Amazon Web Services ブログ
Amazon SageMaker、Amazon OpenSearch Service、Streamlit、LangChain を使った質問応答ボットの構築
エンタープライズ企業における生成系 AI と大規模言語モデル (LLM) の最も一般的な用途の 1 つは、企業の知識コーパスに基づいた質問応答です。Amazon Lex は AI ベースのチャットボットを構築するためのフレームワークを提供します。事前学習済みの基盤モデル (Foundation Models; FM) は、さまざまなトピックに関する要約・テキスト生成・質問応答などの自然言語理解 (NLU) タスクではうまく機能しますが、幻覚やハルシネーションと言われる不正確な情報を含まない回答を提供するのが難しい、もしくは、学習データに含まれない内容に関する質問へ回答することはできません。さらに、基盤モデルは特定の時点のデータをスナップショットとして使用してトレーニングされており、推論時に新しいデータにアクセスすることはできません。推論時に最新のデータにアクセスできない場合、不正確または不適切な応答を返す可能性があります。
この問題に対処するためによく使用されるアプローチは、検索拡張生成 (Retrieval Augmented Generation; RAG) と呼ばれる手法を使用することです。RAG ベースのアプローチでは、LLM を使用してユーザーの質問をベクトル表現に変換し、独自の知識コーパスに対応するベクトル表現が保存されているデータベースに対して類似性検索を行います。少数の類似文書 (典型的には3つ) とユーザーの質問をもとに「プロンプト」を作成して LLM に入力することで、コンテキストとして提供された情報を使用してユーザーの質問に対する回答を生成します。RAG は 2020年に Lewis et al. によって提案され、オリジナルの論文では、クエリをベクトル表現に変換し類似度の高いドキュメントを取得するレトリーバーと、解答生成に使う事前学習済みの seq2seq モデルを組み合わせて end-to-end でのファインチューニングを行います。RAG ベースのアプローチの全体像を理解するには、こちらのブログ記事 (Amazon SageMaker JumpStart の基盤モデルによる検索拡張生成を使用した質問への回答) を参照してください。
この投稿では、エンタープライズで使用可能な質問応答ボットなどの RAG アプリケーションを作成するためのすべての構成要素を含む詳細なガイドを提供します。提供するサンプルコードでは、さまざまな AWS サービス、オープンソースの基盤モデル (テキスト生成には FLAN-T5 XXL、ベクトル表現には GPT-J-6B )、パッケージ (コンポーネントとのインターフェースにはLangChain、ボットのフロントエンドの構築には Streamlit) を組み合わせて使用しています。
本ソリューション構築に必要なすべてのリソースを用意する AWS Cloud Formation テンプレートを公開しています。次に、LangChain を使って以下を結びつける方法を示します。
- Amazon SageMaker でホストされている LLM とのインターフェース
- ナレッジベース文書のチャンク
- Amazon OpenSearch Service へドキュメントのベクトル表現の取り込み
- 質問応答タスクの実装
同じアーキテクチャを用いて、オープンソースモデルを Amazon Titan モデルと交換することも可能です。Amazon Bedrock のローンチ後、Amazon Bedrock を使用して同様の生成系 AI アプリケーションを実装する方法を示す記事を公開する予定ですので、ご期待ください。
ソリューション概要
この記事のナレッジコーパスとして SageMaker ドキュメントを使用します。このサイトの HTML ページを (チャンク間の文脈の連続性をある程度維持するために) 重なり合う小さなチャンクに変換してから、これらのチャンクを gpt-j-6b モデルを使用してベクトル表現に変換し、OpenSearch Service に保存します。AWS Lambda 関数内に RAG に関する機能を実装し、Amazon API Gateway を用いてリクエストをその Lambda 関数にルーティングします。Streamlit には、API Gateway を介して Lambda 関数を呼び出すチャットボットアプリケーションを実装し、その Lambda 関数がOpenSearch Service インデックスに対してユーザーの質問のベクトル表現との類似性検索を行います。類似性の高い文書 (チャンク) は Lambda 関数によってコンテキストとしてプロンプトに追加され、関数は SageMaker エンドポイントとしてデプロイされた flan-t5-xxl モデルを使用してユーザーの質問に対する回答を生成します。この記事のコードはすべて GitHub リポジトリにあります。
次の図は、提案されたソリューションの大まかなアーキテクチャを示しています。
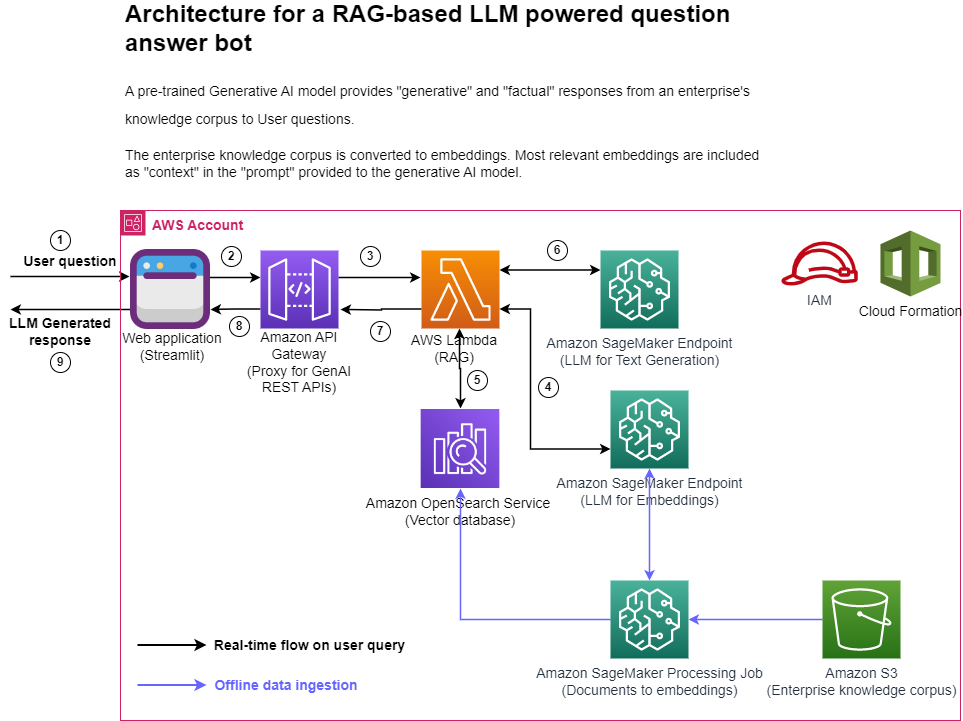
図1. アーキテクチャ図
各ステップごとの説明は、以下の通りです。
- ユーザーは Streamlit ウェブアプリケーションを介して質問を送信します。
- Streamlit アプリケーションは API Gateway の REST API エンドポイントを呼び出します。
- API Gateway は Lambda 関数を呼び出します。
- この Lambda 関数は SageMaker エンドポイントを呼び出して、ユーザーの質問をベクトル表現に変換します。
- この Lambda 関数は OpenSearch Service API を呼び出して、ユーザーの質問と似たドキュメントを検索します。
- この Lambda 関数は、ユーザークエリと類似文書をコンテキストとしてプロンプトを作成し、SageMaker エンドポイントに応答を生成するように要求します。
- Lambda 関数から API Gateway にレスポンスが返されます。
- API Gateway は Streamlit アプリケーションにレスポンスを返します。
- ユーザーは Streamlit アプリケーション上で結果を確認します。
アーキテクチャ図に示されているように、このソリューションでは次の AWS サービスを使用しています。
- Amazon SageMaker と Amazon SageMaker JumpStart: 2 つの LLM のホストに用います。
- OpenSearch Service: 独自知識コーパスのベクトル表現を保存し、ユーザーの質問との類似性検索を行うために用います。
- Lambda: RAG に関する機能を実装し、API Gateway REST エンドポイント経由で呼び出すために使用します。
- Amazon SageMaker Processing ジョブ: 大規模なデータを OpenSearch に取り込むために用います。
- Amazon SageMaker Studio: Streamlit アプリケーションをホストするために用います。
- AWS Identity and Access Management (IAM) ロールとポリシー: アクセス管理のために用います。
- AWS CloudFormation: ソリューションスタック全体を作成するために必要なリソースをコードとして定義するために用います。
このソリューションではオープンソースパッケージとして、LangChain を OpenSearch Service や SageMaker とのインターフェースに、FastAPI を Lambda 関数内で REST API インターフェースを実装するために用いています。
このブログ記事で紹介するソリューションをご自身の AWS アカウントにデプロイする手順は以下の通りです。
- 提供される CloudFormation テンプレートを用いて、ご自身のアカウントでスタックを作成してください。これにより、このソリューションに必要なすべてのリソースが作成されます。
- LLM 用の SageMaker エンドポイント
- OpenSearch Service クラスタ
- API Gateway
- Lambda 関数
- SageMaker ノートブック
- IAM ロール
- SageMaker ノートブック内の data_ingestion_to_vectordb.ipynb を実行して、SageMaker ドキュメントから OpenSearch Service インデックスにデータを取り込みます。
- SageMaker Studio 内のターミナルで Streamlit アプリケーションを実行し、アプリケーションの URL を新しいブラウザタブで開きます。
- Streamlit アプリが提供するチャットインターフェースから SageMaker について質問したり、LLM が生成した回答を確認したりできます。
これらの手順については、次のセクションで詳しく説明します。
前提条件
この記事で提供されているソリューションを実装するためには、AWS アカウントをお持ちで、LLM・OpenSearch Service・SageMaker への一定程度の理解が必要です。
LLM をホストするためには、高速コンピューティング (GPU) インスタンスにアクセスする必要があります。このソリューションでは、ml.g5.12xlarge と ml.g5.24xlarge のインスタンスを 1 つずつ使用します。次のスクリーンショットに示すように、ご自身の AWS アカウントでこれらのインスタンスが利用可能かどうか確認し、必要に応じて上限緩和を要求してください。(訳注: AWS コンソール内の Service Quotas → AWS Services → Amazon SageMaker と進むと、以下の画面が表示されます)
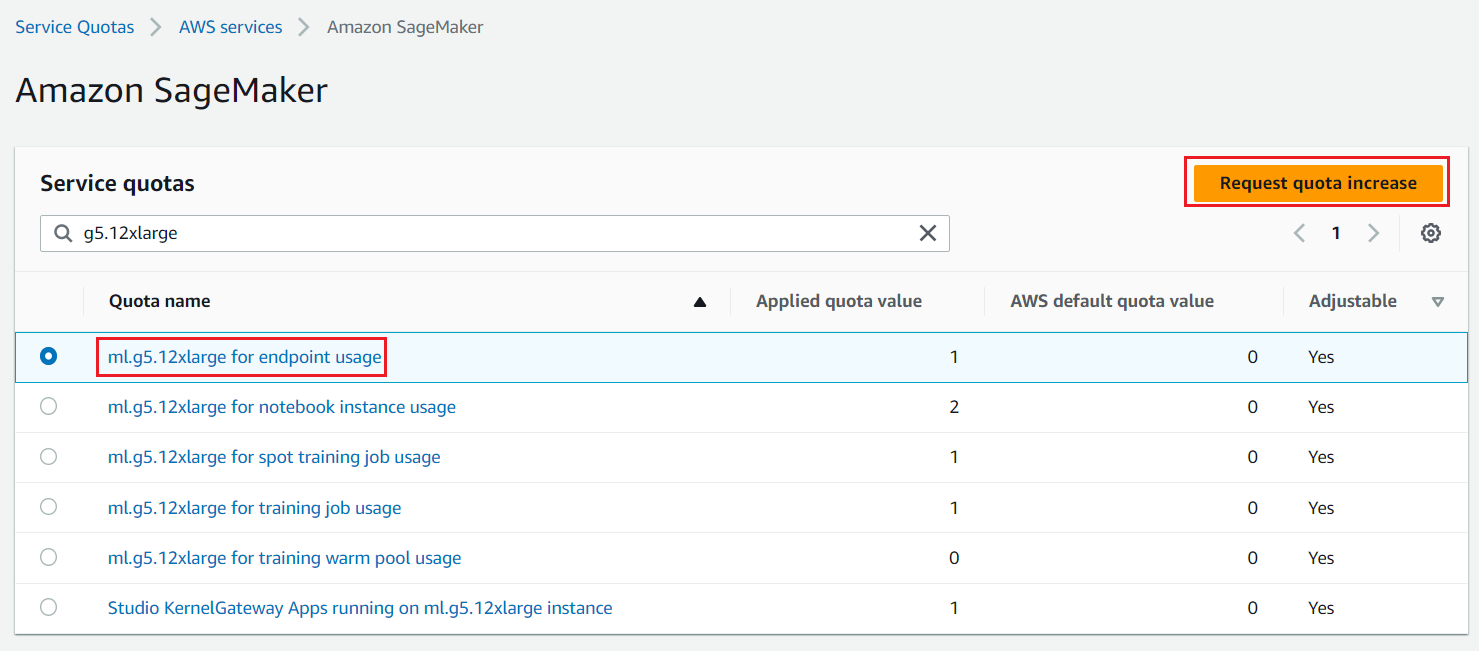
図2. クオータ引き上げリクエスト
AWS Cloud Formation を用いたソリューションスタックの作成
AWS CloudFormation を使用して aws-llm-apps-blog という名前の SageMaker ノートブックと LLMAppsBlogIAMRole という名前の IAM ロールを作成します。リソースをデプロイしたいリージョンの Launch Stack ボタンを選択します。CloudFormation テンプレートには、 OpenSearch Service のパスワードを除いて、デフォルト値が既に入力されています。(訳注: OpenSearch Service のパスワードは大文字・小文字・数字・記号をすべて含む8文字以上の文字列を指定してください) この時、OpenSearch Service のユーザー名とパスワードを書き留めておいてください。このテンプレートはデプロイ完了まで約 15 分かかります。
| AWS Region | Link |
|---|---|
us-east-1 |
|
us-west-2 |
|
eu-west-1 |
|
ap-northeast-1 |
スタックが正常に作成されたら、AWS CloudFormation コンソールのスタックの出力タブに移動し、OpenSearchDomainEndpoint と LLMAppAPIEndpoint の値を書き留めます。これらは後続の手順で使用します。
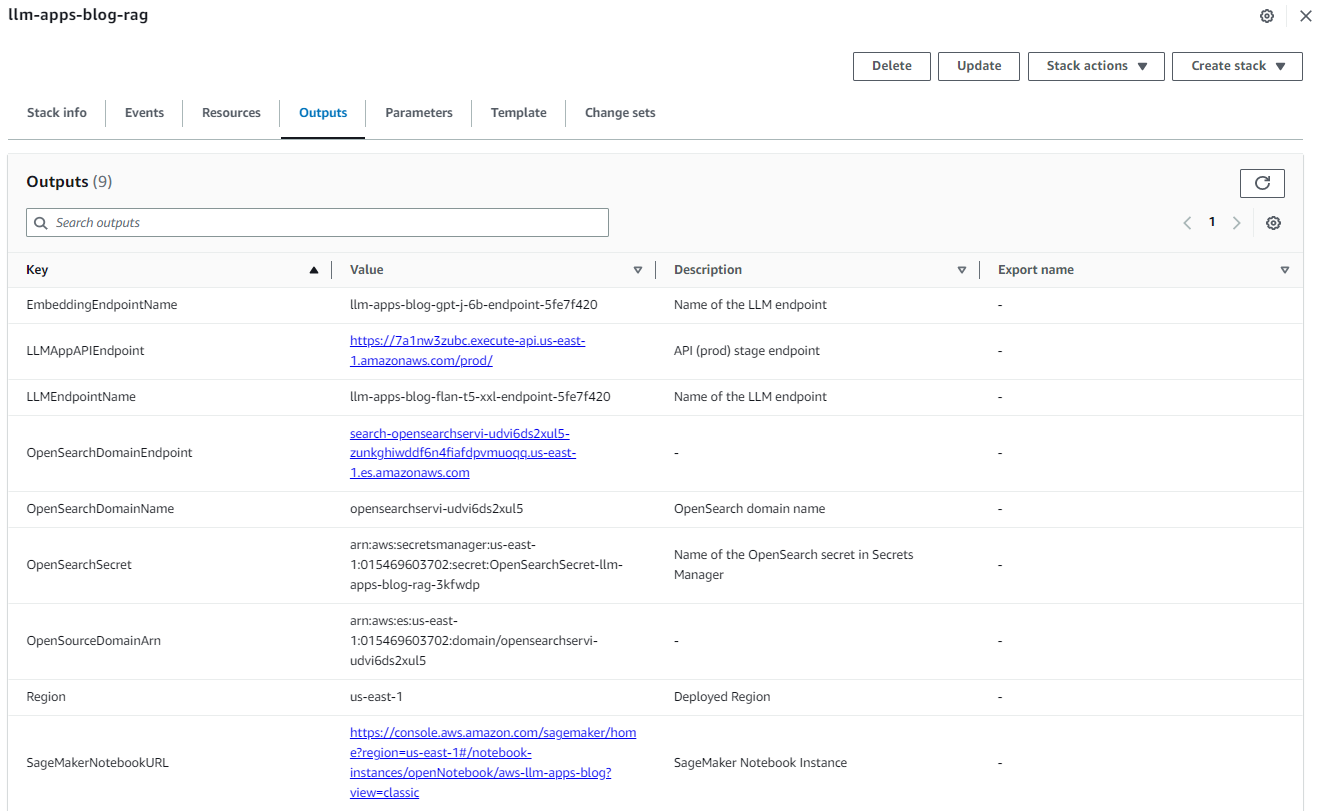
図3. Cloud Formation スタックの出力
OpenSearch Service へのデータの取り込み
データを取り込むには、次の手順を実行します。
- SageMaker コンソールのナビゲーションペインにてノートブックセクション内にあるノートブックインスタンスを選択します。
aws-llm-apps-blogというノートブックインスタンスを選択し、JupyterLab を開くを選択します。 図4. JupyterLab を開く
図4. JupyterLab を開く- data_ingestion_to_vectordb.ipynb を選択して JupyterLab で開きます。このノートブックは、SageMaker ドキュメントを
llm_apps_workshop_embeddingsという名前の OpenSearch Service インデックスに取り込みます。
図5. データ取り込みのノートブックを開く
- ノートブックが開いたら、Run メニューから Run All Cells を選択し、このノートブックのコードを実行します。これにより、ノートブックのローカル環境にデータセットをダウンロードした後に、OpenSearch Service インデックスに取り込みます。このノートブックの実行には約 20 分かかります。ノートブックは、FAISS と呼ばれる別のベクトルデータベースにもデータを取り込みます。FAISS インデックスファイルはローカルに保存された後に、Amazon Simple Storage Service (S3) にアップロードされるため、Lambda 関数から代替のベクトルデータベースを使用するオプションとして用いることも可能です。
 図6. ノートブックの全てのセルを実行
図6. ノートブックの全てのセルを実行
ここまでで、ドキュメントを複数のチャンクに分割し、ベクトル表現に変換して OpenSearch に取り込む準備ができました。LangChain の RecursiveCharacterTextSplitter クラスを使用してドキュメントをチャンク化し、次に LangChain の SageMakerEndpointEmbeddingsJumpStart クラスを使用してこれらのチャンクを gpt-j-6b LLM を使用してベクトル表現に変換します。このベクトル表現は LangChain の OpenSearchVectorSearch クラスを介してOpenSearch Serviceに保存されます。この一連のコードを Python スクリプトとしてパッケージ化し、カスタムコンテナ経由で SageMaker Processing ジョブで実行します。コードの詳細については、data_ingestion_to_vectordb.ipynb ノートブックを参照してください。
- カスタムコンテナを作成し、その中で LangChain と opensearch-py Python パッケージをインストールします。
- このコンテナイメージを Amazon Elastic Container Registry (ECR) にアップロードします。
- SageMaker ScriptProcessor クラスを使用して、複数のノードで実行される SageMaker Processing ジョブを作成します。
- Amazon S3 で利用可能なデータファイルは、
ProcessingInputの一部としてs3_data_distribution_type='ShardedByS3Key'を設定することにより、複数の SageMaker Processing ジョブインスタンスに自動的に分散されます。 - 各ノードは複数のファイルのサブセットを処理するため、OpenSearch Service にデータを取り込むのに必要な全体時間が短縮されます。
- また、各ノード内でも Python の並列処理を使用してファイル処理を内部的に並列化します。つまり、2 つのレベルで並列化が行われており、1 つは個々のノードが作業 (ファイル) を分散するクラスターレベルで、もう 1 つはノード内での処理が複数のプロセスに分割されるノードレベルです。
- Amazon S3 で利用可能なデータファイルは、
- すべてのセルがエラーなく実行されたら、ノートブックを閉じます。ここまでで、データが OpenSearch Service で利用できるようになりました。ブラウザのアドレスバーに次の URL を入力すると、
llm_apps_workshop_embeddingsインデックスに含まれるドキュメントの数が表示されます。以下の URL のyour-opensearch-domain-endpointには、CloudFormation スタックを作成した際に出力される OpenSearch Service ドメインエンドポイントを使用してください。OpenSearch Service のユーザー名とパスワードの入力を求められます。これらの値は CloudFormation スタックの出力、もしくは作成時のメモから入手してください。
ブラウザウィンドウには、次のような出力が表示されます。この出力は、5,667 件のドキュメントが取り込まれたことを示しています
llm_apps_workshop_embeddings index. {"count":5667,"_shards":{"total":5,"successful":5,"skipped":0,"failed":0}}
Streamlit アプリケーションを SageMaker Studio で実行
ここまでで、質問応答ボット用の Streamlit ウェブアプリケーションを実行する準備ができました。このアプリケーションでは、ユーザーが行なった質問に対して、Lambda 関数によって提供される /llm/rag REST API エンドポイントを介して回答を取得できます。
SageMaker Studio は、Streamlit ウェブアプリケーションをホストするための便利なプラットフォームを提供します。以下の手順では、SageMaker Studio で Streamlit アプリケーションを実行する方法について説明します。同じ手順を用いてご自身のラップトップ上でアプリケーションを実行することもできます。
- Studio を開き、新しいターミナルを開きます。
- ターミナルで次のコマンドを実行して、この記事のコードリポジトリをクローンし、アプリケーションで必要な Python パッケージをインストールします。
- CloudFormation スタックの出力から取得できる API Gateway エンドポイント URL を、webapp.py ファイルに設定する必要があります。これを行うには、次の
sedコマンドを実行します。以下のシェルコマンドのreplace-with-LLMAppAPIEndpoint-value-from-cloudformation-stack-outputsを CloudFormation スタックの出力のLLMAppAPIEndpointフィールドの値に置き換えてから実行して、Studio で Streamlit アプリケーションを起動します。 - アプリケーションが正常に実行されると、次のような出力が表示されます (表示される IP アドレスは、この例に示されているものとは異なります)。次のステップでアプリの URL の一部として使用する出力のポート番号 (通常は 8501) を書き留めておきます。
- Studio のドメイン URL に似た URL を使用して、新しいブラウザタブでアプリにアクセスできます。たとえば、スタジオの URL が
https://d-randomidentifier.studio.us-east-1.sagemaker.aws/jupyter/default/lab?の場合、Streamlit アプリの URL はhttps://d-randomidentifier.studio.us-east-1.sagemaker.aws/jupyter/default/proxy/8501/webappになります。(labがproxy/8501/webappに置き換えられていることに注意してください。) 前のステップで記録したポート番号が 8501 と異なる場合は、StreamlitアプリのURLに 8501 の代わりにそのポート番号を使用してください。
次のスクリーンショットは、いくつかのユーザーからの質問を含むアプリを示しています。

Lambda 関数内の RAG 実装の詳細
アプリケーションが動作するようになったので、Lambda 関数を詳しく見てみましょう。Lambda 関数は FastAPI を使用して RAG 用の REST API を実装し、Mangum パッケージは API をハンドラーと共にラップし、Lambda へのデプロイ用にパッケージ化します。API Gateway を使用してすべてのリクエストを Lambda 関数へルーティングし、アプリケーション内でルーティングを処理します。
次のコードスニペットは、OpenSearch インデックスからユーザーの質問に類似したドキュメントを検索し、その質問と類似ドキュメントを組み合わせてプロンプトを作成する方法を示しています。このプロンプトが LLM に提供され、ユーザーの質問に対する回答が生成されます。
リソースの削除
今後料金が発生しないように、リソースを削除してください。これを行うには、次のスクリーンショットで示すように、削除したいスタックを選択してから右上の削除ボタンをクリックして、CloudFormation スタックを削除します。
 図7: リソースの削除
図7: リソースの削除
まとめ
この記事では、AWS サービス、オープンソース LLM、およびオープンソースの Python パッケージを組み合わせて、エンタープライズ水準の RAG ソリューションを作成する方法を示しました。
Amazon SageMaker JumpStart、Amazon Titan モデル、Amazon Bedrock、Amazon OpenSearch Service についてさらに詳しく学習し、この記事で提供されているサンプル実装とご自身のビジネスに関連するデータセットを使用してソリューションを構築することをお勧めします。質問や提案がある場合は、コメントを残してください。(訳注: コメントは原文に対してお願いいたします)
この記事は、Amit Arora (AI/ML Specialist Architect), Dr. Xin Huang (Senior Applied Scientist), Navneet Tuteja (Data Specialist) によって執筆され、翻訳は合田 (Solutions Architect) が担当しました。原文はこちらです。