Pocket Bundle シリーズ : Amazon S3 ~ 無制限に拡張可能なオブジェクトストレージ
2026-04-02 | Author : 米倉 裕基 (監修 : 伊勢田 氷琴)
Pocket Bundle シリーズとは ?
AWS サービスの要点を「ポケットに入れて持ち歩ける」コンパクトさで解説するシリーズです。図解とポイント解説を中心に、短時間で要点を把握できる構成になっています。基礎概念から実践的な設計知識まで、現場で役立つ情報を凝縮しています。
Amazon S3 とは ?
S3 は「Simple Storage Service」の頭文字 3 つの S から名付けられた、AWS の中核ストレージサービスです。2006 年のサービス開始以来、Amazon EC2 と並んで AWS の基盤を支え続けており、現在では世界中の企業がペタバイト規模のデータを S3 上で管理しています。
「オブジェクトストレージ」とは、ファイルをフォルダ階層ではなくフラットな構造で管理する方式です。データ本体にメタデータを紐付けて保存するため、大規模なデータを低コストで扱うことに最適化されています。
詳しくは、公式ドキュメントの「Amazon S3 とは」をご覧ください。
X ポスト » | Facebook シェア » | はてブ »

builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
主な特徴
S3 には 3 つの主要な特徴があります。99.999999999 % (イレブンナイン) の耐久性、事実上無制限のスケーラビリティ、そして豊富なストレージクラスです。
「耐久性」と「可用性」は混同されがちですが、意味が異なります。耐久性はデータが消失しない確率、可用性はサービスにアクセスできる確率です。S3 Standard の可用性は 99.99 % で設計されており (年間約 52 分のダウンタイム相当)、SLA 保証値は 99.9 % です。データは失われなくても、一時的にアクセスできない時間は存在します。
事実上容量上限はなく「ペタバイト規模のデータも格納可能」ですが、単一のオブジェクトサイズの上限は 50 TB です (2025 年 12 月に 5TB から引き上げられました)。
ストレージクラスは後から変更可能です。最初は S3 Standard で始め、アクセスパターンが判明してからライフサイクルポリシーで自動最適化するのが一般的な運用です。
詳しくは、公式ドキュメントの「Amazon S3 の特徴」をご覧ください。

バケットとオブジェクトの基本
S3 は「バケット」の中に「オブジェクト」を格納する構造です。バケットはオブジェクトを格納するコンテナです。オブジェクトはデータ本体 (ファイルそのもの) とメタデータ (データに関する付随情報) で構成されます。
バケット名の「グローバルで一意」という制約は、全 AWS アカウントで重複不可を意味します。そのため company-project-env のように会社名・プロジェクト名・環境名を組み合わせた命名が一般的です。IP アドレス形式やピリオド連続、末尾ハイフンは使用できません。また、バケット名は作成後に変更できないため、命名規則を事前に検討しておくことをおすすめします。
メタデータはシステムメタデータ (Content-Type、Last-Modified など) とユーザー定義メタデータの 2 種類があります。ユーザー定義メタデータは 2 KB まで付与できます。
詳しくは、公式ドキュメントの「汎用バケットの概要」をご覧ください。

ストレージクラスの種類と選択
S3 はアクセス頻度やユースケースに応じて複数のストレージクラスを提供しています。頻繁にアクセスするデータ向けの S3 Standard、アクセスパターンが変化するデータ向けの S3 Intelligent-Tiering、低頻度アクセス向けの S3 Standard-IA / S3 One Zone-IA、長期保管向けの S3 Glacier 系 3 クラス、そして高速処理向けの S3 Express One Zone があります。また、AI 向けの新しいバケットタイプとして S3 Vectors も登場しています。
アクセスパターンが不明な場合は、S3 Intelligent-Tiering が有力な選択肢です。アクセス頻度に応じて自動的に最適なクラスへ移行するため、手動での判断が不要になります。なお、Archive Access 層と Deep Archive Access 層への自動移行はオプトイン (明示的な有効化) が必要です。また、1,000 オブジェクトあたり月額 $0.0025 の監視料金が発生します (128 KB 未満のオブジェクトは監視対象外で料金もかかりません)。監視対象 (128 KB 以上) のファイルが大量にある場合は、監視料金の合計が移行による節約額を上回ることがあるため、サイズ分布を事前に確認してください。
S3 One Zone-IA は単一 AZ 配置のため、AZ の物理的な喪失 (地震・洪水等の災害) が発生した場合、データが恒久的に失われる可能性があります。再生成可能なデータ (サムネイル、中間処理ファイルなど) 専用と考えてください。
IA クラスと Glacier クラスには最低保管期間があります (Standard-IA:30 日、Glacier Instant / Flexible:90 日、Glacier Deep Archive:180 日)。期間未満で削除・移行しても、最低期間分の料金が発生します。短命なデータには最低保管期間のない S3 Standard が最適です。
S3 Glacier Flexible Retrieval の取り出しオプションは 3 種類あります。緊急性に応じて選択してください。
- Expedited:1 ~ 5 分 (高額)
- Standard:3 ~ 5 時間 (標準料金)
- Bulk:5 ~ 12 時間 (無料)
詳しくは、公式ドキュメントの「Amazon S3 ストレージクラスの理解と管理」をご覧ください。

セキュリティとアクセス管理
S3 はデフォルトで外部アクセスを遮断しています。具体的には、Block Public Access、IAM ポリシー、バケットポリシー、ACL、アクセスポイント、暗号化という多層のセキュリティレイヤーで保護されています。ACL (アクセス制御リスト) はオブジェクトやバケット単位で読み取り・書き込み権限を設定する仕組みで、従来はアクセス制御の主要な手段として使われていました。現在は新規バケットでデフォルト無効になっており、より柔軟なバケットポリシーの使用が推奨されています。
Block Public Access は、バケットポリシーや ACL の設定に関わらず、S3 への公開アクセスを一括でブロックする機能です。アカウントレベルとバケットレベルの両方で設定でき、意図しない公開を防ぐ最後の砦として機能します。ただし、これだけに依存するのではなく、IAM ポリシーで事前に適切な権限を設計しておくことが大切です。

IAM ポリシーと暗号化
IAM ポリシーとバケットポリシーの使い分け
IAM ポリシーは「誰が」アクセスできるかをユーザーやロール側で制御するアイデンティティベースのポリシーです。バケットポリシーは「このバケットに誰がアクセスできるか」をリソース側で制御するリソースベースのポリシーです。クロスアカウントアクセスにはバケットポリシーが必要です。
暗号化の選択基準
SSE-S3(S3 が管理するキーで暗号化)はデフォルトで有効で、追加料金はかかりません。SSE-KMS (AWS Key Management Service のキーで暗号化) は、キーの使用履歴を監査ログで追跡したい場合に選択します。SSE-C (お客様が用意したキーで暗号化) は、キーを完全に自社管理したい場合に使用します。
IAM Access Analyzer for S3 を活用すると、意図せず外部からアクセス可能になっているバケットを自動検出できます。
コンプライアンス要件でデータの改ざん防止が求められる場合は、S3 Object Lock (WORM: Write Once Read Many) を検討してください。指定期間中はオブジェクトの削除・上書きを防止できます。
⚠ よくある設定ミス:バケットポリシーで "Principal": "*" と "Action": "s3:*" を組み合わせると、意図しない全公開につながります。
詳しくは、公式ドキュメントの「Amazon S3 のセキュリティのベストプラクティス」をご覧ください。
バージョニングとレプリケーション
バージョニングはオブジェクトの全変更履歴を保存し、誤削除や上書きから保護します。オブジェクトを削除すると、実際にはデータは消えず「削除マーカー」という目印が付与されます。この削除マーカーを取り除くことで、オブジェクトを復元できます。
レプリケーションはバケット間でオブジェクトを自動コピーする機能です。CRR (クロスリージョンレプリケーション) は災害対策、SRR (同一リージョンレプリケーション) はログ集約やコンプライアンス対応に活用されます。
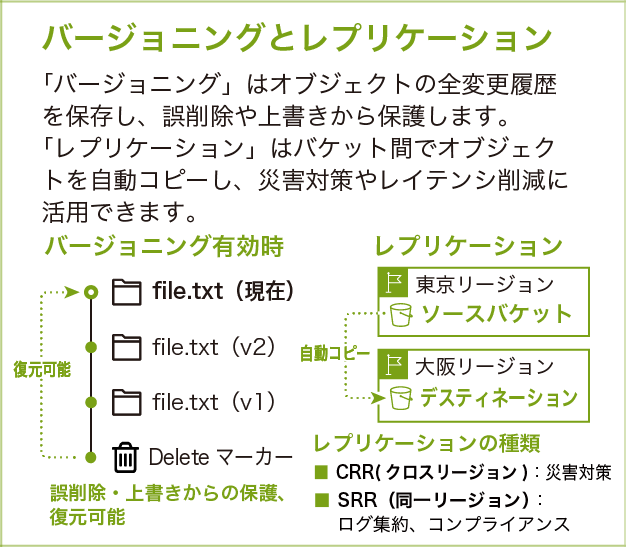
各機能について
バージョニング
バージョニングは一度有効にすると無効化できず、「停止」のみ可能です。停止後も既存の非現行バージョンは残り続けます。全バージョンが保存されるためストレージコストが増加するので、ライフサイクルポリシーで「非現行バージョンは 90 日後に削除」などのルールを組み合わせることを推奨します。
削除マーカーはレプリケーション設定でオプションとして複製できます。デフォルトでは複製されないため、ソースバケットで削除してもデスティネーションバケットにはオブジェクトが残ります。意図しないデータ損失を防ぐため、設定を明示的に確認してください。
詳しくは、「S3 バージョニングによる複数のバージョンのオブジェクトの保持」を参照してください。
レプリケーション
ソース・デスティネーション両方のバケットでバージョニングを有効化し、適切な IAM ロールを設定する必要があります。既存オブジェクトはデフォルトではレプリケートされません。レプリケーション設定前に保存済みのオブジェクトをコピーしたい場合は、バッチレプリケーション を使って一括でコピーできます。
レプリケーションは非同期で、通常数分以内に完了します。15 分以内の SLA が必要な場合は S3 Replication Time Control (RTC) を利用してください(99.9 % のオブジェクトが 15 分以内にレプリケートされます。追加料金あり)。
詳しくは、公式ドキュメントの「リージョン内およびリージョン間でのオブジェクトのレプリケート」をご覧ください。
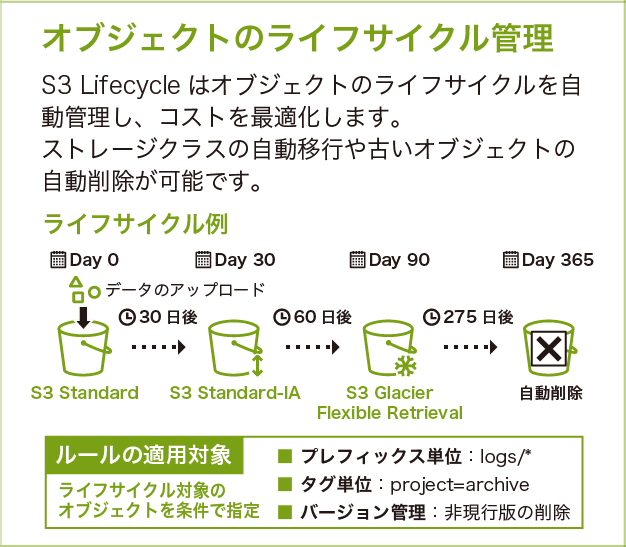
オブジェクトのライフサイクル管理
S3 Lifecycle はオブジェクトのライフサイクルを自動管理し、コストを最適化します。例えば、Day 0 に S3 Standard で保存されたオブジェクトが、30 日後に Standard-IA、60 日後に S3 Glacier Flexible Retrieval、275 日後に自動削除されるといったルールを設定できます。
ルールはプレフィックス単位・タグ単位・バージョン管理単位で適用対象を指定できます。
ライフサイクルポリシーは一度設定すれば自動で運用されるのが最大のメリットです。ただし、移行には最低日数の制約があります。S3 Standard → Standard-IA / One Zone-IA は最低 30 日後からしか設定できません。Glacier 系への移行は 0 日から設定可能ですが、最低保管期間(Glacier Instant / Flexible:90 日、Deep Archive:180 日)未満で削除・移行すると早期削除料金が発生します。
最低保管期間未満での削除・移行は早期削除料金が発生します。例えば Standard-IA に移行して 15 日後に削除すると、残り 15 日分の料金が請求されます。
バージョニングと組み合わせる場合、現行バージョンと非現行バージョンに別々のルールを設定できます。非現行バージョンの削除ルールを忘れると、ストレージコストが想定の数倍に膨らむことがあります。
⚠ ライフサイクルポリシーの反映には遅延が生じることがあります(実務上、最大 48 時間程度とされています)。
詳しくは、公式ドキュメントの「ストレージのライフサイクルの管理」をご覧ください。
高パフォーマンスと AI 対応
S3 はパフォーマンスと AI 対応の両面で進化を続けており、高速ストレージクラスの S3 Express One Zone と、新しいバケットタイプの S3 Vectors が登場しています。
S3 Express One Zone は 1 桁ミリ秒のアクセスレイテンシーを実現する高パフォーマンスなストレージクラスで、2023 年に GA (一般提供開始) となりました。S3 Standard と比較して、リクエストコストは最大 85 % 削減 (GET)、PUT は最大 55 % 削減、ストレージ料金は約 31 % 削減されます。単一 AZ 配置のため、AZ の物理的な喪失時にはデータが失われる可能性があるトレードオフがあります。
機械学習の学習データ読み込み、Apache Spark の中間ファイル、リアルタイム分析の一時データなど、速度優先・再生成可能なユースケースに適しています。
詳しくは、公式ドキュメントの「Amazon S3 Express One Zone ストレージクラス」をご覧ください。
S3 Vectors はベクターデータの保存と検索に特化した新しいバケットタイプ (ベクターバケット) で、2025 年 12 月に GA となりました。従来は専用のベクターデータベースを別途構築・運用する必要がありましたが、S3 Vectors を使うことで S3 上で直接ベクター検索が実行できます。RAG アーキテクチャで大規模なベクターデータを低コストで管理したい場合に特に有効です。
詳しくは、公式ドキュメントの「Amazon S3 Vectors」をご覧ください。

アーキテクチャ例
S3 はさまざまなアーキテクチャの中核を担います。静的ウェブサイト配信、データレイク、イベント駆動処理など多彩なユースケースに対応しています。
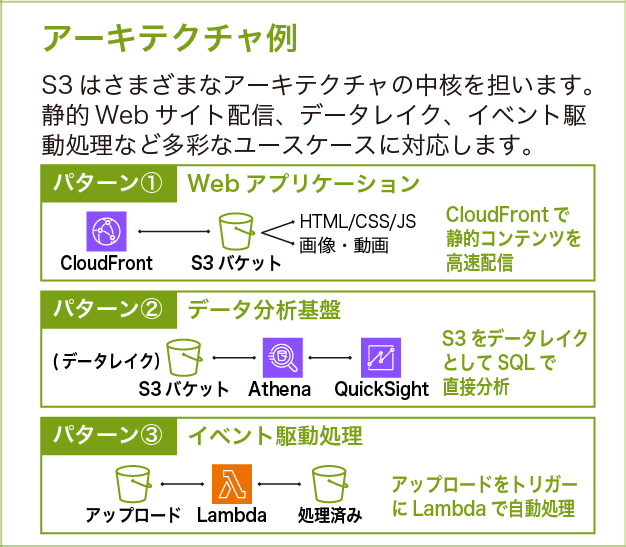
各パターンの紹介
パターン①:Amazon CloudFront + S3 でウェブ配信
S3 に HTML や CSS、画像などの静的ファイルを置き、Amazon CloudFront (CDN) を前段に配置することで、世界中のユーザーに低レイテンシーで配信できます。S3 の静的ウェブサイトホスティング機能は HTTPS に対応していないため、本番環境では Amazon CloudFront の併用が一般的です。コンテンツを更新した際は、style.v2.css のようにバージョン付きファイル名を使うと、キャッシュの影響を受けずに最新版を配信できます。
パターン②:S3 をデータレイクとして SQL で直接分析
S3 に蓄積したデータを、サーバーを立てずに Amazon Athena から SQL で直接分析できます。Amazon Athena はスキャンしたデータ量 (GB 単位) で課金されるため、Parquet (列指向のファイル形式) + 日付パーティショニング (データを日付ごとのフォルダに分割して格納すること) を組み合わせると、スキャン量を大幅に削減できます。AWS Glue Data Catalog と連携するとスキーマ管理も自動化できます。
パターン③:アップロードをトリガーに Lambda で自動処理
S3 にファイルがアップロードされたことをきっかけに、画像のリサイズやデータの変換といった処理を自動で実行できます。S3 イベント通知は Amazon SNS・Amazon SQS・AWS Lambda に送信できます。同一イベント+同一プレフィックスへの複数送信先設定はできないため、複数の処理が必要な場合は Amazon EventBridge を経由してください。
詳しくは、公式ドキュメントの「Amazon S3 の開始方法」をご覧ください。
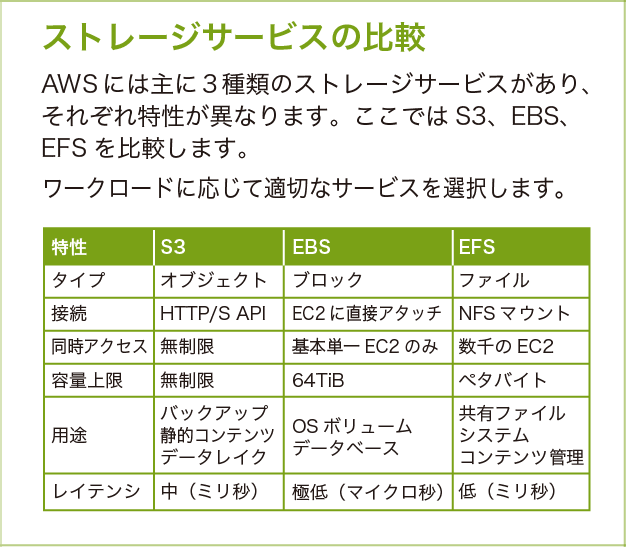
ストレージサービスの比較
AWS には 3 種類の主要ストレージサービスがあり、それぞれ異なる特性を持っています。
|
サービス
|
種類
|
アクセス方式
|
レイテンシー
|
|---|---|---|---|
|
Amazon S3
|
オブジェクト型 |
HTTP/S API |
中 (ミリ秒) |
|
Amazon EBS
|
ブロック型 |
Amazon EC2 に直接アタッチ |
極低 (マイクロ秒) |
|
Amazon EFS
|
ファイル型
|
NFS マウント |
低 (ミリ秒) |
サービス間の移行はコストがかかるため、設計段階での選定が重要です。
Amazon EBS は「Amazon EC2 に直接アタッチ」が前提のため、AWS Lambda からは直接使えません。Amazon ECS タスク (Fargate および EC2 起動タイプ) には EBS ボリュームを直接アタッチ できます。複数 Amazon EC2 からの汎用的な共有アクセスには Amazon EFS が必要です。
S3 のレイテンシー「中 (ミリ秒)」は具体的には通常数十 ms 程度です。Amazon EBS の「極低 (マイクロ秒)」とは 2 ~ 3 桁の差があるため、データベースのストレージとして S3 は使えません。
用途別の選択基準
- ログ保存・静的コンテンツ → Amazon S3
- データベース → Amazon EBS
- 共有ファイルサーバー → Amazon EFS
詳しくは、公式ドキュメントの「AWS ストレージサービスの選択」をご覧ください。
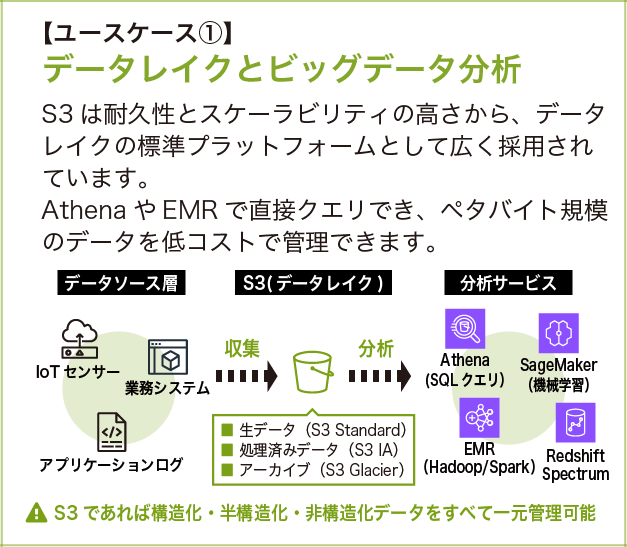
ユースケース①:データレイクとビッグデータ分析
S3 は高い耐久性とスケーラビリティからデータレイクの標準プラットフォームとして採用されています。IoT センサーやアプリケーションログなどのデータを収集し、S3 上で生データ (S3 Standard)、加工済みデータ (S3 Standard-IA)、アーカイブ (S3 Glacier) の 3 層に整理して管理します。
Amazon Athena (SQL クエリ)、Amazon SageMaker (機械学習)、Amazon EMR (Hadoop/Spark)、Amazon Redshift Spectrum などの分析サービスが直接 S3 を参照できます。
S3 をデータレイクの中心に置く最大のメリットは「ストレージとコンピュートの分離」です。データを 1 箇所に集約しておけば、複数の分析ツールから同じデータを参照できます。
Raw Data を Parquet 形式に変換するだけで、Amazon Athena のクエリコストと速度が劇的に改善します。列指向フォーマットにより、必要な列だけを読み込むため、スキャン量が大幅に削減されます。
パーティショニング設計も効果的です。例えば s3://bucket/logs/year=2026/month=01/day=15/ のように日付でフォルダを分けておくと、Amazon Athena は指定期間のフォルダだけをスキャンするため、コストと速度が大幅に改善します。
また、処理失敗時の再実行が容易なのも S3 データレイクの強みです。生データが S3 に残っているため、処理ロジックを修正して再実行できます。
詳しくは、公式ドキュメントの「AWS での分析」をご覧ください。
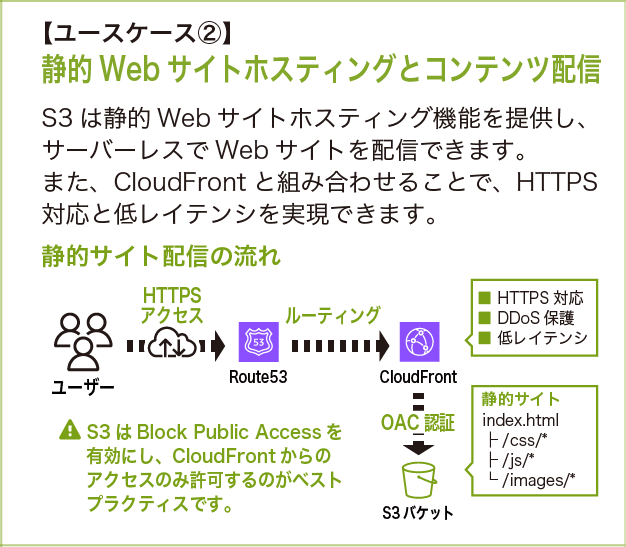
ユースケース②:静的ウェブサイトホスティングとコンテンツ配信
S3 は静的ウェブサイトのホスティング機能を提供しており、Amazon CloudFront と組み合わせることで HTTPS 対応と低レイテンシーのコンテンツ配信が実現できます。
ユーザーのアクセスは Amazon Route 53 (DNS サービス) でルーティングされ、Amazon CloudFront を経由して S3 バケットにアクセスします。この際、OAC (Origin Access Control) という仕組みにより、S3 バケットを非公開のまま Amazon CloudFront 経由でのみ配信できます。S3 バケットには index.html、CSS、JS、画像ファイルなどの静的コンテンツが格納されます。
S3 の静的ウェブサイトホスティング機能は HTTPS に対応していないため、本番環境では Amazon CloudFront を前段に配置するのが一般的です (詳細は前述のアーキテクチャ例パターン①を参照)。
OAC (Origin Access Control) は、Amazon CloudFront から S3 へのアクセスを安全に制御する仕組みです。旧方式の OAI (Origin Access Identity) では SSE-KMS 暗号化や POST リクエストに対応できないなどの制約がありましたが、OAC ではこれらが解消されています。新規構築では OAC を使ってください。
SPA (Single Page Application) と呼ばれる React や Vue.js などのフレームワークで構築されたサイトをホスティングする場合、ページ遷移時に 404 エラーが発生することがあります。これは SPA がブラウザ側でルーティングを処理する仕組みのためです。Amazon CloudFront のエラーページ設定で 404 → index.html にリダイレクトすることで解決できます。
詳しくは、公式ドキュメントの「Amazon S3 を使用して静的ウェブサイトをホスティングする」をご覧ください。
制限事項・注意点
S3 にはバケット・オブジェクト・パフォーマンスの 3 カテゴリーで制限があります。
|
カテゴリー
|
制限
|
|---|---|
|
バケット
|
アカウントあたり最大 10,000 個 (増加申請可能)、名前は変更不可 |
|
オブジェクト
|
最大 50 TB、PUT 単体アップロードは 5 GB まで (それ以上はマルチパートアップロード必須) |
|
パフォーマンス
|
プレフィックスあたり 3,500 PUT/s・5,500 GET/s |
制限事項・注意点の解説
前述のとおり S3 はフラット構造のため、プレフィックスを指定せずに ListObjects API を実行すると全オブジェクトをスキャンします。大量オブジェクトがある場合はパフォーマンスに影響するため、プレフィックス設計が重要です。
パフォーマンス制限の「3,500 PUT/s・5,500 GET/s」はプレフィックスあたりの値です。プレフィックスを分散させれば実質無制限にスケールします。
バケット削除後、同一アカウント・同一リージョンであればすぐに同名バケットを再作成できます。異なるリージョンや異なるアカウントからの再利用には最大 1 時間程度のディレイが生じる場合があります。
マルチパートアップロードは、大きなファイルを複数のパートに分割して並列にアップロードする仕組みです。5 GB 以上のファイルでは必須ですが、100 MB 以上から利用が推奨されています。実際には 5 MB からパート分割が可能で、ネットワーク障害時にパート単位で再送できるため、大容量ファイルの転送安定性が向上します。
詳しくは、公式ドキュメントの「汎用バケットのクォータ、制限、制約」をご覧ください。

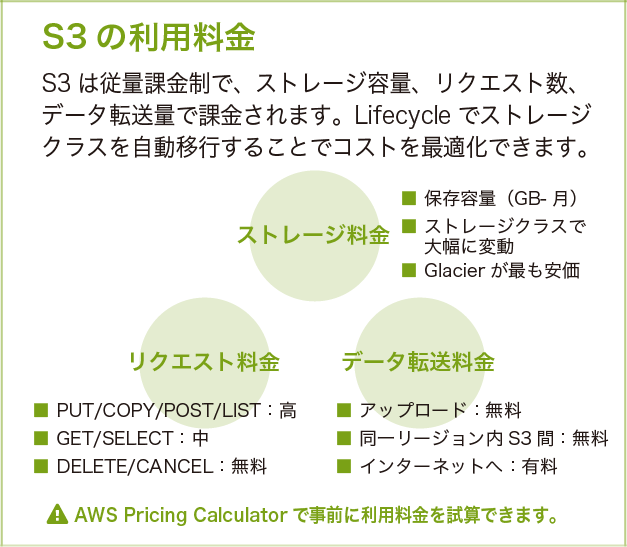
S3 の利用料金
S3 は従量課金制で、ストレージ容量・リクエスト数・データ転送量で課金されます。ストレージ料金はストレージクラスで大幅に変動し、S3 Glacier Deep Archive が最も安価です。リクエスト料金は PUT/COPY/POST/LIST が高く、GET/SELECT が中程度、DELETE/CANCEL は無料です。データ転送はアップロードが無料、ダウンロードは有料です。
ライフサイクルでストレージクラスを自動移行することでコストを最適化できます。
料金で見落とされがちなのがリクエスト料金です。大量の小さなファイルを頻繁に読み書きすると、ストレージ料金より高くなることがあります。Amazon CloudFront のキャッシュを活用して S3 へのリクエスト数を削減するのが有効な対策です。
IA クラスには「取得料金」も発生します (GB 単位)。頻繁にアクセスするデータを IA クラスに置くと、S3 Standard より高くなる場合があります。同様に、バージョニング有効時は全バージョン分のストレージ料金がかかるため、不要なバージョンの蓄積にも注意が必要です。
S3 → 同一リージョン内の Amazon EC2/AWS Lambda 間のデータ転送は無料です。S3 → Amazon CloudFront (オリジンフェッチ) はリージョンに関わらず無料です。ただし S3 からのクロスリージョン転送 (CloudFront 経由を除く) は有料です。
詳しくは、公式ドキュメントの「Amazon S3 料金表」をご覧ください。
参考資料
S3 についてさらに学ぶための公式リソースです。QR コードから各リソースにアクセスできます。
各リソースの使い分け:
- 公式ドキュメント : API リファレンスや設定値の正確な確認
- ベストプラクティス : セキュリティ・コスト最適化の設計指針
- AWS Black Belt : 体系的な学習や機能の深掘り
- AWS ブログ : 新機能の GA 情報や料金変更の最新情報
- 事例紹介 : NTT データグループが SAP S/4HANA 移行で Amazon S3 データレイクの中核に採用
なお、英語版の公式ドキュメントは日本語版より更新が早い場合があります。最新の仕様確認には英語版も参照することをおすすめします。
⚠ 本記事の内容は作成時点の情報です。料金や仕様は変更される場合があるため、最新情報は公式ドキュメントをご確認ください。
まとめ
最後に、本記事で解説した S3 の主要な機能とポイントを一枚にまとめた図をご覧ください。ぜひ保存してご活用ください。 S3 の本質は「シンプルで信頼性の高いオブジェクトストレージ」です。99.999999999% の耐久性と事実上無制限のスケーラビリティを基盤に、多彩なストレージクラスによるコスト最適化、多層のセキュリティ、バージョニング・レプリケーション・ライフサイクル管理による運用自動化が組み合わさっています。
設計時に押さえておきたいポイント
- ストレージクラスはアクセスパターンで選択 : アクセスパターンが不明な場合は S3 Intelligent-Tiering を選択することで、アクセス頻度に応じたストレージ層への移動が自動的に行われます。アーカイブには S3 Glacier Deep Archive が最安ですが、最低保管期間の制約がある点に留意してください。
- セキュリティは最小権限の原則で設計 : S3 はデフォルトで非公開ですが、Block Public Access、IAM ポリシー、バケットポリシーを適切に組み合わせることで、意図しないアクセスを防止できます。
- バージョニングとライフサイクルはセットで検討 : バージョニングを有効にしたら、非現行バージョンの自動削除ルールの設定を推奨します。
- コストの見落としに注意 : リクエスト料金・取得料金・早期削除料金は見落とされがちです。AWS Pricing Calculator (AWS の料金見積もりツール) で事前に試算することを推奨します。
本記事で紹介した内容
本記事では、S3 の基本概念 (バケットとオブジェクト) から、ストレージクラスの選択、セキュリティ設計、バージョニング・レプリケーション・ライフサイクルによる運用自動化、パフォーマンスと AI 対応の最新機能、アーキテクチャパターン、他のストレージサービスとの比較、制限事項、料金体系までを解説しました。
S3 は「使い始めるのは簡単、使いこなすには深い理解が必要」なサービスです。本記事が、S3 を正しく・効率的に活用するための第一歩となれば幸いです。
筆者プロフィール
米倉 裕基
アマゾン ウェブ サービス ジャパン合同会社
テクニカルライター・イラストレーター
日英テクニカルライター・イラストレーター・ドキュメントエンジニアとして、各種エンジニア向け技術文書の制作を行ってきました。趣味は娘に隠れてホラーゲームをプレイすることと、暗号通貨自動取引ボットの開発です。現在、AWS や機械学習、ブロックチェーン関連の資格取得に向け勉強中です。

監修者プロフィール
伊勢田 氷琴
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
普段は業種業界問わず幅広いお客様の技術支援に携わっています。最近は Strands Agents や Amazon Bedrock AgentCore など AI エージェントの実装技術やビジネスとしての生成 AI 活用に関心を持ち、ブログや講演で積極的に情報発信を行なっています。
