AWS Glue には、ネストされた JSON をリレーショナルデータベースに簡単にインポートできるカラムに変換することによって抽出、変換、ロード (ETL) プロセスをシンプル化する、Relationalize と呼ばれるトランスフォームがあります。Relationalize は、ネストされた JSON を JSON ドキュメントの最外部レベルでキーと値のペアに変換します。変換されたデータでは、ネストされた JSON からの元のキーのリストが、ピリオドで区切られた形で維持されます。
サンプルユースケースを使って Relationalize がどのように役立つかを見てみましょう。
Relationalize の実行例
ビデオゲームの開発者が、JSON 形式で保存されたデータに基づいてプレイヤーの行動についてのレポートを実行するために Amazon Redshift などのデータウェアハウスを使用したいとしましょう。サンプル 1 は、ゲームからのユーザーデータ例を示しています。「User1」という名前のプレイヤーには、ネストされた JSON データ内に種族、クラス、ロケーションなどの特徴があります。さらに下に行くと、プレイヤーの武器情報に追加のネストされた JSON データが含まれています。開発者がデータウェアハウスに対してこのデータの ETL を行いたい場合、コードではネストされたループや再帰的関数を用いなければならないかもしれません。
サンプル 1: ネストされた JSON
{
"player": {
"username": "user1",
"characteristics": {
"race": "Human",
"class": "Warlock",
"subclass": "Dawnblade",
"power": 300,
"playercountry": "USA"
},
"arsenal": {
"kinetic": {
"name": "Sweet Business",
"type": "Auto Rifle",
"power": 300,
"element": "Kinetic"
},
"energy": {
"name": "MIDA Mini-Tool",
"type": "Submachine Gun",
"power": 300,
"element": "Solar"
},
"power": {
"name": "Play of the Game",
"type": "Grenade Launcher",
"power": 300,
"element": "Arc"
}
},
"armor": {
"head": "Eye of Another World",
"arms": "Philomath Gloves",
"chest": "Philomath Robes",
"leg": "Philomath Boots",
"classitem": "Philomath Bond"
},
"location": {
"map": "Titan",
"waypoint": "The Rig"
}
}
}
その代わりに、開発者は Relationalize トランスフォームを使うことができます。サンプル 2 は、変換されたデータの様子を示しています。
サンプル 2: フラット化された JSON
{
"player.username": "user1",
"player.characteristics.race": "Human",
"player.characteristics.class": "Warlock",
"player.characteristics.subclass": "Dawnblade",
"player.characteristics.power": 300,
"player.characteristics.playercountry": "USA",
"player.arsenal.kinetic.name": "Sweet Business",
"player.arsenal.kinetic.type": "Auto Rifle",
"player.arsenal.kinetic.power": 300,
"player.arsenal.kinetic.element": "Kinetic",
"player.arsenal.energy.name": "MIDA Mini-Tool",
"player.arsenal.energy.type": "Submachine Gun",
"player.arsenal.energy.power": 300,
"player.arsenal.energy.element": "Solar",
"player.arsenal.power.name": "Play of the Game",
"player.arsenal.power.type": "Grenade Launcher",
"player.arsenal.power.power": 300,
"player.arsenal.power.element": "Arc",
"player.armor.head": "Eye of Another World",
"player.armor.arms": "Philomath Gloves",
"player.armor.chest": "Philomath Robes",
"player.armor.leg": "Philomath Boots",
"player.armor.classitem": "Philomath Bond",
"player.location.map": "Titan",
"player.location.waypoint": "The Rig"
}
この後、データをデータベースまたはデータウェアハウスに書き込むことができます。また、コンマ区切り値 (CSV) 形式、または Optimized Row Columnar (ORC) 形式などの列指向ファイル形式などの区切りテキストファイルに書き込むこともできます。Amazon S3 での長期ストレージには、これらの形式タイプのいずれかを使うことができます。変換済みファイルの S3 での保存は、Amazon Athena または Amazon Redshift Spectrum を使用してこのデータをクエリできるという追加のメリットも提供します。S3 に保存されたデータと Amazon Redshift データウェアハウスに保存されたデータ間で joins を実行することによって、データの有用性をさらに拡大することができます。
開始する前に…
この例では、ETL コード開発での時間を節約する
- Amazon S3 バケットへのデータの保存、および AWS Glue データカタログでデータを使用できるようにするための AWS Glue クローラーの使用という 2 つの準備的なステップを実行しました。これらを実行する方法の手順については、AWS Glue ドキュメントの Cataloging Tables with a Crawler をご覧いただけます。使用した AWS Glue のデータベース名は「blog」で、テーブル名は「players」です。以下のサンプルコードで、これらの値が使用されているのがわかります。
- Zeppelin ノートブックは、AWS Glue 内で使用できる自動デプロイメントを使ってデプロイしました。すでに AWS Glue 開発エンドポイントを使って Zeppelin ノートブックをデプロイしている場合は、このデプロイメント手順を省略できます。そうでない場合は、Zeppelin のデプロイ方法を簡単に確認しましょう。
AWS Glue を使った Zeppelin ノートブックのデプロイメント
以下のステップは AWS Glue ドキュメントで説明されており、ここでは明確化のためにスクリーンショットをいくつか記載します。
まず、以下の 2 つの IAM ロールを作成します。
次に、AWS Glue マネジメントコンソールで [Dev endpoints] を選択し、次に [Add endpoint] を選択します。

エンドポイントと作成した AWS Glue IAM ロールの名前を指定します。
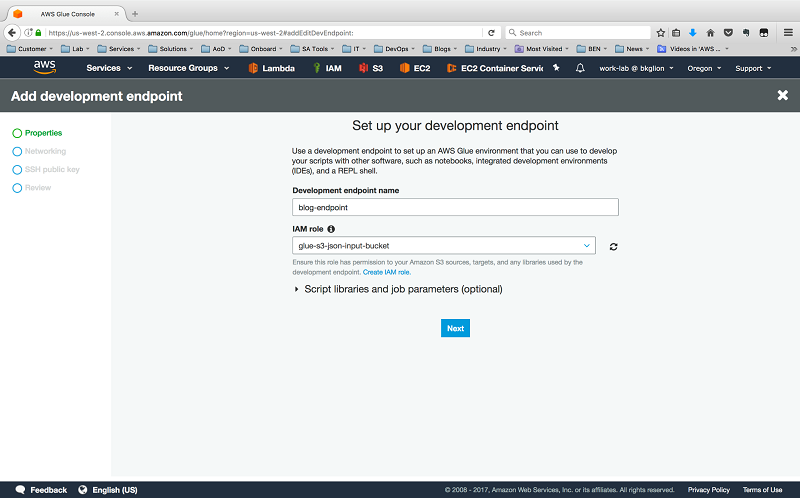
今回のコードは S3 としかやり取りしないので、ネットワーク画面で [Skip Networking] を選択します。
セキュアシェル (SSH) 公開鍵を提供し、設定を確定することによって開発エンドポイントプロセスを完了します。
新しい開発エンドポイントの Provisioning status が PROVISIONING から READY に変わったら、エンドポイントを選択し、次に [Actions] で [Create notebook server] を選択します。
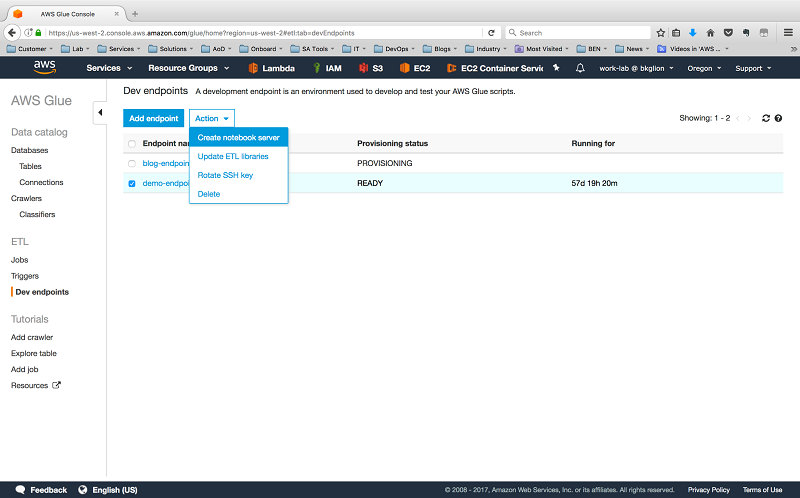
先ほど作成したロールと、TCP ポート 443 でのインバウンドアクセスが許可されたセキュリティグループを含むノートブックサーバーの詳細を入力します。

これを行うことによって、AWS CloudFormation テンプレートが自動的に起動されます。出力は、ウィザードで指定したユーザー名とパスワードで Zeppelin ノートブックにアクセスするために使用できる URL を指定します。
ネストされた JSON をフラット化する方法
データがロードされ、ノートブックサーバーの準備が整ったところで、Zeppelin にアクセスして新しいノートを作成し、インタプリタを spark に設定しました。ORC に出力する別のジョブのために AWS Glue が以前生成した Python コードをいくつか使用しました。次に、Relationalize トランスフォームを追加しました。結果の Python コードはサンプル 3 で確認できます。
サンプル 3: ネストされた JSON を変換し、ORC に出力する Python コード
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
#from awsglue.transforms import Relationalize
# Begin variables to customize with your information
glue_source_database = "blog"
glue_source_table = "players"
glue_temp_storage = "s3://blog-example-edz/temp"
glue_relationalize_output_s3_path = "s3://blog-example-edz/output-flat"
dfc_root_table_name = "root" #default value is "roottable"
# End variables to customize with your information
glueContext = GlueContext(spark.sparkContext)
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = glue_source_database, table_name = glue_source_table, transformation_ctx = "datasource0")
dfc = Relationalize.apply(frame = datasource0, staging_path = glue_temp_storage, name = dfc_root_table_name, transformation_ctx = "dfc")
blogdata = dfc.select(dfc_root_table_name)
blogdataoutput = glueContext.write_dynamic_frame.from_options(frame = blogdata, connection_type = "s3", connection_options = {"path": glue_relationalize_output_s3_path}, format = "orc", transformation_ctx = "blogdataoutput")
このスクリプトで実際に行われている事柄
import ステートメントの後で、GlueContext オブジェクトをインスタンス化します。これによって、AWS Glue でデータを操作できるようになります。次に、AWS Glue 「blog」データベースの「players」テーブルから DynamicFrame (datasource0) を作成します。この DynamicFrame を使用して、データ構造が希望する出力形式に記述される前に、その構造で必要な操作をすべて行います。ソースファイルはそのままで変更されません。
次に Relationalize トランスフォーム (Relationalize.apply()) を datasource0 と共にパラメータのひとつとして実行します。もうひとつの重要なパラメータは name パラメータです。これは、変換完了後にデータを認識するカギとなります。
Relationalize.apply() メソッドが DynamicFrameCollection を返します。これは dfc 変数に保存されます。データを S3 に書き込む前に、 DynamicFrame を DynamicFrameCollection オブジェクトから選択する必要があります。これは、 dfc.select() メソッドを使って行います。正しい DynamicFrame が blogdata 変数に保存されます。
単一の DynamicFrame で始めたのに DynamicFrameCollection が返された理由が気になるかもしれません。この戻り値は、Relationalize が JSON ドキュメント内の配列を処理する方法に起因します。 DynamicFrame は配列ごとに作成されます。Relationalize の動作が完了すると、ルートデータ構造と共に、生成された DynamicFrame のそれぞれが DynamicFrameCollection に追加されます。今回のデータ内に配列はありませんが、これを念頭に置いておくとよいでしょう。最後に、ルート DynamicFrame を S3 内の ORC ファイルに出力 (blogdataoutput) します。
変換されたデータの使用
初めに説明したユースケースのひとつは、ORC ファイルをクエリするための Amazon Athena または Amazon Redshift Spectrum の使用でした。
今回は、以下の SQL DDL ステートメントを使用して、Amazon S3 に保存されたデータのクエリを行うことができるように、両方のサービスで外部テーブルを作成しました。
サンプル 4: Amazon Athena DDL
CREATE EXTERNAL TABLE IF NOT EXISTS blog.blog_data_athena_test (
`characteristics_race` string,
`characteristics_class` string,
`characteristics_subclass` string,
`characteristics_power` int,
`characteristics_playercountry` string,
`kinetic_name` string,
`kinetic_type` string,
`kinetic_power` int,
`kinetic_element` string,
`energy_name` string,
`energy_type` string,
`energy_power` int,
`energy_element` string,
`power_name` string,
`power_type` string,
`power_power` int,
`power_element` string,
`armor_head` string,
`armor_arms` string,
`armor_chest` string,
`armor_leg` string,
`armor_classitem` string,
`map` string,
`waypoint` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
WITH SERDEPROPERTIES (
'serialization.format' = '1'
) LOCATION 's3://blog-example-edz/output-flat/'
TBLPROPERTIES ('has_encrypted_data'='false');
サンプル 5: Amazon Redshift Spectrum DDL
-- Create a Schema
-- A single schema can be used with multiple external tables.
-- This step is only required once for the external tables you create.
create external schema spectrum
from data catalog
database 'blog'
iam_role 'arn:aws:iam::0123456789:role/redshift-role'
create external database if not exists;
-- Create an external table in the schema
create external table spectrum.blog(
username VARCHAR,
characteristics_race VARCHAR,
characteristics_class VARCHAR,
characteristics_subclass VARCHAR,
characteristics_power INTEGER,
characteristics_playercountry VARCHAR,
kinetic_name VARCHAR,
kinetic_type VARCHAR,
kinetic_power INTEGER,
kinetic_element VARCHAR,
energy_name VARCHAR,
energy_type VARCHAR,
energy_power INTEGER,
energy_element VARCHAR,
power_name VARCHAR,
power_type VARCHAR,
power_power INTEGER,
power_element VARCHAR,
armor_head VARCHAR,
armor_arms VARCHAR,
armor_chest VARCHAR,
armor_leg VARCHAR,
armor_classItem VARCHAR,
map VARCHAR,
waypoint VARCHAR)
stored as orc
location 's3://blog-example-edz/output-flat';
サンプル 6 にあるように、Redshift Spectrum テーブル (spectrum.playerdata) を Amazon Redshift テーブル (public.raids) のデータに結合して高度なレポートを生成するクエリも行いました。 where 句では、両方のデータソースに共通の username 値に基づいて 2 つのテーブルを結合します。
サンプル 6: Redshift Spectrum データと Amazon Redshift データの結合を伴う select ステートメント
-- Get Total Raid Completions for the Hunter Class.
select spectrum.playerdata.characteristics_class as class, sum(public.raids."completions.val.raids.leviathan") as "Total Hunter Leviathan Raid Completions" from spectrum.playerdata, public.raids
where spectrum.playerdata.username = public.raids."completions.val.username"
and spectrum.playerdata.characteristics_class = 'Hunter'
group by spectrum.playerdata.characteristics_class;
まとめ
この記事では、ネストされた JSON の変換を自動化するための Relationalize トランスフォームを使用して、AWS Glue でネストされた JSON データをフラット化することがどれだけシンプルであるかを実演しました。AWS Glue は、Python オートメーションスクリプトを開発するために使用できる Zeppelin ノートブックのデプロイメントも自動化します。最後に、AWS Glue では、Amazon Athena および Amazon Redshift Spectrum などのツールを使ってさらに分析を行うため、変換されたデータを直接リレーショナルデータベースに、または Amazon S3 内のファイルに出力することも可能です。
Relationalize は非常に優れたトランスフォームですが、AWS Glue で使用できるトランスフォームはこれだけではありません。利用可能なトランスフォームの完全なリストは、AWS Glue ドキュメントの Built-In Transforms でご覧いただけます。ぜひ今すぐお試しください !
その他の参考資料
この記事が役に立つと思われる場合は、Using Amazon Redshift Spectrum, Amazon Athena and AWS Glue with Node.js in Production と Build a Data Lake Foundation with AWS Glue and Amazon S3 も併せてお読みください。

今回のブログ投稿者について

Trevor Roberts Jr は AWS のソリューションアーキテクトです。お客様がクラウドで成功することを支援する、アーキテクチャ・ガイダンスを行っています。そのかたわらで、Trevor は行ったことのない土地への旅行や家族との時間を楽しんでいます。
require([‘blog’], function() {
AWS.Blog.commenting(‘#aws-comment-trigger-4000’);
});
{{{items.0.additionalFields.title}}}