Con il deep learning, Disney cataloga un universo di contenuti
In un episodio della serie TV Disneyland del 1957, Walt Disney guida i telespettatori nelle profondità dello studio di animazione di Burbank. Riferendosi alla libreria sotterranea, afferma: "Nel nostro archivio, queste mensole, questi tavoli e questi raccoglitori conservano la storia del nostro studio cinematografico."
In un episodio della serie TV Disneyland del 1957, Walt Disney guida i telespettatori nelle profondità dello studio di animazione di Burbank. Riferendosi alla libreria sotterranea, afferma: "Nel nostro archivio, queste mensole, questi tavoli e questi raccoglitori conservano la storia del nostro studio cinematografico."
Molto prima di altri studi di animazione, Disney ha insistito per rendere il suo archivio accessibile a sceneggiatori e disegnatori alla ricerca di riferimenti o ispirazioni. Questo caveau conserva con cura disegni, modelli grafici e molto altro dei personaggi preferiti dei visitatori, come Dumbo e Peter Pan. Da allora, Disney si è impegnata per custodirlo.
Con quasi un secolo di contenuti tra le mani, di cui una parte sempre più consistente in formato digitale, Disney deve organizzare la sua libreria con una cura senza precedenti. Un piccolo team di ingegneri preposti ad attività di ricerca e sviluppo e di information scientist del team Direct-to-Consumer & International (DTCI) Technology di Disney si occupa di tenere gli scaffali (digitali) puliti e in ordine. Creato nel 2018, il dipartimento DTCI riunisce tecnologi ed esperti di The Walt Disney Company e allinea le tecnologie in modo da supportare la vasta gamma di contenuti unici e necessità aziendali di Disney.
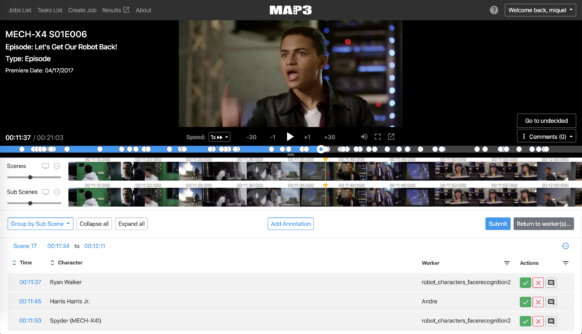
I metadati sono la base del sistema organizzativo e includono informazioni su storie, scene e personaggi di film e spettacoli della Disney. Ad esempio, Bambi disporrà di metadati che identificano non solo personaggi come il coniglietto Tippete o Faline (il cerbiatto amico di Bambi), ma anche il tipo di animale, le relazioni esistenti tra i vari animali e gli archetipi rappresentati da ciascuno di essi. I tag specifici includono quelli relativi a scene nella natura (suddivise per tipi specifici di fiori raffigurati), musica, sentimenti e tono della storia. Perciò, la sfida è usare tag appropriati e metadati corretti per tutti questi contenuti per assicurarsi di ordinarli correttamente, in particolar modo prendendo in considerazione il rapido tasso di crescita di Disney:
"Ci sono nuovi personaggi di spettacoli televisivi, calciatori che cambiano squadra, nuove armi per i supereroi, nuovi spettacoli", ha dichiarato Miquel Farré, technical lead del team, e tutto questo richiede un'elevata mole di nuovi metadati.
Grazie all'aiuto dei servizi AWS, Miquel Farré e il suo team stanno creando strumenti di deep learning e machine learning per applicare tag a questi contenuti con metadati descrittivi in automatico, in modo da rendere il processo di archiviazione ancora più efficiente. In questo modo, sceneggiatori ed esperti di animazione possono effettuare ricerche rapide e acquisire familiarità con tutti i personaggi, da Topolino a Phil Dunphy di Modern Family.
Quale magia si nasconde dietro ai metadati?
Immagine per gentile concessione di Disney
Il team che si occupa di questa mansione è stato creato nel 2012, come parte del gruppo Disney & ABC Television Group. Nel corso degli anni, il team è cresciuto ed è ora parte del gruppo DTCI Technology di Disney, diventando l'indice e la knowledge base di stili e convenzioni dell'universo Disney (ad esempio, in Bambi gli animali parlano, mentre in Biancaneve no). Per fare in modo che gli strumenti di machine learning generino metadati che descrivono i contenuti creativi in maniera accurata, il team si affida a sceneggiatori ed esperti in animazione che spiegano le funzionalità stilistiche che rendono unico ogni spettacolo.
I membri del team creativo traggono vantaggio da questa collaborazione. Quando i contenuti sono taggati con metadati accurati, sarà più facile trovarli al momento opportuno usando un'interfaccia di ricerca. Ad esempio, uno sceneggiatore di Grey's Anatomy potrebbe aver bisogno di sapere quante volte compare il termine "Duodenocefalopancreasectomia" all'interno di un episodio per evitare di essere ridondante. Al contempo, un artista che si sta occupando dei disegni per un nuovo cartone animato ambientato sui fondali marini, potrebbe voler cercare posizionamenti o pose specifici dei personaggi de La Sirenetta o Alla ricerca di Nemo per trarne ispirazione.
Tuttavia, l'applicazione di tag con metadati corretti per tutti i contenuti rappresenta presto un problema dal punto di vista della manodopera: anche se l'applicazione di tag manuale è una parte fondamentale del processo, il team DTCI Technology non ha il tempo per suddividere in categorie i singoli fotogrammi. Ecco perché il team di Farré ha deciso di usare il machine learning (e più di recente il deep learning) per generare i metadati. L'obiettivo è creare algoritmi di deep learning in grado di applicare tag automaticamente ai componenti di una scena in modo coerente al resto della knowledge base di Disney. I dipendenti devono ancora approvare i tag dell'algoritmo, ma il progetto è di ridurre in maniera significativa la mole di lavoro organizzativo della libreria Disney, migliorando l'accuratezza delle ricerche condotte al suo interno.
Inoltre, queste migliorie consentono agli ingegneri di avere più tempo a disposizione per dedicarsi allo sviluppo di modelli di deep learning usando AWS (Amazon Web Services). Perciò, l'impegno per automatizzare la creazione di metadati in diversi tipi di contenuti Disney è costante.

Il deep learning conferisce un'identità all'animazione
Immagine per gentile concessione di Disney
Uno dei progetti di metadati/deep learning più importanti riguarda la risoluzione dei problemi verificati in fase di riconoscimento delle animazioni.
In uno spettacolo televisivo o in un film d'azione, chiedere a una macchina di distinguere un personaggio dall'ambiente circostante è un compito relativamente semplice. Nel caso di animazioni, invece, il discorso diventa più complicato. Ad esempio, una scena animata in cui un personaggio compare in carne ed ossa e in un poster (supponiamo che il personaggio sia un criminale e che ci siano dei manifesti da ricercato sparsi per la città). "Si tratta di un compito molto arduo per un algoritmo", ha affermato Farré.
Lo scorso anno, il team di Farré ha sviluppato un metodo di deep learning in grado di distinguere personaggi animati dalle relative rappresentazioni statiche, identificandoli nel mezzo di una folla di sosia (come in Ducktales, in cui diversi personaggi si assomigliano molto) e riconoscendoli in scene con condizioni di illuminazione singolari (come in Alice nel paese delle meraviglie, quando la protagonista incontra per la prima volta lo Stregatto, di cui si vede solamente un sorriso a trentadue denti). Dopo aver deciso cosa corrisponde a cosa, l'algoritmo è in grado di applicare tag con metadati corretti per le singole scene.
Tuttavia, la vera forza di questo modello è data dal fatto che lo si può applicare a qualsiasi componente di un contenuto di animazione. In altre parole, al posto di creare un nuovo modello per Pippo, Hercules ed Elsa, il team deve solo usare il relativo modello genetico che, con piccoli ritocchi, si adatterà a tutti i personaggi di un film o spettacolo.
In passato, il team lavorava con algoritmi di machine learning più tradizionali, che richiedevano meno dati rispetto all'approccio del deep learning, ma fornivano risultati meno flessibili e più limitati. Se si inseriscono meno dati, gli algoritmi tradizionali funzionano bene. Quando però si dispone di più dati in misura esponenziale, l'uso del deep learning può fare la differenza.
Ora, afferma Farré, il modello di deep learning può trarre beneficio da reti già addestrate ed essere ottimizzato per casi d'uso specifici. Nel caso di personaggi animati, Disney ha perfezionato una rete neurale con migliaia di immagini per assicurarsi che capisca il concetto di "personaggio animato". Quindi, la rete neurale viene riadeguata per ogni spettacolo usando poche centinaia di immagini tratte da alcuni episodi in modo che impari a rilevare e interpretare i "personaggi animati" in uno determinato spettacolo.
AWS si è rivelato un partner chiave nella transizione di Disney da un approccio più tradizionale basato sul machine learning al deep learning, in particolar modo nella fase di sperimentazione. Le istanze EC2 di cloud computing elastiche consentono al team di testare rapidamente nuove versioni del modello. Per il progetto di riconoscimento delle animazioni, Disney usa il framework PyTorch con modelli pre-addestrati. Dal momento che ci sono molte ricerche in atto relativamente al deep learning, il team sperimenta continuamente modelli nuovi e innovativi.
La ricerca di metadati si è rivelata un tale successo che si è sparsa la voce tra i vari dipartimenti di Disney. Farré ha dichiarato che il suo team ha collaborato recentemente con il team di personalizzazione di ESPN per fornire metadati dettagliati su tutti gli articoli e i video per applicazioni digitali e siti Web leader del settore. Se il prodotto sa che l'utente è un fan della squadra di baseball Los Angeles Dodgers, di Stephen Curry, dei Minnesota Vikings e del Manchester United e ha a disposizione più metadati per articolo, può fornire contenuti maggiormente in linea con le preferenze dell'utente. Inoltre, gli algoritmi di machine learning e i metadati forniti possono potenziare un'AI (intelligenza artificiale) più avanzata per promuovere una personalizzazione più implicita (basata sulle relazioni tra dati e comportamento) nel corso del tempo.
Secondo Farré, ci sono infinite applicazioni per i metadati, soprattutto se si considera il fatto che Disney ha una libreria di prodotti, personaggi e contenuti unici di grandi dimensioni e in costante crescita. "Credo che non ci annoieremo", ha dichiarato.
Storie correlate
Coinbase utilizza il machine learning per garantire la sicurezza nello scambio di criptovalute
Capital One utilizza il ML per proteggere meglio i propri clienti dalle frodi

Zendesk aiuta le compagnie a fornire un servizio clienti più veloce utilizzando il ML
Il servizio clienti di T-Mobile acquisisce una dimensione umana grazie al ML
