Amazon Web Services 한국 블로그
Amazon MSK Connect – Apache Kafka 클러스터로 데이터 전달 서비스 출시
Apache Kafka는 실시간 스트리밍 데이터 파이프라인 및 애플리케이션 구축을 위한 오픈 소스 플랫폼입니다. re:Invent 2018에서 AWS는 스트리밍 데이터의 프로세싱을 위해 Apache Kafka를 사용하는 애플리케이션을 쉽게 구축 및 실행할 수 있게 해 주는 완전관리형 서비스인 Amazon Managed Streaming for Apache Kafka를 발표했습니다.
Apache Kafka를 사용하면 IoT 디바이스, 데이터베이스 변경 이벤트 및 웹 사이트 클릭스트림과 같은 소스로부터 실시간 데이터를 캡처하고 이를 데이터베이스 및 영구 스토리지와 같은 대상에 전달할 수 있습니다.
Kafka Connect는 데이터베이스 키 값 스토어, 검색 인덱스 및 파일 시스템과 같은 외부 시스템에 연결하기 위한 프레임워크를 제공하는, Apache Kafka의 오픈 소스 구성 요소입니다. 그러나 Kafka Connect 클러스터를 수동으로 실행하려면 필수 인프라를 계획 및 프로비저닝하고, 클러스터 작업을 처리하고, 부하 변화에 따라 크기를 조정해야 합니다.
오늘 AWS는 Kafka Connect 클러스터를 더 쉽게 관리할 수 있게 해 주는 새로운 기능을 발표합니다. Amazon MSK Connect를 사용하면 Kafka Connect를 사용하는 커넥터를 클릭 몇 번만으로 구성 및 배포할 수 있습니다. MSK Connect는 필수 리소스를 프로비저닝하고 클러스터를 설정합니다. MSK Connect는 커넥터의 전송 상태를 모니터링하고, 기반 하드웨어에 패치를 적용하고 관리하며, 처리량 변화에 맞도록 커넥터의 크기를 자동 조정합니다. 따라서 사용자는 인프라 관리에 신경을 쓰지 않고 애플리케이션 구축에 리소스를 집중할 수 있습니다.
MSK Connect는 Kafka Connect와 완벽하게 호환되므로 코드 변경 없이 기존 커넥터를 마이그레이션할 수 있습니다. MSK 클러스터가 없어도 MSK Connect를 사용할 수 있습니다. MSK Connect는 Amazon MSK, Apache Kafka 및 Apache Kafka 호환 클러스터를 소스 및 싱크로 지원합니다. MSK Connect를 프라이빗 방식으로 클러스터에 연결할 수만 있으면 이러한 클러스터는 자체 관리형이거나 AWS 파트너 및 서드 파티에 의해 관리될 수 있습니다.
Amazon Aurora 및 Debezium과 함께 MSK Connect 사용
테스트를 위해 MSK Connect를 사용하여 데이터베이스에서 데이터 변경 이벤트를 스트리밍해 보겠습니다. 이 작업을 위해, Apache Kafka 기반의 변경 데이터 캡처용 오픈 소스 분산 플랫폼인 Debezium을 사용하겠습니다.
MySQL 호환 Amazon Aurora 데이터베이스를 소스로 사용하고 Debezium MySQL 커넥터를 다음 아키텍처 다이어그램에 설명된 설정과 함께 사용합니다.
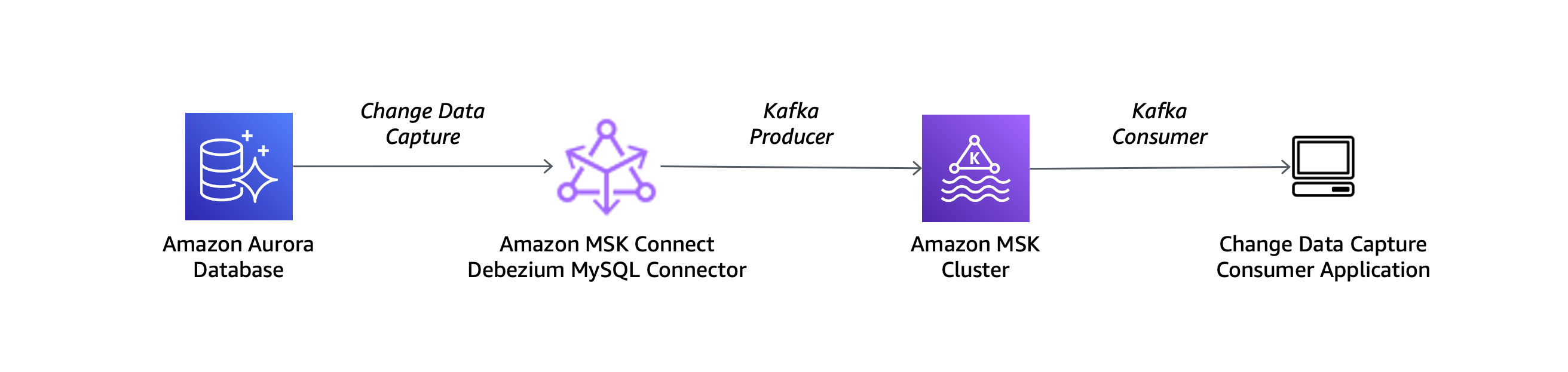
Aurora 데이터베이스를 Debezium과 함께 사용하려면 DB 클러스터 파라미터 그룹에서 바이너리 로깅 기능을 켜야 합니다. Amazon Aurora MySQL 클러스터에 대한 바이너리 로깅을 활성화하려면 어떻게 해야 하나요? 문서의 단계를 따르겠습니다.
그런 다음, MSK Connect를 위한 사용자 지정 플러그인을 생성해야 합니다. 사용자 정의 플러그인은 하나 이상의 커넥터, 전환 또는 변환기의 구현이 포함된 일련의 JAR 파일입니다. Amazon MSK는 커넥터가 실행 중인 연결 클러스터의 작업자에 플러그인을 설치합니다.
Debezium 웹 사이트에서 최신 안정 릴리스를 위한 MySQL 커넥터 플러그인을 다운로드합니다. MSK Connect는 ZIP 또는 JAR 형식의 사용자 정의 플러그인을 수락하므로 다운로드한 아키이브를 ZIP 형식으로 변환하고 JAR 파일을 기본 디렉터리에 유지합니다.
그런 다음 AWS Command Line Interface(CLI)를 사용하여 사용자 정의 플러그인을 MSK Connect에 사용하는 것과 동일한 AWS 리전의 Amazon Simple Storage Service(Amazon S3) 버킷으로 업로드합니다.
Amazon MSK 콘솔에는 새로운 MSK Connect 섹션이 있습니다. 커넥터를 확인하고 커넥터 생성(Create connector)을 선택합니다. 그런 다음 사용자 정의 플러그인을 생성하고 S3 버킷으로 이동하여 이전에 업로드한 사용자 정의 플러그인 ZIP 파일을 선택합니다.

플러그인의 이름과 설명을 입력한 후 다음(Next)을 선택합니다.

이제 사용자 정의 플러그인의 구성이 완료되었으므로 커넥터 생성을 시작합니다. 커넥터의 이름과 설명을 입력합니다.

자체 관리형 Apache Kafka 클러스터를 사용하거나 MSK에서 관리하는 클러스터를 사용할 수 있습니다. IAM 인증을 사용하도록 구성된 MSK 클러스터 중 하나를 선택합니다. 선택한 MSK 클러스터는 Aurora 데이터베이스와 동일한 Virtual Private Cloud(VPC)에 있습니다. 연결을 위하 MSK 클러스터와 Aurora 데이터베이스는 VPC를 위한 기본(default) 보안 그룹을 사용합니다. 간결함을 위해 auto.create.topics.enable이 true로 설정된 클러스터 구성을 사용하겠습니다.
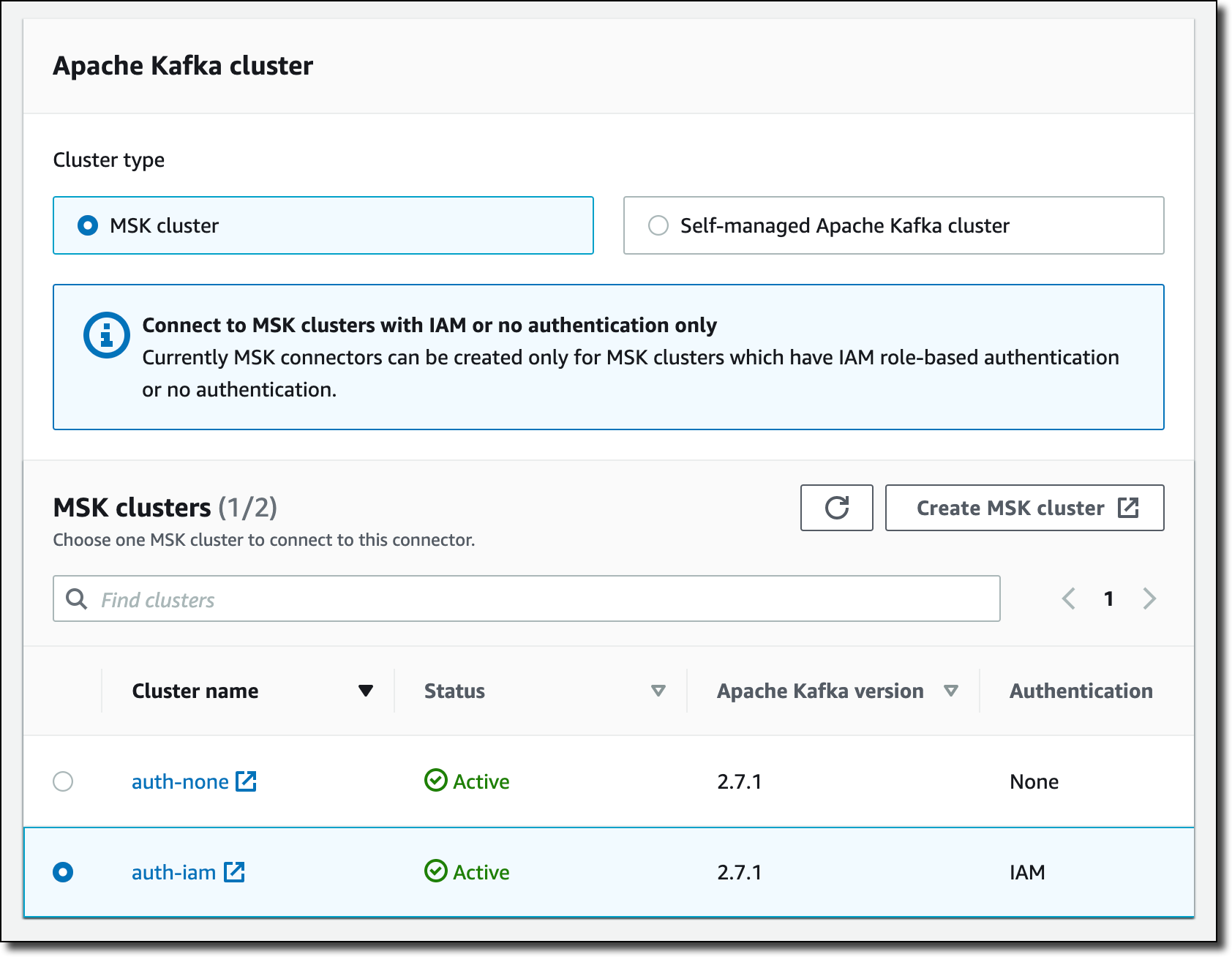
커넥터 구성(Connector configuration)에서 다음과 같은 설정을 사용합니다.
이러한 설정 중 일부는 일반적인 설정으로서, 모든 커넥터에 대해 지정해야 합니다. 예를 들면 다음과 같습니다.
connector.class는 커넥터의 Java 클래스입니다.tasks.max는 이 커넥터에 대해 생성되어야 할 태스크의 최대 수입니다.
다른 설정은 Debezium MySQL 커넥터에만 해당됩니다.
database.hostname은 Aurora 데이터베이스의 작성자 인스턴스 엔드포인트를 포함합니다.database.server.name은 데이터베이스 서비의 논리적 이름입니다. 이 설정은 이름은 Debezium에서 생성한 Kafka 주제의 이름에 사용됩니다.database.include.list는 지정한 서버에서 호스팅하는 데이터베이스의 목록을 포함합니다.database.history.kafka.topic은 데이터베이스 스키마 변경을 추적하기 위해 Debezium에서 내부적으로 사용하는 Kafka 주제입니다.database.history.kafka.bootstrap.servers는 MSK 클러스터의 부트스트랩 서버를 포함합니다.- 마지막의 8개 줄(
database.history.consumer.*및database.history.producer.*)은 데이터베이스 기록 주제를 액세스하기 위한 IAM 인증을 활성화합니다.
커넥터 용량(Connector capacity)에서 자동 조정 용량 또는 프로비저닝된 용량 중에서 선택할 수 있습니다. 이 설정에서는 자동 조정(Autoscaled)을 선택하고 다른 모든 설정은 기본값으로 유지합니다.

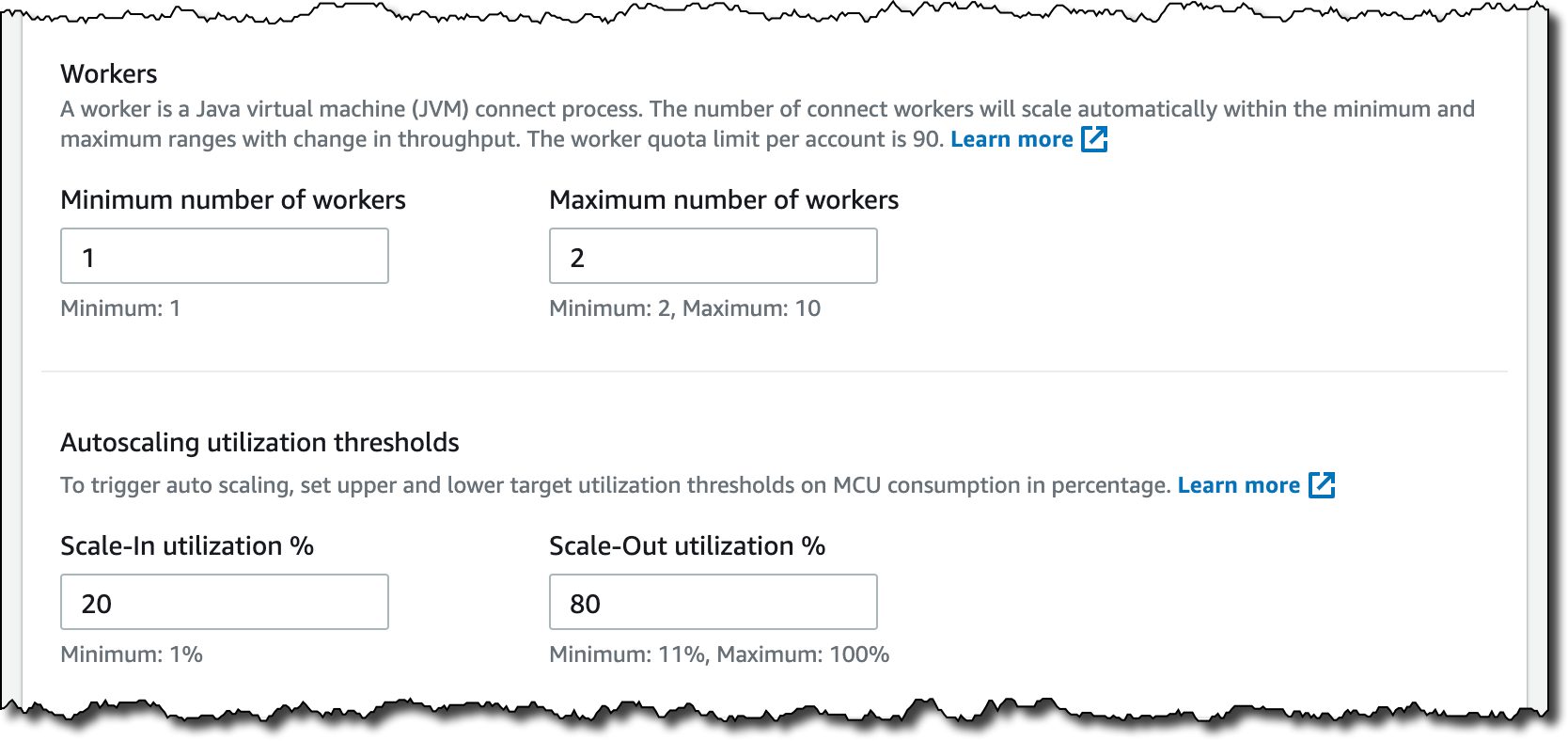
자동 조정 용량에서는 다음과 같은 파라미터를 구성할 수 있습니다.
- 작업자당 MCU(MSK Connect Unit) 개수(MSK Connect Unit (MCU) count per worker) – 각 MCU는 1개의 vCPU로 구성된 컴퓨팅과 4GB의 메모리를 제공합니다.
- 최소 및 최대 작업자 수(number of workers).
- 자동 크기 조정 사용 임계값(Autoscaling utilization thresholds) – 자동 크기 조정을 트리거하는 MCU 소비 상위 및 하위 목표 사용률 임계값(%)입니다.
커넥터에 대한 최소 및 최대 MCU, 메모리 및 네트워크 대역폭의 요약이 있습니다.

작업자 구성(Worker configuration)에는 Amazon MSK에서 제공하는 기본값을 사용하거나 자체 구성을 제공할 수 있습니다. 이 설정에서는 기본값을 사용하겠습니다.
액세스 권한(Access permissions)에서 IAM 역할을 생성합니다. MSK Connect가 역할을 수임할 수 있도록 신뢰할 수 있는 엔터티에 kafkaconnect.amazonaws.com을 추가합니다.
이 역할은 MSK Connect에서 MSK 클러스터 및 기타 AWS 서비스와 상호 작용하는 데 사용합니다. 이 설정에서는 다음과 같은 권한을 추가합니다.
- 앞서 생성한 Amazon CloudWatch 로그 그룹에 대한 로그 쓰기 권한
- IAM를 통해 MSK 클러스터를 인증할 수 있는 권한
Debezium 커넥터에는 기록 주제를 생성하는 데 사용할 복제 요소를 찾기 위해 클러스터 구성에 대한 액세스가 필요합니다. 그렇기 때문에 권한 정책에 kafka-cluster:DescribeClusterDynamicConfiguration 작업(Apache Kafka의 DESCRIBE_CONFIGS 클러스터 ACL과 동등)을 추가하겠습니다.
구성에 따라 더 많은 권한을 역할에 추가해야 할 수 있습니다(예를 들어 커넥터가 S3 버킷 등의 다른 AWS 리소스에 대한 액세스가 필요한 경우). 이러한 경우, 커넥터를 생성하기 전에 권한을 추가해야 합니다.
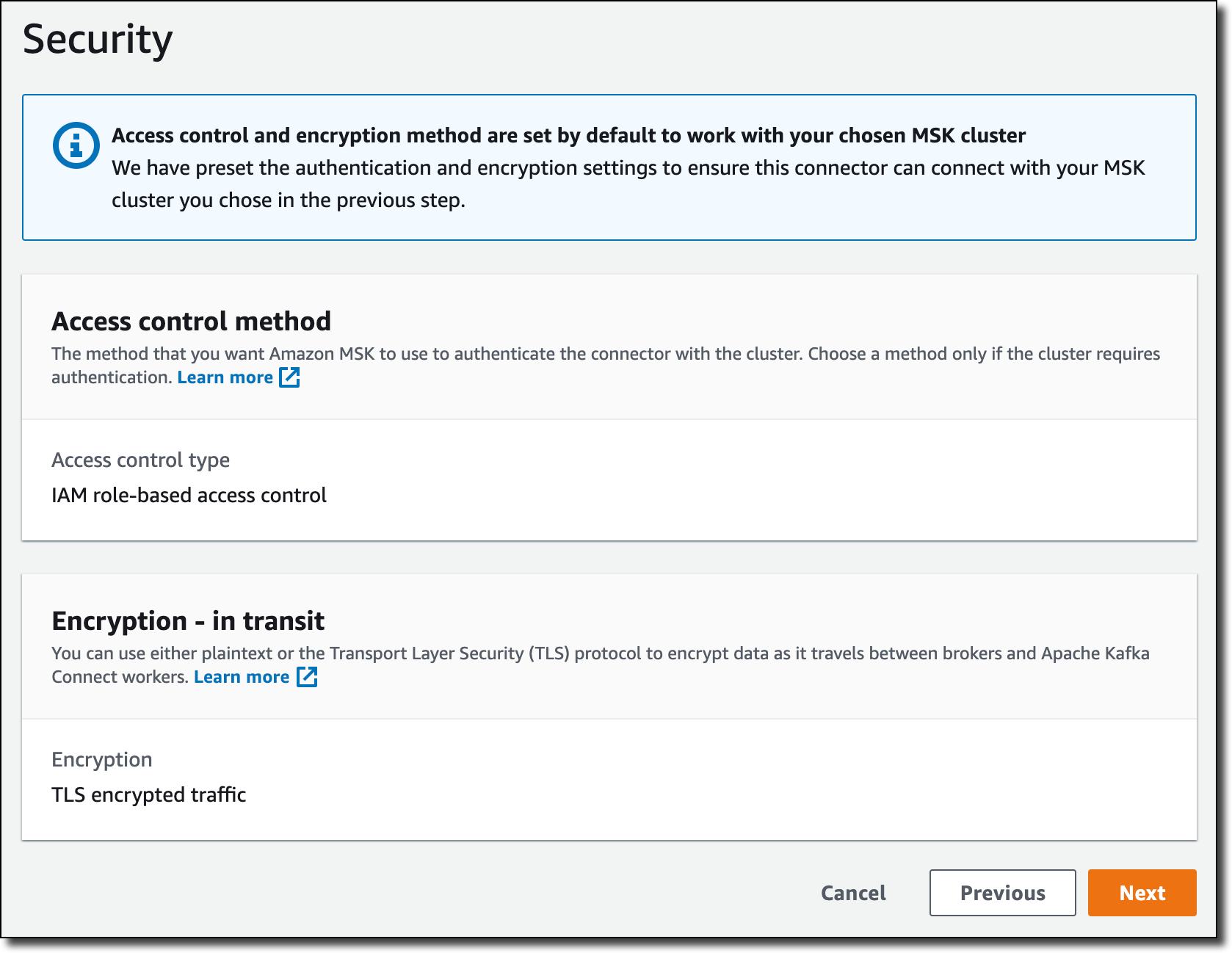
보안(Security)에서 인증 밍 전송 중 암호화에 대한 설정은 MSK 클러스터에서 가져옵니다.
로그(Logs)에서는 커넥터 실행에 대해 더 많은 정보를 얻을 수 있도록 로그를 CloudWatch Logs로 전송하도록 선택합니다. CloudWatch Logs를 사용하면 쉽게 보존을 관리하고 대화형 검색을 수행하며 CloudWatch Logs Insights를 통해 로그 데이터를 분석할 수 있습니다. 로그 그룹 ARN(이전에 IAM 역할에서 사용한 것과 동일한 로그 그룹)을 입력한 후 다음(Next)을 선택합니다.

설정을 검토한 다음 커넥터 생성(Create connector)을 선택합니다. 몇 분 후에 커넥터가 실행됩니다.
Amazon Aurora 및 Debezium과의 MSK Connect 작동 테스트
이제 방금 설정한 아키텍처를 테스트해 보겠습니다. 데이터베이스를 업데이트하고 몇 개의 Kafka 소비자를 시작하여 Debezium의 작동을 확인하기 위해 Amazon EC2(Amazon Elastic Compute Cloud) 인스턴스를 시작하겠습니다. MSK 클러스터와 Aurora 데이터베이스 모두에 연결하기 위해 동일한 VPC를 사용하고 기본(default) 보안 그룹을 할당합니다. 또한 인스턴스에 대한 SSH 액세스 권한을 제공하는 또 다른 보안 그룹을 추가합니다.
Apache Kafka에 대한 바이너리 배포를 다운로드하고 아카이브를 홈 디렉터리에 추출합니다.
IAM을 사용하여 MSK 클러스터를 인증하려면 Amazon MSK 개발자 가이드의 IAM 액세스 제어를 위한 클라이언트 구성 지침을 따릅니다. Amazon MSK Library for IAM의 최신 안정 릴리스를 다운로드합니다.
~/kafka_2.13-2.7.1/config/ 디렉터리에 client-config.properties 파일을 생성하여 Kafka 클라이언트가 IAM 인증을 사용하도록 구성합니다.
다음과 같은 작업을 위해 Bash 프로필에 몇 개의 줄을 추가합니다.
- Kafka 바이너리를
PATH에 추가합니다. - IAM용 MSK 라이브러리를
CLASSPATH에 추가합니다. - MSK 클러스터의 부트스트랩 서버를 저장할
BOOTSTRAP_SERVERS환경 변수를 생성합니다.
$ cat >> ~./bash_profile
export PATH=~/kafka_2.13-2.7.1/bin:$PATH
export CLASSPATH=/home/ec2-user/aws-msk-iam-auth-1.1.0-all.jar
export BOOTSTRAP_SERVERS=<bootstrap servers>그런 다음 인스턴스에 대한 터미널 연결을 세 개 엽니다.
첫 번째 터미널 연결에서 데이터베이스 서버(ecommerce-server)와 동일한 이름의 주제에 대한 Kafka 소비자를 시작합니다. 이 주제는 Debezium에서 스키마 변경 사항을 스트리밍하는 데 사용됩니다(예를 들어 새 테이블이 생성된 경우).
두 번째 터미널 연결에서 데이터베이스 서버(ecommerce-server), 데이터베이스(ecommerce) 및 테이블(orders)을 연결하여 만든 이름을 가진 주제에 대한 또 하나의 Kafta 소비자를 시작합니다. 이 주제는 Debezium에서 테이블에 대한 데이터 변경 사항을 스트리밍하는 데 사용됩니다(예를 들어 새 레코드가 삽입된 경우).
세 번째 터미널 연결에서 MariaDB 패키지를 사용하여 MySQL 클라이언트를 설치하고 Aurora 데이터베이스에 연결합니다.
이 연결에서 ecommerce 데이터베이스와 orders에 대한 테이블을 생성합니다.
이러한 데이터베이스 변경은 MSK Connect에서 관리하는 Debezium 커넥터에 의해 캡처됩어 MSK 클러스터로 스트리밍됩니다. 스키마 변경이 있는 주제를 소비하는 첫 번째 터미널에서 데이터베이스 및 테이블 생성에 대한 정보를 봅니다.
그런 다음 세 번째 터미널의 데이터베이스 연결로 돌아가서 orders 테이블에 레코드 몇 개를 삽입합니다.
INSERT INTO orders VALUES ("123456", "123", "A super noisy mechanical keyboard", "50.00", "2021-08-16 10:11:12");
INSERT INTO orders VALUES ("123457", "123", "An extremely wide monitor", "500.00", "2021-08-16 11:12:13");
INSERT INTO orders VALUES ("123458", "123", "A too sensible microphone", "150.00", "2021-08-16 12:13:14");
두 번째 터미널에서 orders 테이블에 삽입된 레코드의 정보를 봅니다.
변경 데이터 캡처 아키텍처가 가동되어 실행되어 있으며 커넥터는 MSK Connect에 의해 완전 관리되고 있습니다.
가용성 및 요금
MSK Connect는 아시아 태평양(뭄바이), 아시아 태평양(서울), 아시아 태평양(싱가포르), 아시아 태평양(시드니), 아시아 태평양(도쿄), 캐나다(중부), EU(프랑크푸르트), EU(아일랜드), EU(런던), EU(파리), EU(스톡홀름), 남아메리카(상파울루), 미국 동부(버지니아 북부), 미국 동부(오하이오), 미국 서부(캘리포니아 북부), 미국 서부(오레곤)AWS 리전에서 사용할 수 있습니다. 자세한 내용은 AWS 리전 서비스 목록을 참조하세요.
MSK Connect에서는 사용한 만큼만 비용을 지불합니다. 커넥터가 사용하는 리소스는 워크로드에 따라 자동으로 확장될 수 있습니다. 자세한 내용은 Amazon MSK 요금 페이지를 참조하세요.
지금 MSK Connect를 통해 Apache Kafka 커넥터의 관리를 간소화하세요.
– Danilo