Amazon Web Services ブログ
2026 AWS Life Sciences Symposium ハイライト:創薬研究領域
英語版ブログ: “ Highlights from the 2026 AWS Life Sciences Symposium: Research and Drug Discovery”
ライフサイエンス業界全体で、研究者たちは実験の設計方法、データの解釈、そしてシミュレーションとウェット実験を結ぶ創薬サイクルのあり方を根本から変えつつあります。AI エージェントは、この新薬候補の発見プロセス全体を加速させています。2026年5月に開催された 2026 AWS Life Sciences Symposium では、Sanofi、Genentech、Noetik、Apheris、Bristol Myers Squibb、Memorial Sloan Kettering などのリーダーたちが、科学的発見の加速と患者アウトカムの改善のために、エージェンティックAIを現在どのように活用しているかを紹介しました。
研究を変革する 3 つの能力
本シンポジウムを通じて、研究イノベーションの基盤となる3つの能力が浮き彫りになりました。これらは相互に連携し合うものです。
- リアルラボ(Wet)とデジタルラボ(Dry)の接続 — ウェットラボを計装化し、実験データが自動的にシミュレーションシステムへ流れ込む仕組みを作ることで、仮説→実験→結果のサイクルを途切れなく回す。
- FAIR( Findable, Accessible, Interoperable, Reusable )かつガバナンスの効いたデータ基盤の構築 — AI エージェントが推論に必要な科学的コンテキストを備え、インサイトが信頼できるデータに裏付けられるようにする。
- 強力なAIツールを研究者の手に直接届ける — 生物学的基盤モデルから自律的研究エージェントまで、一部の専門家だけでなく、すべての研究者が日々の業務でAIの全能力を活用できるようにする。
この3つの柱こそが、真の「 lab-in-the-loop 」を形づくる条件です。
本トラックは、ビジョンを示すセッションで幕を開け、なぜ今この瞬間が重要なのかを参加者に伝えました。目覚ましい科学的進歩にもかかわらず、創薬はヒト生物学の膨大な複雑さに依然として制約されています——細胞、化合物、分子間相互作用が生み出す途方もない組み合わせが生む探索空間、そして治療領域・組織・分野を越えて残り続ける知識交換のギャップがその要因です。より豊かな生物学データ、モダンなデータ基盤、そして新世代の AI が融合することで、これらのギャップは埋まり始めています。鍵となるのは、データ・基盤・AI の間をつなぐ仕組みを築き、インサイトが好循環で加速する構造を作ることです。これが lab-in-the-loop の本質です。
ループを閉じる:Amazon Bio Discovery を活用した AI 支援による抗体設
本イベントの目玉発表の一つとして、午前の基調講演で初めて披露され、本セッションで詳細が語られたのが、Amazon Bio Discoveryのローンチです
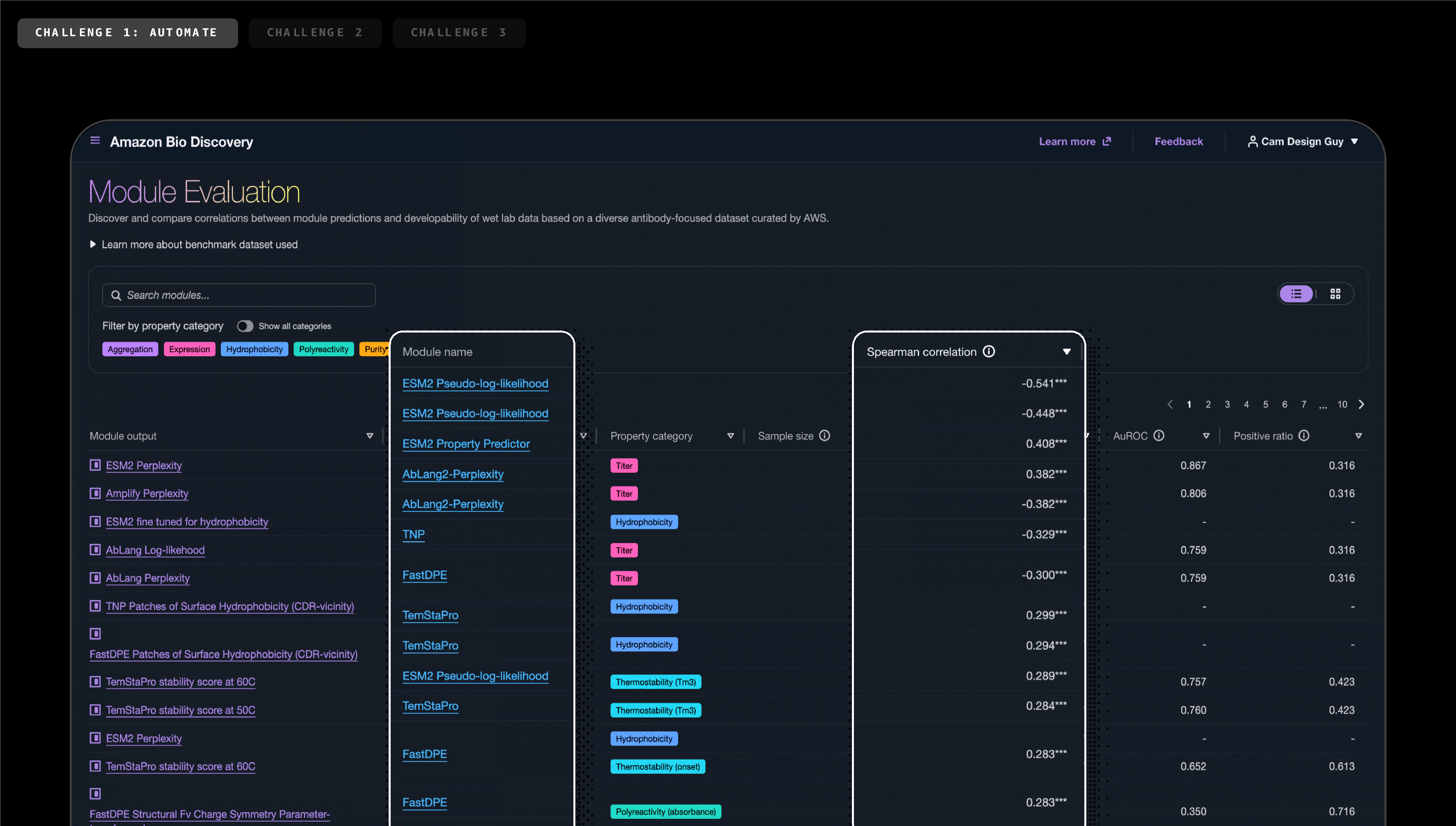
Amazon Bio Discoveryは、AI駆動の抗体探索に特化して構築された統合アプリケーションです。lab-in-the-loop ワークフローを阻害する最も一般的な課題——評価すべきモデルが多すぎる、データが断片化している、インシリコ実験とウェットラボでのバリデーションの調整が困難——に対処するよう設計されています。本アプリケーションは、これらを単一のセキュアでスケーラブルな環境に統合し、以下の機能を提供します:
- コードではなく科学用語で研究者をモデル選択・実験設計・候補評価へとガイドするエージェンティックAIアシスタント
- 40 以上のオープンソースおよび商用 Biological Foundation Model(生物学的基盤モデル)のカタログへのアクセス
- モデル間のヘッドトゥヘッドベンチマーク
- モデルトレーニング
これらすべてが GUI 操作のみで完結するため、あらゆる研究者が初日から高度な探索ワークフローを実行できます。
Memorial Sloan Kettering( MSK )との印象的なケーススタディでは、チームが Amazon Bio Discovery の AI エージェントを使用し、ターゲットタンパク質の実験構造データや既存の抗体データが一切ない状態から、新規のデスモプラスティック小円形細胞腫瘍( DSRCT )ターゲットに対する de novo ナノボディバインダーを設計しました。3 つの de novo 設計手法( RFantibody、IgGM、mBER )を使用して 288,000 以上の候補配列を生成し、多目的パレート最適化でフィルタリングした上で、上位候補を Twist Bioscience に送付しウェットラボでバリデーションを行いました。その結果、46 個のバインダーが確認され、トップ候補は KD = 0.66 nM のサブナノモル親和性を達成。ターゲット選定からラボでの検証完了まで、わずか数週間でした。Twist Bioscience は CRO(受託研究機関)パートナーとして抗体エンジニアリングと生物物理学的キャラクタリゼーションの専門知識を提供し、Amazon Bio Discovery の CRO パートナーネットワークが自社ラボの枠を超えて lab-in-the-loop 能力を拡張できることを示す好例となりました。

Boltz はセッションの最後に、Amazon Bio Discovery へ近日提供予定の独自基盤モデルをプレビューしました。改良された基盤モデルの上に、タンパク質-タンパク質親和性予測と開発性フィルターを追加しています。また、説得力のある推論時スケーリング則を実証しました:生成するデザイン数を増やすほどヒット率は継続的に向上し、60,000 から 180,000 デザインの範囲でも改善が続くことが示されました。
発見サイクルの加速:Sanofi の AWS 上の集中型 lab-in-the-loop
Sanofi の R&D データプラットフォーム&プロダクツ責任者である Sabya Dasgupta 氏と、プラットフォーム&AI ワークフロー責任者である Pradeep Bandaru 氏が、世界最大級の製薬企業の 1 つが AWS 上でエンタープライズ規模の lab-in-the-loop 能力をどのように構築しているかを共有しました。
Sanofiの取り組みから得られた核心的な洞察は、「コンテキストこそが新たなコンピュートである」ということです。パイプラインがどれだけ改善されても、科学的コンテキストを持たないAIエージェントは、すでに試みられた推奨を繰り返し、実験的背景を欠いたままデータを解釈し、良い判断ではなく悪い判断をスケールさせてしまいます。
Sanofi が辿り着いた答えが、 SWEL(Scientific Workflow Experience Labs)です。これは AI エージェントをコンテキスト認識型にし、複雑なコンピュートチェーンをオーケストレーションするオペレーションレイヤーです。AWS上に構築されAmazon Bedrock AgentCore を基盤とする SWEL は、創薬プロセスのあらゆる層にコンテキストを行き渡らせます。具体的には、AI 駆動の分子設計や SIPS(Sanofi 社の統合データ基盤)から始まり、実験の自動化、ワークフローの連携・計算処理のチェーンを経て、最終的には「この分子は過去にどのような検討を経たか」「前回のサイクルで何が起きたか」「なぜこの設計にしたか」「どこで失敗したか」といった文脈を理解する科学的推論エージェントにまでつながります。
成果は明白です:SWEL は MVP(Minimum Viable Product)を 2.5 か月で出荷し、現在 50 以上の科学ワークフローを支え、20 PB 以上の科学データプロダクトへのアクセスを提供し、同じ期間で 2~3 倍のプロジェクトを可能にし、デプロイ速度を 10 倍に加速しました。
際立つユースケースは AI Autolead でした。これは継続学習型のメディシナルケミストリーシステムで、10^13 を超える構造の特徴空間から、サイクルあたり 10 億以上の列挙分子をスクリーニングします。数百の ADME(Absorption, Distribution, Metabolism, Excretion:吸収・分布・代謝・排泄)モデルおよびターゲット AI モデルと、28 の検証済み反応を活用しています。結果:プログラムあたりの生成分子数が 50% 以上削減されつつヒット品質は向上し、ルーチンの de novo 設計が全モダリティで実行されるようになりました。
データインフラの側面では、AWS がエージェンティックコード生成によりインストルメントデータコンバーターの開発を大幅に加速できることを実演し、開発期間を数週間から数分に短縮しました。20 のインストルメントファイルタイプを対象とした評価では、ASM(Allotrope Simple Model)形式変換において 100% のパス率を達成し、ゼロショット生成の 35% と比較して大きな改善を示しました。
研究用途を超えたエージェント展開:Roche の Galileo プラットフォーム
Rocheのグローバルヘッド兼 VP Diagnostics R&D である Arick Huensche 氏が、Roche が 90,000 台以上の接続されたラボ機器を横断して、エージェンティック AI をエンタープライズ規模でどのように展開しているかを語りました。
Roche の Galileo プラットフォーム— Amazon Bedrock および Bedrock AgentCore 上に構築されたエージェンティック AIプラットフォーム——は研究プロトタイプではありません。70,000人以上のユーザーにサービスを提供し、Roche のDIA(Diagnostics)R&D ドメイン全体で 29 のエージェントがデプロイされた本番インフラです。このプラットフォームにより、AI エージェントがデータの移動、メタデータの抽出、結果のバリデーション、ワークフローのオーケストレーションを行い、厳密性とトレーサビリティを維持しながら、複雑な科学プロセスを自然言語でのインタラクションに変換します。
2つのプロトコルイノベーションが注目を集めました。MCP(Model Context Protocol:モデルコンテキストプロトコル)は、AgentCore Gateway を通じて利用され、数百のラボ機器 API、LIMS/ELN(Laboratory Information Management System / Electronic Lab Notebook:ラボ情報管理システム/電子実験ノート)コネクター、バイオインフォマティクスパイプラインのトリガーを、既存システムを書き換えることなく MCP ツールとして公開できるようにしています。もう一つのA2A(Agent-to-Agent:エージェント間通信)プロトコルは、エージェントフレームワークやベンダーを横断した自律的コラボレーションを可能にするものです。タスクライフサイクルの状態管理が定義されており、Strands、LangGraph、CrewAI、Google ADK、OpenAI SDK にまたがるクロスフレームワーク相互運用性を実現しています
Arick 氏の業界への主要なメッセージ:エージェントは広範な機能ではなく jobs-to-be-done(解決すべきジョブ)にスコープすること、エージェントの活用を考える前にまずデータ基盤へ重点投資すること、そしてガバナンスを制約ではなく機能として扱うこと。規制環境では、ビルトインのコンプライアンスが導入を加速します。なぜなら、科学者は監査可能なものを信頼するからです。
AWS ツールの観点からは、Brian Loyal 氏がデータサイエンス、バイオインフォマティクス、ラボプロセス自動化のワークフローにおいてお客様が AgentCore をどのように採用しているかを実演しました。これにより、チームは科学的厳密性を犠牲にすることなく、より迅速に前進できます。
AI サイエンスファクトリーのスケーリング:Lila Sciences
Lila Sciences の VP of Next Generation Platform である Bob Gantzer 氏は、lab-in-the-loop で何が達成できるかについての大胆なビジョン——AI サイエンスファクトリー——を発表しました。
Lila が構築しているのは、単一の AI モデル——いわば「科学的インテリジェンス」——であり、科学のサイクル全体を回すために必要なツール群を備えています:知識ベース、ユニバースシミュレーター、計算ツール、そして AI サイエンスファクトリーです。目標は科学的方法そのものを再発明することであり、機器の完全なパラメトリゼーション、動的実行、スケールされたデータパイプラインを通じて、AI がラボで自律的に仮説生成・実験・学習のサイクルを回す「セルフプレイ」を実現することです。
印象的なデモンストレーションでは、Lila のシームレスな mRNA 設計から実験までのワークフローが示されました。生成 AI による分子選択から、自動合成、ADME アッセイ実行、ML モデル再トレーニングまで——すべてがサイエンティフィックグラフ(科学ワークフローグラフ)を通じてオーケストレーションされています。Lila の mRNA 設計は業界トップクラスの in vivo 性能を実証しており、プラットフォームは現在、タンパク質、RNA、DNA、低分子、触媒、ナノ粒子、そしてその先にまで展開されています。
生物学向け AI モデルの進化:データ駆動型モデルトレーニング
最終セッションでは、Noetik CEO 兼共同創業者の Ron Alfa 氏、Apheris CEO 兼共同創業者の Robin Roehm 氏、Bristol Myers Squibb SVP Therapeutic Discovery Sciences の Payal Sheth 氏が集まり、生物学基盤モデルトレーニングの最前線について深く掘り下げました。
AWS は生物学基盤モデルの全体像を示しました:創薬に関連する公開済み基盤モデルの累積数は、2021 年初頭の1から2025 年半ばまでに 226 に成長し、タンパク質・分子構造、シングルセルトランスクリプトミクス、バイオイメージング、DNA配列、マルチモーダルデータにまたがっています。AWSは、Amazon Bio Discovery によるファインチューニングや Amazon Bedrockでのサーバーレスカスタマイゼーションから、Amazon SageMaker HyperPod での大規模分散トレーニング、Amazon Nova Forge によるフロンティアモデル開発まで、モデルカスタマイゼーションの全スペクトラムを提供しています。Nova Forge は、独自データを Amazon Nova のチェックポイントおよびキュレーションされたトレーニングデータとブレンドすることで、ゼロから構築する場合と比較して 10~100 分の 1 のコストでカスタムフロンティアモデルを構築できます。
BMS と Apheris は、AI Structural Biology(AISB)Network の次なる展開を紹介しました。AISB は製薬企業間の連合学習(Federated Learning)ネットワークであり、現在 9 社が参加して運用されています。AISB-1 連合コフォールディングモデルは、5 社のデータを用い 10 週間未満でトレーニングされ、構造的に信頼性の高い結合サイト相互作用の割合( lDDT > 0.8)において 51% を達成しました。これは OpenFold3 ベースラインの 34% 、平均的な単一企業ファインチューニングモデルの 39% と比較して優れた結果です。AISB-1 は現在 Amazon Bio Discovery で利用可能です。AISB-2 は開発中であり、構造データ、定量的親和性データ、HTS スケールのバイナリ活性データにわたる桁違いに多い独自データを使用して、構造ベースのバーチャルスクリーニング、リード最適化、オフターゲットスクリーニングのための、より広範で汎化性の高い基盤モデルを目指しています。

Noetik はセッションの最後に大胆な主張を展開しました:「 AI 創薬はこの10年間、間違ったデータ——細胞株、マウスモデル、パブリックデータセット——でトレーニングしてきた」。Noetik のアプローチはリアルなヒトデータから始まります。商業ルートで調達し自社が完全に権利を保有するヒト腫瘍検体( FFPE )を、特許出願中のロボティクス支援ワークフローで処理し、H&E、タンパク質、空間 RNA、DNA データとペアリングしています。このマルチモーダル患者データセットでトレーニングされた基盤モデルは、Noetik が特定した患者集団においてゼロショット推論で 56% の客観的奏効率( ORR )を達成しました。元の臨床試験での ORR 8% と比較して大幅な改善です。スケーリング則は生物学にも当てはまります:性能はモデルサイズとコンテキスト長に応じて大幅に向上し、プラトーの兆候は見られません。
エージェンティック・ディスカバリーの時代が到来
すべてのセッションを通じて、一つの共通メッセージが浮かび上がりました:創薬の未来は、より多くのモデルやコンピュートではなく——コンテキスト、オーケストレーション、そして AI と実験の間のループを閉じることにあります。
2026 AWS Life Sciences Symposium の研究・創薬トラックは、エージェンティック AI がもはや将来の約束ではないことを明確にしました。それは Sanofi、Roche、BMS などにおける本番インフラです。MSK における検証済みの科学です。Noetik における新しいアセットクラスです。そして、次世代の医薬品が構築される基盤です。
AWS は、この転換点においてライフサイエンス業界とパートナーシップを組めることを誇りに思います。科学的野心を患者へのインパクトに変えるコンピュート、モデル、データインフラ、エージェンティックフレームワークを提供してまいります。エージェンティック・ディスカバリーの時代は、すでに始まっています。問われているのは、構築するかどうかではなく——どれだけ速く構築するかです。