Amazon Web Services ブログ
新機能 – バイアスを検出し、機械学習モデルの透明性を向上させる Amazon SageMaker Clarify
今日は、お客様が機械学習 (ML) モデルのバイアスを検出し、ステークホルダーと顧客にモデルの動作を説明できるようにすることで透明性を高めるために役立つ Amazon SageMaker の新機能、Amazon SageMaker Clarify をご紹介します。
ML モデルは、データセットに存在する統計的パターンを学習するトレーニングアルゴリズムによって構築されるため、いつくかの疑問がすぐさま思い浮かびます。第一に、ML モデルが特定の予測にたどり着いた理由を説明できるようになるのか? 第二に、モデル化しようとしている現実問題をデータセットが忠実に表現しない場合はどうなるのか? そもそも、このような問題を検出することはできるのか? これらの問題は、認識できない形で何らかのバイアスを生じないのか? これから説明するとおり、これらは決して推論的な疑問ではなく、極めて現実的なもので、その影響は広範囲に及ぶ可能性があります。
バイアス問題から始めましょう。不正なクレジットカード決済を検出するモデルに取り組んでいることを想像してください。幸いにも、決済の大部分は正当なものであり、データセットの 99.9% を占めています。これは、不正決済が 0.1% のみであることを意味し、100,000 件のうち 100 件といったところです。二値分類モデル (正当な決済 vs. 不正な決済) のトレーニングでは、モデルが多数派グループに強い影響を受ける、つまりバイアスがかかる可能性が非常に高くなります。実際に、トリビアルモデルでは決済が常に正当であると判断されてしまうかもしれません。このモデルはまったく役に立たないものの、99.9% は正しいことになります! このシンプルな例から、データの統計的特性、そしてモデルの精度を測定するために使用するメトリクスをどれほど慎重に扱わなければならないかがわかります。
この過少出現問題には多数の派生タイプがあります。クラス、特徴、およびユニークな特徴量が増加しても、データセットには特定のグループについて少量のトレーニングインスタンスしか含まれていない可能性があります。実際、これらのグループの一部は、性別、年齢範囲、または国籍など、さまざまな社会的にセンシティブな特徴に該当することがあります。このようなグループの過少出現は、予測結果に不均衡な影響をもたらす恐れがあります。
残念ながら、悪意がまったくなかったとしても、データベースにバイアス問題が存在し、ビジネス、倫理、および規制面での影響を伴うモデルに取り込まれてしまう可能性があります。このため、モデル管理者が本番環境システムにおけるバイアスの潜在的な原因に注意することが重要になるのです。
では、説明可能性の問題についてお話しましょう。線形回帰や決定木ベースのアルゴリズムといったシンプルで十分に解明されているアルゴリズムでは、モデルを検証し、モデルがトレーニング中に学習したパラメータを調べ、モデルが主に使用する特徴を特定することは比較的簡単です。その後、このプロセスがビジネス慣行に沿っているかどうかを判断できます (つまり、「人間のエキスパートでもこうしただろう」と言うようなものです)。
しかし、モデルがますます複雑になるにつれて (深層学習さん、あなたのことです)、このような分析は不可能になります。スタンリー・キューブリックの「2001 年宇宙の旅」に出てくる先史時代の部族と同じように、私たちはしばしば、不可解なモノリスをまじまじと見詰めながら、それが何を意味するのか頭をかしげるしかありません。多くの企業と組織は、ML モデルを本番環境で使用する前に、それらを説明可能なものにする必要があるかもしれません。さらに、一部の規制では、ML モデルが重大な意思決定の一環として使用される場合に説明可能性が義務付けられている場合があり、この説明可能性は、最初にお話したバイアスの検出にも役立ちます。
こうして、データセットとモデルに存在するバイアスを検出し、モデルが予測を行う方法を理解するための援助をお客様から求められた AWS は、作業を開始し、SageMaker Clarify を考案しました。
Amazon SageMaker Clarify のご紹介
SageMaker Clarify は、AWS の完全マネージド型 ML サービスである Amazon SageMaker の新しい機能セットです。これは、ML のためのウェブベースの統合開発環境である SageMaker Studio に加えて、Amazon SageMaker Data Wrangler、Amazon SageMaker Experiments、および Amazon SageMaker Model Monitor といった SageMaker の他の機能にも統合されています。
SageMaker Clarify を使用することにより、データサイエンティストは以下を実行することができます。
- トレーニングを開始する前にデータセットに存在するバイアスを検出し、トレーニング後はモデルで検出する。
- さまざまな統計メトリクスを使用してバイアスを測定する。
- モデル全体、および個々の予測の両方について、特徴量が予測結果にどのように寄与するかを説明する。
- 経時的なバイアスのドリフトと特徴重要性のドリフトを検出する (Amazon SageMaker Model Monitor との統合によって実行可能になりました)。
これらの機能をひとつずつ見てみましょう。
データセットバイアスの検出: これは重要な最初の一歩です。実際、大きく偏ったデータセットはトレーニングには適していないと言ってよいでしょう。これを早期に把握することで、時間とお金を節約し、苛立たなくてもすむようになります! データセットについて SageMaker Clarify が計算したバイアスメトリクスを調べてから、データ処理パイプラインに独自のバイアス低減手法を追加することができます。データセットの修正と処理が終わったら、もう一度バイアスを測定して、バイアスが実際に減少したかどうかを確認できます。
モデルバイアスの検出: モデルをトレーニングしたら、SageMaker Clarify のバイアス分析を実行できます。これには、一時的なエンドポイントへの自動デプロイメントと、ユーザーのモデルとデータセットを使用したバイアスメトリクスの計算が含まれます。これらのメトリクスを計算することで、トレーニングしたモデルについて、グループ全体での類似する予測動作の有無を把握できます。
バイアスの測定: SageMaker Clarify では、多数の異なるバイアスメトリクスから選択することができます。以下がその例です。
- ラベルにおける陽性率の差 (DPL): データセットのラベルに特定のセンシティブな特徴量との相関関係がないか? たとえば、特定の都市に住んでいる人々が陽性となる可能性が高くなっていないか?
- 予測されたラベルにおける陽性率の差 (DPPL): 特定のグループについて陽性ラベルを過剰予測していないか?
- 精度差 (AD): モデルによる予測の精度が他のグループよりも高いというグループがないか?
- 反実仮想 – フリップテスト (FT): ひとつのグループの各メンバーを調べ、それらを他のグループの類似するメンバーと比較した場合、これらのメンバーが異なる予測を得ていないか?
予測の説明 – モデルが予測を行う方法を説明するために、SageMaker Clarify は SHapley Additive exPlanations (SHAP) と呼ばれる一般的な手法をサポートしています。ゲーム理論に由来する SHAP は、各データインスタンスについてそれぞれの予測結果に対する特徴量の寄与を分析し、それらを正の値と負の値で表します。例えば、与信取引申請モデルでの予測では、アリスの申請が 87.5% のスコアで承認されていて、雇用ステータス (+27.2%) とクレジットスコア (+32.4%) がこのスコアに最も強く寄与しており、所得水準がわずかにマイナスの影響を及ぼしている (-5%) ことがわかります。このような洞察は、モデルが期待どおりに機能しているという信頼を築き、顧客と規制当局にこのモデルが特定の予測にたどり着いた理由を説明する上で非常に重要です。完全なデータセットに対する SHAP 値をさらに分析することで、特徴と特徴量の相対的な重要性を特定することもでき、予測における問題とバイアスの発見につながる可能性があります。
このように、 SageMaker Clarify にはバイアス検出と説明可能性のための極めて強力な機能がいくつか備わっています。幸いに、SageMaker Clarify ではこれらの機能の使用も非常に簡単です。まず、表形式データセット (CSV または JSON) の前処理されたクリーンコピーを Amazon Simple Storage Service (S3) にアップロードする必要があります。次に、組み込まれたコンテナを使用して、データセットで Amazon SageMaker Processing ジョブを開始し、ターゲット属性、バイアスを分析するセンシティブな列の名前と値、および計算したいバイアスメトリクスを定義する短い設定ファイルを渡します。お分かりのとおり、このジョブは完全マネージド型のインフラストラクチャで実行されます。トレーニング後の分析には、ジョブが一時的なエンドポイントの自動作成と削除も実行します。ジョブが完了すると、S3 と SageMaker Studio で結果を取得でき、これには結果を要約する自動生成されたレポートが含まれます。
それでは、SageMaker Clarify の使用を開始する方法をご紹介しましょう。
Amazon SageMaker Clarify を使用したデータセットとモデルの検証
German Credit Data データセットには、ラベル付けされた 1,000 部の与信取引申請が含まれており、これを XGBoost での二値分類モデルのトレーニングに使用しました。各データインスタンスには、信用目的、与信額、住居の状況、および雇用履歴などの 20 の特徴があります。カテゴリ別の特徴は Axx 値でコード化されています。たとえば、信用実績の特徴は、A30 なら「与信を受けていない」、A31 なら「この銀行での与信はすべて完済されている」などのようにコード化されています。
特に、このデータセットには、顧客が外国人労働者かどうかがわかる特徴が含まれており、データセットに目を通すと、外国人労働者が有利になる大規模な不均衡の兆候があるのがわかります。ここにバイアスが隠されている可能性はあるのでしょうか? モデルはどうでしょう? XGBoost はバイアスを増加させたのか、それとも減少させたのでしょうか? どの特徴が予測結果に最も寄与しているのでしょうか? 調べてみましょう。
モデルのトレーニング後に続く次のステップは、バイアスメトリクスを計算する組み込みのコンテナイメージを使用して、データセットで SageMaker Clarify のバイアス分析ジョブを実行することです。ジョブの入力は、データセットと、以下を定義する JSON 設定ファイルです。
- ターゲット属性 (
Class1Good2Bad) の名前と陽性予測の値 (1)。 - 分析するセンシティブな特徴 (「ファセット」と呼ばれます) とそれらの値。今回は、
ForeignWorkerが0に設定されているインスタンスがデータセットで過小出現しているようなので、これらに注目します。 - ジョブが計算する必要があるバイアスメトリクス。モデルはすでに用意してあるので、その名前を渡して、トレーニング後のメトリクスを一時的なエンドポイントで計算できるようにします。
以下は、設定ファイルにおける関連スニペットです。
"label": "Class1Good2Bad",
"label_values_or_threshold": [1],
"facet": [
{
"name_or_index" : "ForeignWorker",
"value_or_threshold": [0]
}
],
. . .
"methods": {
"pre_training_bias": {"methods": "all"}
"post_training_bias": {"methods": "all"}
},
"predictor": {
"model_name": "xgboost-german-model",
"instance_type": "ml.m5.xlarge",
"initial_instance_count": 1
}次に、ジョブの入力 (データセットおよび設定ファイル) と出力 (レポート) を設定し、S3 のすべての適切なパスを渡します:
config_input = ProcessingInput(
input_name="analysis_config",
source=analysis_config_s3_path,
destination="/opt/ml/processing/input/config")
data_input = ProcessingInput(
input_name="dataset",
source=train_data_s3_path,
destination="/opt/ml/processing/input/data")
result_output = ProcessingOutput(
source="/opt/ml/processing/output",
destination=analysis_result_s3_path,
output_name="analysis_result")
最後に、処理ジョブを実行します。
from sagemaker.processing import Processor, ProcessingInput, ProcessingJob, ProcessingOutput
analyzer_image_uri = f'678264136642.dkr.ecr.us-east-2.amazonaws.com/sagemaker-xai-analyzer:latest'
analyzer = Processor(base_job_name='analyzer',
image_uri=analyzer_image_uri,
role=sagemaker.get_execution_role(),
instance_count=1,
instance_type='ml.c5.xlarge')
analyzer.run(inputs=[ data_input, config_input], outputs=[result_output])処理ジョブが完了すると、レポートを取得できます。では、バイアスメトリクスを見ていきましょう。
Amazon SageMaker Clarify を使用したバイアスの検出
以下は、トレーニング前のバイアスメトリクスの一部です。
"ForeignWorker": [
{
"value_or_threshold": "0",
"metrics": [
{
"name": "CI",
"description": "Class Imbalance (CI)",
"value": 0.9225
},
{
"name": "DPL",
"description": "Difference in Positive Proportions in Labels (DPL)",
"value": -0.21401904442300435
},
. . . クラス不均衡メトリクスが、データセットに目を通したときの印象を裏付けています。データセットでは、評価対象となる外国労働者が国内労働者よりも約 92% 多くなっています。この不均衡が原因かどうかは別として、国内労働者の陽性率の差がかなりのマイナスになっていることもわかります。つまり、陽性ラベルの国内労働者の割合が少ないということです。この統計パターンは ML アルゴリズムによって検出される可能性があり、陰性とされる国内労働者の割合が高くなる原因となります。これが実際に妥当であるかどうかを判断するにはさらなる分析が必要になりますが、いずれにせよ、SageMaker Clarify がこの潜在的な問題について警告できたのはすばらしいことです。
トレーニング済みのモデルを提供したので、トレーニング後のメトリクスも利用できます。DPPL と DPL を比較すると、XGBoost が陽性率のバイアスをわずかに減少させたことがわかります (-18.8% vs -21.4%)。DAR がマイナスになっているのもわかります。これは、モデルの国内労働者に対する精度が外国労働者の精度よりも高いことを示しています。
"ForeignWorker": [
{
"value_or_threshold": "0",
"metrics": [
{
"name": "DPPL",
"description": "\"Difference in Positive Proportions in Predicted Labels (DPPL)\")",
"value": -0.18801124208230213
},
{
"name": "DAR",
"description": "Difference in Acceptance Rates (DAR)",
"value": -0.050909090909090904
},
{
"name": "DRR",
"description": "Difference in Rejection Rates (DRR)",
"value": 0.0365296803652968
},
. . .SageMaker Clarify は SageMaker Studio に統合されているので、そこでバイアスメトリクスを視覚化できます。これは、トライアルのリストから処理ジョブを見つけて、[Open in trial details] (トライアルの詳細を開く) を右クリックし、[Bias report] (バイアスレポート) ビューを選択するだけで実行できます。
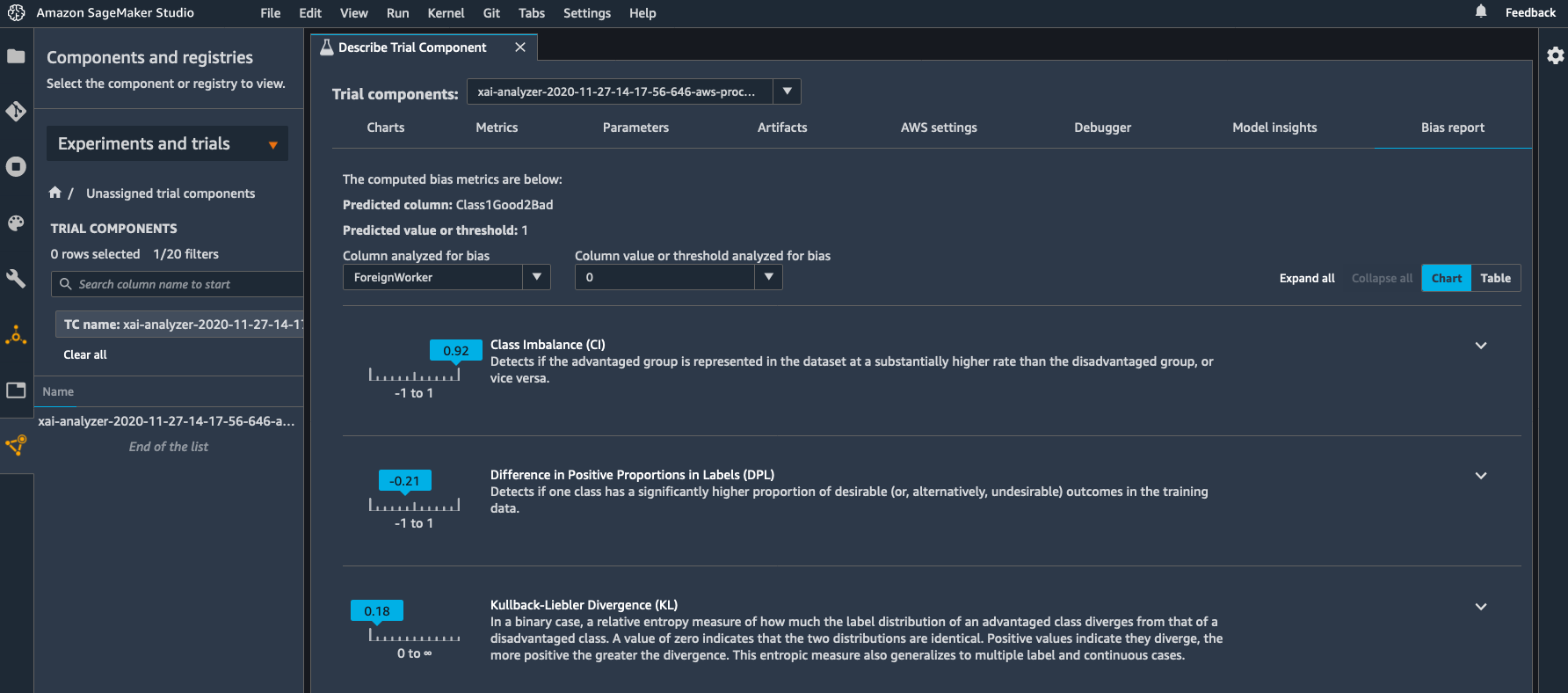
最後に、特定のバイアスメトリクスの値が高くなっていることに問題があるかどうかを判断するには、ドメイン固有の考慮が必要になり、倫理、社会、規制、およびビジネス面での考慮事項に基づいて行われなければなりません。同様に、バイアスを除去するための介入には、多くの場合、問題の明確化からデプロイメントにおけるフィードバックループまで、ML ライフサイクル全体の慎重な分析が必要になります。
それでは、モデルがその予測の基準とする特徴を理解する上で、SageMaker Clarify がどのように役立つのかを見てみましょう。
Amazon SageMaker Clarify を使用した予測の説明
レポートには、データセット内にあるすべての特徴の相対的な重要性を示すグローバルな SHAP 値が含まれています。SageMaker Studio で利用できる特徴重要度グラフから、信用期間、当座預金口座がない (A14)、および融資額が 3 つの最も重要な特徴であることがわかります。全ての条件が同じだとすると、銀行は、短期間の少額融資を受けており、小切手を切る可能性がない顧客をより安全だと見なすでしょう。

S3 には、個々のデータインスタンスに対する SHAP 値が記載された CSV ファイルもあります。このファイルは、特徴と特徴量の重要性に関する全体像を提供してくれます。
使用の開始
ご覧いただいたとおり、SageMaker Clarify はバイアスを検出し、モデルの仕組みを理解するための強力なツールです。Amazon SageMaker Clarify は、本日から Amazon SageMaker が利用できるすべてのリージョンでご利用いただけ、追加料金は発生しません。
使用をすばやく開始するためのサンプルノートブックをご用意しましたので、ぜひお試しいただき、感想をお聞かせください。AWS では、お客様からのフィードバックをお待ちしております。フィードバックは、通常の AWS サポート担当者、または SageMaker の AWS フォーラム経由でお送りください。
貴重な時間を割いて助けてくださった同僚の Sanjiv Das、Michele Donini、Jason Gelman、Krishnaram Kenthapadi、Pinar Yilmaz、そして Bilal Zafar に感謝します。
データセット参照元: Dua, D. and Graff, C.(2019).UCI Machine Learning Repository.Irvine, CA: University of California, School of Information and Computer Science.