Amazon Web Services ブログ
AWS における AI エージェント対応のデータ基盤 (1) — ツールを配る時代から、データを返す時代へ
AI エージェントに本番データを分析させるには、単にモデルと API をつなぐだけでは足りません。認可、ビジネスデータカタログ、ドメイン知識の 3 要素が揃うことで、エージェントは組織のアクセス制御とデータ構造を尊重した形で動作できます。
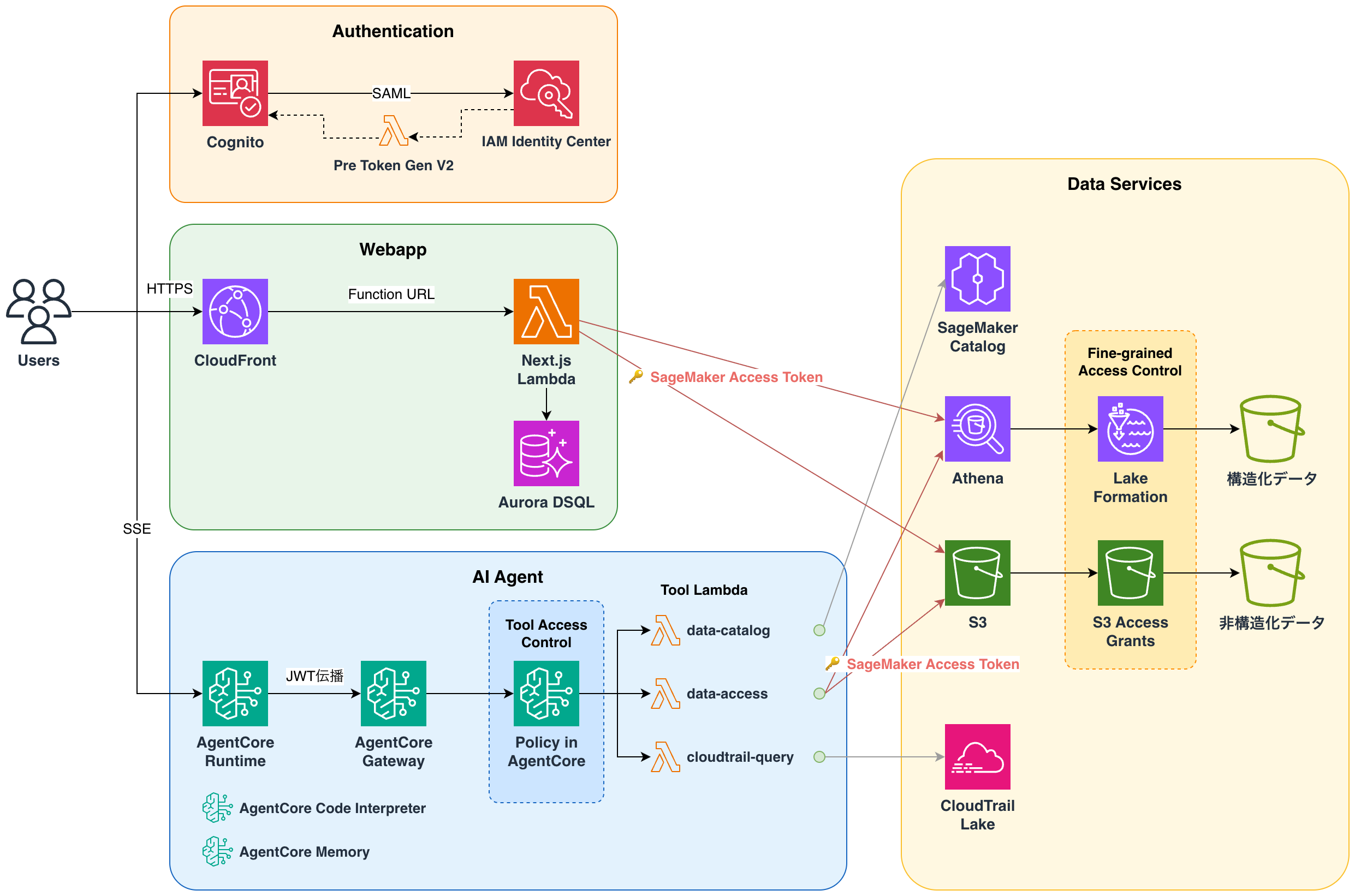
本記事は、シリーズ「AWS における AI エージェント対応のデータ基盤」の第 1 回です。Amazon SageMaker を使用したデータ分析エージェントの参照実装としてサンプルリポジトリ aws-samples/sample-sagemaker-agentic-analyst を公開しました。本記事ではこのサンプルを題材に、3 要素がどう組み立てられているかを俯瞰し、2 つのデモシナリオで実際の挙動を見ていきます。また、AI エージェント対応のデータ基盤でできることの例として、従来は個別のモデルトレーニングが必要だった時系列予測を、任意のデータかつゼロショットで実行する例も紹介します。認可の実装詳細は第 2 回で扱います。
ツールを配る時代から、データを返す時代へ
組織のデータを業務で活用したい場合、利用者はこれまで BI ツール、ダッシュボード、SQL エディタといったツールを使って、自分でデータにたどり着く必要がありました。「先月の関西エリアの売上の前年同月比を見たい」と思ったら、ダッシュボードを開き、フィルタを設定し、数値を読み取ります。慣れていない利用者は、ツールの使い方を覚えるところから始めなければなりません。
AI エージェントがあれば、要求の形が変わります。利用者はチャット UI に「先月の関西エリアの売上の前年同月比を見せて」と依頼すれば、エージェントが利用者の権限を代行してデータを取得し、集計し、結果を返します。利用者はツールの操作を学ぶ必要はありません。必要なのは、何を知りたいかを言葉で伝えることだけです。
この変化を成立させる要素は 3 つあります。
第 1 に、認可がデータ層で効いていること。 エージェントは利用者本人の権限でデータを取得する必要があります。例えば「AWS Lambda の実行ロールに全てのデータへのアクセス権を与え、利用者が見てよい範囲は LLM に判断させる」という仕組みは成立しません。システムプロンプトはユーザーからの指示によって上書きされる可能性があるからです。このため、アクセス制御は LLM の外側、データ層で効かせる必要があります。行・列・オブジェクトレベルのアクセス制御は、データ層で宣言的に設定され、利用者を特定した認証情報でクエリが実行されなければなりません。
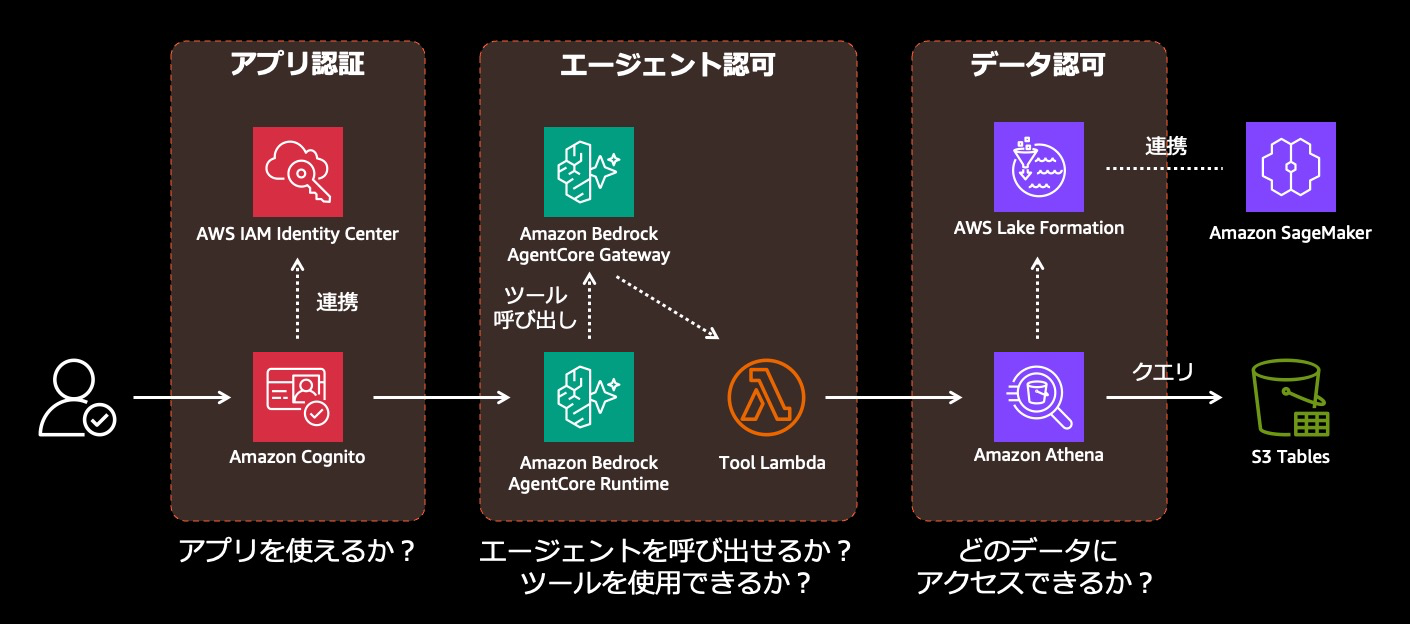
第 2 に、データがカタログ化され、エージェントから発見可能であること。 エージェントは組織のどこにどんなデータがあるか知らなければ、正しいクエリを実行できません。エージェントのコンテキストウィンドウをあふれさせる前に、的確にデータを発見するための仕組みが必要です。
第 3 に、ドメイン知識がエージェントに届くこと。 同じ「アクティブユーザー」という語でも、組織ごとに定義が違います。「週次レポートでは前週比と前年同週比を併記する」といった分析パターンも組織ごとに異なります。こうした文脈をエージェントに渡す方法がないと、一般的には正しいが組織の文脈と合わない回答や、あるいはもっともらしく見える誤ったデータを返す可能性があります。
本記事で紹介するサンプルは、これら 3 要素を Amazon SageMaker Catalog、Amazon Bedrock AgentCore、AWS Lake Formation、Amazon S3 Access Grants の組み合わせで実装しています。
AI エージェント対応のデータ基盤の 3 要素
3 要素がサンプルでどのように実装されているかを表にまとめます。
| 要素 | 役割 | 本サンプルでの実装 |
|---|---|---|
| 認可 | 触ってよいデータ・使ってよいツールを制御する | SageMaker Catalog(AWS Lake Formation + Amazon S3 Access Grants)で設定された行・列・オブジェクトレベルのアクセス権が、エージェント経由のデータアクセス時にも透過的に評価される。ツール単位の認可は、エージェントからツールへのリクエストを仲介する Amazon Bedrock AgentCore Gateway 上で、Policy in Amazon Bedrock AgentCore により管理する |
| ビジネスデータカタログ | どこにどんなデータがあるかを発見させ、正しいデータに導く | SageMaker Catalog をエージェントから検索・参照できるツール(catalog_search / catalog_detail)として提供する。Publish/Subscribe モデルと整合する |
| ドメイン知識 | 組織固有の語彙・パターン・嗜好を注入する | SageMaker Catalog のアセット説明・ビジネス用語集を通じて、組織のデータ資産そのものがエージェントのドメイン知識源になる。Amazon Bedrock AgentCore Memory がチャット履歴を担当する |
認可: 宣言的な設定を透過的に適用する
Amazon SageMaker Catalog は、データと AI の発見・ガバナンス・コラボレーションを担うサービスで、Amazon DataZone の上に構築されています。データプロデューサーがテーブルやファイルを Publish し、データコンシューマーが Subscribe することで、プロジェクト単位の権限が宣言的に設定されます。
このデータ層の認可では、権限を設定する場所と、権限が適用される場所が分離されているのが特徴です。設定は SageMaker Catalog 上で Publish/Subscribe モデルに沿って行い、実際のアクセス制御はクエリ実行時に別のサービスで適用されます。行・列レベルのフィルタリングは、データレイクに対するきめ細かなアクセス制御を担う AWS Lake Formation が適用します。S3 オブジェクトへのアクセスは、利用者・グループ単位で管理する Amazon S3 Access Grants が適用します。
AI エージェントがデータアクセスするときも、同じ認可設定がそのまま効きます。エージェントの内部にアクセス制御ロジックを書く必要はありません。利用者が SageMaker Catalog で付与されている権限が、エージェント経由のアクセスに対しても同じように評価されます。具体的な実装パターン(ブラウザのログインセッションから Tool Lambda の手元までプロジェクトロールの一時認証情報を運ぶ仕組み)は第 2 回で扱います。
ツール単位の認可は別軸で必要になります。たとえばセキュリティ監査ロールには CloudTrail 検索ツールだけを許し、データコンシューマーには Athena クエリと S3 読み取りだけを許す、といった職務分離です。本サンプルでは、Policy in Amazon Bedrock AgentCore により、AgentCore Gateway に接続されたツールの実行がグループベースのポリシーで制御されます。
ビジネスデータカタログ: エージェントから発見可能にする
SageMaker Catalog は UI から人間が検索するだけのものではありません。本サンプルでは、エージェントがツール経由で検索・参照できるよう、以下の Tool を独自に実装して AgentCore Gateway 経由で提供しています。
catalog_search: 自然言語クエリやキーワードでアセットを検索するcatalog_detail: 特定アセットの詳細(スキーマ、説明、ビジネス用語集との関連)を取得する
エージェントは、利用者の問いに応じてまずカタログを検索し、適切なテーブルを特定してからクエリを組み立てます。検索は Subscribe 済みアセットに絞り込むか、カタログ全体を対象にするかを選べます。Subscribe 済みに絞ると回答は利用者の現在の権限で得られる範囲に限定されます。一方、全体検索では Subscribe していないアセットも「未購読」として識別できるため、必要であれば利用者に Subscribe 申請を促すこともできます(デモ 2 で扱います)。いずれの場合も、実際のデータアクセスは利用者本人の権限で実行されるため、Subscribe していないアセットのデータを勝手に読むことはできません。
ドメイン知識: データ資産に書き込む
ドメイン知識には、組織内で共有されるものと、利用者個人に紐付くものがあります。本サンプルでは、それぞれを注入できるパスを以下のように整理しています。
| 種類 | 注入できるパス |
|---|---|
| 組織固有の語彙・定義(例: 「アクティブユーザー」の定義) | SageMaker Catalog のアセット説明・ビジネス用語集。データプロデューサーが Publish 時に書き込むと、そのままエージェントが参照できる |
| 分析パターン・クエリテンプレート(例: 月次売上では必ず前年同月比も出す) | システムプロンプトへの注入、SageMaker Catalog のアセット説明への記述、Agent Core Memory のセマンティック検索 |
| 利用者個人の嗜好・履歴(例: 関西エリアの分析をよく頼む) | AgentCore Memory の長期記憶 |
ポイントは、カタログのメタデータだけでは似たテーブルを区別できない場面が多いことです。たとえば sales_daily と sales_fact がどちらも売上を表していても、一方は速報値で一方は確定値かもしれません。この違いを自然言語でアセット説明に書き込めば、エージェントは正しいテーブルを選べます。ドメイン知識をデータ資産そのものに書き込む文化が、エージェントの回答品質を左右します。
補足: SQL 生成とセマンティックレイヤー
AI エージェントにデータ分析を任せる際のアプローチは、大きく 2 つに整理できます。1 つは本サンプルのようにエージェントが SQL を直接生成する方法(Text-to-SQL)、もう 1 つは事前に定義したメトリクスと次元を持つセマンティックレイヤーを通じて問い合わせる方法です。前者は任意の問いに柔軟に応答でき、後者は正確性と決定性が必要な分析を安定して返せます。どちらが優れているというより、組織のデータ成熟度と用途で使い分けるのが現実的です。
本サンプルのアーキテクチャは、どちらのアプローチにも寄せられる構造を持ちます。Amazon Bedrock AgentCore Gateway は任意のツールを AWS Lambda 上で実装して接続できるため、athena_query のような汎用的な SQL 実行ツールと、sales_monthly_metric のように事前にパラメータ化されたツールを、同じエージェントに共存させられます。広いカバレッジを Text-to-SQL で取りつつ、よくあるユースケースや間違えてはいけない分析だけをセマンティックレイヤー相当のツールとして事前定義する、という運用も組めます。SageMaker Catalog のアセット説明・ビジネス用語集は、どちらのアプローチでもドメイン知識の伝達路として使えます。
デモ
3 要素がどう協調して動くかを、2 つのシナリオで見ていきます。
デモ 1: 構造化データと非構造化データを束ねて分析する
営業分析担当者が「店舗別の売上傾向を知りたい」と問いかけるところから始まります。
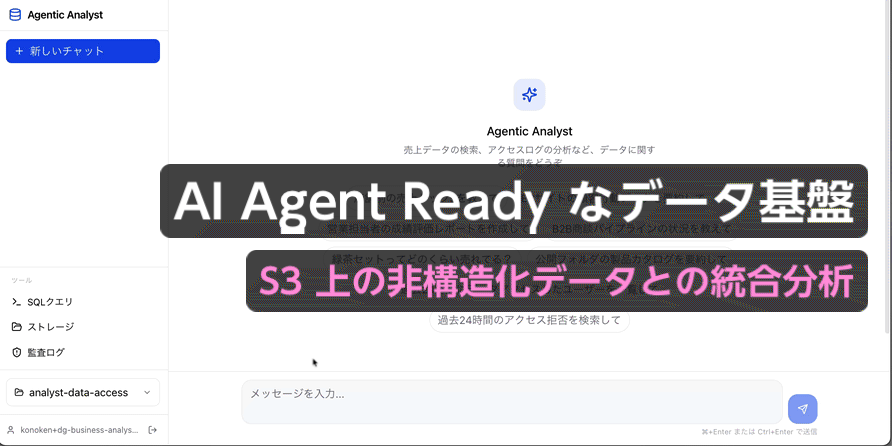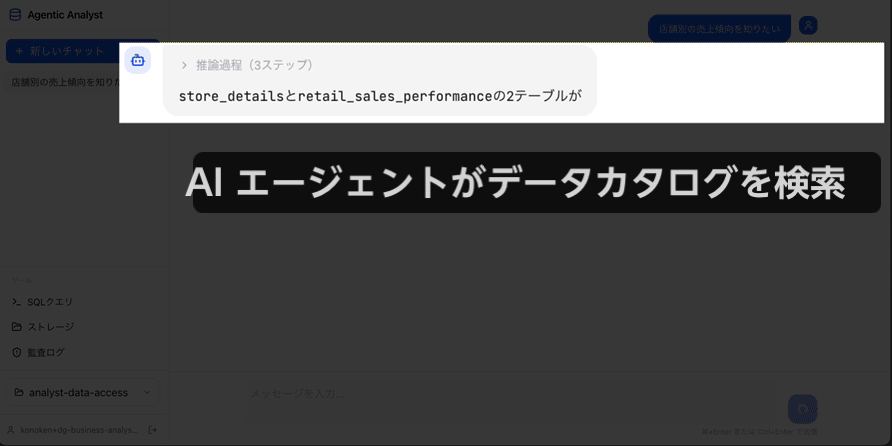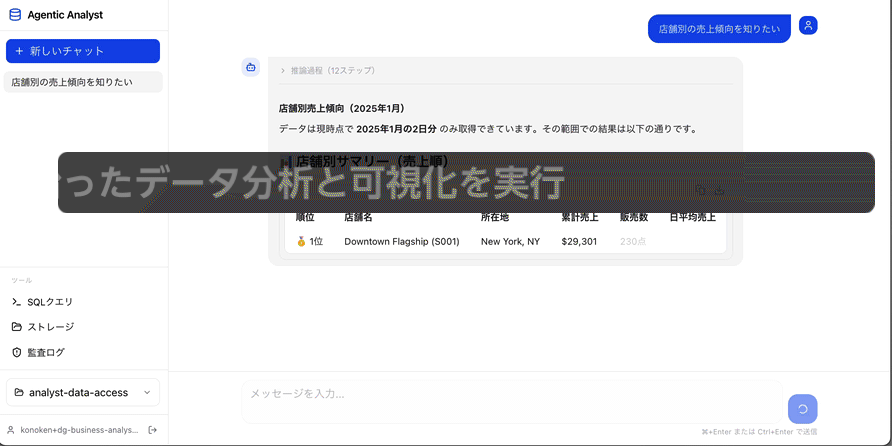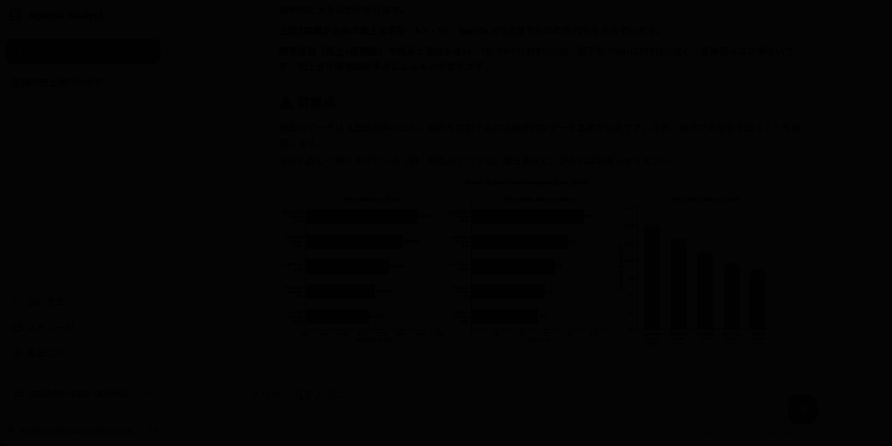
エージェントはまず SageMaker Catalog を検索し、売上テーブルを見つけます。利用者本人の権限で Amazon Athena にクエリを投げ、店舗別の集計を取得します。Amazon Bedrock AgentCore Code Interpreter で集計結果を可視化し、グラフと短い解釈を返します。ここで効いている要素は次の通りです。
- ビジネスデータカタログ: 利用者はテーブル名を知らなくてよい。エージェントがカタログから探す
- 認可: クエリは利用者本人の権限で実行される。Subscribe していないアセットはエージェントが検索で「未購読」と判別できる
- ドメイン知識: 「店舗別の売上傾向」という問いを、適切な集計粒度に落とし込む
続いて利用者が「既存の製品カタログを読んで、製品ごとのトレンドを分析して」と依頼します。ここでは、品番は売上テーブルにありますが、品名や製品説明はテーブルには含まれておらず、Amazon S3 上のテキストファイル(製品カタログ)にしかないという状況です。

エージェントは S3 からテキストファイルを取得し、そこに書かれた品名・説明と売上データを突き合わせて、製品カテゴリごとのトレンドを分析します。構造化データ(Athena / Lake Formation)と非構造化データ(S3 / S3 Access Grants)を同じ会話の中で束ねられるのは、どちらも利用者本人の権限で取得しているからです。
デモ 2: 権限のないデータへのアクセスを、エージェントが仲介する
もう 1 つのシナリオは、データへのアクセス権がまだない状況から始まります。利用者が「B2B 商談パイプラインの状況を教えて」と問いかけます。
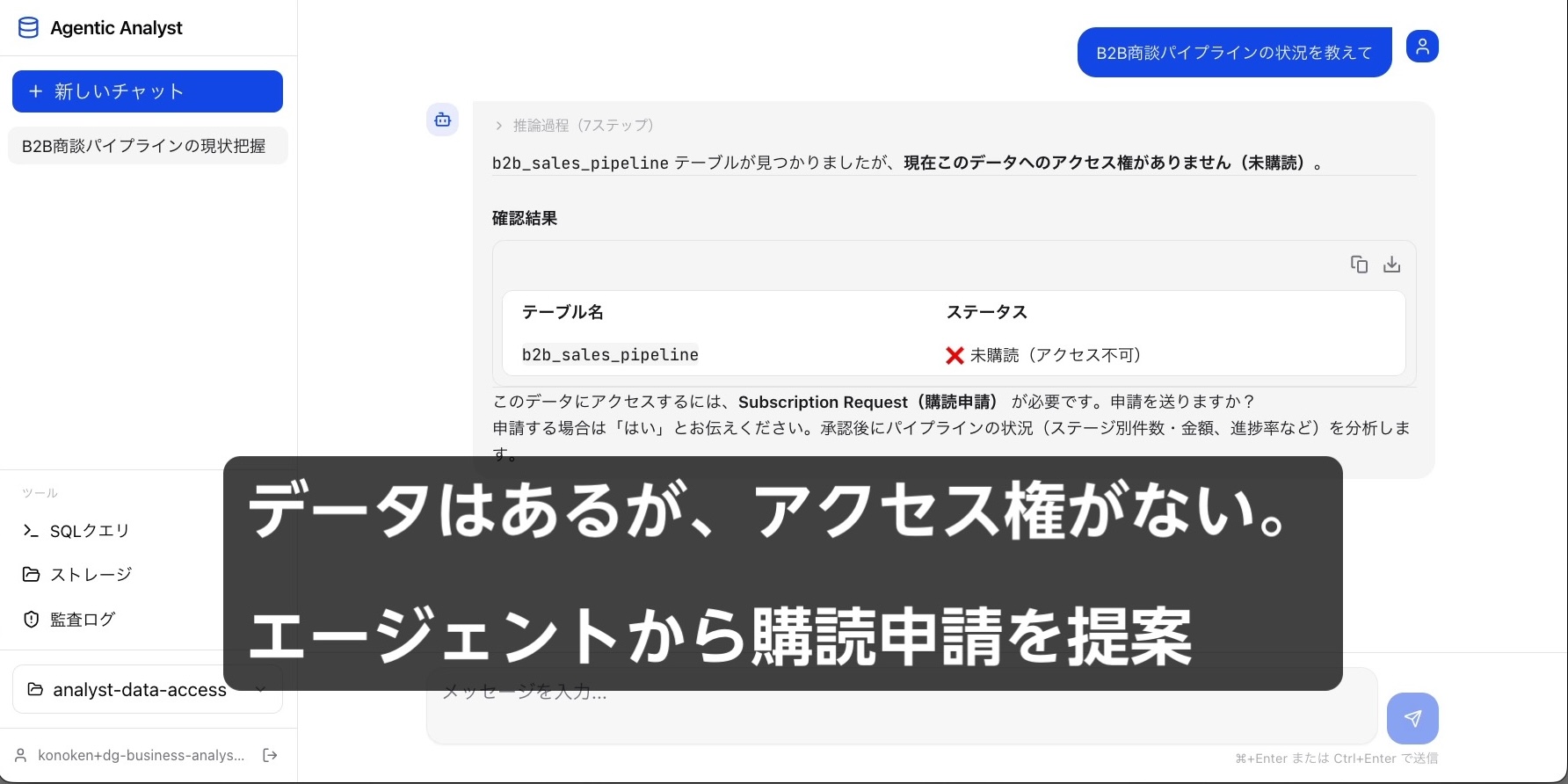
カタログには B2B 商談データがありますが、利用者のプロジェクトはまだ Subscribe していません。エージェントはデータにアクセスできないことを伝え、利用者の指示に従って SageMaker Catalog に Subscribe 申請を出します。申請自体をエージェントが Amazon DataZone の API 経由で実行します(上のスクリーンショット)。
次に、データ所有者の操作に移ります。データ所有者は Amazon SageMaker Unified Studio にログインし、届いている Subscribe 申請を確認して承認します。
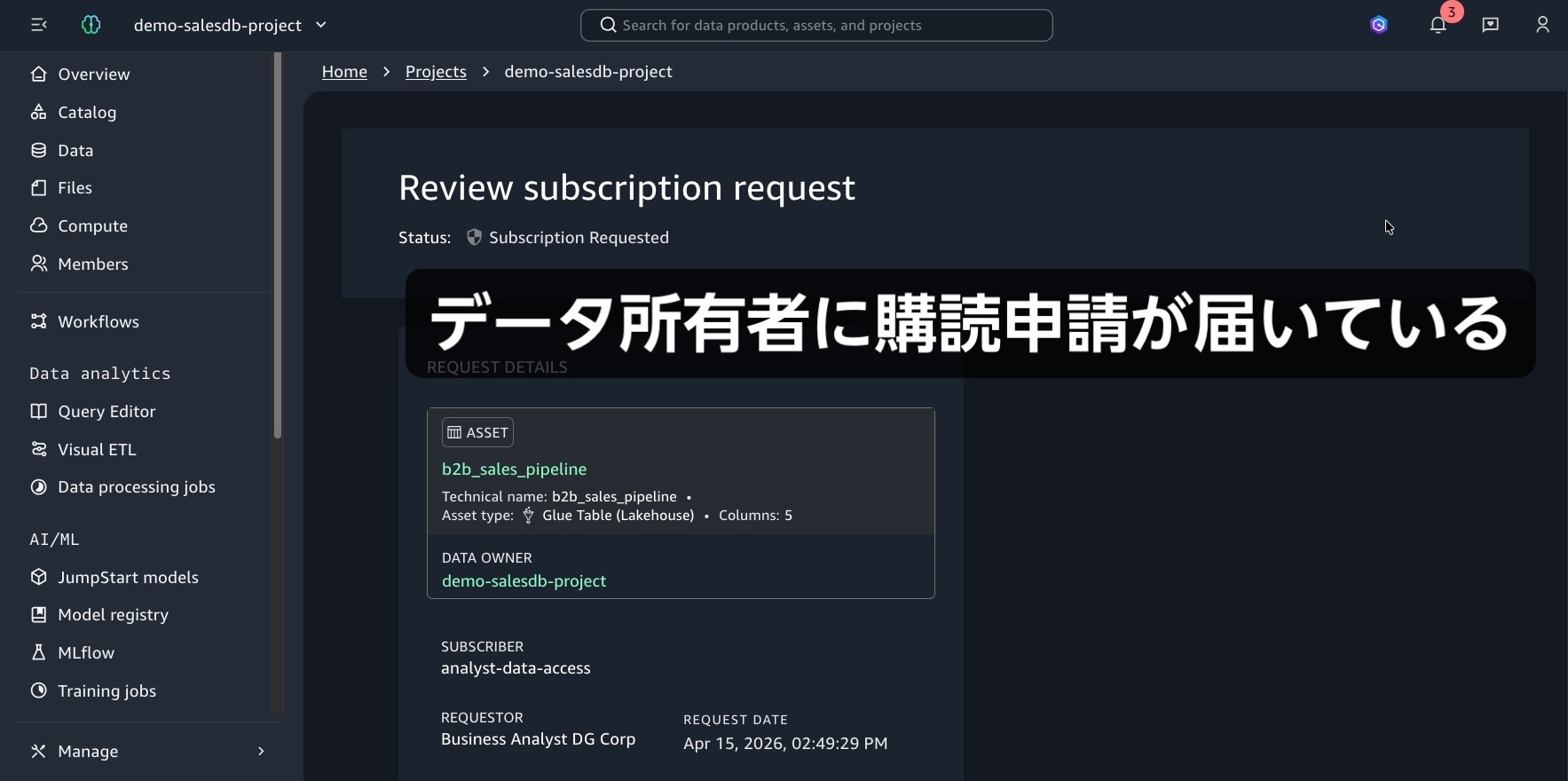
利用者の画面に戻ります。同じチャットセッションで「承認されました」と伝えると、エージェントは再度データアクセスを試み、今度は成功します。B2B 商談パイプラインの分析と可視化が提示されます。
このシナリオの注目点は、利用者が SageMaker Catalog の UI を直接触らなくても、既存の Publish/Subscribe モデルに乗ってデータアクセス権の申請と取得ができることです。データガバナンスの仕組みはそのまま維持され、利用者体験だけがチャット UI に統合されます。
デモで起きていること
どちらのデモでも、データ取得は利用者本人の権限で実行されています。AWS Lake Formation が行・列レベルのアクセス制御を、Amazon S3 Access Grants がオブジェクトレベルのアクセス制御を、クエリ実行時にプロジェクトロールの認証情報に対して評価します。利用者が Subscribe していないアセットには、エージェントもアクセスできません。デモ 2 で Subscribe 申請が承認されるまでデータが返らなかったのは、その評価がエージェント経由のアクセスにも同じように効いている証拠です。
どの利用者がどのロールで何を見たかは、すべて AWS CloudTrail に記録されます。Lambda の実行ロールは監査ログのデータアクセスに登場しません。プロジェクトロールの一時認証情報でクエリが実行されているからです。
サンプルの拡張例: ゼロショット時系列予測をオンデマンドで
3 要素(認可、ビジネスデータカタログ、ドメイン知識)が揃ったデータ基盤の上には、分析以外の高度な機能もオンデマンドで組み込めます。ここでは一例として、本サンプルに含めているゼロショット時系列予測を紹介します。
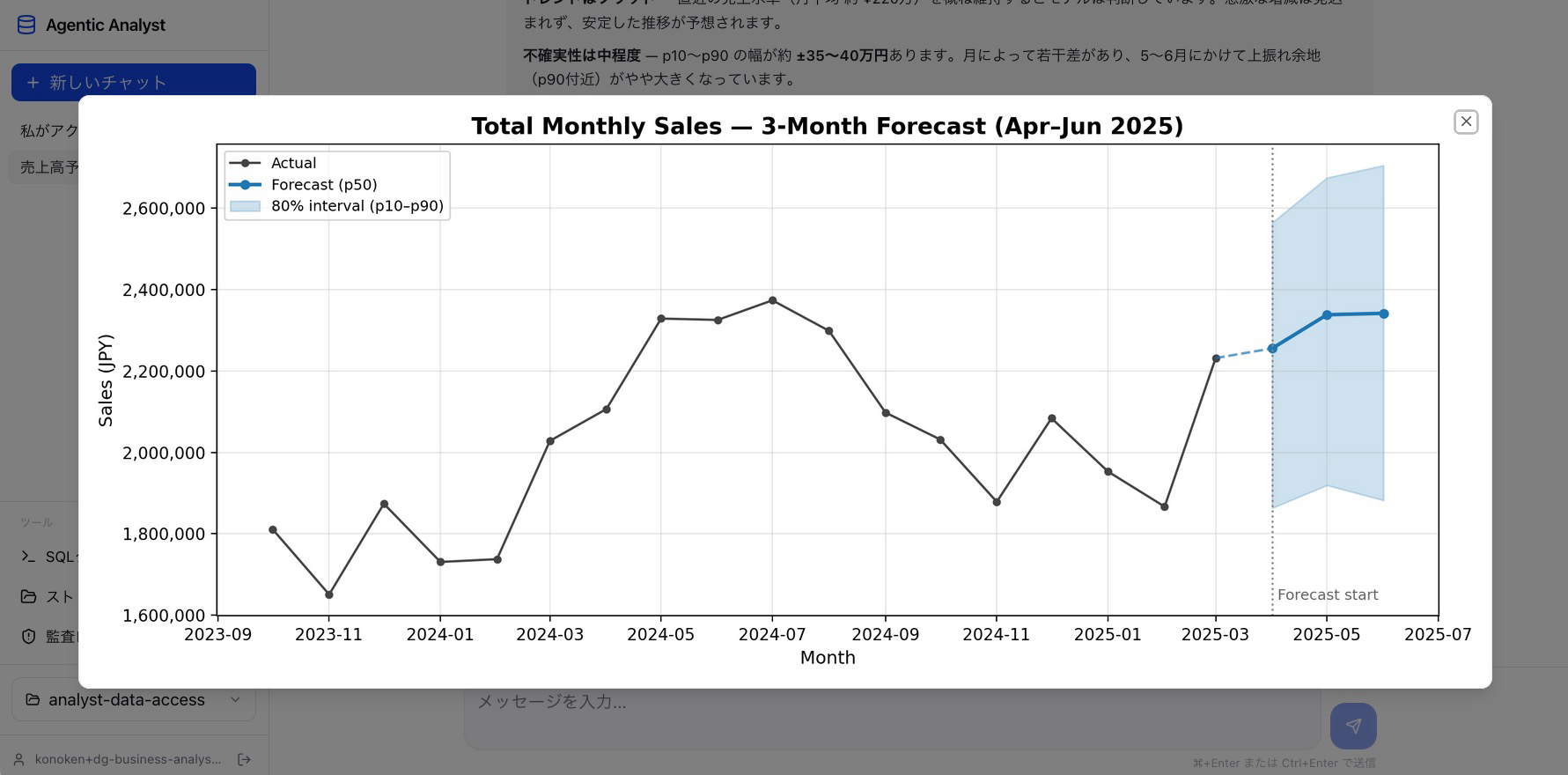
従来、時系列予測モデルを使うには、データ準備、特徴量設計、モデル学習、評価、運用という長いサイクルが必要でした。系列ごとに個別のモデルをトレーニングするコストは、適用対象を限定する要因になっていました。近年登場したゼロショット予測モデル(本サンプルでは Chronos-2)は、新しい系列に対する追加学習なしに実用精度の予測を返します。このモデルを Amazon SageMaker AI の推論エンドポイントでホストし、エージェントのツール(time_series_forecast)として公開することで、利用者は任意のテーブルに対して「来月の売上を予測して」と依頼するだけで予測結果とグラフを受け取れます。
このツール 1 つで、本サンプルの世界観は次のように広がります。
- 利用者が SageMaker Catalog で Subscribe した売上・在庫・トラフィック等のテーブルに対して、学習プロジェクトを立ち上げずに予測を実行できる
- エージェントがデータの取得から集計、予測、可視化までを一連の会話の中で扱う。Amazon Athena で取得したデータはそのまま Chronos-2 の推論エンドポイントに渡され、AgentCore Code Interpreter で fan chart として描画される
- アクセス制御はデータ取得の段階で効いているため、予測対象になるのは利用者が見てよい系列だけに自動的に限定される
個別のトレーニング基盤を用意せずに、アクセス制御されたデータの上で時系列予測を提供できる点が、この組み合わせの面白さです。実装の詳細(Chronos-2 の系列フォーマット、前処理の難しさ、AgentCore Code Interpreter 側の描画仕様)は、サンプルリポジトリの apps/gateway-tools/time-series-forecast/ と apps/chat-agent/src/prompt.ts を参照してください。
考慮事項
コスト
本サンプルの固定費は月数ドル程度です。大半を占めるのは Amazon Bedrock のモデル推論の従量課金で、利用量に依存します。具体的な試算はサンプルリポジトリの docs/ 配下に掲載しています。AWS 無料利用枠の範囲で動く部分も多く、低コストで検証を始めることができます。
既存データレイクへの適用
既存の S3 / Redshift データレイクを、作り直さずに本サンプルと同じ構造に組み込めます。対象のテーブルやデータセットを SageMaker Catalog で管理するようにし、Publish/Subscribe を設定することで、エージェント経由のアクセスを追加できます。データのメタデータ整備や Publisher/Subscriber の役割分担、運用ポリシーの設計は、組織のデータガバナンス方針に沿って進めます。
デプロイ手順の概要
読者が自分で動かせるよう、手順の全体像を示します。詳細は リポジトリの README を参照してください。前提として、AWS IAM Identity Center(以下 IdC)の組織インスタンスが必要で、SageMaker Unified Studio ドメインは AWS マネジメントコンソールから作成する必要があります。
まとめと次のアクション
AI エージェントが組織の本番データで動くには、認可、ビジネスデータカタログ、ドメイン知識の 3 要素が揃う必要があります。本サンプルは、これらを Amazon SageMaker Catalog、Amazon Bedrock AgentCore、AWS Lake Formation、Amazon S3 Access Grants の組み合わせで実現しています。既存のデータレイクを作り直すことなく、SageMaker Catalog で管理する形に組み込んで AI エージェントに接続できます。
ツールを配る時代から、データを返す時代へ。次のアクションとして、以下を検討してください。
- 試す: GitHub リポジトリ を参照してデプロイし、3 つの IdC ユーザーで権限ごとに異なる回答が返ることを確認する
- 自社に当てはめる: 既存の S3 / Redshift データレイクを SageMaker Catalog で管理する形に組み込めるかを検討する。具体的には、対象テーブルの洗い出しと、Publisher/Subscriber の役割分担の設計から着手する
- 仕組みの理解を深める: 第 2 回「SageMaker Catalog で行・列レベルのアクセス権を透過的に適用する」で、認可の実装パターンを追う
