Amazon Web Services ブログ
AWS における AI エージェント対応のデータ基盤 (2) — SageMaker Catalog で行・列レベルのアクセス権を透過的に適用する
本記事は、シリーズ「AWS における AI エージェント対応のデータ基盤」の第 2 回です。第 1 回では、AI エージェントが組織の本番データに対して正しく動くために必要な 3 要素(認可・ビジネスデータカタログ・ドメイン知識)を紹介し、認可が効いている様子をデモで示しました。本記事では、3 要素のうち認可に焦点を当て、AI エージェント経由のデータアクセスに Amazon SageMaker Catalog のアクセス制御を透過的に効かせる実装パターンを解説します。
サンプルリポジトリ: aws-samples/sample-sagemaker-agentic-analyst
AI エージェントにアクセス制御を効かせる 3 つの壁
AI エージェントにデータアクセスを任せるとき、守るべき原則があります。エージェントは独自の認可ロジックを持たず、ユーザーが SageMaker Catalog で付与されている権限を、エージェント経由でもそのまま透過的に利用させることです(SageMaker Catalog は Amazon DataZone の上に構築されており、権限設定は DataZone API で操作します)。エージェント内に独自の認可ロジックを作ると、既存のガバナンスと二重管理になり、整合性を保つのが難しくなるからです。
この原則を実現しようとすると、素直な実装ではたどり着けない 3 つの壁があります。これらは本記事で解説する設計上の工夫によって越えられます。
壁 1: コンピュートリソース自体のロールで権限を取得すると、全ユーザーが同一権限になる。 AI エージェントのツールは AWS Lambda、AWS Fargate、Amazon EC2 など何らかのコンピュートリソース上で実行されます。そのコンピュートリソース自体のロール(たとえば Lambda の実行ロール)で DataZone の GetEnvironmentCredentials API を呼ぶと、返ってくるのはそのロール自身のメンバーシップに基づくプロジェクトロールです。どのユーザーがリクエストしても同じ認証情報が返るため、ユーザー個別のアクセス制御を効かせるには工夫が必要です。
壁 2: SAML フェデレーション経由のトークンには、IdP 側のグループ情報が乗らない。 AWS IAM Identity Center(以下 IdC)と、たとえば Amazon Cognito を SAML フェデレーションで連携する構成では、IdC 側のグループ情報が Cognito のトークンに自動的には含まれません。「データコンシューマーには athena_query を許可し、ドメイン管理者には cloudtrail_query のみ許可する」といったツール単位の認可を IdC のグループベースで行うには、グループ情報をトークンに載せる工夫が必要です。
壁 3: 設定時と実行時で関与するサービスが異なり、認可の全体像を把握する必要がある。 SageMaker Catalog の裏側では複数のサービスが連携しています。設定時に使うサービスと、クエリ実行時に評価されるサービスが異なるため、全体像を把握しないと正しい実装にたどり着けません。
本記事では、サンプルリポジトリ sample-sagemaker-agentic-analyst がこれらの壁をどう越えているかを解説します。
サービスの役割分担を整理する
本記事で扱うサービスの関係を先に整理します。
Amazon SageMaker Catalog は、データと AI の発見・ガバナンス・コラボレーションを担うサービスで、Amazon DataZone の上に構築されています。データの Publish/Subscribe やアクセス権の設定は SageMaker Catalog(および Amazon SageMaker Unified Studio の UI)で行いますが、実際のクエリ実行時に行・列レベルのアクセス制御を評価するのは AWS Lake Formation です。S3 上のファイルに対するアクセス制御は Amazon S3 Access Grants が担います。
つまり、SageMaker Catalog で「誰がどのデータを見てよいか」を 設定 し、Lake Formation と S3 Access Grants が 実行時 にその設定を評価する、という役割分担です。
重要な原則として、DataZone はクエリ実行パスに入りません。後述する認証情報変換フローでは DataZone API(RedeemAccessToken / GetEnvironmentCredentials)を呼びますが、これは AgentCore Gateway に接続された Lambda(以下 Tool Lambda)が プロジェクトロールの認証情報を取得する ための前段であり、Athena クエリや S3 オブジェクト取得そのものには DataZone は介在しません。クエリ実行時の認可評価は Lake Formation と S3 Access Grants が担います。この「認証情報取得の経路」と「データアクセスの経路」の分離を理解しておくと、以降のフローが読みやすくなります。
認証情報変換フロー: 5 つのステップ
壁 1 と壁 3 に対応するため、本サンプルでは 5 つのステップで認証情報を変換します。ブラウザでサインインしたユーザーの Cognito トークンから出発し、最終的にそのユーザーの権限が反映された SageMaker プロジェクトロールの一時認証情報を Tool Lambda の手元に届けます(下図)。
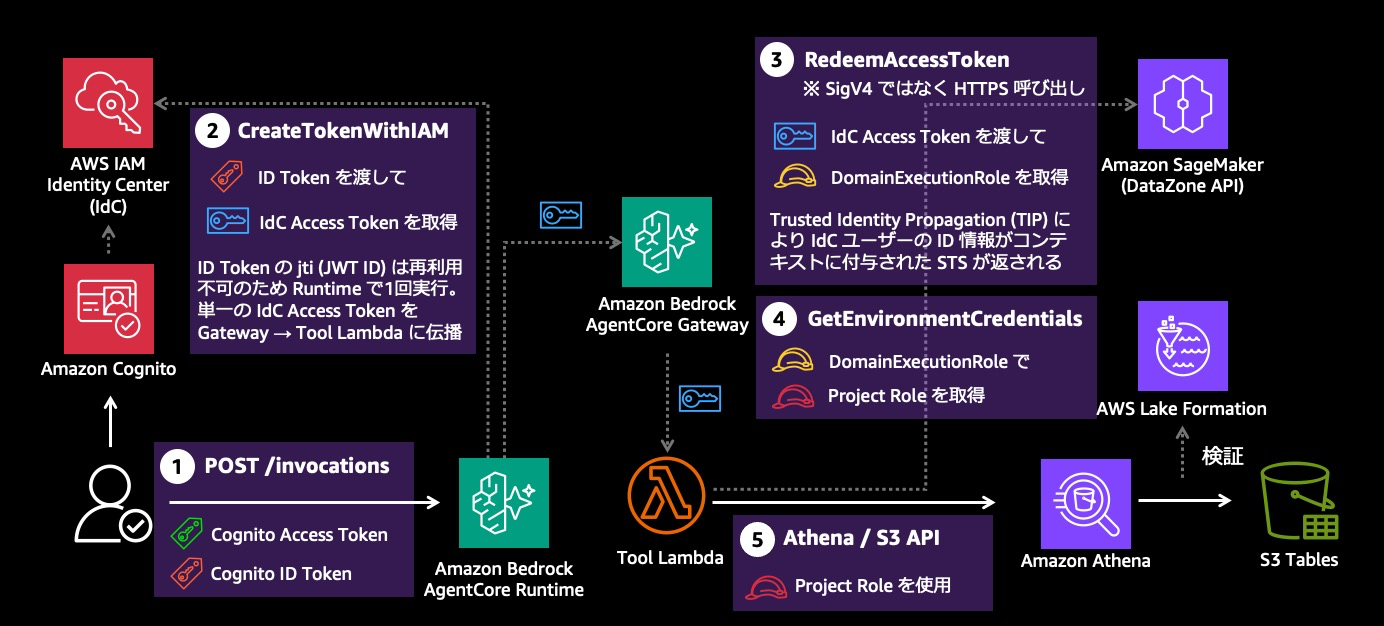
Step 1: ブラウザから AgentCore Runtime へ
ブラウザ上の React アプリが、Amazon Bedrock AgentCore Runtime のエンドポイントに HTTPS リクエストを送ります。このリクエストには 2 つのトークンが乗っています。
Authorization: Bearer <Cognito Access Token>— Runtime の Cognito Authorizer が検証します- カスタムヘッダー
X-Amzn-Bedrock-AgentCore-Runtime-Custom-Cognito-Id-Token: <Cognito ID Token>— 次のステップで使います
Cognito Access Token と Cognito ID Token はどちらも Amazon Cognito が発行する JSON Web Token(JWT)ですが、役割が異なります。Access Token は「このリクエストは正当なユーザーから来たか」を Runtime と Gateway が判定するために使います。ID Token はユーザーのアイデンティティ情報(メールアドレスなど)を含んでおり、次のステップで IdC のユーザーと突き合わせるために使います。
Step 2: chat-agent が Cognito ID Token を IdC Access Token に引き換える
Amazon Bedrock AgentCore Runtime はエージェントプロセスをホストするマネージドサービスです。呼び出し主体はその上で動くユーザーコード(本サンプルでは chat-agent)であり、Runtime サービス自身がトークン変換を自動で行うわけではありません。chat-agent が IdC の CreateTokenWithIAM API を呼びます。
const tokenRes = await new SSOOIDCClient({ region }).send(
new CreateTokenWithIAMCommand({
clientId: idcApplicationArn,
grantType: 'urn:ietf:params:oauth:grant-type:jwt-bearer',
assertion: cognitoIdToken,
}),
);
const idcAccessToken = tokenRes.accessToken;jwt-bearer grant で Cognito ID Token を渡すと、IdC はそのクレームから IdC ユーザーを特定し、IdC Access Token を返します。
ここで 2 つの補足があります。
Cognito JWT と IdC Access Token は別物です。 発行者が違い(Cognito vs IdC)、形式も違います(JWT vs 不透明トークン)。Cognito JWT は Cognito 連携アプリでしか通用しませんが、IdC Access Token は IdC の Trusted Identity Propagation(TIP) に対応した AWS サービスで通用します。TIP は、IdC ユーザーのアイデンティティを IAM ロールの STS セッションに identity context として伝播させる仕組みです。DataZone は TIP 対応サービスの 1 つで、RedeemAccessToken はその入口に位置します。CreateTokenWithIAM と RedeemAccessToken は、このトークンの世界をまたぐブリッジの役割を果たします。
ただし本サンプルでは、TIP の identity-enhanced session をそのままデータ層まで持ち込んで Lake Formation や S3 Access Grants に評価させる構成は採っていません。SageMaker Catalog の Publish/Subscribe モデルが プロジェクトロール に行・列・オブジェクトレベルの権限を付与する設計になっているため、IdC ユーザーのアイデンティティは RedeemAccessToken → GetEnvironmentCredentials を経由してプロジェクトロールへ引き換えられ、以降のデータアクセスはプロジェクトロールの権限で評価されます。TIP の役割はこの引き換えの前段に限定され、本記事の焦点もそこにあります。
CreateTokenWithIAM には jti 制約があります。 JWT には jti(JWT ID)という一意識別子のクレームがあり、IdC は jwt-bearer grant で受け取った JWT の jti を記録します。同じ jti の JWT が再度送られると拒否されるため、同一の Cognito ID Token で CreateTokenWithIAM を 2 回呼ぶことはできません。このため、chat-agent で 1 リクエストあたり 1 回だけ実行し、得られた IdC Access Token を x-idc-access-token カスタムヘッダーで AgentCore Gateway 経由で全 Tool Lambda に伝播する設計になっています。
なお、CreateTokenWithIAM を呼ぶための IAM アクション名は sso-oauth:CreateTokenWithIAM です。SDK クライアントは SSOOIDCClient を使いますが、IAM ポリシー側のサービス名は sso-oauth になります。また、IdC の OAuth Customer Managed Application に datazone:domain:access スコープを事前に登録しておく必要があります。
Step 3: Tool Lambda が IdC Access Token を DomainExecutionRole の認証情報に引き換える
Tool Lambda が Amazon DataZone の RedeemAccessToken エンドポイントに HTTP POST を投げます。
const redeemRes = await fetch(
`https://datazone.${region}.api.aws/sso/redeem-token`,
{
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ domainId, accessToken: idcAccessToken }),
},
);
const { credentials: domainExecRoleCreds } = await redeemRes.json();RedeemAccessToken は AWS SDK に含まれていません。 公開ドキュメントでは Athena JDBC ドライバ経由の利用例(Analyze subscribed data via JDBC)が示されていますが、サーバーサイドアプリからの直接呼び出しは生の HTTP リクエストで行う必要があります。このため、エンドポイント URL も通常の DataZone SDK が使う datazone.{region}.amazonaws.com ではなく datazone.{region}.api.aws を指定します。
この API には 2 つの特徴があります。SigV4 署名が不要であること(認証は IdC Access Token 自体が行う)、そして jti 制約がないため並列の Tool 呼び出しで複数の Lambda が同じ IdC Access Token を使っても問題ないことです。
返ってくるのは DomainExecutionRole の一時認証情報(accessKeyId / secretAccessKey / sessionToken / expiration)です。DomainExecutionRole は SageMaker Unified Studio ドメインに紐付く IAM ロールで、この認証情報には IdC ユーザーのアイデンティティが紐付いています。内部的には、RedeemAccessToken が DomainExecutionRole を assume する際に、Step 2 で触れた TIP の仕組みにより STS セッションに IdC ユーザーの identity context が埋め込まれます。これが次のステップで効いてきます。
Step 4: Tool Lambda が DomainExecutionRole の認証情報でプロジェクトロールを取得する
Tool Lambda が Amazon DataZone SDK を DomainExecutionRole の認証情報で 初期化し、GetEnvironmentCredentials を呼びます。
const envCreds = await new DataZoneClient({
region,
credentials: domainExecRoleCreds,
}).send(
new GetEnvironmentCredentialsCommand({
domainIdentifier: domainId,
environmentIdentifier: environmentId,
}),
);Amazon DataZone は呼び出し元の STS セッションから identity context を取り出し、IdC ユーザーを特定します。そのユーザーがプロジェクトのメンバーであれば、プロジェクトロールの一時認証情報を返します。メンバーでなければ拒否されます。
ここが本サンプルの核心です。DomainExecutionRole の認証情報で呼ぶからこそ、ユーザー本人のメンバーシップ で認可が評価されます。もし Lambda 実行ロールで直接 GetEnvironmentCredentials を呼んでいたら、Lambda 実行ロール自身のメンバーシップで判定されてしまい、ユーザーごとの権限差が消えます。
Step 5: プロジェクトロールで Athena / S3 を呼び出す
Tool Lambda が Athena や S3 のクライアントを プロジェクトロールの認証情報で 初期化し、クエリやオブジェクト取得を実行します。
const athena = new AthenaClient({
region,
credentials: {
accessKeyId: envCreds.accessKeyId,
secretAccessKey: envCreds.secretAccessKey,
sessionToken: envCreds.sessionToken,
},
});Athena がクエリを実行すると、Lake Formation がプロジェクトロールの権限に基づいて行・列レベルのフィルタリングを透過的に適用します。ユーザーの権限の範囲内にある行と列だけが結果として返り、範囲外の情報は応答に含まれません。
ステップのまとめ
| Step | 主体 | API | 入力 | 出力 |
|---|---|---|---|---|
| 1 | ブラウザ → Runtime | POST /invocations | — | Cognito Access Token + ID Token(Runtime に到達) |
| 2 | chat-agent → IdC | CreateTokenWithIAM |
Cognito ID Token | IdC Access Token |
| 3 | Tool Lambda → DataZone | RedeemAccessToken |
IdC Access Token | DomainExecutionRole 認証情報 |
| 4 | Tool Lambda → DataZone | GetEnvironmentCredentials |
DomainExecutionRole 認証情報 | プロジェクトロール認証情報 |
| 5 | Tool Lambda → Athena/S3 | StartQueryExecution / GetObject 等 |
プロジェクトロール認証情報 | クエリ結果 / オブジェクト |
Step 5 の S3 アクセスは Publisher と Subscriber で経路が分かれます。後述の「Publisher と Subscriber で異なる S3 アクセス方式」で詳述します。
この設計では、Lambda 実行ロールはデータアクセスに一切使いません。権限判定はすべてユーザーに紐付いた認証情報で行われます。
Policy in AgentCore によるツール単位認可
認証情報変換フローはデータアクセスの認可を扱いますが、「どのユーザーがどのツールを呼べるか」という別軸の認可も必要です。AgentCore の認可モデルは、Inbound(ユーザー → AI エージェントへの入口) と Outbound(AI エージェント → ツールへの出口) の 2 軸で整理されます。Inbound は AgentCore Runtime の JWT Authorizer が Cognito Access Token を検証して「この呼び出し元はエージェントを呼んでよいか」を判定します。Outbound はツール単位の認可で、本サンプルでは AgentCore Gateway の Policy in AgentCore で実現しています(下図)。
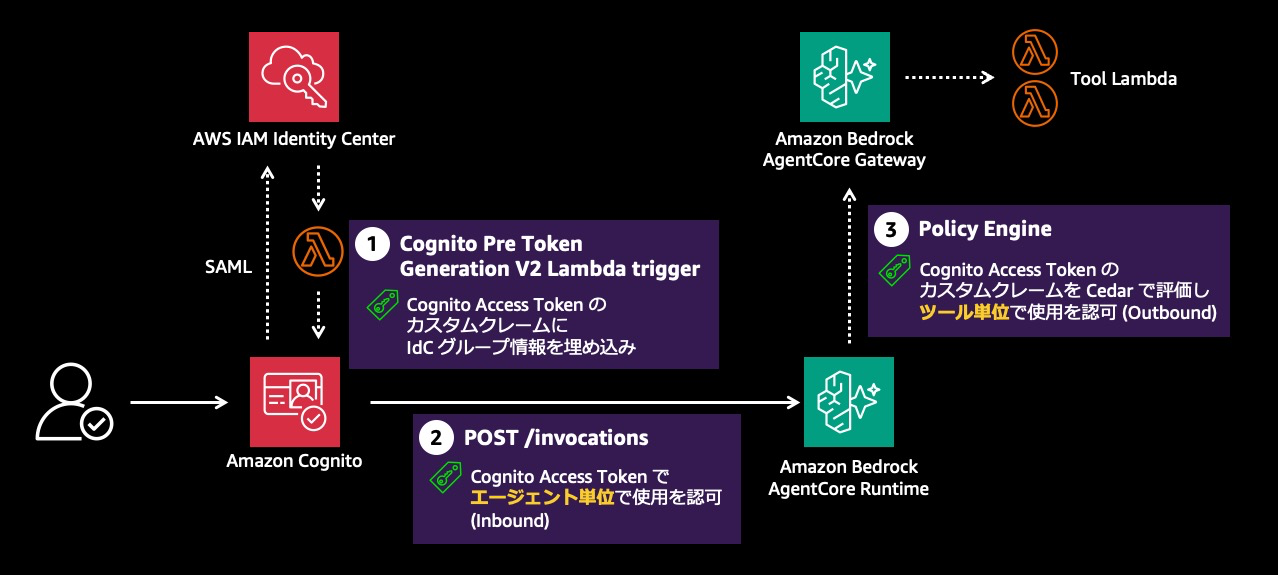
グループ情報の埋め込み
壁 2 で述べた通り、IdC と Cognito を SAML フェデレーションで連携する構成では、IdC 側のグループ情報は Cognito トークンに自動的には含まれません。本サンプルでは、Amazon Cognito の Pre token generation Lambda trigger の V2 イベントを使い、Cognito Access Token に cedar_groups カスタムクレームを埋め込みます。値は |data-producers|security-auditors| のようにパイプ区切りの文字列です。
Cedar ポリシーによる評価
Policy in AgentCore では、Cedar 言語で記述されたポリシーを policy engine に登録し、それを AgentCore Gateway に関連付けます。Gateway にリクエストが到達すると、policy engine が Cognito Access Token の cedar_groups クレームを読み取り、Cedar ポリシーで評価します。Gateway はリクエスト時点で JWT のクレームを AgentCore::OAuthUser エンティティのタグとして Entity Store に格納するため、ポリシー上は principal.getTag("cedar_groups") のようにタグとして参照します。「JWT では cedar_groups クレーム、Cedar ポリシーでは cedar_groups タグ」という名前の対応関係です。
permit(
principal is AgentCore::OAuthUser, action,
resource == AgentCore::Gateway::"<gateway-arn>"
) when {
principal.hasTag("cedar_groups") &&
principal.getTag("cedar_groups") like "*|security-auditors|*" &&
(action == AgentCore::Action::"cloudtrail-query___cloudtrail_query")
};このポリシーは「security-auditors グループに属するユーザーだけが cloudtrail_query ツールを呼べる」ことを宣言しています。アクション名の cloudtrail-query___cloudtrail_query は、AgentCore Gateway が MCP ツール定義から自動生成する命名で、ターゲット名(cloudtrail-query)___ ツール名(cloudtrail_query) の形を取ります。
Cedar の policy engine は default-deny(明示的に許可されない限り拒否)で動作します。上記の 1 本のポリシーだけでは security-auditors 向けの 1 ツールしか許可されていないため、他のユーザー・他のツールはすべて拒否されます。同様のポリシーを複数定義することで、たとえばデータコンシューマーには athena_query と s3_read のみを許可し、データプロデューサーにはカタログ管理ツールも許可する、といった職務分離を実現できます。
Policy in AgentCore によるツール単位認可と、認証情報変換フローによるデータアクセス認可は独立した 2 つの軸です。Gateway で「このユーザーはこのツールを呼んでよいか」を判定し、Tool Lambda で「このユーザーはこのデータを見てよいか」を判定します。
Publisher と Subscriber で異なる S3 アクセス方式
非構造化データ(S3 上のファイル)へのアクセスは、プロジェクトの役割によって経路が異なります。Amazon S3 Access Grants は、S3 の prefix / bucket / object 単位で IAM プリンシパルやディレクトリユーザーに READ/WRITE/READWRITE 権限を付与する仕組みで、GetDataAccess API で当該対象への一時認証情報を取得してから S3 API を呼ぶ形で利用します。SageMaker Catalog の Publish/Subscribe は、この Grant を Subscriber のプロジェクトロールに対してのみ自動作成する 設計です。Publisher 側のプロジェクトロールには明示的な Grant が作られず、Publisher は別のパス(IAM ポリシーによる直接アクセス)でバケットを読みます。これが Publisher/Subscriber で経路が分かれる理由です。
Publisher(プロジェクトがバケットを所有する場合): プロジェクトロールの認証情報で直接 S3:GetObject を呼びます。アクセス権は、プロジェクトロールに付与された IAM インラインポリシー(プロジェクト配下のプレフィックスに限定)によって許可されます。Publisher プロジェクトロール自身への明示的な S3 Access Grants の Grant は存在しないため、GetDataAccess は失敗します。
Subscriber(別プロジェクト経由で購読する場合): SageMaker Unified Studio の Publish/Subscribe が Subscriber ロールに対して IAM タイプの Grant を自動作成します。Tool Lambda はまず S3Control:GetDataAccess で一時認証情報を取得し、その認証情報で S3:GetObject を呼びます。
判断ロジックは、コネクションの accessRole の有無とプロジェクトの所有関係で決まります。プロジェクトレベルのコネクションで accessRole があれば S3 Access Grants 経由、なければ直接アクセスです。
まとめと次のアクション
本記事では、AI エージェント経由のデータアクセスに SageMaker Catalog のアクセス制御を透過的に効かせる実装パターンを解説しました。
- 設定時と実行時の役割分担 を整理し、SageMaker Catalog / DataZone が設定を担い、Lake Formation / S3 Access Grants が実行時に認可を評価する構造を明確にする
- 認証情報変換フロー(
CreateTokenWithIAM→RedeemAccessToken→GetEnvironmentCredentials)で、ユーザーに紐付いたプロジェクトロールの認証情報を Tool Lambda に届ける - Policy in AgentCore で、ツール単位の認可をデータアクセス認可とは独立した軸で制御する
Lambda 実行ロールはデータアクセスに一切使わず、権限判定はすべてユーザーに紐付いた認証情報で行われます。これにより、SageMaker Catalog で設定された行・列・オブジェクトレベルのアクセス権は、AI エージェント経由でも透過的に適用されます。
第 1 回で紹介した拡張性(ゼロショット時系列予測のオンデマンド実行)も、本記事で解説した認可の仕組みに支えられています。アクセス制御されたデータを、追加の認証設計なしで Amazon SageMaker AI の推論エンドポイントに流し込めるのは、プロジェクトロールの認証情報が Tool Lambda の手元まで届いているからです。サンプルリポジトリの apps/gateway-tools/time-series-forecast/ と design/data-access-control.md で実装の詳細を確認できます。
