si tratta di parametri che indicano se il sistema si sta avvicinando a certi limiti (rilevamento proattivo, prima dell'impatto) o se è già compromesso in qualche modo inaspettato (rilevamento reattivo, dopo l'impatto).
Questi avvisi possono eseguire carichi di lavoro di correzione automatica e notificare ai nostri operatori che si è verificato un problema. La notifica rimanda gli operatori ai pannelli di controllo e ai runbook esatti che devono utilizzare. Quando sono a lavoro e una notifica mi avvisa di un problema, posso utilizzare rapidamente il relativo pannello di controllo per quantificare l'impatto per il cliente, convalidare o valutare la causa principale, mitigare e ridurre il tempo di ripresa. Anche se l'allarme ha già iniziato un flusso di lavoro di correzione automatica, devo vedere che cosa sta facendo, qual è l'effetto sul sistema e, in circostanze eccezionali, spostare il flusso di lavoro fornendo una conferma umana per i passaggi più critici per la sicurezza.
Quando c'è un evento in corso, generalmente Amazon coinvolge più operatori sul lavoro. Gli operatori possono usare diversi pannelli di controllo durante la sequenza delle attività. Queste attività includono la quantificazione dell'impatto per i clienti, la valutazione, il rilevamento tra i servizi della causa principale dell'evento, l'osservazione dei flussi di lavoro di correzione automatica e l'esecuzione e la convalida dei passaggi di mitigazione basati sul runbook. Nel frattempo, anche i team del peering e gli stakeholder aziendali utilizzano i pannelli di controllo per monitorare l'impatto continuativo durante l'evento. Questi diversi partecipanti comunicano utilizzando strumenti di gestione degli incidenti, chat room (con bot come Chatbot di AWS) e videoconferenze. Ogni stakeholder fornisce una prospettiva diversa dei dati che vede nel pannello di controllo.
Ogni settimana, anche i team di Amazon e le organizzazioni esterne fissano delle riunioni per la revisione delle operazioni a cui partecipano leader senior, amministratori e ingegneri. Durante queste riunioni, utilizziamo una ruota della fortuna per scegliere i pannelli di controllo per l'audit di alto livello. Gli stakeholder verificano l'esperienza dei clienti e gli obiettivi chiave a livello di servizio, come la disponibilità e la latenza. I pannelli di controllo di audit utilizzati da questi stakeholder mostrano generalmente i dati operativi di tutte le zone di disponibilità e di tutte le regioni.
Inoltre, durante la pianificazione e la previsione della capacità a lungo termine, Amazon utilizza delle dashboard che visualizzano i parametri aziendali, di utilizzo e di capacità di più alto livello emessi dal nostro sistema in intervalli di tempo più lunghi.
Tipi di dashboard
I pannelli di controllo vengono utilizzati per monitorare manualmente i servizi, ma non c'è una dimensione che funziona per tutti i casi d'uso. Per la maggior parte dei sistemi utilizziamo molti pannelli di controllo, ognuno dei quali fornisce un punto di vista diverso nel sistema. Questi punti di vista diversi permettono agli utenti di capire il comportamento dei nostri sistemi da prospettive diverse e in intervalli di tempo diversi.
I dati da visualizzare cambiamo significativamente da pannello a pannello. Abbiamo imparato a concentrarci sul destinatario principale quando progettiamo dei pannelli di controllo: decidiamo quali dati vanno in quale pannello sulla base del destinatario che lo utilizzerà e della motivazione dell'utilizzo. Probabilmente sai già che in Amazon lavoriamo guardando al cliente. La creazione di pannelli di controllo ne è un esempio. Creiamo i pannelli di controllo sulla base delle necessità dell'utente finale e dei suoi requisiti specifici.
Il seguente diagramma illustra come diverse dashboard forniscono diverse visualizzazioni del sistema nell’insieme:
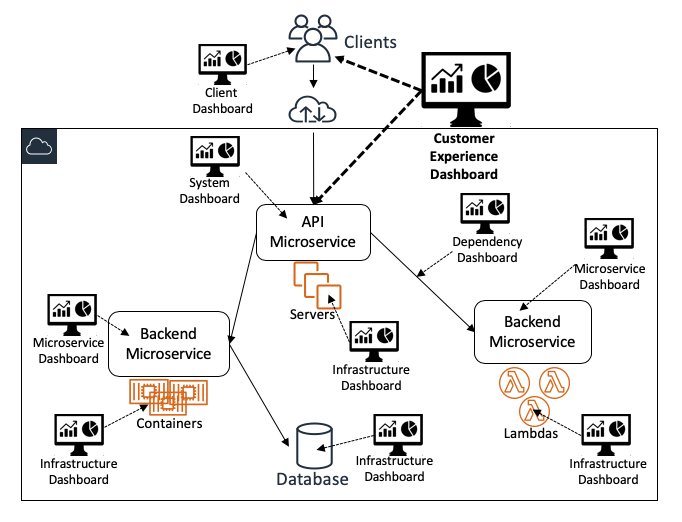
Dashboard di alto livello
Pannello di controllo per l'esperienza del cliente
In Amazon, i pannelli di controllo più importanti e utilizzati sono quelli per l'esperienza del cliente. Questi pannelli sono progettati per essere utilizzati da ampi gruppi di utenti tra cui operatori di servizi e molti altri stakeholder e presentano in modo estremamente efficiente dei parametri sull'integrità e l'aderenza del servizio agli obiettivi. Mostrano i dati di monitoraggio tratti dal servizio stesso e dagli strumenti del client, dai tester continui (come le canary Synthetics di Amazon CloudWatch) e dai sistemi di correzione automatica. Questi pannelli di controllo contengono anche dei dati che aiutano gli utenti a rispondere alle domande sulla profondità e la portata dell'impatto. Alcune di queste domande sono, ad esempio, "Quanti clienti sono colpiti?" e "Quali sono i clienti più colpiti?"
Pannello di controllo a livello di sistema
I punti di accesso ai nostri servizi basati sul Web sono generalmente endpoint UI e API, quindi i pannelli di controllo a livello di sistema dedicati devono contenere abbastanza dati perché gli operatori possano vedere come si stanno comportando il sistema e gli endpoint rivolti ai clienti. In primo luogo, questi pannelli mostrano i dati di monitoraggio a livello di interfaccia. Inoltre, mostrano tre categorie di dati di monitoraggio per ogni API:
- Dati di monitoraggio relativi all'input. Includono i conteggi delle richieste ricevute o del lavoro raccolto da code/flussi, i percentili delle dimensioni dei byte delle richieste e i conteggi dell'autenticazione/autorizzazione non riuscita.
- Dati di monitoraggio relativi all'elaborazione. Possono includere i conteggi multi-modali dell'esecuzione di percorsi/rami logici aziendali, i percentili di conteggi/fallimento/latenza delle richieste dei microservizi back-end, gli output di log di errore o guasto e i dati di tracciamento delle richieste.
- Dati di monitoraggio relativi all'output. Possono includere i conteggi del tipo di risposta (suddivisi per risposte di errore/guasto del cliente), la dimensione delle risposte e i percentili dei byte di prima risposta e della risposta completa del tempo di scrittura.
In generale, vogliamo mantenere l'esperienza del cliente e i pannelli di controllo a livello di sistema al livello più alto possibile. Evitiamo coscientemente la tentazione di aggiungere troppi parametri ai pannelli perché il sovraccarico delle informazioni potrebbe distrarre dal messaggio principale che questi pannelli devono trasmettere.
Pannelli di controllo delle istanze dei servizi
Creiamo alcuni pannelli per facilitare la valutazione rapida e completa dell'esperienza dei clienti in un'istanza del servizio (partizione o cella). Questa visualizzazione limitata permette agli operatori che lavorano su una singola istanza del servizio di non sovraccaricarsi con dati irrilevanti da altre istanze del servizio.
Pannelli di controllo di audit del servizio
Creiamo anche pannelli di controllo per l'esperienza dei clienti che mostrano volontariamente i dati per tutte le istanze di un servizio in tutte le zone di disponibilità e in tutte le regioni. Questi pannelli di controllo di audit del servizio vengono utilizzati dagli operatori per effettuare l'audit automatico degli avvisi in tutte le istanze del servizio. Questi avvisi possono anche essere revisionati durante le riunioni operative settimanali menzionate prima.
Pannelli di controllo di pianificazione e previsione della capacità
Per i casi d’uso più a lungo termine, creiamo anche delle dashboard per la pianificazione e la previsione della capacità che ci aiutano a visualizzare la crescita del nostro servizio.
Dashboard di basso livello
Le API di Amazon vengono generalmente implementate orchestrando le richieste nei microservizi di back-end. Questi microservizi possono appartenere a diversi team, ognuno dei quali è responsabile di alcuni aspetti specifici dell'elaborazione della richiesta. Ad esempio, alcuni microservizi sono dedicati all'autenticazione e all'autorizzazione della richiesta, alla messa in pratica del throttling/limite, al conteggio dell'utilizzo, alla creazione/l'aggiornamento/l'eliminazione delle risorse, al recupero delle risorse dai datastore e all'avvio di flussi di lavoro asincroni. Generalmente i team creano almeno un pannello di controllo specifico del microservizio dedicato che mostra i parametri per ogni API, o l'unità di lavoro, se il servizio non è sincronizzato con l'elaborazione dei dati.
Pannelli di controllo specifici del microservizio
I pannelli di controllo per i microservizi mostrano generalmente i dati di monitoraggio specifici dell'implementazione che richiedono grande conoscenza del servizio. Questi pannelli di controllo vengono utilizzati principalmente dai team proprietari del servizio. Tuttavia, dato che i nostri servizi hanno moltissimi strumenti, dobbiamo presentare i dati tratti da questi strumenti in modo che non sopraffacciano gli operatori. Per questo, questi pannelli di controllo mostrano alcuni dati in forma aggregata. Quando gli operatori identificano delle anomalie nei dati aggregati, generalmente utilizzano una grande varietà di altri strumenti per approfondire, eseguendo query ad hoc sui dati di monitoraggio sottostanti che "disaggregano" i dati, tracciano le richieste e rivelano i dati relativi o correlati.
Pannelli di controllo delle infrastrutture
I nostri servizi vengono eseguiti sull'infrastruttura AWS che tipicamente emette i parametri; per questo, abbiamo anche dei pannelli di controllo delle infrastrutture dedicati. Questi pannelli di controllo si concentrano prima di tutto sui parametri emessi dalle risorse di calcolo eseguite dai nostri sistemi, come le istanze Amazon Elastic Compute Cloud (EC2), i container di Amazon Elastic Container Service (ECS)/Amazon Elastic Kubernetes Service (EKS) e le funzioni di AWS Lambda. I parametri come l'utilizzo della CPU, il traffico di rete, l'IO su disco e l'utilizzo dello spazio vengono comunemente utilizzati in questi pannelli di controllo insieme a cluster correlati, Auto Scaling e parametri di quota rilevanti per queste risorse di calcolo.
Pannelli di controllo delle dipendenze
Oltre alle risorse di calcolo, in molti casi i microservizi dipendono da altri microservizi. Anche se i team proprietari di queste dipendenze hanno già i loro pannelli di controllo, ogni proprietario del microservizio generalmente crea pannelli di controllo dedicati della dipendenza per fornire una visualizzazione di come si comportano le dipendenze upstream (come proxy e sistema di bilanciamento del carico) e downstream (come data store, code e flussi), secondo quanto misurato dal servizio. Queste dashboard possono anche essere utilizzate per tracciare altri parametri critici, come le date di scadenza dei certificati di sicurezza e altri utilizzi delle quote di dipendenza.
Progettazione delle dashboard
In Amazon siamo convinti che la coerenza nella presentazione dei dati sia fondamentale nel processo di creazione di un pannello. Perché sia efficace, la coerenza deve essere raggiunta in ogni pannello di controllo e in tutti i pannelli di controllo. Negli anni abbiamo identificato, adattato e rifinito un set comune di stili e norme di progettazione che crediamo rendano i pannelli di controllo accessibili per tutti i destinatari e che aumentino il valore della nostra organizzazione. Nel tempo abbiamo inoltre trovato alcune modalità di misurazione e miglioramento delle convenzioni di progettazione. Ad esempio, se un operatore capisce rapidamente i dati presentati nei pannelli di controllo e li utilizza per capire come funziona un servizio, significa che tali pannelli di controllo presentano le informazioni giuste nel modo giusto.
Una tendenza molto comune nella creazione dei pannelli di controllo è quella di sovrastimare o sottostimare la conoscenza dell'ambito dell'utente destinatario. È semplice creare un pannello che abbia totalmente senso per chi lo ha progettato, ma magari non rilevante per gli utenti. Utilizziamo la tecnica del lavoro mirato al cliente (in questo caso, agli utenti del pannello) per eliminare i rischi e
abbiamo adottato delle norme di progettazione che standardizzano il layout dei dati nel pannello. I pannelli di controllo sono renderizzati dall'altro al basso e inizialmente gli utenti tendono a interpretare i grafici renderizzati (visibili quando il pannello carica) come il fattore più importante. Quindi, la nostra norma di progettazione consiglia di inserire i dati più importanti nella parte alta del pannello. Abbiamo scoperto che generalmente i grafici di disponibilità aggregati/riassuntivi e i grafici percentili di latenza end-to-end sono i pannelli di controllo più importanti per i servizi Web.
Ecco uno screenshot della parte superiore di una dashboard per un ipotetico servizio Foo:
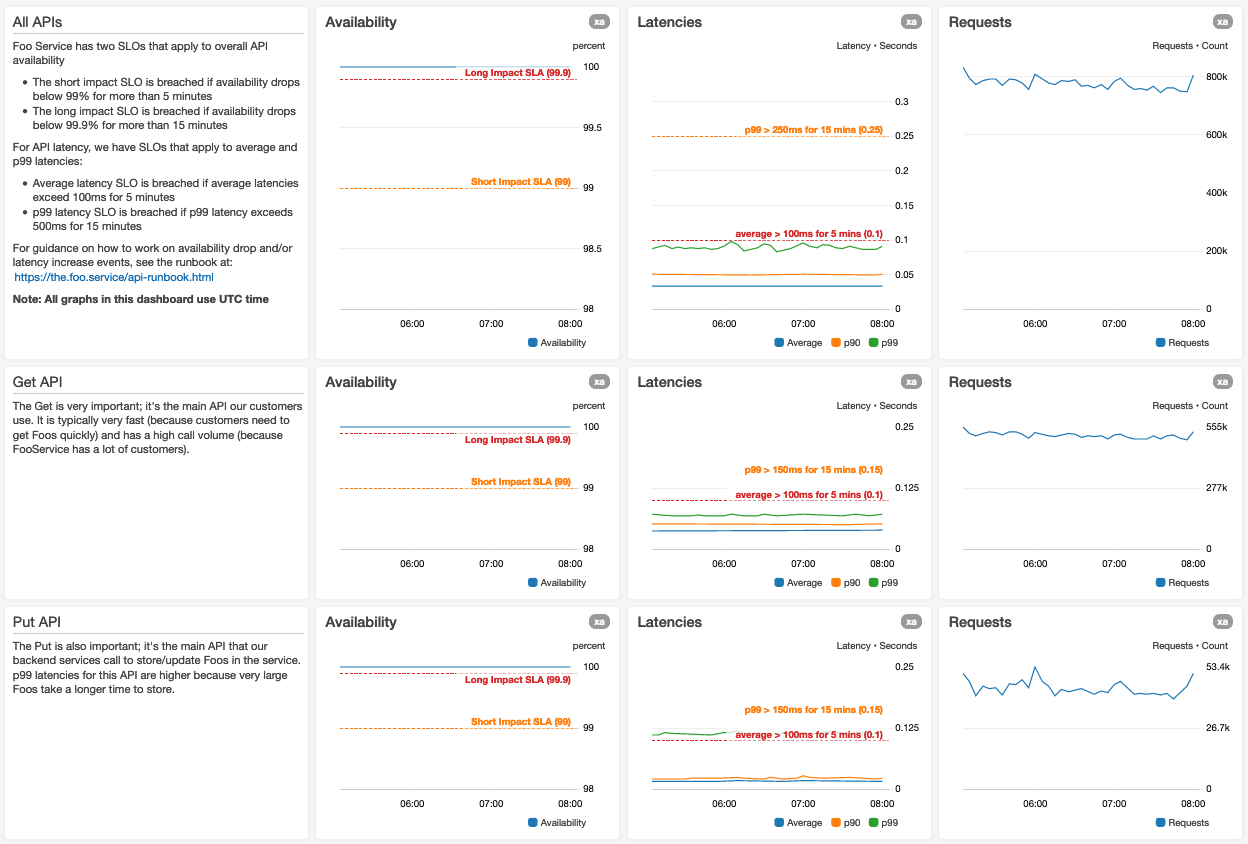
Utilizziamo grafici più grandi per i parametri più importanti
Se in un grafico ci sono molti parametri, ci assicuriamo che la legenda non schiacci orizzontalmente o verticalmente i dati visibili del grafico. Se utilizziamo delle query di ricerca nei grafici, ci assicuriamo di permettere dei risultati del set di parametri più ampi.
Disponiamo i grafici nella risoluzione dello schermo minima prevista
Questo permette di evitare che gli utenti debbano scorrere orizzontalmente. Infatti, chi lavora alle 3 di notte su un computer portatile può non notare la barra per scorrere orizzontalmente e non capire che sulla destra ci sono altri grafici.
Mostriamo il fuso orario
Per quanto riguarda i pannelli di controllo che mostrano la data e l'ora, ci assicuriamo che il fuso orario relativo sia ben visibile. Nel caso dei pannelli di controllo utilizzati contemporaneamente da operatori in diversi fusi orari, impostiamo di default il fuso orario standard (UTC) a cui entrambi possono fare riferimento. In questo modo, gli utenti possono comunicare tra loro utilizzando un unico fuso orario e risparmiando tempo e sforzi mentali di calcolo dell'ora.
Utilizziamo l'intervallo di tempo e il periodo di data point più corti
Per impostazione predefinita utilizziamo l'intervallo di tempo e il periodo di data point rilevante per i casi d'uso più comuni. Ci assicuriamo che tutti i grafici di un pannello di controllo mostrino inizialmente i dati per lo stesso intervallo temporale e la stessa risoluzione. Pensiamo sia molto più corretto che tutti i grafici di una sezione del pannello di controllo abbiano la stessa dimensione orizzontale. Questo permette una correlazione di tempo semplice tra i grafici.
Evitiamo anche di inserire troppi data point nei grafici perché questo rallenta molto il tempo di caricamento del pannello di controllo. Inoltre, abbiamo osservato che mostrare troppi data point all'utente può effettivamente ridurre la visibilità nel caso di altre anomalie. Per esempio, un grafico con un intervallo di tre ore e data point con risoluzione di un minuto con soli 180 valori per parametro avrà una resa chiara anche nei widget piccoli del pannello di controllo. Questo numeri di data point fornisce anche abbastanza contesto agli operatori che devono controllare gli eventi operativi in corso.
Abilitiamo la possibilità di adattare l'intervallo di tempo e il periodo del parametro
I nostri pannelli di controllo forniscono dei controlli per adattare rapidamente sia l'intervallo di tempo che il periodo del parametro per tutti i grafici. Altri intervalli comuni x rapporto di risoluzione che utilizziamo nei nostri pannelli di controllo sono:
- 1 ora x 1 minuto (60 data point), utile per zoomare e osservare gli eventi in corso
- 12 ore x 1 minuto (720 data point)
- 1 giorno x 5 minuti (288 data point), utile per visualizzare le tendenze giornaliere
- 3 giorni x 5 minuti (864 data point)
- 1 settimana x 1 ora (168 data point), utile per visualizzare le tendenze settimanali
- 1 mese x 1 ora (744 data point)
- 3 mesi x 1 giorno (90 data point), utile per visualizzare le tendenze trimestrali
- 9 mesi x 1 giorno (270 data point)
- 15 mesi x 1 giorno (450 data point), utile per la revisione della capacità a lungo termine
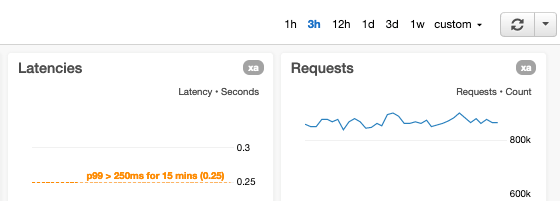
Commentiamo i grafici con soglie di allarme
Quando tracciamo il grafico dei parametri che abbiamo collegato agli avvisi automatici, se una soglia di allarme è statica, commentiamo i grafici con linee orizzontali. Se le soglie di allarme sono dinamiche, ovvero basate su previsioni generate utilizzando l'intelligenza artificiale (IA) e il machine learning (ML), mostriamo sia i parametri della soglia che quelli attuali nello stesso grafico. Se un grafico mostra un parametro che misura un aspetto del servizio con limiti noti (ad esempio, un limite "massimo testato" e un limite di risorsa difficile), commentiamo il grafico con una linea orizzontale a indicare dove si trovano i limiti noti o testati. Per i parametri con degli obiettivi, aggiungiamo una linea orizzontale per renderli visibili all'utente.
Evitiamo di aggiungere linee orizzontali ai grafici che utilizzano già un asse y sinistro e destro
Se si aggiungono delle linee orizzontali a questi grafici, per gli utenti sarà più complicato sapere a quale asse y si riferisce la linea orizzontale. Per evitare questo problema, dividiamo i grafici, come segue, in due grafici che utilizzano un solo asse orizzontale e aggiungiamo la linea orizzontale solo al grafico in cui è necessaria.
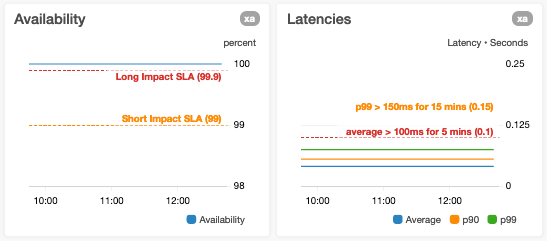
Non sovraccarichiamo un asse y con più parametri con intervalli di valore molto diversi
Evitiamo questa situazione perché potrebbe ridurre la visibilità della variazione di uno o più parametri. Un esempio di questo caso è quando inseriamo latenze p0 (minime) e p100 (massime) nello stesso grafico in cui i valori dei data point p100 potrebbero essere ordini di grandezza maggiori dei data point p0.
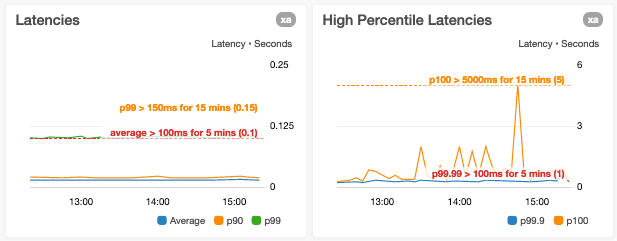
Siamo attenti a ridurre i limiti dell’asse y solo nell’attuale intervallo di valori del data point
A prima vista, un grafico con un intervallo di asse y limitato ai valori del data point può far sembrare un parametro molto più variabile di quanto è realmente.
Evitiamo il sovraccarico dei singoli grafici
Vogliamo assicurarci di non avere troppe statistiche o troppi parametri non correlati in un solo grafico. Ad esempio, quando aggiungiamo dei grafici per l'elaborazione di una richiesta, generalmente creiamo grafici adiacenti separati nel pannello di controllo per:
- % di disponibilità (Guasti/richieste * 100)
- Latenze p10, medie e p90
- Latenze p99,9 e massime (p100)
Non diamo per scontato che l'utente sappia esattamente cosa significano ogni parametro e ogni widget
Questo vale soprattutto per i parametri specifici di implementazione. Vogliamo fornire il contesto necessario nel testo del pannello di controllo, ad esempio con descrizioni accanto o sotto ogni grafico. L'operatore può così leggere il testo e capire cosa significa il parametro. Poi, può interpretare cosa significa "normale" e cosa succede quando il grafico non è "normale". Nel testo forniamo dei link alle risorse correlate che un operatore può utilizzare per determinare la causa principale. Ecco alcuni esempi dei tipi di link che forniamo:
- Ai runbook. Per gli esperti dell'ambito in questione, il pannello di controllo può essere il runbook.
- Ai pannelli di controllo di "approfondimento".
- Ai pannelli di controllo equivalenti per altri cluster o partizioni.
- Alle pipeline di distribuzione.
- Alle informazioni di contatto per le dipendenze.
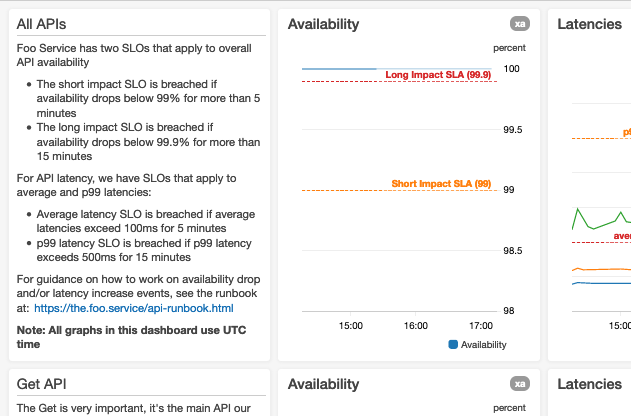
Utilizziamo stati degli allarmi, numeri semplici e/o widget grafici con serie temporali, se applicabile
In base ai casi d’uso per la dashboard, riteniamo che sia più appropriato mostrare un widget che contiene un solo numero (ad esempio il più recente valore di un parametro) o lo stato dell’allarme piuttosto che mostrare un grafico con una serie temporale complessa di tutti i data point recenti.

Non facciamo affidamento su grafici che mostrano parametri sparse
I parametri sparse sono parametri emessi solamente quando si verificano certe condizioni di errore. Anche se instrumentare i servizi può essere efficace per emettere questi parametri solo quando necessario, gli utenti del pannello di controllo possono confondersi con i grafici vuoti o quasi vuoti. Quando troviamo questi parametri durante la progettazione dei pannelli di controllo, generalmente modifichiamo il servizio per emettere continuativamente valori sicuri (ovvero a zero) per questi parametri in assenza della condizione di errore. In questo modo, gli operatori possono comprendere facilmente che l'assenza dei dati implica che il servizio non sta emettendo telemetrie correttamente.
Aggiungiamo grafici aggiuntivi che mostrano parametri per modalità
Lo facciamo quando mostriamo i grafici per i parametri che aggregano comportamenti multi-modello nei nostri sistemi. Questo accade in diverse circostanze, ad esempio:
- Quando un servizio supporta le richieste con dimensioni variabili, possiamo creare un grafico per le latenze complete delle richieste. Inoltre, possiamo anche creare dei grafici che mostrano parametri per richieste di piccole, medie e grandi dimensioni.
- Se un servizio esegue le richieste in modi diversi in base ai valori (o alle combinazioni) dei parametri di input, possiamo aggiungere grafici per i parametri che catturano ogni modalità di esecuzione.
Manutenzione delle dashboard
La prima fase è la creazione dei pannelli di controllo con più visualizzazioni dei nostri sistemi. Tuttavia, i nostri sistemi si evolvono e si ridimensionano costantemente e i pannelli di controllo devono evolversi con loro, perché vengono aggiunte nuove caratteristiche e vengono migliorate le architetture. La manutenzione e l'aggiornamento dei pannelli di controllo vengono effettuati durante il nostro processo di sviluppo. Prima di completare le modifiche e durante la revisione del codice, i nostri sviluppatori si chiedono sempre: "Devo aggiornare dei pannelli di controllo?" Il loro obiettivo è quello di fare i cambiamenti ai pannelli di controllo prima che vengano distribuite le modifiche sottostanti. Questo permette di evitare che un operatore debba aggiornare i pannelli di controllo durante o dopo la distribuzione di un sistema per confermare che la modifica è stata distribuita.
Se un pannello di controllo contiene molte più informazioni dettagliate del normale, potrebbe significare che gli operatori stanno utilizzando quel pannello per il rilevamento manuale delle anomalie invece di utilizzare gli avvisi automatici o la correzione automatica. Effettuiamo continuamente audit ai nostri pannelli di controllo per determinare se è possibile ridurre lo sforzo manuale migliorando la strumentazione dei nostri servizi e gli avvisi automatici. Inoltre, alleggeriamo o aggiorniamo in modo costante i grafici che non apportano più valore ai pannelli di controllo.
Permettendo ai nostri sviluppatori di aggiornare i pannelli di controllo, ci assicuriamo di averne un set completo e identico per i nostri ambienti di pre-produzione (alfa, beta o gamma). Le nostre pipeline di distribuzione automatica distribuiscono le modifiche prima agli ambienti di pre-produzione. Quindi, i nostri team devono poter convalidare facilmente le modifiche in questi ambienti di test utilizzando i pannelli di controllo associati (e gli avvisi automatici) in modo esattamente coerente con le modalità di valutazione che verranno implementate alle modifiche degli ambienti di produzione.
La maggior parte dei sistemi si evolve continuamente quando vengono aggiornati i requisiti, vengono aggiunte nuove caratteristiche e vengono modificate le architetture dei software per permette il dimensionamento nel tempo. I pannelli di controllo sono un componente essenziale dei nostri sistemi, quindi seguiamo il processo di Infrastructure-as-Code (IaC) per conservarli. Questo processo ci assicura che i pannelli di controllo siano controllati in sistemi di controllo della versione e che le modifiche vengano distribuite al loro interno utilizzando gli stessi strumenti che utilizzano i nostri sviluppatori e i nostri operatori per i servizi.
Quando conduciamo un postmortem per un evento operativo inaspettato, i nostri team verificano se i miglioramenti ai pannelli di controllo (e gli avvisi automatici) possono aver svuotato preventivamente l'evento, se hanno identificato la causa principale più rapidamente o se hanno ridotto il tempo di recupero. Generalmente ci chiediamo: "Guardandoci indietro, i pannelli di controllo mostravano chiaramente l'impatto del cliente, aiutavano gli operatori a determinare la causa principale e assistevano durante la misurazione del tempo di ripresa?" Se la risposta a queste domande è no, il nostro post mortem include alcune azioni di rifinitura delle dashboard.
Conclusioni
In Amazon lavoriamo con servizi su larga scala in tutto il mondo. I nostri sistemi automatizzati monitorano costantemente eventuali problemi, li rilevano, ci avvisano e li correggono, e dobbiamo avere la possibilità di monitorare, approfondire, effettuare audit ed esaminare questi servizi e questi sistemi automatici. Per raggiungere l'obiettivo, creiamo e manteniamo dei pannelli di controllo che forniscono visualizzazioni diverse per i nostri sistemi. Progettiamo questi pannelli di controllo per gruppi di destinatari sia ampi che specifici lavorando in prospettiva per gli utenti. Per rendere i pannelli di controllo più semplici da capire per gli operatori e i proprietari dei servizi, utilizziamo un set consistente di stili e norme di progettazione per assicurarci che siano utili e facili da usare.
I nostri pannelli di controllo forniscono molte prospettive e visualizzazioni diverse delle modalità di funzionamento dei servizi AWS. Hanno un ruolo cruciale nella consegna di un'incredibile esperienza del cliente e aiutano i team di Amazon a capire i servizi, metterli in pratica e ridimensionarli. Speriamo che questo articolo possa esserti di aiuto durante la progettazione, la creazione e la manutenzione dei tuoi pannelli di controllo. Se vuoi vedere un esempio di come creare dashboard utilizzando i servizi AWS, ecco un breve video e una guida self-service.
Informazioni sull’autore
John O'Shea è Principal Engineer presso Amazon Web Services. Attualmente si occupa di Amazon CloudWatch e di altri servizi di osservabilità e monitoraggio interni di Amazon.

Contenuti correlati
Hai trovato quello che cercavi?
Facci sapere la tua opinione per aiutarci a migliorare la qualità dei contenuti delle nostre pagine