Amazon Web Services ブログ
AWS IoT Greengrass と Strands Agents を使用した Small Language Model の大規模デプロイ
本記事は 2025 年 12 月 19 日に公開された Deploying Small Language Models at Scale with AWS IoT Greengrass and Strands Agents を翻訳したものです。翻訳はソリューションアーキテクトの中西貴大が担当しました。
はじめに
現代の製造業は、ますます複雑な課題に直面しています。セキュリティとパフォーマンスの基準を維持しながら、リアルタイムの運用データに応答するインテリジェントな意思決定システムの実装する、という課題です。センサーデータ量と運用の複雑性に対処するためには、即時応答を必要とする場合にはローカルで情報を処理し、複雑なタスクの場合にはクラウドリソースを活用する AI ソリューションが必要です。
業界は、エッジコンピューティングと AI が融合する重要な岐路に立たされています。Small Language Models (SLM) は、制約のある GPU ハードウェア上で実行できるほど軽量でありながら、コンテキストを理解した洞察を提供するのに十分な性能を持っています。Large Language Models (LLM) とは異なり、SLM は産業用 PC やゲートウェイの電力や熱に関する制約を満たすため、リソースが限られ信頼性が最も重要な工場環境に最適です。このブログ投稿では、SLM は約 30 億から 150 億のパラメータを持つと仮定します。
このブログでは、製造業における代表的なプロトコルとして Open Platform Communications Unified Architecture (OPC-UA) に焦点を当てます。OPC-UA サーバーは標準化されたリアルタイムの機械データを提供し、エッジで実行される SLM がそのデータを消費できるため、オペレーターは機器のステータスの照会、テレメトリの解釈、ドキュメントへの即時アクセスが可能になります。これらはクラウド接続がなくても実現できます。
AWS IoT Greengrass は、SLM を Greengrass コンポーネント(例: Lambda 関数やカスタムコンポーネント)として OPC-UA ゲートウェイに直接デプロイすることで、このハイブリッドパターンを実現します。ローカル推論により、安全上重要なタスクの応答性が確保される一方、クラウドでは、より強力なセキュリティ制御の下で、フリート全体の分析、マルチサイトの最適化、またはモデルの再学習が処理されます。
このハイブリッドアプローチは、さまざまな業界で可能性を広げます。自動車メーカーは、車両のコンピュートユニットで SLM を実行して、自然な音声コマンドと強化された運転体験を提供できます。エネルギープロバイダーは、変電所で SCADA センサーデータをローカルで処理できます。ゲーム業界では、SLM をプレイヤーのデバイス上で実行して、ゲーム内の AI コンパニオンを提供できます。製造業を超えて、高等教育機関では SLM を使用して、個別化された学習、校正、研究支援、コンテンツ生成を提供できます。
このブログでは、AWS IoT Greengrass を使用して SLM をエッジにシームレスかつ大規模にデプロイする方法を見ていきます。
ソリューションの概要
このソリューションは AWS IoT Greengrass を使用してエッジデバイス上に SLM をデプロイおよび管理し、Strands Agents がローカルエージェント機能を提供します。使用されるサービスには以下が含まれます。
- AWS IoT Greengrass: デバイスソフトウェアのデプロイ、管理、監視を可能にするオープンソースのエッジソフトウェアおよびクラウドサービスです。
- AWS IoT Core: IoT デバイスを AWS クラウドに接続できるサービスです。
- Amazon Simple Storage Service (S3): あらゆる量のデータを保存および取得できる、高度にスケーラブルなオブジェクトストレージです。
- Strands Agents: クラウドおよびローカル推論を使用してマルチエージェントシステムを実行するための軽量な Python フレームワークです。
コードサンプルでは、産業オートメーションのシナリオを使用してエージェントの機能をデモンストレーションします。オーブンとコンベヤーベルトで構成される工場を定義する OPC-UA シミュレーター、および産業データのソースとしてメンテナンスランブックが含まれます。このソリューションは、他のエージェントツールを使用することで、他のユースケースにも拡張できます。下図に、概要レベルのアーキテクチャを示します。
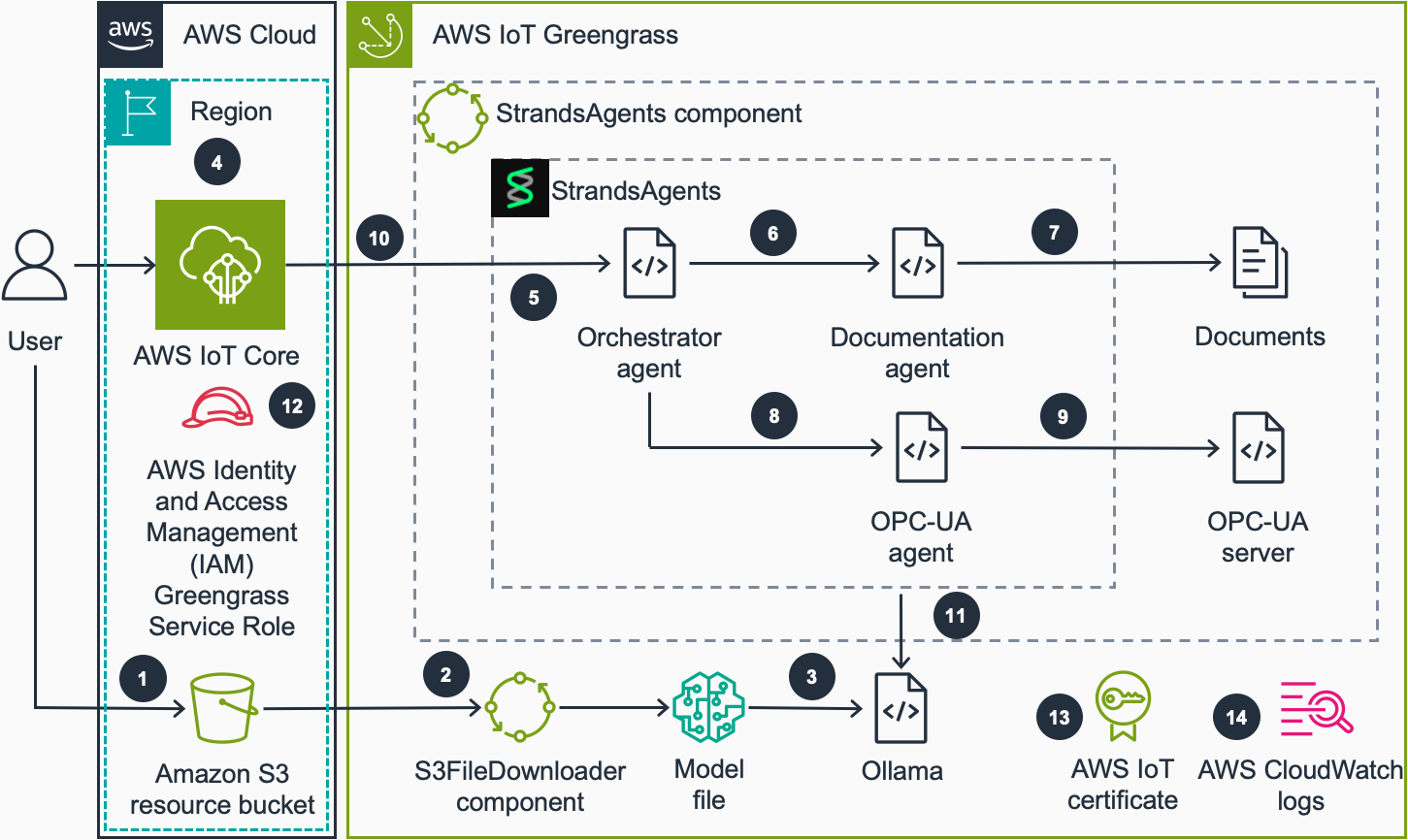
- ユーザーは GPT-Generated Unified Format (GGUF) 形式のモデルファイルを、Amazon S3 バケットにアップロードします。このバケットには AWS IoT Greengrass デバイスがアクセスできます。
- フリート内のデバイスがファイルダウンロードジョブを受信します。S3FileDownloader コンポーネントがこのジョブを処理し、S3 バケットからデバイスにモデルファイルをダウンロードします。S3FileDownloader コンポーネントは大容量ファイルを処理でき、Greengrass コンポーネントアーティファクトのサイズ制限を超えがちな SLM モデルファイルに必要な機能です。
- GGUF 形式のモデルファイルは、Strands Agents コンポーネントが Ollama への最初の呼び出しを行う際に Ollama に読み込まれます。GGUF は LLM を格納するためのバイナリファイル形式です。Ollama は GGUF モデルファイルを読み込んで推論を実行するソフトウェアです。モデル名はコンポーネントの recipe.yaml ファイルで指定されます。
- ユーザーは AWS IoT MQTT broker のデバイス固有のエージェントトピックにペイロードをパブリッシュして、ローカルエージェントにクエリを送信します。
- クエリを受信後、コンポーネントは Strands Agents SDK のモデル非依存なオーケストレーション機能を活用します。Orchestrator Agent はクエリを認識し、必要な情報源について推論し、応答を形成する前に包括的なデータを収集するために適切な特化エージェント (Documentation Agent、OPC-UA Agent、またはその両方) を呼び出します。
- クエリがドキュメント内で見つけることができる情報に関連している場合、Orchestrator Agent は Documentation Agent を呼び出します。
- Documentation Agent は提供されたドキュメントから情報を見つけ、それを Orchestrator Agent に返します。
- クエリが現在または過去のマシンデータに関連している場合、Orchestrator Agent は OPC-UA Agent を呼び出します。
- OPC-UA Agent はユーザークエリに応じて OPC-UA サーバーにクエリを実行し、サーバーからのデータを Orchestrator Agent に返します。
- Orchestrator Agent は収集した情報に基づいて応答を形成します。Strands Agents コンポーネントは AWS IoT MQTT broker のデバイス固有のエージェント応答トピックに応答をパブリッシュします。
- Strands Agent SDK により、システムはエッジで Ollama を通じてローカルにデプロイされた基盤モデルで動作できると同時に、接続が利用可能な場合は Amazon Bedrock などのクラウドベースのモデルに切り替えるオプションを維持します。
- AWS IAM Greengrass サービスロールが S3 リソースバケットへのアクセスを提供し、デバイスにモデルをダウンロードします。
- IoT thing にアタッチされた AWS IoT 証明書により、Strands Agents コンポーネントは AWS IoT Core に対して MQTT ペイロードの受信とパブリッシュができます。
- Greengrass コンポーネントはコンポーネントの動作をローカルファイルシステムにログ出力します。オプションで、AWS CloudWatch ログを有効にして CloudWatch コンソールでコンポーネントの動作を監視できます。
前提事項
このウォークスルーを開始する前に、以下のことを確認してください。
- AWS アカウント。
- AWS IoT Greengrass と SLM を実行するデバイス(例: NVIDIA Jetson Orin Nano または Amazon Elastic Compute Cloud (EC2) GPU インスタンス)。Greengrass のデプロイについて詳しくは、チュートリアル: AWS IoT Greengrass V2 の開始方法 のドキュメントをご参照ください。提供されたテンプレートを使用して、作業環境を EC2 にデプロイできます。
- デバイスに Ollama がインストールされ、実行されていること。
- デバイスに Python 3.10 + がインストールされていること。
- AWS IoT Greengrass Development Kit (GDK) CLI がインストールされていること。
- エージェントとツール呼び出しをサポートする SLM (例: Qwen 3)。
ウォークスルー
この記事では、以下のことを行います。
- Strands Agents を AWS IoT Greengrass コンポーネントとしてデプロイします。
- SLM をエッジデバイスにダウンロードします。
- デプロイされたエージェントをテストします。
コンポーネントのデプロイ
まず、StrandsAgentGreengrass コンポーネントをエッジデバイスにデプロイしましょう。Strands Agents リポジトリをクローンします。
Greengrass Development Kit (GDK) を使用してコンポーネントをビルドおよび公開します:
コンポーネントを公開するには、gdk-config.json ファイル内のリージョンとバケットの値を変更する必要があります。推奨されるアーティファクトバケット値は greengrass-artifacts です。GDK は、バケットが存在しない場合、greengrass-artifacts-<region>-<account-id> のような形式でバケットを生成します。詳細については、 Greengrass Development Kit CLI configuration file のドキュメントを参照してください。
バケットとリージョンの値を変更した後、以下のコマンドを実行してコンポーネントをビルドおよび公開します。
コンポーネントは AWS IoT Greengrass Components Console に表示されます。デバイスにコンポーネントをデプロイするには、コンポーネントをデプロイする ドキュメントを参照してください。
デプロイ後、コンポーネントはデバイス上で実行されます。これは Strands Agents、OPC-UA シミュレーションサーバー、サンプルドキュメントで構成されています。Strands Agents は SLM 推論エンジンとして Ollama サーバーを使用します。このコンポーネントには、シミュレートされたリアルタイムデータとエージェントが使用するサンプル機器マニュアルを取得するための OPC-UA およびドキュメントツールが含まれています。
Amazon EC2 インスタンスでコンポーネントをテストしたい場合は、IoTResources.yaml Amazon CloudFormation テンプレートを使用して、必要なソフトウェアがインストールされた GPU インスタンスをデプロイできます。このテンプレートでは、Greengrass を実行するためのリソースも作成されます。スタックのデプロイ後、AWS IoT Greengrass コンソールに Greengrass Core デバイスが表示されます。CloudFormation スタックは、リポジトリの source/cfn フォルダにあります。CloudFormation スタックのデプロイ方法については、CloudFormation コンソールからスタックを作成するドキュメントをお読みください。
モデルファイルのダウンロード
このコンポーネントには、Ollama が SLM として使用する GGUF 形式のモデルファイルが必要です。エッジデバイスの /tmp/destination/ フォルダにモデルファイルをコピーする必要があります。コンポーネントの recipe.yaml ファイルでデフォルトの ModelGGUFName パラメータを使用する場合、モデルファイル名は model.gguf である必要があります。
GGUF 形式のモデルファイルがない場合は、Hugging Face からダウンロードできます。例えば Qwen3-1.7B-GGUF です。実際のアプリケーションでは、これはユースケースに対する特定のビジネス課題を解決するファインチューニング済みのモデルになります。
(オプション) S3FileDownloader を使用したモデルファイルのダウンロード
エッジデバイスへのモデル配布を大規模に管理するには、S3FileDownloader AWS IoT Greengrass コンポーネントを使用できます。このコンポーネントは、自動リトライと再開機能をサポートしているため、接続が不安定な環境で大きなファイルをデプロイする際に特に有効です。モデルファイルのサイズは大きくなる可能性があり、多くの IoT ユースケースではデバイスの接続性が信頼できないため、このコンポーネントはデバイスフリートに対してモデルを確実にデプロイするのに役立ちます。
S3FileDownloader コンポーネントをデバイスにデプロイした後、AWS IoT MQTT Test Client を使用して、以下のペイロードを things/<MyThingName>/download トピックに発行できます。ファイルは Amazon
S3 バケットからダウンロードされ、エッジデバイスの /tmp/destination/ フォルダに配置されます。
リポジトリで提供されている CloudFormation テンプレートを使用した場合は、このテンプレートによって作成された S3 バケットを使用できます。バケット名を確認するには、CloudFormation スタックのデプロイ出力を参照してください。
ローカルエージェントのテスト
デプロイが完了してモデルがダウンロードされたら、AWS IoT Core MQTT Test Client を通じてエージェントをテストできます。手順は次のとおりです。
things/<MyThingName>/#トピックをサブスクライブして、エージェントのレスポンスを表示します。- 入力トピック
things/<MyThingName>/agent/queryにテストクエリをパブリッシュします:
- 複数のトピックでレスポンスを受信します:
- 最終レスポンストピック (
things/<MyThingName>/agent/response) には、Orchestrator Agent の最終レスポンスが含まれます:
- 最終レスポンストピック (
-
- サブエージェントレスポンス (
things/<MyThingName>/agent/subagent) には、OPC-UA Agent や Documentation Agent などの中間エージェントからのレスポンスが含まれています。
- サブエージェントレスポンス (
エージェントはローカル SLM を使用してクエリを処理し、OPC-UA シミュレートデータとローカルに保存された機器ドキュメントの両方に基づいて応答を提供します。デモンストレーションの目的で、AWS IoT Core MQTT テストクライアントをローカルデバイスとの通信用の簡単なインターフェースとして使用します。プロダクション環境では、Strands Agents はデバイス内のみで完全に動作させることができ、クラウドとの通信は必須ではありません。
コンポーネントのモニタリング
コンポーネントの動作を監視するには、AWS IoT Greengrass デバイスにリモートで接続し、コンポーネントログを確認します。
これにより、モデルの読み込み、クエリ処理、レスポンス生成など、エージェントのリアルタイム動作を確認できます。Greengrass のログシステムの詳細については、AWS IoT Greengrass ログのモニタリング のドキュメントで詳しく学ぶことができます。
クリーンアップ
この記事で作成したリソースを削除するには、AWS IoT Core Greengrass コンソールにアクセスしてください。
- デプロイ に移動し、コンポーネントのデプロイに使用したデプロイメントを選択して、Strands Agents コンポーネントを削除してデプロイメントを修正します。
- S3FileDownloader コンポーネントをデプロイしている場合は、前のステップで説明したようにデプロイメントから削除できます。
- コンポーネント に移動し、Strands Agents コンポーネントを選択して バージョンを削除 を選択してコンポーネントを削除します。
- S3FileDownloader コンポーネントを作成している場合は、前のステップで説明したように削除できます。
- EC2 インスタンスでデモを実行するために CloudFormation スタックをデプロイした場合は、AWS CloudFormation コンソール からスタックを削除してください。EC2 インスタンスは停止または終了されるまで時間料金が発生することに注意してください。
- Greengrass コアデバイスが不要な場合は、Greengrass コンソールの コアデバイス セクションから削除できます。
- Greengrass コアデバイスを削除した後、モノに接続されている IoT 証明書を削除します。モノの証明書を見つけるには、AWS IoT モノ コンソール に移動し、このガイドで作成したモノを選択して、証明書 タブを表示し、接続されている証明書を選択して、アクション を選択してから、無効化 と 削除 を実施します。
結論
この投稿では、AWS IoT Greengrass 上の Strands Agents を通じて統合された Ollama を使用して、SLM をローカルで実行する方法を示しました。このワークフローは、軽量な AI モデルを制約のあるハードウェア上にデプロイして管理しつつ、スケールと監視のためのクラウド統合の恩恵を受ける方法を実証しました。製造業の例として OPC-UA を使用し、エッジの SLM により、限られた接続環境でも、オペレーターが機器のステータスを照会し、テレメトリを解釈し、リアルタイムでドキュメントにアクセスできることを示しました。重要な決定はローカルで実行され、複雑な分析と再学習は安全にクラウドで処理されるという、ハイブリッドな方式です。このアーキテクチャを拡張して、エッジ AI エージェント (AWS IoT Greengrass を使用) とクラウドベースのエージェント (Amazon Bedrock を使用) がシームレスに統合されるハイブリッドクラウドエッジ AI エージェントシステムを作成できます。これにより分散コラボレーションが可能になります。エッジエージェントはリアルタイムの低レイテンシ処理と即座のアクションを管理し、クラウドエージェントは複雑な推論、データ分析、モデル改良、オーケストレーションを処理します。
著者について
 Ozan Cihangir is a Senior Prototyping Engineer at AWS Specialists & Partners Organization. He helps customers to build innovative solutions for their emerging technology projects in the cloud.
Ozan Cihangir is a Senior Prototyping Engineer at AWS Specialists & Partners Organization. He helps customers to build innovative solutions for their emerging technology projects in the cloud.
 Luis Orus is a senior member of the AWS Specialists & Partners Organization, where he has held multiple roles – from building high-performing teams at global scale to helping customers innovate and experiment quickly through prototyping.
Luis Orus is a senior member of the AWS Specialists & Partners Organization, where he has held multiple roles – from building high-performing teams at global scale to helping customers innovate and experiment quickly through prototyping.
 Amir Majlesi leads the EMEA prototyping team within AWS Specialists & Partners Organization. He has extensive experience in helping customers accelerate cloud adoption, expedite their path to production and foster a culture of innovation. Through rapid prototyping methodologies, Amir enables customer teams to build cloud native applications, with a focus on emerging technologies such as Generative & Agentic AI, Advanced Analytics, Serverless and IoT.
Amir Majlesi leads the EMEA prototyping team within AWS Specialists & Partners Organization. He has extensive experience in helping customers accelerate cloud adoption, expedite their path to production and foster a culture of innovation. Through rapid prototyping methodologies, Amir enables customer teams to build cloud native applications, with a focus on emerging technologies such as Generative & Agentic AI, Advanced Analytics, Serverless and IoT.
 Jaime Stewart focused his Solutions Architect Internship within AWS Specialists & Partners Organization around Edge Inference with SLMs. Jaime currently pursues a MSc in Artificial Intelligence.
Jaime Stewart focused his Solutions Architect Internship within AWS Specialists & Partners Organization around Edge Inference with SLMs. Jaime currently pursues a MSc in Artificial Intelligence.