Amazon Web Services ブログ
AWS DMS データ検証:カスタムサーバーレスアーキテクチャ
本投稿は、Anil Malakar と Mahesh Kansara と Prabodh Pawar による記事 「AWS DMS validation: A custom serverless architecture」を翻訳したものです。
AWS Database Migration Service (AWS DMS) は、ダウンタイムを最小限に抑えて AWS へのデータベース移行をサポートするマネージドサービスです。移行プロセス中にソースデータベースを完全に稼働したまま、同種の移行 (Oracle から Oracle など) と異種の移行 (Oracle から PostgreSQL など) の両方をサポートしています。この投稿では、AWS サーバーレスサービスを使用して AWS DMS データ検証ソリューションをカスタムに構築する方法を説明します。
データ検証の課題
AWS DMS のお客様は、AWS DMS サービスが提供するデータ検証機能の使用を選択しないかもしれません。ビジネスの要件としてターゲット環境でデータを迅速に利用できるようにする必要がある場合、ロード、大規模なデータセットの転送、またはデータのリロード後、検証が完了するまでに時間がかかってしまうためです。その結果、手動で検証を実行するか、1 回限りのフルロードのみの検証を使用することを選択する可能性がありますが、これには追加の労力と時間が必要になります。
この問題は、ある企業のお客様が毎月手動で検証を行っていることが原因で判明しました。顧客がデータの不一致を発見して報告した時点で、関連する DMS ログはすでに期限切れになっていました。これにより、2つの問題が発生しました。1つは、お客様のビジネスに影響を与える可能性がある正確なデータ検証の機会を逃したこと、もう一つは、根本原因のトラブルシューティングにおいて重大な課題に直面したことです。
この課題に対処するため、カスタマイズされたソリューションアーキテクチャを構築しました。このアーキテクチャは、AWS DMS タスクの完了かエラーが発生したとき (フルロード移行の場合)、あるいは変更データキャプチャ (CDC) 中のソースにアクティブな書き込み/変更がないときに、データ検証プロセスを自動的に実行することを目的としています。
この投稿では、AWS DMS にイベント駆動型データ検証を実装する方法を紹介します。この投稿はアーキテクチャのガイダンスのみです。いくつかのコードスニペットが含まれていますが、それらは参照用であり、特定の実装ニーズに合わせて調整する必要がある場合があります。
当社のカスタムアーキテクチャアプローチでは、移行パフォーマンスを損なうことなく、自動データ検証の恩恵を受けることができます。ソースデータベースとターゲットデータベース間の単純なレコード数の比較から、ビジネス固有のデータポイントを対象とした複雑なマルチテーブルクエリまで、データ検証に柔軟性があります。このアーキテクチャは、検証結果をメールなどの選択した通信チャネルを通じて自動的に配信するので、AWS DMS コンソールにログインする必要がなくなります。これは、通知を通じてデータ品質を監視するのに役立ちます。
このカスタム検証アプローチは、DMS のネイティブな検証機能の代替手段ではなく並行して機能します。特定のデータ品質要件に基づいて検証チェックを自動化する柔軟性があります。
ソリューションの概要
このアーキテクチャは、AWS サーバーレスコンピューティングとイベント駆動型のメカニズムを使用して、2 つの方法でデータを検証します:
- AWS DMS タスクのステータスが変更されたときに自動的に (例えば、
REPLICATION_TASK_STOPPEDがトリガーされたとき) - Amazon EventBridge で定義されたスケジュールに基づいて
どちらの場合も、AWS Lambda 関数がデータ検証を実行し、結果は Amazon Simple Notification Service (Amazon SNS) のメール通知を使用して自動的に送信されます。
次の図は、ソリューションアーキテクチャを示しています。
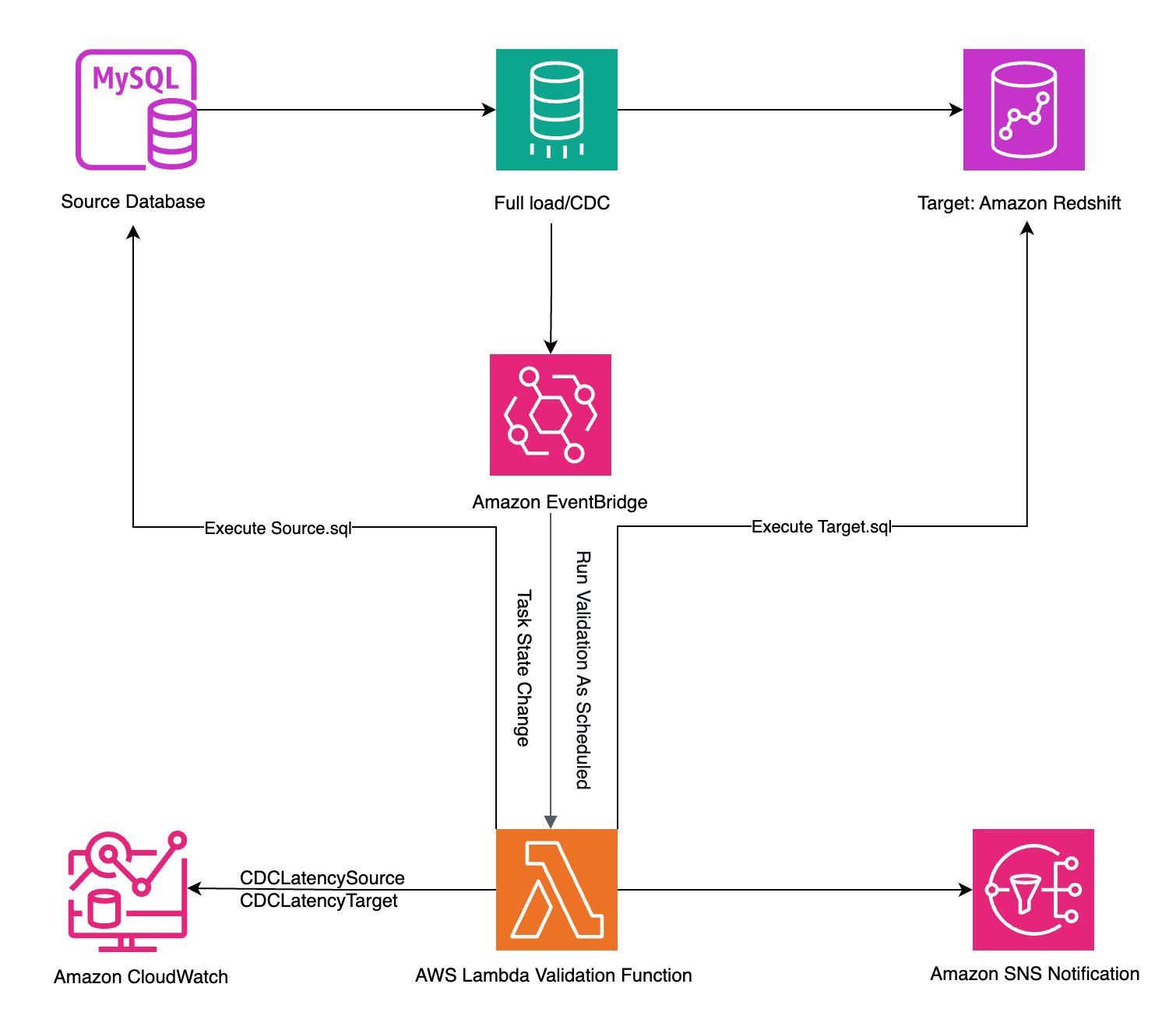
前提条件
始める前に、次の前提条件を満たす必要があります:
- AWS DMS レプリケーションインスタンスを作成します。
- AWS DMS のソースエンドポイントとターゲットエンドポイントを作成し、それぞれソースデータベースとターゲットデータベースに接続します。
- AWS DMS タスクを作成し、タスクにエンドポイントを関連付け、Amazon CloudWatch ログを有効にします。
- AWS Identity and Access Management( IAM )ロールを使用して、必要な AWS サービスにアクセスするための適切な権限があることを確認します。
- このソリューションを実装するには、AWS Lambda 関数を記述およびカスタマイズするための Python プログラミング言語の知識が必要です。
Lambda 関数の作成
カスタムデータ検証を実装するには、まず Lambda 関数を作成し、特定のジョブを実行するためのファイルを追加します。これは、ソリューションをモジュール化し続けるためです。次のスクリーンショットは、さまざまなカスタムモジュールを示しています。
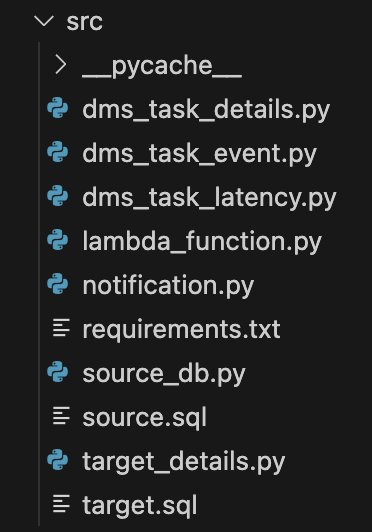
アーキテクチャは、以下のような構造であるべきです。これは必要に応じて拡張できます:
- dms_task_details – AWS DMS タスク情報を管理し、AWS DMS タスクのソースとターゲットエンドポイントを取得します。
- dms_task_event – AWS DMS フルロードタスクから発生したイベントから AWS DMS タスクの詳細を取得します。
- dms_task_latency – AWS DMS タスクのレイテンシーメトリクスを処理します:
- Amazon CloudWatch から AWS DMS レイテンシーメトリクスを取得します。
- CDC のソースレイテンシーとターゲットレイテンシーの両方を監視します。
- lambda_function – AWS DMS レプリケーションタスクの自動検証システムとして機能します。次の機能を実行します:
- AWS DMS イベントのモニタリング:
- AWS DMS タスクイベントをキャプチャして処理します。特に
REPLICATION_TASK_STOPPEDイベントを監視します - タスクが停止すると、dms_task_event_details モジュールの
dms_task_event_detailsメソッドを介して詳細なイベント処理がトリガーされます。
- AWS DMS タスクイベントをキャプチャして処理します。特に
- レプリケーションデータの検証:
- ソースとターゲットの両方の AWS DMS レプリケーションレイテンシーメトリックスを監視します。
- 並列処理を実装して、ソースとターゲットのデータ数を効率的に比較します。
- 検証を行う前のレイテンシー閾値チェック (5 秒未満) を含みます。
- パラレルデータ検証:
- 並行実行には ThreadPoolExecutor を使用します。これは、ソースデータベースとターゲットデータベースで同時にクエリを実行するのに役立ちます。
ソースクエリとターゲットクエリを並行して実行することでパフォーマンスを最適化します。
- 並行実行には ThreadPoolExecutor を使用します。これは、ソースデータベースとターゲットデータベースで同時にクエリを実行するのに役立ちます。
- AWS DMS イベントのモニタリング:
- notification – Amazon SNS を使用してアラート通知を実行します:
- 検証結果の自動通知を実装しています。
- ソースとターゲットのデータ数の不一致を報告します。
- トラブルシューティングに役立つ詳細なエラーメッセージを提供します。
- requirements.txt – アプリケーションに必要なすべての依存関係を一覧表示します。この場合、Lambda 関数が MySQL データベースと通信できるようにするライブラリである PyMySQL バージョン 1.0.2 を指定しています。Lambda 関数を MySQL に接続するには、関数に PyMySQL パッケージを含むレイヤーを追加する必要があります。
- source_db – ソースデータベースの操作を管理します。AWS Secrets Manager に保存されている認証情報を使用して AWS DMS ソースデータベースに接続し、source.sql で定義されたクエリを実行するコードを実装します。
- source.sql – ソースデータベースからデータを取得し、レプリケーションが成功したことを確認するためにターゲットデータベースと比較する SQL クエリが含まれています。
- target_details – ターゲットデータベースの操作を処理します。AWS Secrets Manager に保存されている認証情報を使用して AWS DMS ターゲットデータベースに接続し、
target.sqlファイルに定義されているクエリを実行するコードを実装します。 - target.sql – レプリケーションが成功したことを確認するために、ソースデータベースに対応するターゲットデータベースからデータを取得する SQL クエリが含まれています。
フルロードの場合
AWS DMS のステータス変更イベント REPLICATION_TASK_STOPPED が、Lambda 検証関数の lambda_handler 関数イベントパラメータで受信されます。
- REPLICATION_TASK_STOPPEDイベントのイベントパラメータからイベントタイプを取得して、イベントリソースからタスクを取得します。次のコードを参照してください:
- Boto3 ライブラリを使用して AWS DMS クライアントを作成し、
describe_replication_tasksメソッドのレスポンスからソースとターゲットの詳細を取得します:
クエリの実行と結果送信の自動化
次のステップは、Lambda 検証関数が各データベースで実行して結果を比較するためのソースおよびターゲット固有のクエリを作成することです。Amazon SNS を使用して、結果をユーザーにメールで送信できます。
以下のコードスニペットを参照して、ソースとターゲットからデータを取得し、結果を比較することができます。以下のコードでは、source.sql と target.sql で単純な count クエリを使用してソースとターゲットのデータを比較していますが、クエリを複数のテーブルに拡張したり、成功または失敗を定義するロジックをカスタマイズしたりすることができます。
CDCの場合
Lambda 検証関数は、EventBridge で定義されたスケジュールに従ってトリガーされます。AWS DMS タスクのレイテンシーメトリクスである CDCLatencySource と CDCLatencyTarget を取得する必要があります。
- Boto3 を使用して CloudWatch クライアントを作成します:
- 以下のコードを使用して CloudWatch からメトリクスを取得します:
- ソースとターゲットのレイテンシーメトリクスを取得するには、CloudWatch クライアントを使用して以下のコードを参照してください:
- レイテンシーが 5 秒未満として指定して下さい(要件に応じて変更可能)。Lambda 検証関数はソースとターゲットの両方のデータベースで並列クエリを実行します。以下のコードでは、source.sql と target.sql で単純な count クエリを使用してソースとターゲットのデータを比較していますが、複数のテーブルにクエリを拡張したり、成功または失敗を定義するロジックをカスタマイズしたりすることができます。
Lambda 検証関数は両方のクエリ結果を受け取ると、それらを比較し、Amazon SNSを使用して通知を送信します。以下は、メールで受信した通知の例です:
EventBridge のルールを作成してください
また、AWS DMS イベントをキャプチャするように EventBridge ルールを設定し、スケジューラーを実行して Lambda 検証機能を呼び出す必要があります。
- EventBridge コンソールで、次の JSON に示されている構成を使用してルールを作成します。このルールはフルロードのシナリオで使用されます。
- 次のスクリーンショットに示すように、Lambda 関数にルールのターゲットを設定します。

- CDC の場合は、特定のスケジュールで実行するスケジューラーを作成し、ターゲットに Lambda 検証機能を設定します。
技術的範囲と制限事項
このソリューションを実装する前に、その技術的な境界と制約を理解することが重要です。
このセクションでは、このアーキテクチャが達成できることとその制限について概説し、特定のユースケースの要件を満たすかどうかを判断するのに役立ちます。
- データベースサポート: 本ソリューションでは MySQL から Redshift への移行シナリオを示していますが、他のデータベースにも対応できるように拡張できます。ただし、照合順序の違いを検証し、文字セットの互換性を確認し、お客様の環境で十分にテストすることを忘れないでください。
- LOB の取り扱い: このソリューションは Large Object (LOB) の検証をサポートしていません。これらのカラムを検証の対象から除外することを検討してください。
- クエリ: クエリの実行に 15 分以上かかる場合は、Lambda の代わりに Amazon Elastic Container Service (Amazon ECS) または AWS Fargate を使用してください。
コストに関する考慮事項
このソリューションは自動化された検証機能を提供しますが、検証チェックの頻度を調整し、CloudWatch で適切なログ保持期間を設定し、Lambda 関数の実行時間を最適化することで、コストを効果的に管理できます。
不要なコストの発生を防ぐため、このアーキテクチャの実装後はすべてのリソースを削除することを忘れないでください。
まとめ
この投稿では、AWS DMS のデータ検証プロセスを自動化し、手動の作業を削減するアーキテクチャをご紹介しました。
このアーキテクチャは、サーバーレスコンピューティングとイベント駆動型アーキテクチャを使用して、データ検証ルーチンを動的にトリガーし、レイテンシーに関する懸念に対処し、データ移行のパフォーマンスへの影響を最小限に抑えます。
ご自身のユースケースでこのアプローチを試してみてください。