O blog da AWS
AWS Lambda: Resiliência nos bastidores
Este blog post discute como um serviço regional, como o Lambda, aproveita as zonas de disponibilidade e a estabilidade para atingir sua meta de alta disponibilidade e mostra como as equipes do Lambda verificam a estabilidade estática de seus serviços usando o AWS Fault Injection Simulator (AWS FIS). Também fornece uma solução usando serviços e ferramentas da AWS para alcançar a estratégia de resiliência do serviço Lambda, usando FIS, Amazon CloudWatch e Amazon Route 53 Application Recovery Controller (Route 53 ARC).
O papel das zonas de disponibilidade
As zonas de disponibilidade são seções fisicamente isoladas de uma região da AWS, projetadas para operar, mas também se falhar de forma independente. Eles são separados por uma distância significativa um do outro, de até 100 quilômetros (60 milhas), para evitar falhas correlacionadas, mas próximos o suficiente para usar a replicação síncrona com latência de milissegundos de um dígito.
Clientes e serviços da AWS usam zonas de disponibilidade há anos para criar aplicativos altamente disponíveis, tolerantes a falhas e escaláveis. Em particular, os serviços regionais da AWS, como AWS Lambda, Amazon DynamoDB, Amazon Simple Queue Service (Amazon SQS) e Amazon Simple Storage Service (Amazon S3), alcançam suas promessas de alta disponibilidade espalhando várias réplicas independentes de seus serviços em várias zonas de disponibilidade. Ele usa os princípios de independência e redundância das zonas de disponibilidade para maximizar a disponibilidade geral desse serviço.
Cada réplica é chamada de réplica zonal. O sistema foi projetado para que qualquer uma das réplicas possa falhar a qualquer momento. Quando uma réplica falha, ela pode ser removida temporariamente do sistema até que tudo volte a funcionar conforme o esperado. Quando isso acontece, a carga é compartilhada entre as réplicas zonais restantes.
Projetando para falhas
Uma lição que aprendemos na AWS criando serviços é que, quando há uma deficiência na zona de disponibilidade, é melhor não confiar nas operações do plano de controle para remediar a falha. Uma operação de plano de controle pode, por exemplo, provisionar mais capacidade em uma zona de disponibilidade que não seja afetada pela deficiência.
Esse princípio é chamado de estabilidade estática e descreve a capacidade de um sistema manter seu estado estacionário original (ou comportamento) mesmo quando submetido a eventos disruptivos sem precisar fazer nenhuma alteração. Um serviço estaticamente estável deve ter o mínimo possível de dependências para seu processo de recuperação.
Para um serviço regional como o AWS Lambda, isso significa que a capacidade restante nas zonas de disponibilidade saudáveis pode absorver o tráfego de uma zona de disponibilidade potencialmente prejudicada sem precisar aumentar a escala. Isso implica provisionamento excessivo de recursos em todas as zonas de disponibilidade. Ter essa capacidade extra pré-provisionada ajuda o Lambda a alcançar sua estabilidade estática. É uma compensação entre o custo do provisionamento excessivo de recursos e a disponibilidade do serviço. Como o AWS Lambda promete alta disponibilidade a seus clientes, com um compromisso mensal de serviço de disponibilidade de 99,95%, essa compensação recai sobre a disponibilidade do serviço.
Como se preparar para falhas
A preparação para uma deficiência na zona de sisponibilidade é difícil porque os sintomas e o tamanho do impacto podem variar muito. Uma zona de disponibilidade pode estar parcialmente acessível ou totalmente inacessível. As causas da deficiência podem variar de cortes de fibra, problemas de energia, superaquecimento, avarias de hardware, problemas de rede, problemas de capacidade e outras situações inesperadas. Quando isso acontece, acontece muito raramente. As categorias mais comuns de falhas são implantações e configurações incorretas.
Embora algumas dessas falhas possam ser difíceis de inferir ou reproduzir, os sintomas comuns incluem interrupção da conectividade, aumento da latência, aumento do tráfego devido a tempestades de novas tentativas, aumento do uso da CPU e da memória e entrada e saída (IO) E/S lenta.
Na AWS, aprendemos a esperar o inesperado e a planejar o fracasso. Isso significa injetar falhas no sistema para reproduzir alguns dos sintomas comuns de deficiências na Zona de Disponibilidade, observar como o sistema responde e implementar melhorias. Além disso, a injeção de falhas no sistema ajuda a descobrir possíveis pontos cegos alarmantes e de monitoramento, além de oferecer às equipes a oportunidade de praticar e melhorar sua resposta aos eventos com foco na redução do tempo de recuperação.
Como o Lambda testa sua resposta a uma deficiência na zona de disponibilidade
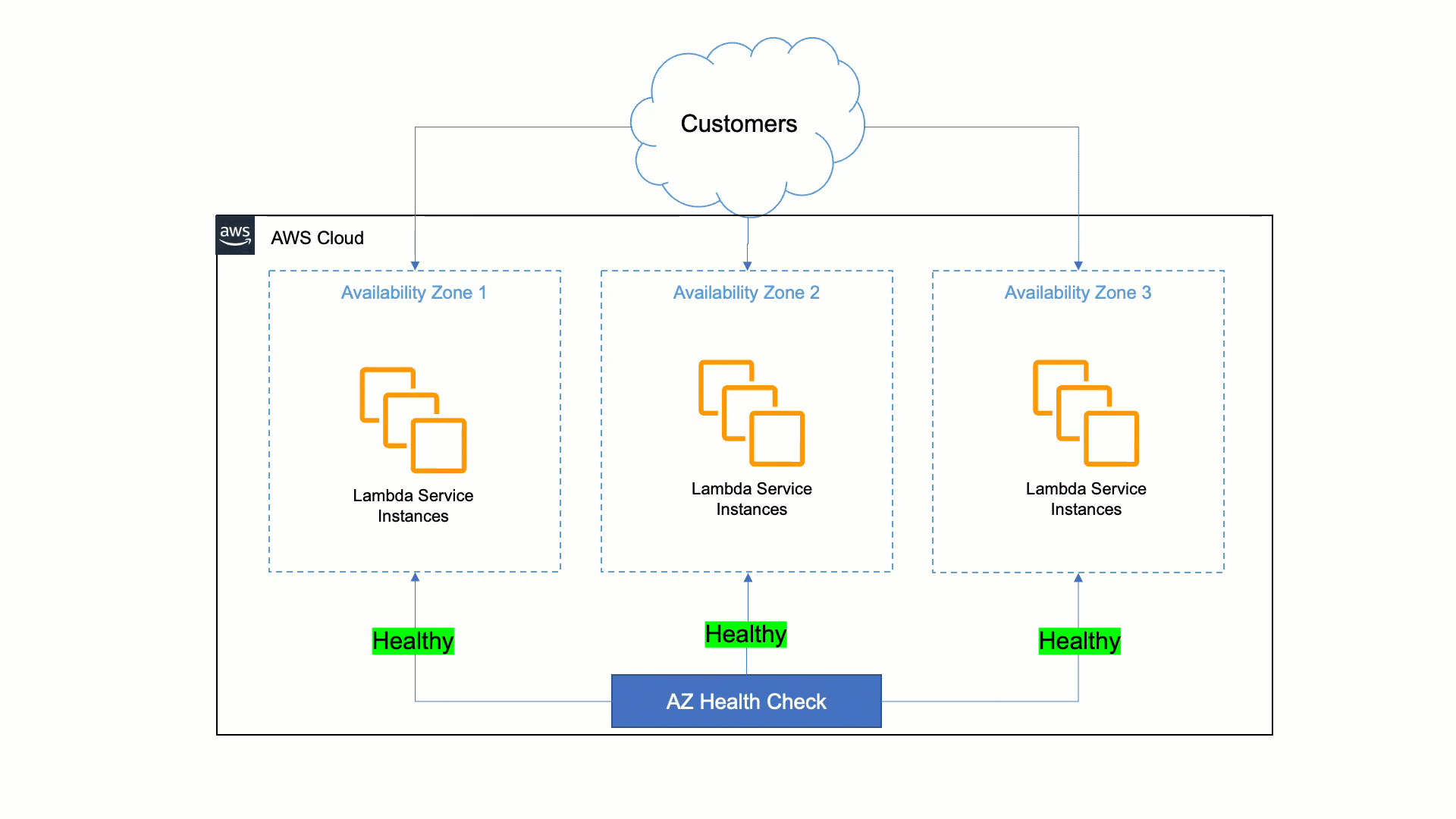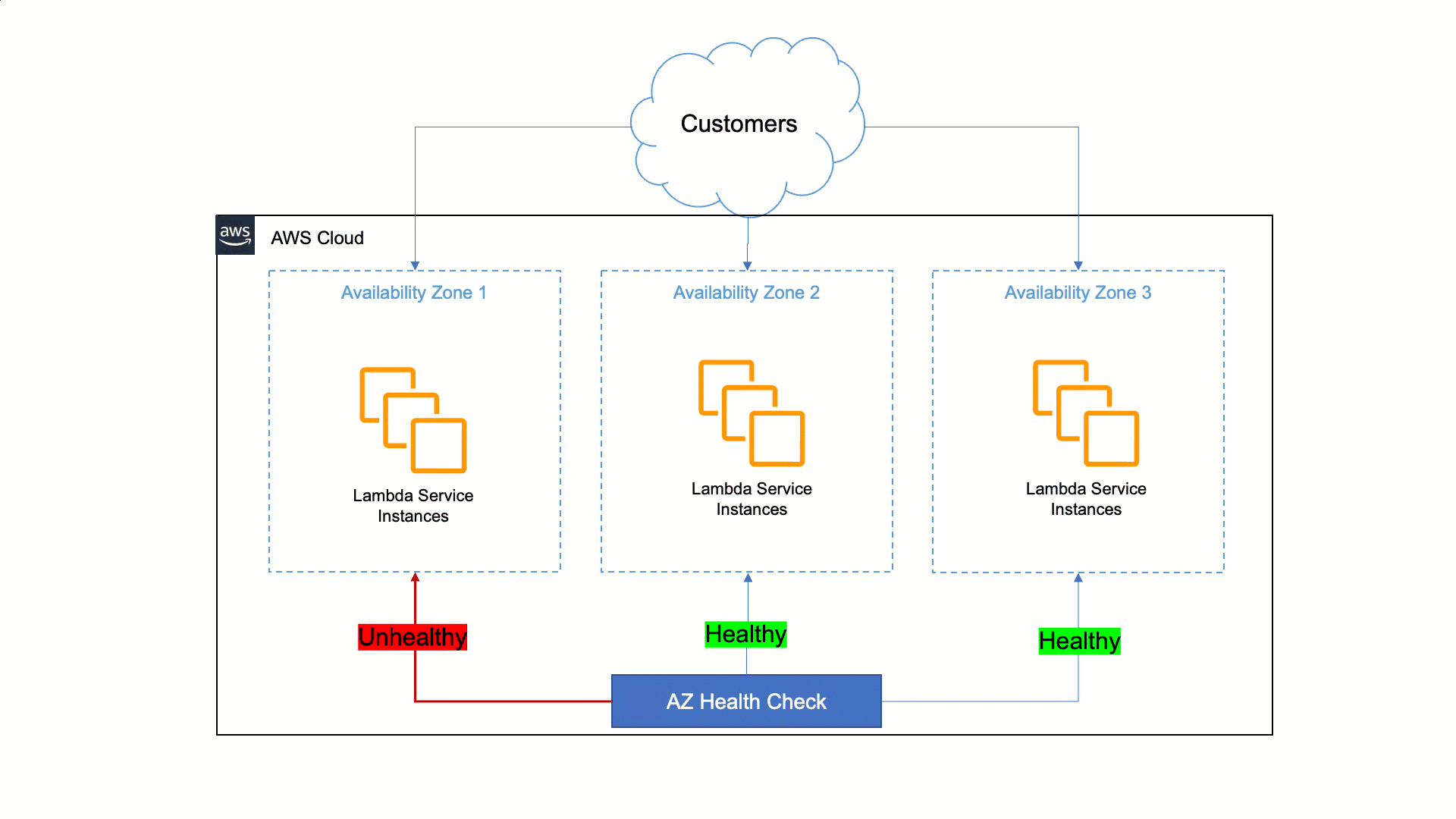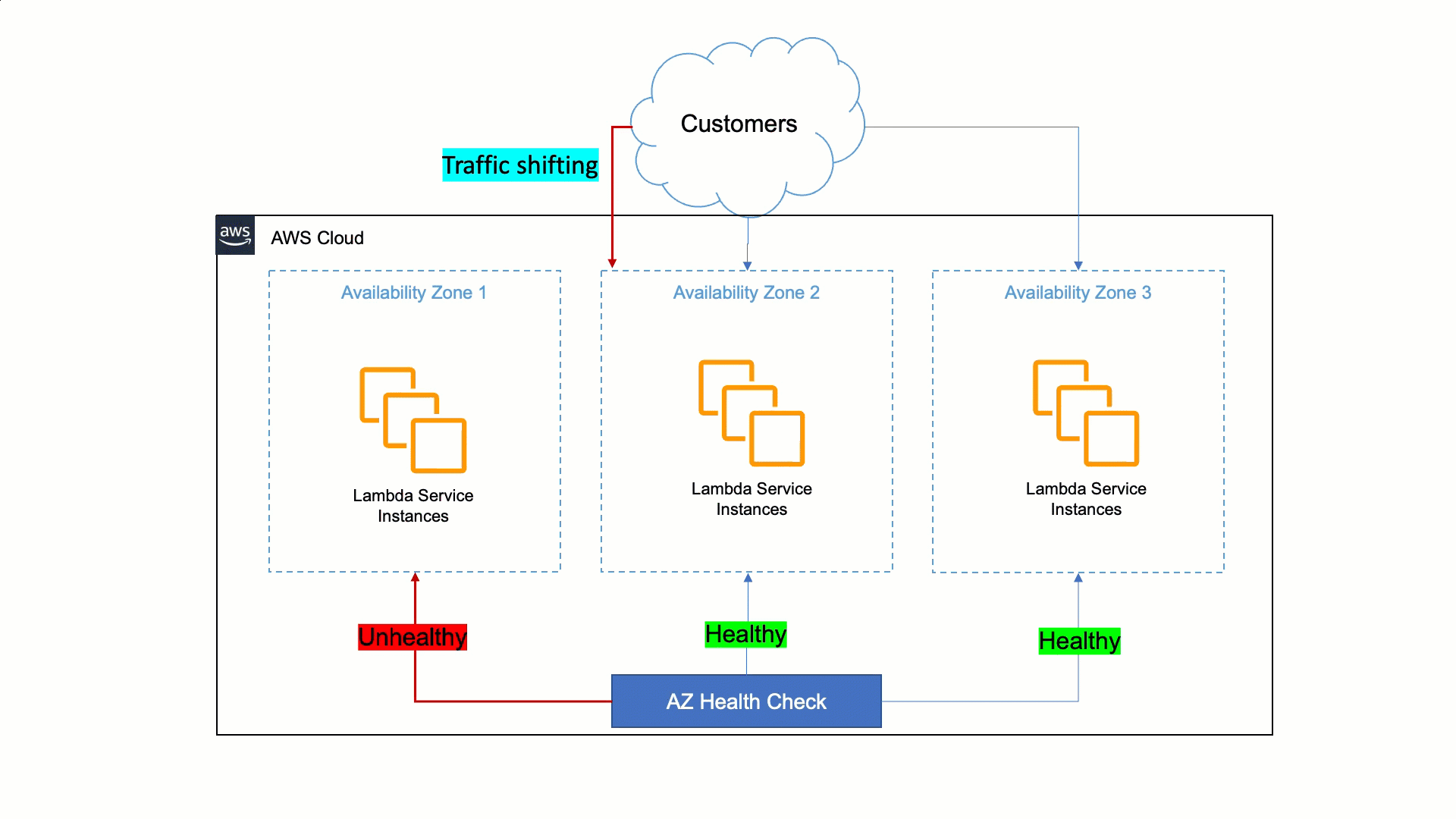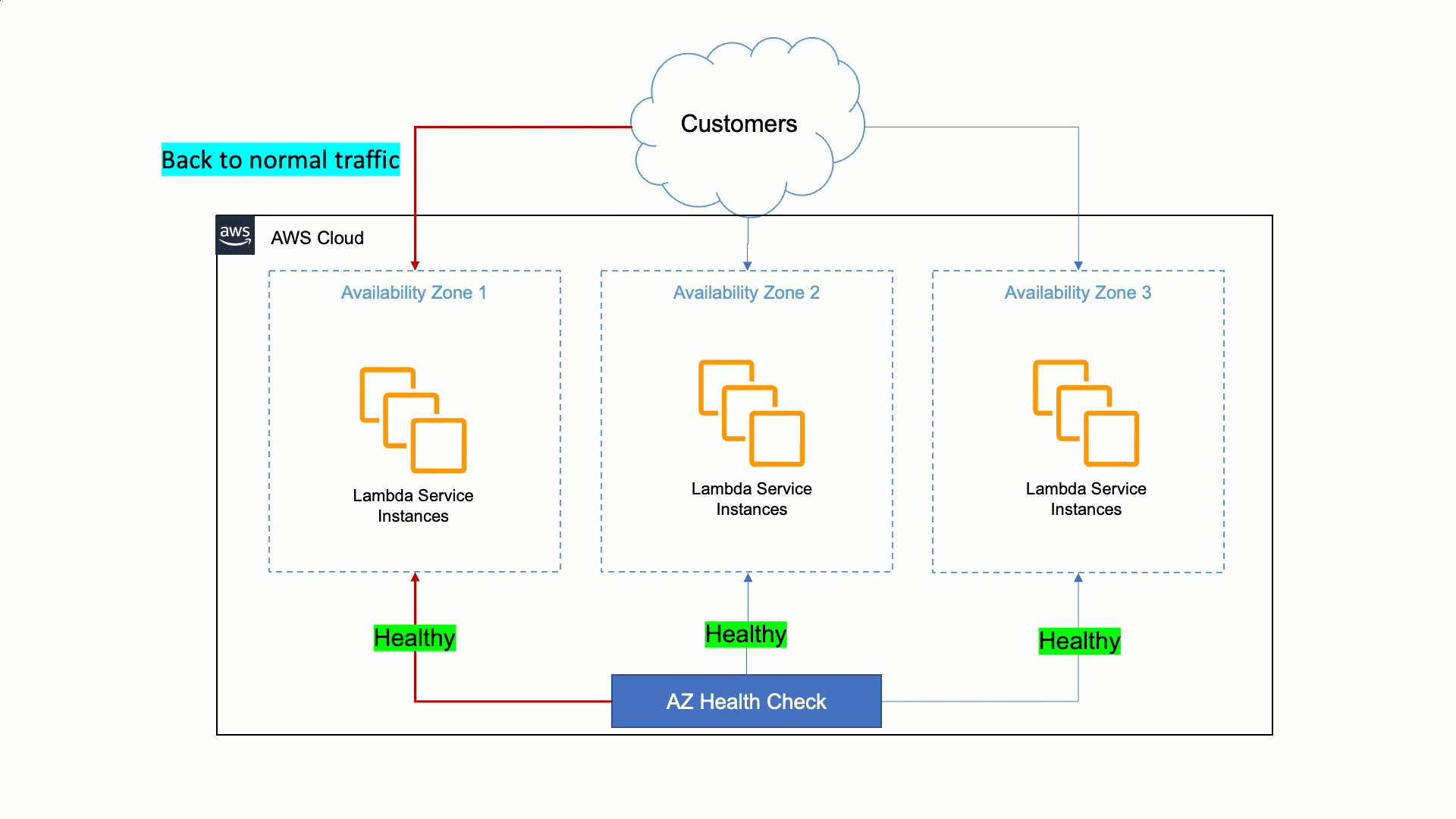
A abordagem da Lambda para ser resiliente às deficiências da Zona de Disponibilidade é confiar na estabilidade estática e em sistemas automatizados. Os humanos são mais lentos do que as máquinas para detectar problemas e mitigá-los. Portanto, a Lambda deve garantir que seus serviços possam detectar problemas em uma réplica zonal e corrigi-los automaticamente em minutos e sem intervenção do operador. Essa correção automática é feita transferindo o tráfego do cliente da Zona de Disponibilidade afetada para zonas saudáveis, e é chamada de evacuação da Zona de Disponibilidade.
Para fazer isso, a Lambda criou uma ferramenta que detecta falhas e realiza a evacuação da Zona de Disponibilidade quando necessário. Essa ferramenta faz uma comparação estatística de métricas entre diferentes zonas de disponibilidade e instâncias do EC2 para identificar zonas de disponibilidade insalubresindisponíveis. Se uma zona de disponibilidade apresentar problemas, a ferramenta iniciará automaticamente a evacuação da zona de disponibilidade indisponível. Essa automação reduz o tempo da primeira ação de 30 minutos para menos de 3 minutos.
 Como o AWS Lambda usa o AWS FIS
Como o AWS Lambda usa o AWS FIS
Para verificar se a automação funciona continuamente conforme o esperado, o Lambda realiza uma grande variedade de testes, incluindo testes de falha na zona de disponibilidade em seu ambiente de pré-produção. O principal objetivo desses testes é verificar se os serviços estão estaticamente estáveis na presença de deficiências na zona de disponibilidade e verificar se a evacuação da zona de disponibilidade pode ser iniciada com sucesso. A vantagem de ter um teste automatizado é que as equipes podem repeti-lo regularmente e não precisam ter habilidades especiais. Basta um clique para iniciar o teste.
Para esses testes, o Lambda usa o AWS FIS para injetar falhas em sua grande frota de instâncias do EC2. Eles usam o AWS FIS com o suporte do agente do AWS System Manager (SSM) e filtros de recursos para direcionar sua frota de instâncias EC2 em uma zona de disponibilidade específica. Essa é uma abordagem versátil que pode injetar falhas de recursos, como esgotamento de CPU e memória, e falhas de rede, como latência, perda ou queda de pacotes.
Injetar perda ou latência de pacotes é muito importante, pois esses sintomas podem ter um sério impacto no desempenho do aplicativo e da rede. De fato, a latência e a perda, mesmo em pequenas quantidades, podem criar ineficiências e impedir que os aplicativos funcionem com desempenho máximo. Para o Lambda, é fundamental ser capaz de detectar o aumento da latência ou perda antes que isso afete os clientes.
Como recuperar rapidamente seus aplicativos de falhas nas zonas de disponibilidade
Você pode criar uma solução semelhante para recuperar rapidamente seus aplicativos de uma falha zonal. A solução deve ter um mecanismo para evacuar uma zona de disponibilidade danificada, um sistema de monitoramento que permita detectar quando uma réplica zonal está danificada e uma forma de testar a estabilidade estática do seu sistema. A AWS fornece muitas ferramentas e serviços que podem ajudar você a criar essa solução para alcançar a estratégia de resiliência da Lambda.
Para realizar a evacuação da zona de disponibilidade, você pode usar o novo recurso de mudança zonal do Route 53 ARC, que, no momento da redação deste artigo, está em versão prévia. A mudança zonal permite que você evacue uma zona de disponibilidade para aplicativos que usam o Elastic Load Balancing. Se você descobrir que uma réplica zonal está danificada ou não está íntegra, você pode usar a mudança zonal para evacuar a zona de disponibilidade por um período de tempo, enquanto o problema é corrigido.
Para realizar a mudança zonal, você deve detectar quando uma réplica zonal não está íntegra. Seu aplicativo deve fornecer um sinal de sua integridade por zona de disponibilidade. Há duas maneiras comuns de capturar esse sinal. Primeiro, passivamente, você pode verificar suas métricas, como tempos de resposta, códigos de status HTTP e outras métricas que podem ajudar a rastrear erros fatais em seus aplicativos. Ou ativamente, usando o monitoramento sintético, que permite criar solicitações sintéticas em seu aplicativo de produção para fornecer uma visão mais completa da experiência do cliente.
O Amazon CloudWatch Synthetics fornece canaries, que são scripts executados de forma programada e executam solicitações sintéticas nos endpoints e APIs do seu aplicativo. Os canaries realizam as mesmas ações que os clientes e verificam continuamente a experiência do cliente. Você pode criar um canaries para cada réplica zonal do seu aplicativo e monitorar os resultados de forma independente.
Com essas informações, se a experiência do usuário diminuir em uma das réplicas, você poderá iniciar uma evacuação da zona de disponibilidade usando a mudança de zona e minimizar a experiência ruim para o usuário enquanto encontra e corrige as fontes da falha.
Para garantir que você possa se recuperar com êxito de uma falha, você deve testar a solução com antecedência. Sem testes, é apenas uma suposição. Para provar ou refutar suas suposições sobre a capacidade do seu sistema de lidar com eventos disruptivos, como problemas em zonas de disponibilidade, você pode usar o AWS Fault Injection Simulator (FIS).
Com o FIS, você pode injetar falhas simultaneamente em vários recursos dentro do mesmo domínio de falha, como zonas de disponibilidade. Atualmente, o FIS se integra a vários serviços da AWS, incluindo Amazon EC2, Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS), Amazon Relational Database Service (Amazon RDS), AWS Networking e Amazon CloudWatch.
Os casos de uso típicos para testar a resiliência de uma carga de trabalho ao comprometimento das zonas de disponibilidade são, por exemplo, encerrar todos os recursos computacionais e bancos de dados em uma zona de disponibilidade específica, injetar latência ou perda de pacotes, aumentar o consumo de recursos (CPU, memória e E/S) em recursos computacionais em uma zona de disponibilidade específica ou afetar a comunicação de rede dentro ou entre as zonas de disponibilidade.
Para obter mais informações e um exemplo passo a passo de como se recuperar rapidamente de falhas de aplicativos em uma única zona de disponibilidade e testá-la com o AWS FIS, leia esta postagem de blog.
Conclusão
Este artigo discute a estabilidade estática, um mecanismo usado pelos serviços da AWS, como o Lambda, para criar serviços regionais resilientes. Também discute como a AWS tira proveito dos mesmos serviços e infraestrutura dos clientes. Ele mostra como o Lambda usa várias zonas de disponibilidade e serviços como o AWS FIS para criar serviços altamente disponíveis e melhorar seu tempo de recuperação de falhas inesperadas para apenas alguns minutos sem intervenção humana. Por fim, mostra uma solução que você pode implementar em suas aplicações para alcançar a estratégia de resiliência da Lambda.
Para saber mais sobre o AWS FIS, há muitos tutoriais e um workshop que você pode conferir.
Para obter mais recursos de aprendizado sem servidor, visite Serverless Land.
Este artigo foi traduzido do Blog da AWS em Inglês.
Sobre o autor
 Adrian Hornsby é Engenheiro Principal de Desenvolvimento de Sistemas
Adrian Hornsby é Engenheiro Principal de Desenvolvimento de Sistemas
 Marcia Villalba é Developer Advocate
Marcia Villalba é Developer Advocate
Tradutor
 Daniel Abib é Enterprise Solution Architect na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e segurança. Ele trabalha apoiando clientes corporativos, ajudando-os em sua jornada para a nuvem.
Daniel Abib é Enterprise Solution Architect na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e segurança. Ele trabalha apoiando clientes corporativos, ajudando-os em sua jornada para a nuvem.