AWS 기술 블로그
Category: Management & Governance

Claude Code 비용/사용량을 한눈에: AWS에 Observability 플랫폼 구축하기
AI 코딩 어시스턴트의 도입이 가속화되면서, 조직은 새로운 질문에 직면하고 있습니다. “우리 팀이 AI 도구를 얼마나 효과적으로 사용하고 있는가?” 세션당 비용은 합리적인지, 어떤 모델이 비용 대비 높은 생산성을 제공하는지, 도구 실행의 성공률은 어떤지 — 이러한 질문에 답하려면 체계적인 관측성(Observability) 플랫폼이 필요합니다. Claude Code는 Anthropic이 제공하는 터미널 기반 AI 코딩 에이전트입니다. Amazon Bedrock을 통해 Claude Code를 사용하는 […]

오픈소스 Arize Phoenix 를 활용한 멀티 에이전트 AI시스템 쉽고 빠르게 모니터링하기
개요 최근 생성형 AI는 Agentic Workflow와 함께 유사 MSA 형태의 구성으로 동작되고 있습니다. 많은 시스템은 이미 여러 AI 에이전트가 사용자의 질문에 따라 유기적으로 협업하며 문제를 추리하고 생각하며 결과에 도달하고 있습니다. 이 과정속에 AI Agent는 서로 여러번 되묻고 필요한 경우 MCP(Model Context Protocol) Tool을 호출하거나 RAG(Retrieval-Augmented Generation)를 참조하기도 합니다. 이러한 에이전트는 사용자를 위한 작업을 자동화 하고 […]

빗썸의 AWS Service Endpoint 통합 아키텍처를 통한 비용 및 관리 효율 최적화
빗썸(Bithumb)은 대한민국을 대표하는 가상자산 거래소 중 하나로, 안정적이고 확장 가능한 서비스를 제공하기 위해 AWS(Amazon Web Services)의 다양한 인프라 서비스를 적극 활용하고 있습니다. 글로벌 수준의 보안성과 고가용성을 확보하기 위해 다양한 클라우드 기반 아키텍처를 채택하고 있으며, 이러한 기술적 기반 위에 수많은 사용자에게 빠르고 안정적인 거래 환경을 제공합니다. 빗썸은 단순한 암호화폐 거래소를 넘어 디지털 자산의 미래 가치를 선도하는 […]

Amazon DataZone에서 Custom Asset Type을 활용하여 외부 자산(Tableau) 통합 및 데이터 계보 관리하기
배경 데이터 중심 조직은 AWS 내 서비스와 Tableau, MicroStrategy 같은 외부 BI 도구를 함께 활용하는 하이브리드 환경에서 운영되는 경우가 많습니다. 이러한 환경에서 조직들은 다음과 같은 니즈를 가지고 있습니다. 통합 데이터 자산 카탈로그 : Tableau 대시보드와 같은 외부 자산도 함께 등록하여 모든 데이터 자산을 한 곳에서 검색 및 관리 End-to-End 데이터 계보(Lineage) : Tableau 대시보드가 어떤 […]
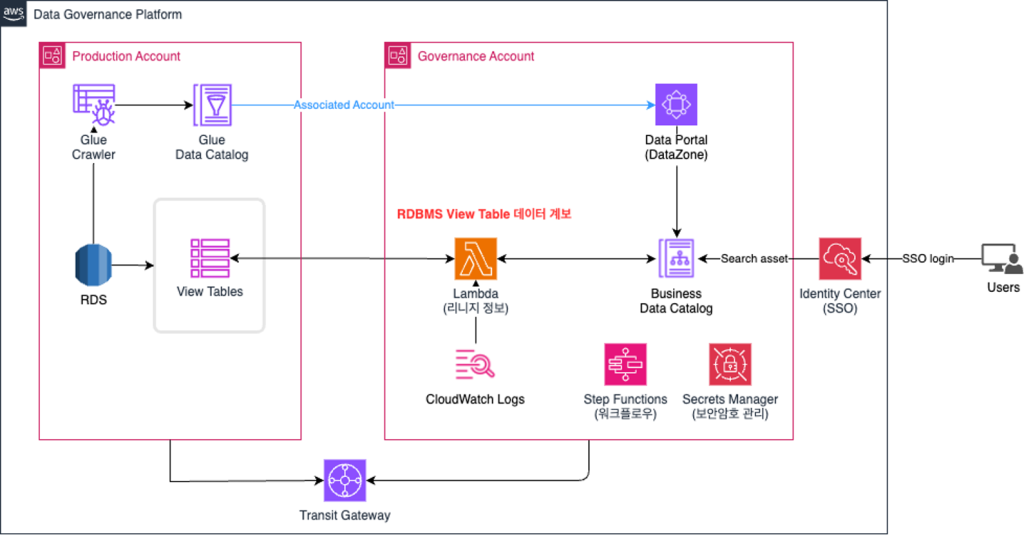
AWS DataZone에서 OpenLineage 기반의 View 테이블 데이터 계보 그리기
배경 관계형 데이터베이스에서 View 테이블은 실제 데이터를 저장하지 않고, 기본 테이블의 데이터를 기반으로 한 가상의 테이블입니다. View 테이블의 데이터 계보는 데이터가 어떤 기본 테이블에서 비롯되었고, 어떤 과정을 거쳐 최종적으로 View 테이블에 도달했는지를 명확히 파악하는 데 필수적입니다. 이를 통해 데이터의 출처와 변환 과정을 명확히 이해하고, 데이터의 신뢰성을 보장할 수 있습니다. 또한, 데이터 계보는 View 테이블이 잘못된 […]

모니터링 중앙화를 구축하는 가장 쉬운 방법, AWS CloudWatch cross-account-observability
시작하며,, SA로 많은 고객을 만나다 보면, AWS Cloud를 사용하는 많은 사례에서 비즈니스가 성장해 감에 따라 하나의 조직에서 여러 Account를 관리해야 하는 상황을 쉽게 마주치곤 합니다. 각각의 고객 마다 문제를 해결하기 위해 다양한 방법을 고민하고, 저마다의 해결책을 구현하는 것을 볼 수 있었습니다. 하지만 경우에 따라 Observability 중앙화를 위해 도입한 도구의 Learning-curve를 마주 한다거나, 의도하지 않았던 비용의 […]

CloudWatch Real User Monitoring(RUM)을 사용하여 Amazon CloudFront의 성능 테스트를 준비하고 실행하기
이 글은 Networking & Content Delivery 블로그에 게시된 글 (Prepare and run performance tests for Amazon Cloudfront with Real User Monitoring)를 한국어로 번역 및 편집하였습니다. 소비자 대상 웹사이트와 모바일 앱의 경우, 사용자의 화면에 콘텐츠가 로드되는 속도는 사용자의 브라우징 경험뿐만 아니라 비즈니스의 성공에도 직접적인 영향을 미칩니다. 만약 콘텐츠 로딩에 시간이 오래 걸린다면, 사용자는 거래를 완료하기 전에 […]

VMS Solutions의 AWS 기반 데이터 아키텍처 구축과 보안 최적화 사례
VMS Solutions (브이엠에스 솔루션스)는 첨단 제조업의 생산 계획 최적화를 선도하는 APS(Advanced Planning and Scheduling) 전문기업으로, 2024년 가트너 아시아태평양 Supply Chain Planning 분야에서 Notable Vendor로 선정된 바 있습니다. 브이엠에스 솔루션스의 주력 제품인 MOZART는 고성능 데이터 처리와 시스템 연동을 통해 제조업체의 생산성을 혁신하며, 특히 클라우드 기반의 MOZART Cloud는 AWS 인프라를 활용해 뛰어난 확장성과 보안을 제공합니다. MOZART Cloud는 […]

Amazon Aurora PostgreSQL의 쿼리 플랜 모니터링
이 글은 Database 블로그의 Monitor query plans for Amazon Aurora PostgreSQL 을 한국어 번역 및 편집하였습니다. Amazon Aurora PostgreSQL 호환 버전이 한층 더 강화되었습니다. 이제 사용자들은 쿼리 플랜을 자유롭게 관리할 수 있게 되었습니다. 이 기능을 통해 현재 데이터베이스 부하에 기여하는 쿼리 플랜을 식별하고, 시간이 지남에 따라 쿼리 플랜의 성능 통계를 추적할 수 있습니다. 이 글에서는 […]

AWS 오픈 소스 관찰 가능성(Observability) 도구로 커스텀 메트릭 모니터링
현대의 기업과 조직은 IT 인프라와 애플리케이션의 성능을 실시간으로 정확하게 파악하고, 문제가 발생할 때 즉각적으로 대응할 수 있는 능력이 중요합니다. 이 능력을 갖추기 위해 많은 조직들이 다양한 모니터링 도구를 활용하고 있습니다. 그 중에서도 특히 Prometheus (프로메테우스)는 널리 사용되는 오픈 소스 모니터링 도구로, 네트워크 트래픽, 시스템 자원 사용량, 애플리케이션 응답 시간 등 다양한 표준 메트릭을 모니터링하는 데 […]