Amazon Web Services ブログ
Amazon MSK Connect のご紹介 – マネージドコネクタを使用して Apache Kafka クラスターとの間でデータをストリーミングする
Apache Kafka は、リアルタイムのストリーミングデータパイプラインおよびアプリケーションを構築するためのオープンソースプラットフォームです。当社は、re:Invent 2018 において、Amazon Managed Streaming for Apache Kafka を発表しました。これは、Apache Kafka を使用してストリーミングデータを処理するアプリケーションの構築と実行を容易にする完全マネージド型のサービスです。
Apache Kafka を使用すると、IoT デバイス、データベース変更イベント、ウェブサイトのクリックストリームなどのソースからリアルタイムデータをキャプチャし、データベースや永続的ストレージなどの送信先に配信します。
Kafka Connect は、データベース、key-value ストア、検索インデックス、ファイルシステムなどの外部システムと接続するためのフレームワークを提供する Apache Kafka のオープンソースコンポーネントです。ただし、Kafka Connect クラスターを手動で実行するには、必要なインフラストラクチャを計画およびプロビジョンし、クラスターオペレーションを処理し、負荷の変化に応じてスケールする必要があります。
2021 年 9 月 16 日、Kafka Connect クラスターの管理を容易にする新機能を発表します。MSK Connect を使用すると、数回クリックするだけで Kafka Connect を使用してコネクタを設定およびデプロイできます。MSK Connect は、必要なリソースをプロビジョンし、クラスターをセットアップします。コネクタのヘルスと配信の状態を継続的にモニタリングし、基盤となるハードウェアにパッチを適用して管理し、スループットの変化に合わせてコネクタをオートスケールします。その結果、インフラストラクチャの管理ではなく、アプリケーションの構築にリソースを集中させることができます。
MSK Connect は Kafka Connect と完全に互換性があります。つまり、コードを変更せずに既存のコネクタを移行できます。MSK Connect を使用するために MSK クラスターは必要ありません。Amazon MSK、Apache Kafka、および Apache Kafka 互換クラスターをソースおよびシンクとしてサポートしています。これらのクラスターは、MSK Connect がクラスターにプライベートに接続できる限り、セルフマネージドとしたり、AWS パートナーおよびサードパーティーによるマネージドとしたりできます。
Amazon Aurora および Debezium での MSK Connect の使用
MSK Connect をテストするために、これを使用して、データベースの 1 つからデータ変更イベントをストリーミングしたいと思います。そのために、Apache Kafka の上に構築された変更データキャプチャ用のオープンソースの分散プラットフォームである Debezium を使用します。
MySQL 互換の Amazon Aurora データベースをソースとして使用し、Debezium MySQL コネクタを次のアーキテクチャ図で説明するセットアップで使用します。
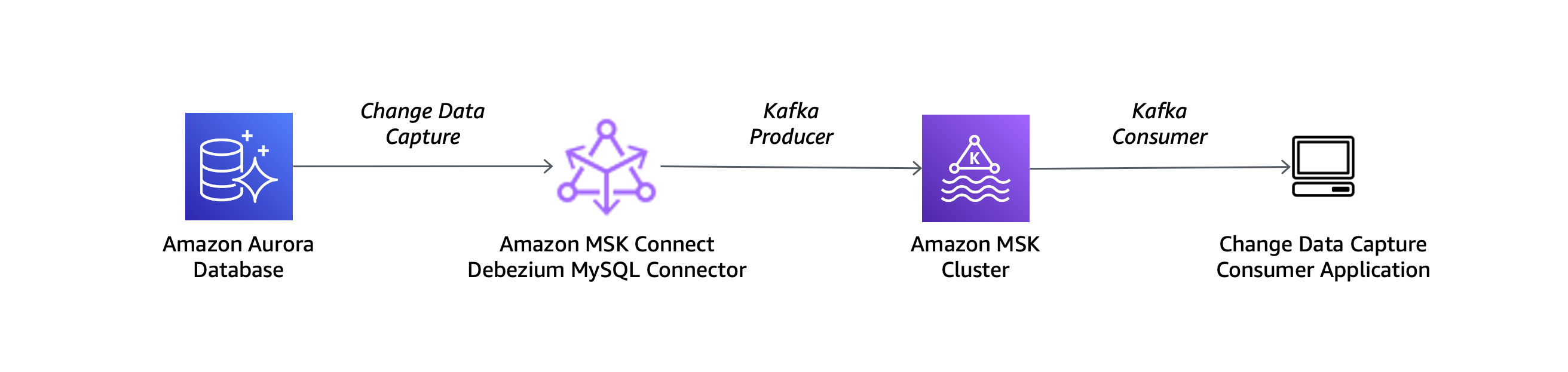
Debezium で Aurora データベースを使用するには、DB クラスターパラメータグループでバイナリログ記録を有効にする必要があります。Amazon Aurora MySQL クラスターのバイナリログを有効にするにはどうすればよいですか? の記事の手順に従います。
次に、MSK Connect 用のカスタムプラグインを作成する必要があります。カスタムプラグインは、1 つ以上のコネクタ、トランスフォーム、またはコンバーターの実装を含む JAR ファイルのセットです。Amazon MSK は、コネクタが実行されている接続クラスターのワーカーにプラグインをインストールします。
Debezium ウェブサイトから、最新の安定版リリース用の MySQL コネクタプラグインをダウンロードします。MSK Connect は ZIP または JAR 形式のカスタムプラグインを受け入れるため、ダウンロードしたアーカイブを ZIP 形式に変換し、JAR ファイルをメインディレクトリに保持します。
その後、AWS Command Line Interface (CLI) を使用して、MSK Connect のために使用しているのと同じ AWS リージョンの Amazon Simple Storage Service (Amazon S3) バケットにカスタムプラグインをアップロードします。
Amazon MSK コンソールには、新しい MSK Connect セクションがあります。コネクタを確認し、[Create connector] (コネクタを作成) を選択します。その後、カスタムプラグインを作成し、S3 バケットを参照して、以前にアップロードしたカスタムプラグイン ZIP ファイルを選択します。

プラグインの名前と説明を入力し、[Next] (次へ) を選択します。

カスタムプラグインの設定が完了したので、コネクタの作成を開始します。コネクタの名前と説明を入力します。

セルフマネージド Apache Kafka クラスターを使用するか、MSK によって管理されているクラスターを使用するかを選べます。IAM 認証を使用するように設定された MSK クラスターの 1 つを選択します。選択した MSK クラスターは、Aurora データベースと同じ仮想プライベートクラウド (VPC) にあります。接続するために、MSK クラスターと Aurora データベースは VPC 用に default セキュリティグループを使用します。わかりやすくするために、auto.create.topics.enable を true に設定したクラスター設定を使用します。
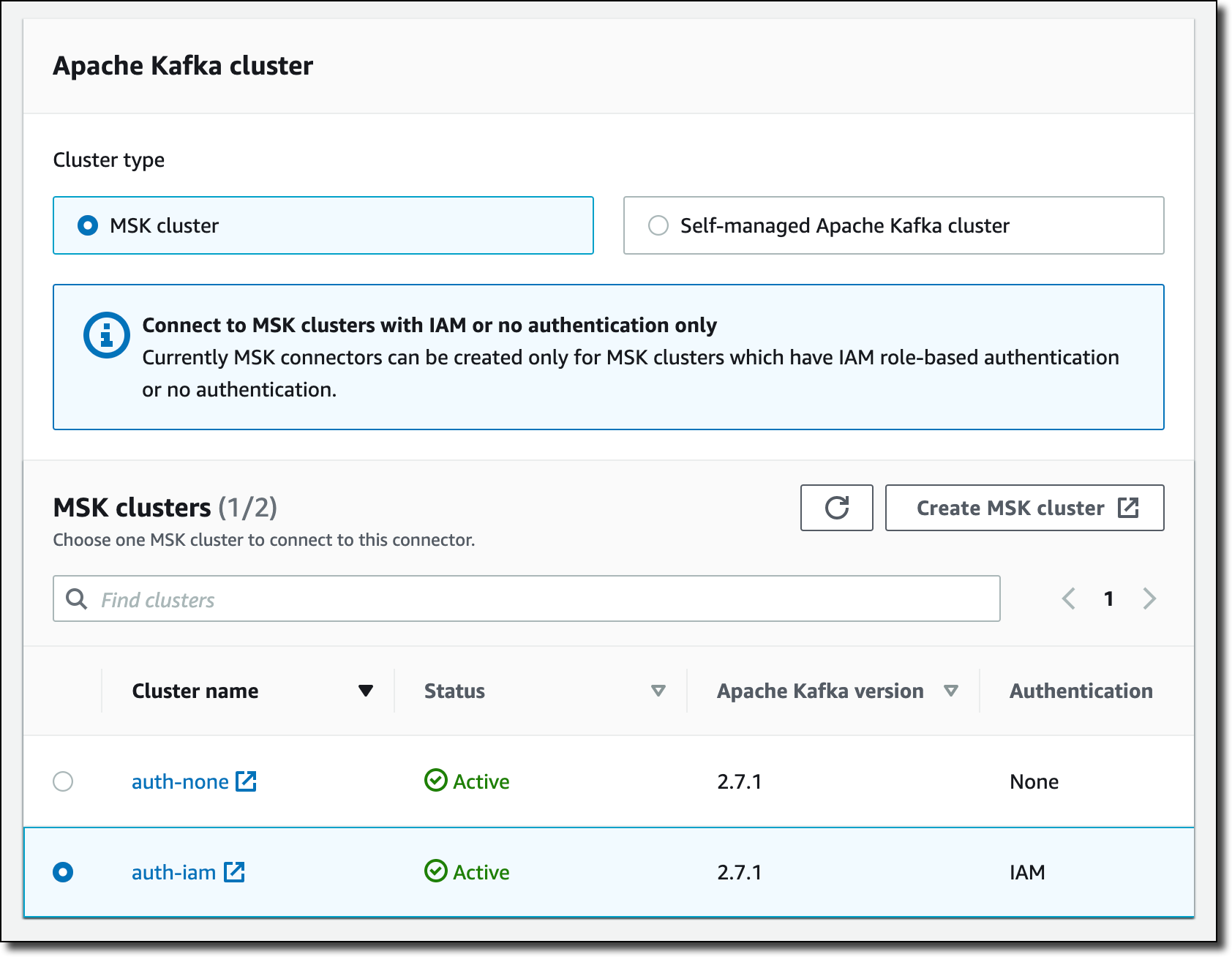
[Connector configuration] (コネクタの設定) では、次の設定を使用します。
これらの設定の一部は汎用であり、任意のコネクタのために指定される必要があります。以下に例を示します。
connector.classはコネクタの Java クラスです。tasks.maxは、このコネクタのために作成する必要があるタスクの最大数です。
その他の設定は Debezium MySQL コネクタに固有です。
database.hostnameには、Aurora データベースのライターインスタンスエンドポイントが含まれています。database.server.nameは、データベースサーバーの論理名です。Debezium によって作成された Kafka トピックの名前に使用されています。database.include.listには、指定されたサーバーによってホストされているデータベースのリストが含まれます。database.history.kafka.topicは、データベーススキーマの変更を追跡するために Debezium が内部的に使用する Kafka トピックです。database.history.kafka.bootstrap.serversには、MSK クラスターのブートストラップサーバーが含まれています。- 最後の 8 行 (
database.history.consumer.*およびdatabase.history.producer.*) は、データベース履歴トピックにアクセスするために IAM 認証を有効にします。
[Connector capacity] (コネクタの容量) では、オートスケールまたはプロビジョンされた容量を選択できます。このセットアップでは、[Autoscaled] (オートスケール済み) を選択し、その他の設定はすべてデフォルトのままにします。

オートスケールされた容量で、次のパラメータを設定できます。
- [MSK Connect Unit (MCU) count per worker] (ワーカーあたりの MSK Connect Unit (MCU) 数) – 各 MCU は、1 vCPU のコンピューティングと 4 GB のメモリを提供します。
- [minimum number of workers] (ワーカーの最小数) および [maximum number of workers] (ワーカーの最大数)。
- [Autoscaling utilization thresholds] (オートスケーリング使用率のしきい値) – オートスケーリングをトリガーする MCU 消費の上限と下限のターゲット使用率のしきい値 (%)。
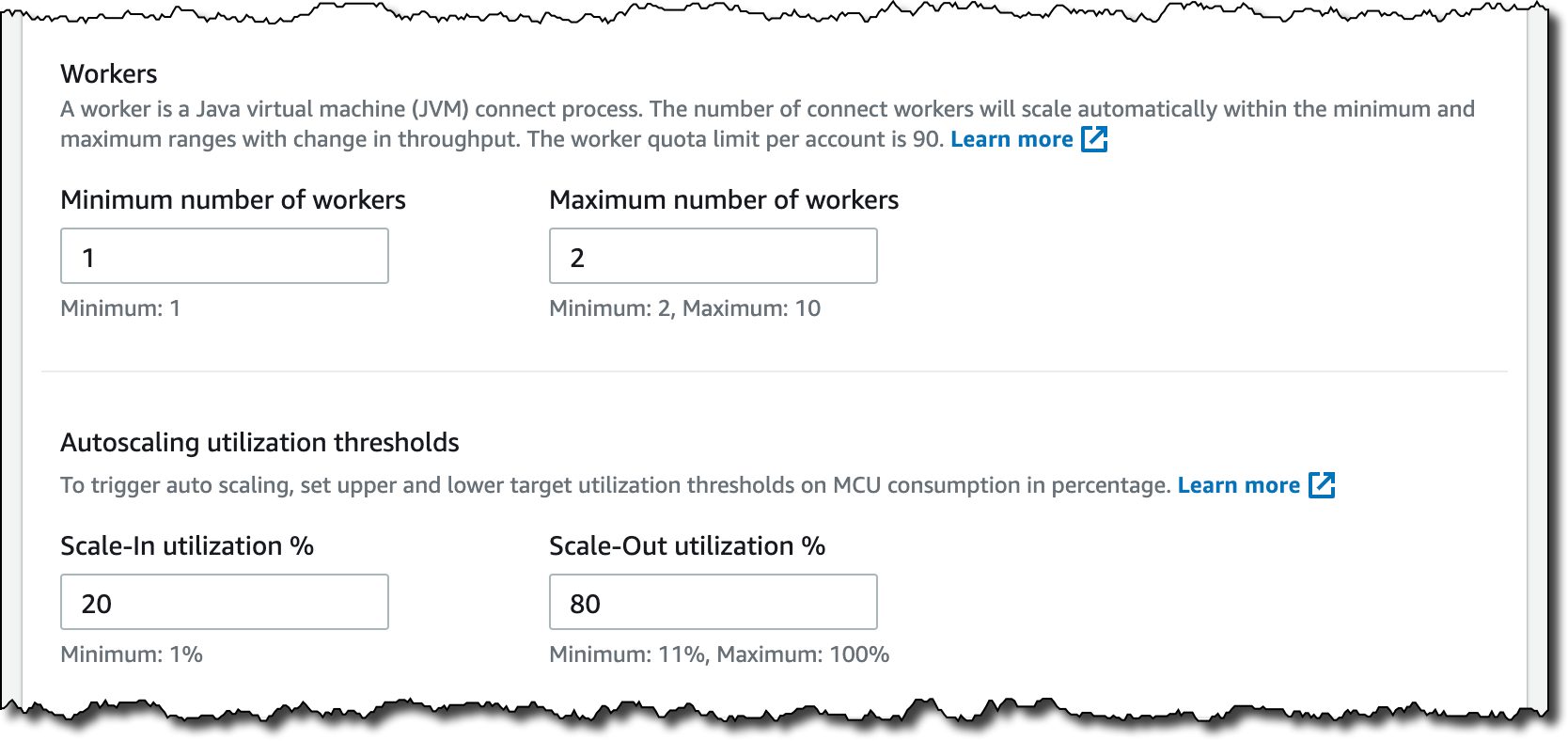
コネクタの最小および最大 MCU、メモリ、およびネットワーク帯域幅の概要が表示されます。

[Worker configuration] (ワーカー設定) で、Amazon MSK によって提供されるデフォルトの設定を使用するか、独自の設定を提供できます。このセットアップでは、デフォルトのものを使用します。
[Access permissions] (アクセス許可) で、IAM ロールを作成します。信頼されたエンティティで、kafkaconnect.amazonaws.com を追加して、MSK Connect がロールを引き受けられるようにします。
ロールは、MSK Connect が MSK クラスターや他の AWS のサービスとやり取りするために使用されます。このセットアップでは、次のように追加します。
- 前に作成した Amazon CloudWatch ロググループにログを書き込むための許可。
- IAM を介して MSK クラスターに対して認証するための許可。
Debezium コネクタは、履歴トピックの作成に使用するレプリケーションファクターを見つけるために、クラスター設定にアクセスする必要があります。このため、許可ポリシーに kafka-cluster:DescribeClusterDynamicConfiguration アクション (同等の Apache Kafka の DESCRIBE_CONFIGS クラスター ACL) を追加します。
設定によっては、ロールにさらに許可を追加する必要がある場合があります (例えば、コネクタが S3 バケットなどの他の AWS リソースにアクセスする必要がある場合など)。その場合は、コネクタを作成する前に許可を追加する必要があります。
[Security] (セキュリティ) では、認証と転送中の暗号化の設定は、MSK クラスターから取得されます。
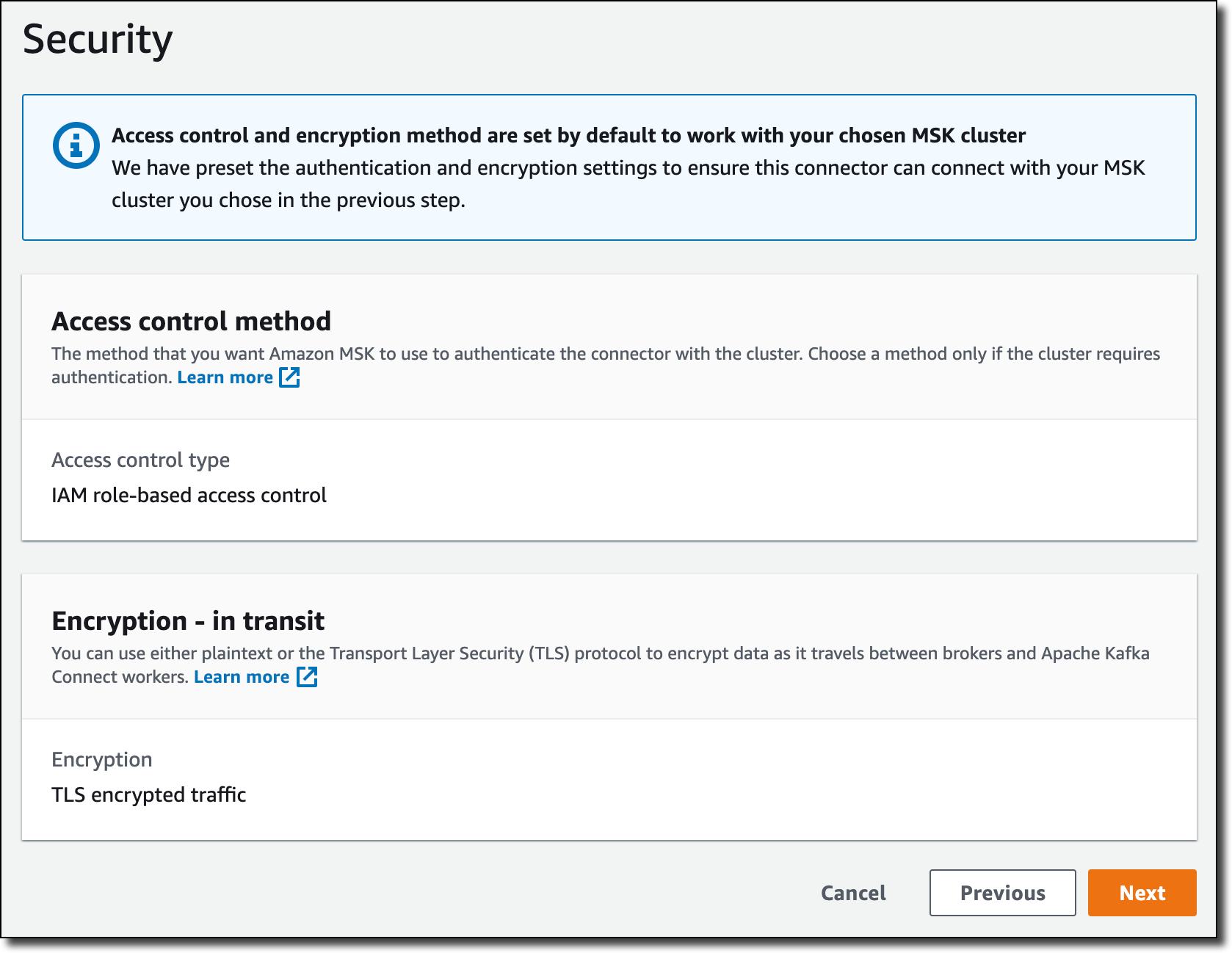
[Logs] (ログ) では、コネクタの実行に関する詳細情報を取得するために、CloudWatch Logs にログを配信することを選択します。CloudWatch Logs を使用すると、CloudWatch Logs Insights で簡単に保持を管理し、ログデータをインタラクティブに検索および分析できます。ロググループ ARN (以前 IAM ロールで使用したのと同じロググループ) を入力し、[Next] (次へ) を選択します。

設定を確認し、[Create connector] (コネクタを作成) を選択します。数分後には、コネクタが実行されています。
Amazon Aurora および Debezium での MSK Connect のテスト
では、先ほどセットアップしたアーキテクチャをテストしてみましょう。Amazon Elastic Compute Cloud (Amazon EC2) インスタンスを起動してデータベースを更新し、いくつかの Kafka コンシューマーを起動して稼働している Debezium を確認します。MSK クラスターと Aurora データベースの両方に接続できるようにするには、同じ VPC を使用し、デフォルトのセキュリティグループを割り当てます。また、インスタンスへの SSH アクセスを許可する別のセキュリティグループを追加します。
Apache Kafka のバイナリディストリビューションをダウンロードし、アーカイブをホームディレクトリに抽出します。
IAM を使用して MSK クラスターで認証するには、Amazon MSK デベロッパーガイドの指示に従って、IAM アクセスコントロールのクライアントを設定します。Amazon MSK Library for IAM の最新の安定版リリースをダウンロードします。
~/kafka_2.13-2.7.1/config/ ディレクトリで、IAM 認証を使用するように Kafka クライアントを設定するための client-config.properties ファイルを作成します。
次を実行するために Bash プロファイルに数行追加します。
- Kafka バイナリを
PATHに追加します。 - MSK Library for IAM を
CLASSPATHに追加します。 BOOTSTRAP_SERVERS環境変数を作成して、MSK クラスターのブートストラップサーバーを保存します。
$ cat >> ~./bash_profile
export PATH=~/kafka_2.13-2.7.1/bin:$PATH
export CLASSPATH=/home/ec2-user/aws-msk-iam-auth-1.1.0-all.jar
export BOOTSTRAP_SERVERS=<bootstrap servers>その後、インスタンスに対する 3 つのターミナル接続を開きます。
最初のターミナル接続では、データベースサーバー (ecommerce-server) と同じ名前のトピック用の Kafka コンシューマーを起動します。このトピックは、Debezium がスキーマの変更をストリームするために使用します (例えば、新しいテーブルが作成されたとき)。
2 番目のターミナル接続では、データベースサーバー (ecommerce-server)、データベース (ecommerce)、およびテーブル (orders) を連結して構築された名前を持つトピック用の別の Kafka コンシューマーを起動します。このトピックは、Debezium がテーブル用にデータ変更をストリームするために使用します (例えば、新しいレコードが挿入されたとき)。
3 番目のターミナル接続では、MariaDB パッケージを使用して MySQL クライアントをインストールし、Aurora データベースに接続します。
この接続から、ecommerce データベースと orders 用のテーブルを作成します。
これらのデータベースの変更は、MSK Connect によって管理される Debezium コネクタによってキャプチャされ、MSK クラスターにストリーミングされます。最初のターミナルでは、スキーマの変更でトピックを消費すると、データベースとテーブルの作成に関する情報が表示されます。
その後、3 番目のターミナルのデータベース接続に戻り、orders テーブルにいくつかのレコードを挿入します。
INSERT INTO orders VALUES ("123456", "123", "A super noisy mechanical keyboard", "50.00", "2021-08-16 10:11:12");
INSERT INTO orders VALUES ("123457", "123", "An extremely wide monitor", "500.00", "2021-08-16 11:12:13");
INSERT INTO orders VALUES ("123458", "123", "A too sensible microphone", "150.00", "2021-08-16 12:13:14");
2 番目のターミナルでは、orders テーブルに挿入されたレコードに関する情報が表示されます。
変更データキャプチャアーキテクチャは稼動しており、コネクタは MSK Connect によってフルマネージド状態です。
可用性と料金
MSK Connect は、アジアパシフィック (ムンバイ)、アジアパシフィック (ソウル)、アジアパシフィック (シンガポール)、アジアパシフィック (シドニー)、アジアパシフィック (東京)、カナダ (中部)、欧州 (フランクフルト)、欧州 (アイルランド)、欧州 (ロンドン)、欧州 (パリ)、欧州 (ストックホルム)、南米 (サンパウロ)、米国東部 (バージニア北部)、米国東部 (オハイオ)、米国西部 (北カリフォルニア)、米国西部 (オレゴン) といった AWS リージョンでご利用いただけます。詳細については、AWS リージョン別のサービス表を参照してください。
MSK Connect では、使用した分の料金をお支払いいただきます。コネクタによって使用されるリソースは、ワークロードに基づいて自動的にスケールできます。詳細については、Amazon MSK の料金のページを参照してください。
MSK Connect で Apache Kafka コネクタの管理を今すぐ簡素化しましょう。
– Danilo
原文はこちらです。